Trino(原 Presto)是一个分布式 SQL 查询引擎,旨在查询分布在一个或多个异构数据源上的大型数据集。Trino 可以通过连接器查询 Hive、MySQL、Kafka 及其他数据源。本教程将介绍如何执行以下操作:
- 在 Dataproc 集群上安装 Trino 服务
- 从安装在本地机器上的 Trino 客户端查询公共数据,该客户端与集群上的 Trino 服务通信
- 通过 Trino Java JDBC 驱动程序,从与集群上的 Trino 服务通信的 Java 应用运行查询。
目标
- 从 BigQuery 中提取数据
- 以 CSV 文件的形式将数据加载到 Cloud Storage 中
- 转换数据:
- 将数据公开为 Hive 外部表,以便 Trino 可以查询这些数据
- 将 CSV 格式的数据转换为 Parquet 格式,以加快查询速度
费用
在本文档中,您将使用 Google Cloud的以下收费组件:
如需根据您的预计使用量来估算费用,请使用价格计算器。
准备工作
如果您尚未完成此操作,请创建 Google Cloud 项目和 Cloud Storage 存储桶,以保存此教程中使用的数据。1. 设置您的项目- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Dataproc, Compute Engine, Cloud Storage, and BigQuery APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Install the Google Cloud CLI.
-
如果您使用的是外部身份提供方 (IdP),则必须先使用联合身份登录 gcloud CLI。
-
如需初始化 gcloud CLI,请运行以下命令:
gcloud init -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Dataproc, Compute Engine, Cloud Storage, and BigQuery APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Install the Google Cloud CLI.
-
如果您使用的是外部身份提供方 (IdP),则必须先使用联合身份登录 gcloud CLI。
-
如需初始化 gcloud CLI,请运行以下命令:
gcloud init - In the Google Cloud console, go to the Cloud Storage Buckets page.
- Click Create.
- On the Create a bucket page, enter your bucket information. To go to the next
step, click Continue.
-
In the Get started section, do the following:
- Enter a globally unique name that meets the bucket naming requirements.
- To add a
bucket label,
expand the Labels section (),
click add_box
Add label, and specify a
keyand avaluefor your label.
-
In the Choose where to store your data section, do the following:
- Select a Location type.
- Choose a location where your bucket's data is permanently stored from the Location type drop-down menu.
- If you select the dual-region location type, you can also choose to enable turbo replication by using the relevant checkbox.
- To set up cross-bucket replication, select
Add cross-bucket replication via Storage Transfer Service and
follow these steps:
Set up cross-bucket replication
- In the Bucket menu, select a bucket.
In the Replication settings section, click Configure to configure settings for the replication job.
The Configure cross-bucket replication pane appears.
- To filter objects to replicate by object name prefix, enter a prefix that you want to include or exclude objects from, then click Add a prefix.
- To set a storage class for the replicated objects, select a storage class from the Storage class menu. If you skip this step, the replicated objects will use the destination bucket's storage class by default.
- Click Done.
-
In the Choose how to store your data section, do the following:
- Select a default storage class for the bucket or Autoclass for automatic storage class management of your bucket's data.
- To enable hierarchical namespace, in the Optimize storage for data-intensive workloads section, select Enable hierarchical namespace on this bucket.
- In the Choose how to control access to objects section, select whether or not your bucket enforces public access prevention, and select an access control method for your bucket's objects.
-
In the Choose how to protect object data section, do the
following:
- Select any of the options under Data protection that you
want to set for your bucket.
- To enable soft delete, click the Soft delete policy (For data recovery) checkbox, and specify the number of days you want to retain objects after deletion.
- To set Object Versioning, click the Object versioning (For version control) checkbox, and specify the maximum number of versions per object and the number of days after which the noncurrent versions expire.
- To enable the retention policy on objects and buckets, click the Retention (For compliance) checkbox, and then do the following:
- To enable Object Retention Lock, click the Enable object retention checkbox.
- To enable Bucket Lock, click the Set bucket retention policy checkbox, and choose a unit of time and a length of time for your retention period.
- To choose how your object data will be encrypted, expand the Data encryption section (), and select a Data encryption method.
- Select any of the options under Data protection that you
want to set for your bucket.
-
In the Get started section, do the following:
- Click Create.
- 设置环境变量:
- PROJECT:您的项目 ID
- BUCKET_NAME::您在准备工作中创建的 Cloud Storage 存储分区的名称
- REGION:将在其中创建此教程所使用集群的区域,例如“us-west1”
- WORKERS:此教程推荐配备 3 到 5 个工作器
export PROJECT=project-id export WORKERS=number export REGION=region export BUCKET_NAME=bucket-name
- 在本地机器上运行 Google Cloud CLI 以创建集群。
gcloud beta dataproc clusters create trino-cluster \ --project=${PROJECT} \ --region=${REGION} \ --num-workers=${WORKERS} \ --scopes=cloud-platform \ --optional-components=TRINO \ --image-version=2.1 \ --enable-component-gateway - 在本地机器上,运行以下命令,以 CSV 文件(不含标题)形式将出租车数据从 BigQuery 导入您在准备工作中创建的 Cloud Storage 存储分区。
bq --location=us extract --destination_format=CSV \ --field_delimiter=',' --print_header=false \ "bigquery-public-data:chicago_taxi_trips.taxi_trips" \ gs://${BUCKET_NAME}/chicago_taxi_trips/csv/shard-*.csv - 创建由 Cloud Storage 存储桶中的 CSV 和 Parquet 文件支持的 Hive 外部表。
- 创建 Hive 外部表
chicago_taxi_trips_csv。gcloud dataproc jobs submit hive \ --cluster trino-cluster \ --region=${REGION} \ --execute " CREATE EXTERNAL TABLE chicago_taxi_trips_csv( unique_key STRING, taxi_id STRING, trip_start_timestamp TIMESTAMP, trip_end_timestamp TIMESTAMP, trip_seconds INT, trip_miles FLOAT, pickup_census_tract INT, dropoff_census_tract INT, pickup_community_area INT, dropoff_community_area INT, fare FLOAT, tips FLOAT, tolls FLOAT, extras FLOAT, trip_total FLOAT, payment_type STRING, company STRING, pickup_latitude FLOAT, pickup_longitude FLOAT, pickup_location STRING, dropoff_latitude FLOAT, dropoff_longitude FLOAT, dropoff_location STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE location 'gs://${BUCKET_NAME}/chicago_taxi_trips/csv/';" - 验证 Hive 外部表的创建过程。
gcloud dataproc jobs submit hive \ --cluster trino-cluster \ --region=${REGION} \ --execute "SELECT COUNT(*) FROM chicago_taxi_trips_csv;" - 创建另一个具有相同列的 Hive 外部表
chicago_taxi_trips_parquet,但以 Parquet 格式存储数据可提高查询性能。gcloud dataproc jobs submit hive \ --cluster trino-cluster \ --region=${REGION} \ --execute " CREATE EXTERNAL TABLE chicago_taxi_trips_parquet( unique_key STRING, taxi_id STRING, trip_start_timestamp TIMESTAMP, trip_end_timestamp TIMESTAMP, trip_seconds INT, trip_miles FLOAT, pickup_census_tract INT, dropoff_census_tract INT, pickup_community_area INT, dropoff_community_area INT, fare FLOAT, tips FLOAT, tolls FLOAT, extras FLOAT, trip_total FLOAT, payment_type STRING, company STRING, pickup_latitude FLOAT, pickup_longitude FLOAT, pickup_location STRING, dropoff_latitude FLOAT, dropoff_longitude FLOAT, dropoff_location STRING) STORED AS PARQUET location 'gs://${BUCKET_NAME}/chicago_taxi_trips/parquet/';" - 将 Hive CSV 表中的数据加载到 Hive Parquet 表中。
gcloud dataproc jobs submit hive \ --cluster trino-cluster \ --region=${REGION} \ --execute " INSERT OVERWRITE TABLE chicago_taxi_trips_parquet SELECT * FROM chicago_taxi_trips_csv;" - 验证数据已正确加载。
gcloud dataproc jobs submit hive \ --cluster trino-cluster \ --region=${REGION} \ --execute "SELECT COUNT(*) FROM chicago_taxi_trips_parquet;"
- 创建 Hive 外部表
- 在本地机器上运行以下命令,以通过 SSH 连接到集群的主节点。在执行命令期间,本地终端将停止响应。
gcloud compute ssh trino-cluster-m
- 在集群主节点的 SSH 终端窗口中运行 Trino CLI,连接到该主节点上运行的 Trino 服务器。
trino --catalog hive --schema default
- 在
trino:default提示符下,验证 Trino 是否能找到 Hive 表。show tables;
Table ‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐ chicago_taxi_trips_csv chicago_taxi_trips_parquet (2 rows)
- 从
trino:default提示符运行查询,并比较查询 Parquet 与 CSV 数据的性能。- Parquet 数据查询
select count(*) from chicago_taxi_trips_parquet where trip_miles > 50;
_col0 ‐‐‐‐‐‐‐‐ 117957 (1 row)
Query 20180928_171735_00006_2sz8c, FINISHED, 3 nodes Splits: 308 total, 308 done (100.00%) 0:16 [113M rows, 297MB] [6.91M rows/s, 18.2MB/s] - CSV 数据查询
select count(*) from chicago_taxi_trips_csv where trip_miles > 50;
_col0 ‐‐‐‐‐‐‐‐ 117957 (1 row)
Query 20180928_171936_00009_2sz8c, FINISHED, 3 nodes Splits: 881 total, 881 done (100.00%) 0:47 [113M rows, 41.5GB] [2.42M rows/s, 911MB/s]
- Parquet 数据查询
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
- 如需删除您的集群,请输入以下命令:
gcloud dataproc clusters delete --project=${PROJECT} trino-cluster \ --region=${REGION} - 如需删除您在准备工作中创建的 Cloud Storage 存储分区(包括存储在存储分区中的数据文件),请输入以下命令:
gcloud storage rm gs://${BUCKET_NAME} --recursive
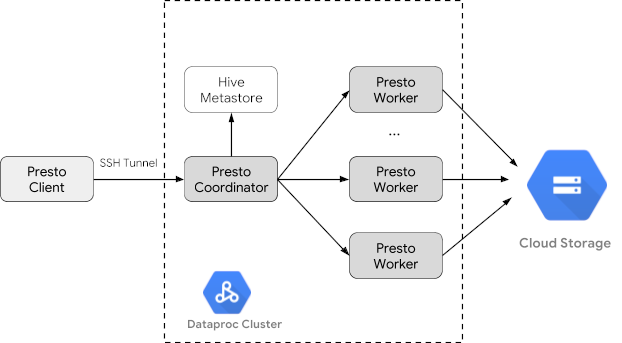
创建 Dataproc 集群
使用 optional-components 标志(在 2.1 版本及更高版本的映像中可用)创建 Dataproc 集群,在该集群上安装 Trino 可选组件,并使用 enable-component-gateway 标志启用组件网关,使您能够从 Google Cloud 控制台访问 Trino 网页界面。
准备数据
将 bigquery-public-data chicago_taxi_trips 数据集作为 CSV 文件导出到 Cloud Storage,然后创建 Hive 外部表以引用数据。
运行查询
您可以在本地通过 Trino CLI 或通过应用运行查询。
Trino CLI 查询
此部分演示如何使用 Trino CLI 查询 Hive Parquet 格式的出租车数据集。
Java 应用查询
如需通过 Trino Java JDBC 驱动程序从 Java 应用运行查询,请执行以下操作:下载 Trino Java JDBC 驱动程序。1. 在 Maven pom.xml 中添加 trino-jdbc 依赖项。
<dependency> <groupId>io.trino</groupId> <artifactId>trino-jdbc</artifactId> <version>376</version> </dependency>
package dataproc.codelab.trino;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
import java.util.Properties;
public class TrinoQuery {
private static final String URL = "jdbc:trino://trino-cluster-m:8080/hive/default";
private static final String SOCKS_PROXY = "localhost:1080";
private static final String USER = "user";
private static final String QUERY =
"select count(*) as count from chicago_taxi_trips_parquet where trip_miles > 50";
public static void main(String[] args) {
try {
Properties properties = new Properties();
properties.setProperty("user", USER);
properties.setProperty("socksProxy", SOCKS_PROXY);
Connection connection = DriverManager.getConnection(URL, properties);
try (Statement stmt = connection.createStatement()) {
ResultSet rs = stmt.executeQuery(QUERY);
while (rs.next()) {
int count = rs.getInt("count");
System.out.println("The number of long trips: " + count);
}
}
} catch (SQLException e) {
e.printStackTrace();
}
}
}日志记录和监控
日志记录
Trino 日志位于集群主节点和工作器节点上的 /var/log/trino/。
网页界面
请参阅查看和访问组件网关网址,在本地浏览器中打开集群主节点上运行的 Trino 网页界面。
监控
Trino 通过运行时表公开集群的运行时信息。在 Trino 会话(从 trino:default)提示符中,运行以下查询以查看运行时表数据:
select * FROM system.runtime.nodes;
清理
完成本教程后,您可以清理您创建的资源,让它们停止使用配额,以免产生费用。以下部分介绍如何删除或关闭这些资源。
删除项目
为了避免产生费用,最简单的方法是删除您为本教程创建的项目。
要删除项目,请执行以下操作: