Tujuan
Tutorial ini menunjukkan kepada Anda cara:
- Buat cluster Dataproc, instal Apache HBase dan Apache ZooKeeper di cluster
- Buat tabel HBase menggunakan shell HBase yang berjalan di node master cluster Dataproc
- Gunakan Cloud Shell untuk mengirimkan tugas Spark Java atau PySpark ke layanan Dataproc yang menulis data ke, lalu membaca data dari, tabel HBase
Biaya
Dalam dokumen ini, Anda akan menggunakan komponen Google Cloudyang dapat ditagih berikut:
Untuk membuat perkiraan biaya berdasarkan proyeksi penggunaan Anda,
gunakan kalkulator harga.
Sebelum memulai
Jika Anda belum melakukannya, buat project Google Cloud Platform.
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Dataproc and Compute Engine APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Dataproc and Compute Engine APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. Jalankan perintah berikut di terminal sesi Cloud Shell untuk:
- Instal komponen HBase dan ZooKeeper
- Sediakan tiga node pekerja (tiga hingga lima pekerja direkomendasikan untuk menjalankan kode dalam tutorial ini)
- Aktifkan Component Gateway
- Menggunakan gambar versi 2.0
- Gunakan tanda
--propertiesuntuk menambahkan konfigurasi HBase dan library HBase ke jalur class driver dan eksekutor Spark.
Dari Google Cloud konsol atau terminal sesi Cloud Shell, SSH ke node master cluster Dataproc.
Verifikasi penginstalan konektor Apache HBase Spark di node master:
ls -l /usr/lib/spark/jars | grep hbase-spark
-rw-r--r-- 1 root root size date time hbase-spark-connector.version.jar
Biarkan terminal sesi SSH tetap terbuka untuk:
- Membuat tabel HBase
- (Pengguna Java): jalankan perintah di node master cluster untuk menentukan versi komponen yang diinstal di cluster
- Pindai tabel Hbase setelah Anda menjalankan kode
Buka shell HBase:
hbase shell
Buat 'my-table' HBase dengan grup kolom 'cf':
create 'my_table','cf'
- Untuk mengonfirmasi pembuatan tabel, di konsol Google Cloud , klik HBase
di link Component Gateway konsolGoogle Cloud
untuk membuka UI Apache HBase.
my-tabletercantum di bagian Tabel di halaman Beranda.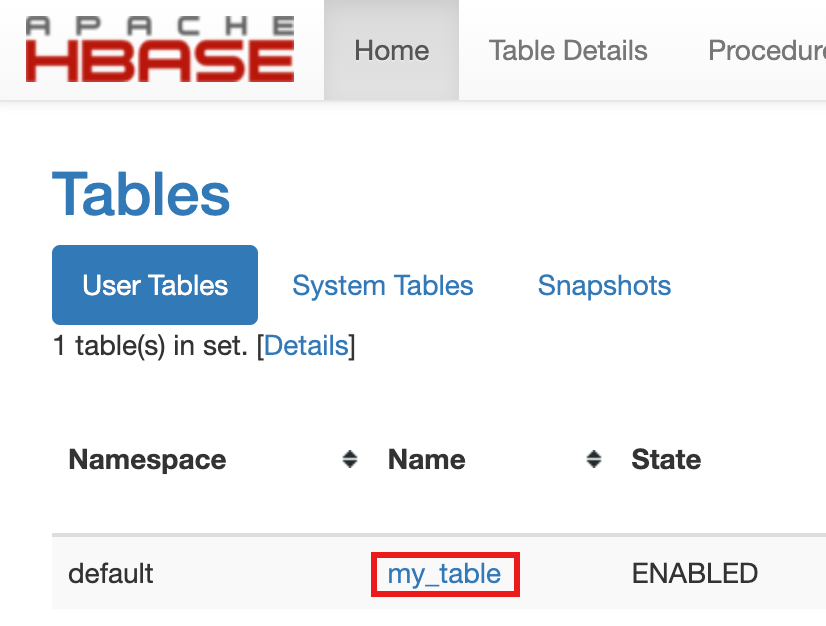
- Untuk mengonfirmasi pembuatan tabel, di konsol Google Cloud , klik HBase
di link Component Gateway konsolGoogle Cloud
untuk membuka UI Apache HBase.
Buka terminal sesi Cloud Shell.
Buat clone repositori GitHub GoogleCloudDataproc/cloud-dataproc ke terminal sesi Cloud Shell Anda:
git clone https://github.com/GoogleCloudDataproc/cloud-dataproc.git
Ubah ke direktori
cloud-dataproc/spark-hbase:cd cloud-dataproc/spark-hbase
user-name@cloudshell:~/cloud-dataproc/spark-hbase (project-id)$
Kirimkan tugas Dataproc.
- Tetapkan versi komponen dalam file
pom.xml.- Halaman versi rilis 2.0.x Dataproc mencantumkan versi komponen Scala, Spark, dan HBase yang diinstal dengan versi subminor 2.0 image terbaru dan empat versi terakhir.
- Untuk menemukan versi subminor cluster versi image 2.0 Anda, klik nama cluster di halaman
Clusters di konsolGoogle Cloud untuk membuka halaman Cluster details, tempat Image version cluster dicantumkan.
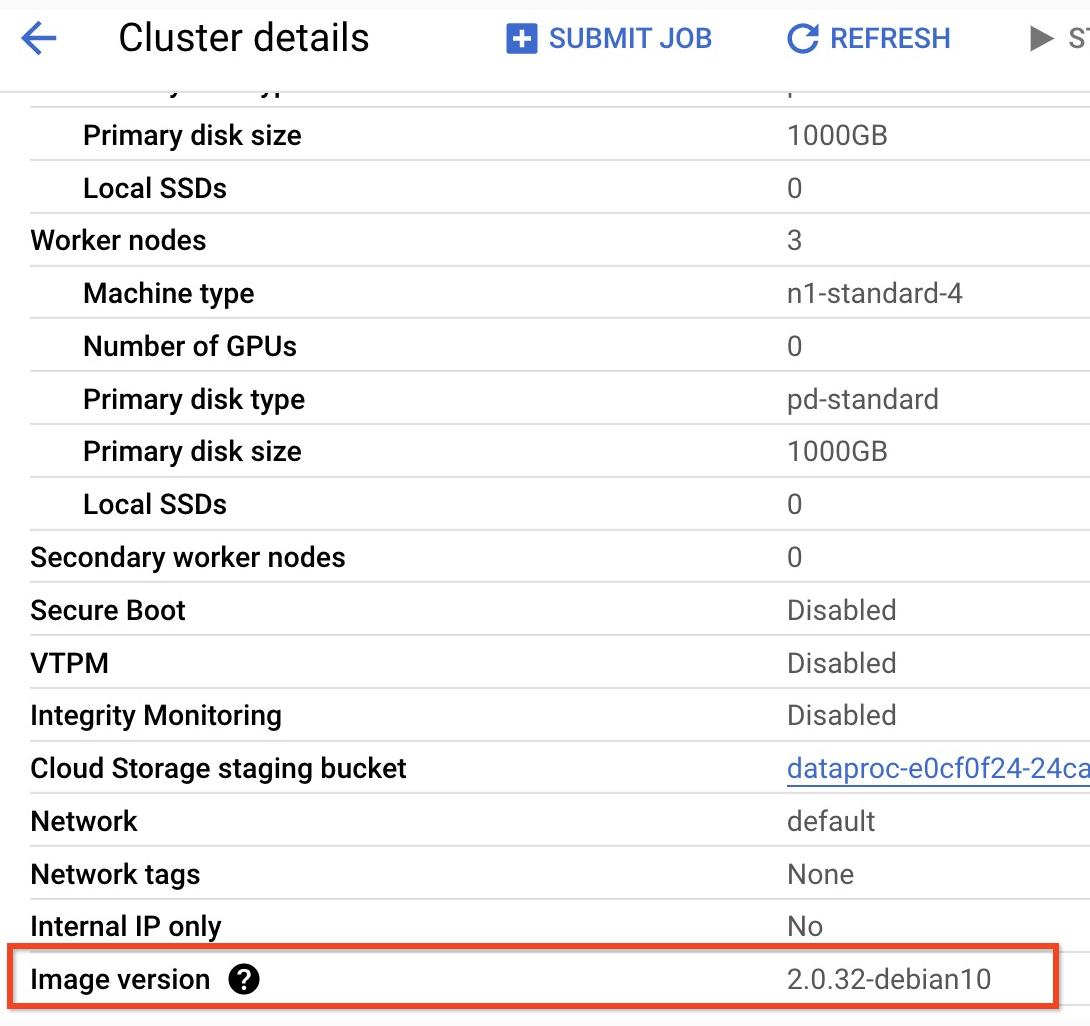
- Untuk menemukan versi subminor cluster versi image 2.0 Anda, klik nama cluster di halaman
Clusters di konsolGoogle Cloud untuk membuka halaman Cluster details, tempat Image version cluster dicantumkan.
- Atau, Anda dapat menjalankan perintah berikut di
terminal sesi SSH
dari node master cluster untuk menentukan versi komponen:
- Periksa versi scala:
scala -version
- Periksa versi Spark (control-D untuk keluar):
spark-shell
- Periksa versi HBase:
hbase version
- Identifikasi dependensi versi Spark, Scala, dan HBase
di Maven
pom.xml:<properties> <scala.version>scala full version (for example, 2.12.14)</scala.version> <scala.main.version>scala main version (for example, 2.12)</scala.main.version> <spark.version>spark version (for example, 3.1.2)</spark.version> <hbase.client.version>hbase version (for example, 2.2.7)</hbase.client.version> <hbase-spark.version>1.0.0(the current Apache HBase Spark Connector version)> </properties>
hbase-spark.versionadalah versi konektor Spark HBase saat ini; biarkan nomor versi ini tidak berubah.
- Periksa versi scala:
- Edit file
pom.xmldi editor Cloud Shell untuk memasukkan nomor versi Scala, Spark, dan HBase yang benar. Klik Open Terminal setelah Anda selesai mengedit untuk kembali ke command line terminal Cloud Shell.cloudshell edit .
- Beralih ke Java 8 di Cloud Shell. Versi JDK ini diperlukan untuk
membangun kode (Anda dapat mengabaikan pesan peringatan plugin):
sudo update-java-alternatives -s java-1.8.0-openjdk-amd64 && export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
- Verifikasi penginstalan Java 8:
java -version
openjdk version "1.8..."
- Halaman versi rilis 2.0.x Dataproc mencantumkan versi komponen Scala, Spark, dan HBase yang diinstal dengan versi subminor 2.0 image terbaru dan empat versi terakhir.
- Buat file
jar:mvn clean package
.jarditempatkan di subdirektori/target(misalnya,target/spark-hbase-1.0-SNAPSHOT.jar. Kirim tugas.
gcloud dataproc jobs submit spark \ --class=hbase.SparkHBaseMain \ --jars=target/filename.jar \ --region=cluster-region \ --cluster=cluster-name
--jars: Masukkan nama file.jarAnda setelah "target/" dan sebelum ".jar".- Jika Anda tidak menetapkan classpath HBase driver dan executor Spark saat
membuat cluster,
Anda harus menetapkannya dengan setiap pengiriman tugas dengan menyertakan
flag
‑‑propertiesberikut dalam perintah pengiriman tugas:--properties='spark.driver.extraClassPath=/etc/hbase/conf:/usr/lib/hbase/*,spark.executor.extraClassPath=/etc/hbase/conf:/usr/lib/hbase/*'
Lihat output tabel HBase di output terminal sesi Cloud Shell:
Waiting for job output... ... +----+----+ | key|name| +----+----+ |key1| foo| |key2| bar| +----+----+
Kirim tugas.
gcloud dataproc jobs submit pyspark scripts/pyspark-hbase.py \ --region=cluster-region \ --cluster=cluster-name
- Jika Anda tidak menetapkan classpath HBase driver dan executor Spark saat
membuat cluster,
Anda harus menetapkannya dengan setiap pengiriman tugas dengan menyertakan
flag
‑‑propertiesberikut dalam perintah pengiriman tugas:--properties='spark.driver.extraClassPath=/etc/hbase/conf:/usr/lib/hbase/*,spark.executor.extraClassPath=/etc/hbase/conf:/usr/lib/hbase/*'
- Jika Anda tidak menetapkan classpath HBase driver dan executor Spark saat
membuat cluster,
Anda harus menetapkannya dengan setiap pengiriman tugas dengan menyertakan
flag
Lihat output tabel HBase di output terminal sesi Cloud Shell:
Waiting for job output... ... +----+----+ | key|name| +----+----+ |key1| foo| |key2| bar| +----+----+
- Buka shell HBase:
hbase shell
- Pindai 'my-table':
scan 'my_table'
ROW COLUMN+CELL key1 column=cf:name, timestamp=1647364013561, value=foo key2 column=cf:name, timestamp=1647364012817, value=bar 2 row(s) Took 0.5009 seconds
Pembersihan
Setelah menyelesaikan tutorial, Anda dapat membersihkan resource yang dibuat agar resource tersebut berhenti menggunakan kuota dan dikenai biaya. Bagian berikut menjelaskan cara menghapus atau menonaktifkan resource ini.
Menghapus project
Cara termudah untuk menghilangkan penagihan adalah dengan menghapus project yang Anda buat untuk tutorial.
Untuk menghapus project:
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Menghapus cluster
- Untuk menghapus cluster Anda:
gcloud dataproc clusters delete cluster-name \ --region=${REGION}
Membuat cluster Dataproc
gcloud dataproc clusters create cluster-name \ --region=region \ --optional-components=HBASE,ZOOKEEPER \ --num-workers=3 \ --enable-component-gateway \ --image-version=2.0 \ --properties='spark:spark.driver.extraClassPath=/etc/hbase/conf:/usr/lib/hbase/*,spark:spark.executor.extraClassPath=/etc/hbase/conf:/usr/lib/hbase/*'
Memverifikasi penginstalan konektor
Membuat tabel HBase
Jalankan perintah yang tercantum di bagian ini di terminal sesi SSH node master yang Anda buka pada langkah sebelumnya.
Melihat kode Spark
Java
Python
Menjalankan kode
Java
Python
Memindai tabel HBase
Anda dapat memindai konten tabel HBase dengan menjalankan perintah berikut di terminal sesi SSH node master yang Anda buka di Verifikasi penginstalan konektor: