Before you begin
If you haven't already done so, set up a Google Cloud project and two (2) Cloud Storage buckets.
Set up your project
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Dataproc, Compute Engine, Cloud Storage, and Cloud Run functions APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Install the Google Cloud CLI.
-
If you're using an external identity provider (IdP), you must first sign in to the gcloud CLI with your federated identity.
-
To initialize the gcloud CLI, run the following command:
gcloud init -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Dataproc, Compute Engine, Cloud Storage, and Cloud Run functions APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Install the Google Cloud CLI.
-
If you're using an external identity provider (IdP), you must first sign in to the gcloud CLI with your federated identity.
-
To initialize the gcloud CLI, run the following command:
gcloud init
Create or use two Cloud Storage buckets in your project
You will need two Cloud Storage buckets in your project: one for input files and another for output.
- In the Google Cloud console, go to the Cloud Storage Buckets page.
- Click Create.
- On the Create a bucket page, enter your bucket information. To go to the next
step, click Continue.
-
In the Get started section, do the following:
- Enter a globally unique name that meets the bucket naming requirements.
- To add a
bucket label,
expand the Labels section (),
click add_box
Add label, and specify a
keyand avaluefor your label.
-
In the Choose where to store your data section, do the following:
- Select a Location type.
- Choose a location where your bucket's data is permanently stored from the Location type drop-down menu.
- If you select the dual-region location type, you can also choose to enable turbo replication by using the relevant checkbox.
- To set up cross-bucket replication, select
Add cross-bucket replication via Storage Transfer Service and
follow these steps:
Set up cross-bucket replication
- In the Bucket menu, select a bucket.
In the Replication settings section, click Configure to configure settings for the replication job.
The Configure cross-bucket replication pane appears.
- To filter objects to replicate by object name prefix, enter a prefix that you want to include or exclude objects from, then click Add a prefix.
- To set a storage class for the replicated objects, select a storage class from the Storage class menu. If you skip this step, the replicated objects will use the destination bucket's storage class by default.
- Click Done.
-
In the Choose how to store your data section, do the following:
- Select a default storage class for the bucket or Autoclass for automatic storage class management of your bucket's data.
- To enable hierarchical namespace, in the Optimize storage for data-intensive workloads section, select Enable hierarchical namespace on this bucket.
- In the Choose how to control access to objects section, select whether or not your bucket enforces public access prevention, and select an access control method for your bucket's objects.
-
In the Choose how to protect object data section, do the
following:
- Select any of the options under Data protection that you
want to set for your bucket.
- To enable soft delete, click the Soft delete policy (For data recovery) checkbox, and specify the number of days you want to retain objects after deletion.
- To set Object Versioning, click the Object versioning (For version control) checkbox, and specify the maximum number of versions per object and the number of days after which the noncurrent versions expire.
- To enable the retention policy on objects and buckets, click the Retention (For compliance) checkbox, and then do the following:
- To enable Object Retention Lock, click the Enable object retention checkbox.
- To enable Bucket Lock, click the Set bucket retention policy checkbox, and choose a unit of time and a length of time for your retention period.
- To choose how your object data will be encrypted, expand the Data encryption section (), and select a Data encryption method.
- Select any of the options under Data protection that you
want to set for your bucket.
-
In the Get started section, do the following:
- Click Create.
Create a workflow template
To create and define a workflow template, copy and run the following commands in a local terminal window or in Cloud Shell.
- Create the workflow template.
gcloud dataproc workflow-templates create wordcount-template \ --region=us-central1
- Add the wordcount job to the workflow template.
-
Specify your output-bucket-name before running
the command (your function will supply the input bucket).
After you insert the output-bucket-name, the output
bucket argument should read as follows:
gs://your-output-bucket/wordcount-output". -
The "count" step ID
is required, and identifies the added hadoop job.
gcloud dataproc workflow-templates add-job hadoop \ --workflow-template=wordcount-template \ --step-id=count \ --jar=file:///usr/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar \ --region=us-central1 \ -- wordcount gs://input-bucket gs://output-bucket-name/wordcount-output
-
Specify your output-bucket-name before running
the command (your function will supply the input bucket).
After you insert the output-bucket-name, the output
bucket argument should read as follows:
- Use a
managed,
single-node
cluster to run the workflow. Dataproc will create the
cluster, run the workflow on it, then delete the cluster when the workflow completes.
gcloud dataproc workflow-templates set-managed-cluster wordcount-template \ --cluster-name=wordcount \ --single-node \ --region=us-central1 - Click the
wordcount-templatename on the Dataproc Workflows page in the Google Cloud console to open the Workflow template details page. Confirm the wordcount-template attributes.
Parameterize the workflow template
Parameterize the input bucket variable to pass to the workflow template.
- Export the workflow template to a
wordcount.yamltext file for parameterization.gcloud dataproc workflow-templates export wordcount-template \ --destination=wordcount.yaml \ --region=us-central1
- Using a text editor, open
wordcount.yaml, then add aparametersblock to the end of YAML file so that the Cloud Storage INPUT_BUCKET_URI can be passed asargs[1]to the wordcount binary when the workflow is triggered.A sample exported YAML file is shown, below. You can take one of two approaches to update your template:
- Copy then paste the entire file to replace your exported
wordcount.yamlafter replacing your-output_bucket with your output bucket name, OR - Copy then paste only the
parameterssection to the end of your exportedwordcount.yamlfile.
jobs: - hadoopJob: args: - wordcount - gs://input-bucket - gs://your-output-bucket/wordcount-output mainJarFileUri: file:///usr/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar stepId: count placement: managedCluster: clusterName: wordcount config: softwareConfig: properties: dataproc:dataproc.allow.zero.workers: 'true' parameters: - name: INPUT_BUCKET_URI description: wordcount input bucket URI fields: - jobs['count'].hadoopJob.args[1] - Copy then paste the entire file to replace your exported
- Import the parameterized
wordcount.yamltext file. Type 'Y'es when asked to overwrite the template.gcloud dataproc workflow-templates import wordcount-template \ --source=wordcount.yaml \ --region=us-central1
Create a Cloud function
Open the Cloud Run functions page in the Google Cloud console, then click CREATE FUNCTION.
On the Create function page, enter or select the following information:
- Name: wordcount
- Memory allocated: Keep the default selection.
- Trigger:
- Cloud Storage
- Event Type: Finalize/Create
- Bucket: Select your input bucket (see Create a Cloud Storage bucket in your project). When a file is added to this bucket, the function will trigger the workflow. The workflow will run the wordcount application, which will process all text files in the bucket.
Source code:
- Inline editor
- Runtime: Node.js 8
INDEX.JStab: Replace the default code snippet with the following code, then edit theconst projectIdline to supply -your-project-id- (without a leading or trailing "-").
const dataproc = require('@google-cloud/dataproc').v1; exports.startWorkflow = (data) => { const projectId = '-your-project-id-' const region = 'us-central1' const workflowTemplate = 'wordcount-template' const client = new dataproc.WorkflowTemplateServiceClient({ apiEndpoint: `${region}-dataproc.googleapis.com`, }); const file = data; console.log("Event: ", file); const inputBucketUri = `gs://${file.bucket}/${file.name}`; const request = { name: client.projectRegionWorkflowTemplatePath(projectId, region, workflowTemplate), parameters: {"INPUT_BUCKET_URI": inputBucketUri} }; client.instantiateWorkflowTemplate(request) .then(responses => { console.log("Launched Dataproc Workflow:", responses[1]); }) .catch(err => { console.error(err); }); };PACKAGE.JSONtab: Replace the default code snippet with the following code.
{ "name": "dataproc-workflow", "version": "1.0.0", "dependencies":{ "@google-cloud/dataproc": ">=1.0.0"} }- Function to execute: Insert: "startWorkflow".
Click CREATE.
Test your function
Copy public file
rose.txtto your bucket to trigger the function. Insert your-input-bucket-name (the bucket used to trigger your function) in the command.gcloud storage cp gs://pub/shakespeare/rose.txt gs://your-input-bucket-name
Wait 30 seconds, then run the following command to verify the function completed successfully.
gcloud functions logs read wordcount
... Function execution took 1348 ms, finished with status: 'ok'
To view the function logs from the Functions list page in the Google Cloud console, click the
wordcountfunction name, then click VIEW LOGS on the Function details page.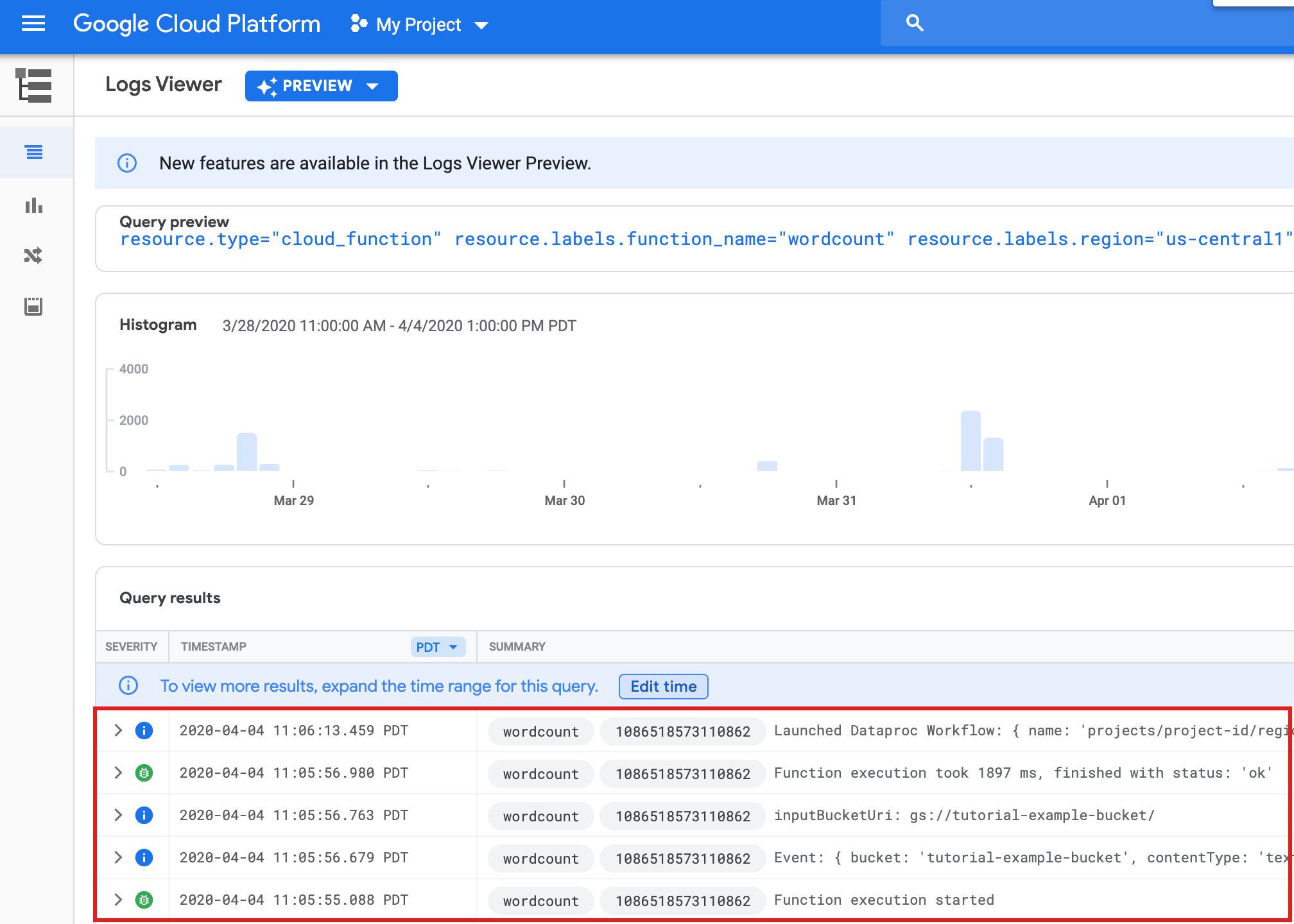
You can view the
wordcount-outputfolder in your output bucket from the Storage browser page in the Google Cloud console.
After the workflow completes, job details persist in the Google Cloud console. Click the
count...job listed on the Dataproc Jobs page to view workflow job details.
Clean up
The workflow in this tutorial deletes its managed cluster when the workflow completes. To avoid recurring costs, you can delete other resources associated with this tutorial.
Delete a project
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Delete Cloud Storage buckets
- In the Google Cloud console, go to the Cloud Storage Buckets page.
- Click the checkbox for the bucket that you want to delete.
- To delete the bucket, click Delete, and then follow the instructions.
Delete your workflow template
gcloud dataproc workflow-templates delete wordcount-template \ --region=us-central1
Delete your Cloud function
Open the Cloud Run functions page in the
Google Cloud console, select the box to the left of the wordcount function,
then click Delete.