Penginstalan komponen HBase opsional terbatas pada cluster Dataproc yang dibuat dengan versi image 1.5 atau 2.0.
Meskipun Google Cloud menyediakan banyak layanan yang memungkinkan Anda men-deploy Apache HBase yang dikelola sendiri, Bigtable sering kali menjadi opsi terbaik karena menyediakan API terbuka dengan portabilitas beban kerja dan HBase. Tabel database HBase dapat dimigrasikan ke Bigtable untuk pengelolaan data pokok, sementara aplikasi yang sebelumnya beroperasi dengan HBase, seperti Spark, dapat tetap berada di Dataproc dan terhubung dengan aman ke Bigtable. Dalam panduan ini, kami memberikan langkah-langkah tingkat tinggi untuk mulai menggunakan Bigtable dan memberikan referensi untuk memigrasikan data ke Bigtable dari deployment Dataproc HBase.
Mulai menggunakan Bigtable
Cloud Bigtable adalah platform NoSQL berperforma tinggi dan sangat skalabel yang menyediakan kompatibilitas dan portabilitas klien API Apache HBase untuk beban kerja HBase. Klien ini kompatibel dengan HBase API versi 1.x dan 2.x serta dapat disertakan dengan aplikasi yang ada untuk membaca dan menulis ke Bigtable. Aplikasi HBase yang ada dapat menambahkan library klien HBase Bigtable untuk membaca dan menulis data yang disimpan di Bigtable.
Lihat Bigtable dan HBase API untuk mengetahui informasi selengkapnya tentang cara mengonfigurasi aplikasi HBase dengan Bigtable.
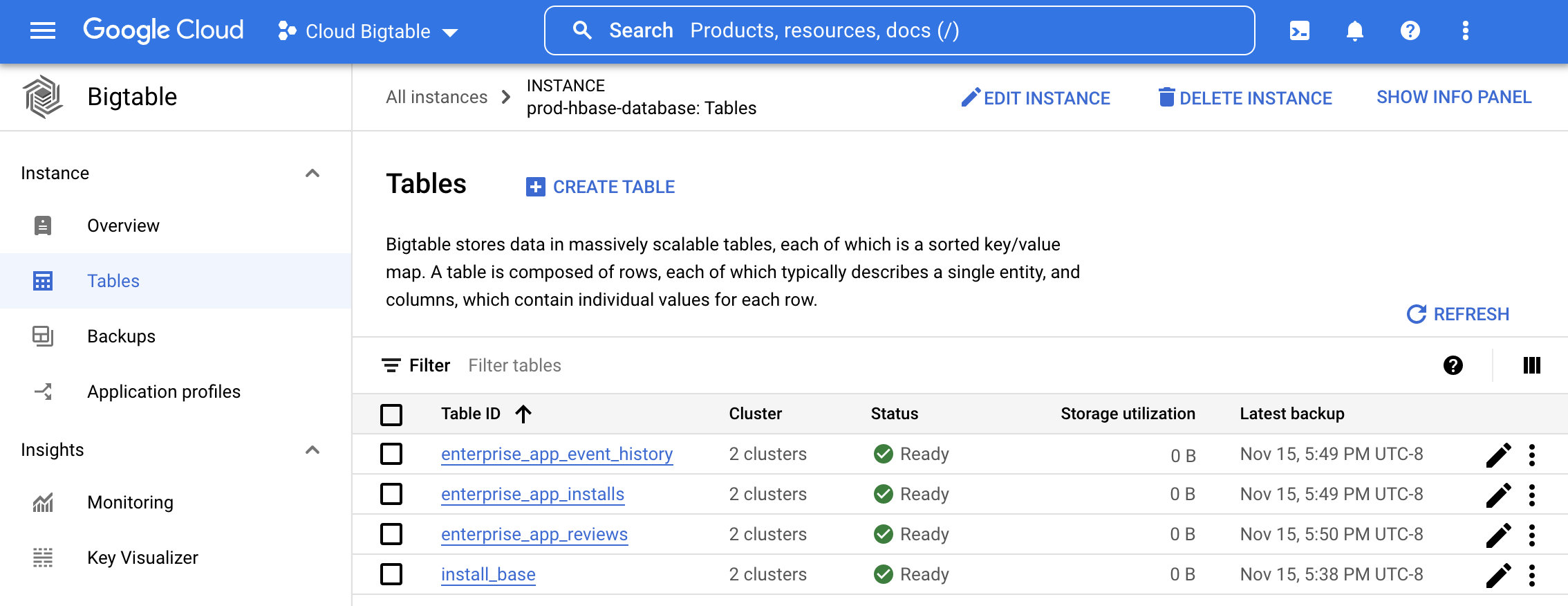
Membuat cluster Bigtable
Anda dapat mulai menggunakan Bigtable dengan membuat cluster dan tabel untuk menyimpan data yang sebelumnya disimpan di HBase. Ikuti langkah-langkah dalam dokumentasi Bigtable untuk membuat instance, cluster, dan tabel dengan skema yang sama seperti tabel HBase. Untuk pembuatan tabel otomatis dari DDL tabel HBase, lihat alat penerjemah skema.
Buka instance Bigtable di konsol untuk melihat tabel dan diagram pemantauan sisi server, termasuk baris per detik, latensi, dan throughput, untuk mengelola tabel yang baru disediakan. Google Cloud Untuk mengetahui informasi tambahan, lihat Pemantauan.
Memigrasikan data dari Dataproc ke Bigtable
Setelah membuat tabel di Bigtable, Anda dapat mengimpor dan memvalidasi data dengan mengikuti panduan di Memigrasikan HBase di Google Cloud ke Bigtable. Setelah memigrasikan data, Anda dapat memperbarui aplikasi untuk mengirim operasi baca dan tulis ke Bigtable.
Langkah berikutnya
- Lihat Contoh Wordcount Spark untuk menjalankan Spark dengan Bigtable.
- Tinjau opsi migrasi online dengan replikasi langsung dari HBase ke Bigtable.
- Tonton video Cara Box memodernisasi database NoSQL-nya untuk memahami manfaat lainnya.