데이터 과학자는 Apache Spark용 BigQuery 커넥터를 사용하여 BigQuery의 원활하게 확장 가능한 SQL 엔진의 이점을 Apache Spark의 머신러닝 기능과 통합할 수 있습니다. 이 튜토리얼에서는 Dataproc, BigQuery, Apache Spark ML을 사용하여 데이터 세트에서 머신러닝을 수행하는 방법에 대해 설명합니다.
목표
선형 회귀를 사용하면 다음 5개 요인에 대한 함수로 출생 시 체중 모델을 구축할 수 있습니다.- 임신 주수
- 산모 연령
- 부체의 연령
- 임신 기간 동안 산모의 체중 증가
- Apgar 점수
다음 도구를 사용하세요.
- BigQuery: Google Cloud 프로젝트에 기록되는 선형 회귀 입력 테이블을 준비하는 데 사용합니다.
- Python: BigQuery에서 데이터를 쿼리하고 관리하는 데 사용합니다.
- Apache Spark: 결과 선형 회귀 테이블에 액세스하는 데 사용합니다.
- Spark ML: 모델을 구축하고 평가하는 데 사용합니다.
- Spark PySpark 작업: Spark ML 함수를 호출하는 데 사용됩니다.
비용
이 문서에서는 비용이 청구될 수 있는 Google Cloud구성요소( )를 사용합니다.
- Compute Engine
- Dataproc
- BigQuery
프로젝트 사용량을 기준으로 예상 비용을 산출하려면 가격 계산기를 사용합니다.
시작하기 전에
Dataproc 클러스터에는 Spark 구성요소(Spark ML 포함)가 설치되어 있습니다. 이 예에서 Dataproc 클러스터를 설정하고 코드를 실행하려면 다음을 수행해야 합니다.
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Enable the Dataproc, BigQuery, Compute Engine APIs.
-
Install the Google Cloud CLI.
-
외부 ID 공급업체(IdP)를 사용하는 경우 먼저 제휴 ID로 gcloud CLI에 로그인해야 합니다.
-
gcloud CLI를 초기화하려면 다음 명령어를 실행합니다.
gcloud init -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Enable the Dataproc, BigQuery, Compute Engine APIs.
-
Install the Google Cloud CLI.
-
외부 ID 공급업체(IdP)를 사용하는 경우 먼저 제휴 ID로 gcloud CLI에 로그인해야 합니다.
-
gcloud CLI를 초기화하려면 다음 명령어를 실행합니다.
gcloud init - 프로젝트에서 Dataproc 클러스터를 만듭니다. 클러스터는 Spark 2.0 이상을 갖춘 Dataproc 버전을 실행해야 합니다(머신러닝 라이브러리 포함).
프로젝트에서 데이터세트를 만듭니다.
- BigQuery 웹 UI로 이동합니다.
- 왼쪽 탐색 창에서 프로젝트 이름을 클릭한 다음 데이터 세트 만들기를 클릭합니다.
- 데이터 세트 만들기 대화상자에서 다음을 수행합니다.
- 데이터 세트 ID에 'natality_regression'을 입력합니다.
- 데이터 위치에서 데이터 세트의 위치를 선택할 수 있습니다. 기본값 위치는
US multi-region입니다. 데이터 세트를 만든 후에는 위치를 변경할 수 없습니다. - 기본 테이블 만료 시간에서 다음 옵션 중 하나를 선택합니다.
- 사용 안 함(기본값): 테이블을 수동으로 삭제해야 합니다.
- 일수: 테이블이 생성 시간으로부터 지정된 일 수가 지난 후에 삭제됩니다.
- 암호화에서 다음 옵션 중 하나를 선택합니다.
- Google-owned and Google-managed encryption key(기본값).
- 고객 관리 키: Cloud KMS 키로 데이터 보호를 참조하세요.
- 데이터 세트 만들기를 클릭합니다.
공개 출생률 데이터 세트에 대해 쿼리를 실행한 후에 쿼리 결과를 데이터 세트의 새 테이블에 저장합니다.
- 다음 쿼리를 복사하여 쿼리 편집기에 붙여넣은 후에 실행을 클릭합니다.
CREATE OR REPLACE TABLE natality_regression.regression_input as SELECT weight_pounds, mother_age, father_age, gestation_weeks, weight_gain_pounds, apgar_5min FROM `bigquery-public-data.samples.natality` WHERE weight_pounds IS NOT NULL AND mother_age IS NOT NULL AND father_age IS NOT NULL AND gestation_weeks IS NOT NULL AND weight_gain_pounds IS NOT NULL AND apgar_5min IS NOT NULL
- (약 1분 후) 쿼리가 완료되면 결과가 프로젝트의
natality_regression데이터 세트에 "regression_input" BigQuery 테이블로 저장됩니다.
- 다음 쿼리를 복사하여 쿼리 편집기에 붙여넣은 후에 실행을 클릭합니다.
Python과 Python용 Google Cloud 클라이언트 라이브러리(코드를 실행하는 데 필요함)를 설치하는 방법은 Python 개발 환경 설정을 참조합니다. Python
virtualenv를 설치하고 사용하는 것이 좋습니다.아래의
natality_tutorial.py코드를 복사하여 로컬 머신의python셸에 붙여넣습니다. 셸에 있는<return>키를 눌러 코드를 실행함으로써 기본Google Cloud 프로젝트에서 'natality_regression' BigQuery 데이터 세트를 만들고, 'regression_input' 테이블이 공개natality데이터의 하위 집합으로 채워지도록 합니다.natality_regression데이터 세트와regression_input테이블이 만들어졌는지 확인합니다.
다음 코드를 복사하여 로컬 머신의 새
natality_sparkml.py파일에 붙여넣습니다."""Run a linear regression using Apache Spark ML. In the following PySpark (Spark Python API) code, we take the following actions: * Load a previously created linear regression (BigQuery) input table into our Cloud Dataproc Spark cluster as an RDD (Resilient Distributed Dataset) * Transform the RDD into a Spark Dataframe * Vectorize the features on which the model will be trained * Compute a linear regression using Spark ML """ from pyspark.context import SparkContext from pyspark.ml.linalg import Vectors from pyspark.ml.regression import LinearRegression from pyspark.sql.session import SparkSession # The imports, above, allow us to access SparkML features specific to linear # regression as well as the Vectors types. # Define a function that collects the features of interest # (mother_age, father_age, and gestation_weeks) into a vector. # Package the vector in a tuple containing the label (`weight_pounds`) for that # row. def vector_from_inputs(r): return (r["weight_pounds"], Vectors.dense(float(r["mother_age"]), float(r["father_age"]), float(r["gestation_weeks"]), float(r["weight_gain_pounds"]), float(r["apgar_5min"]))) sc = SparkContext() spark = SparkSession(sc) # Read the data from BigQuery as a Spark Dataframe. natality_data = spark.read.format("bigquery").option( "table", "natality_regression.regression_input").load() # Create a view so that Spark SQL queries can be run against the data. natality_data.createOrReplaceTempView("natality") # As a precaution, run a query in Spark SQL to ensure no NULL values exist. sql_query = """ SELECT * from natality where weight_pounds is not null and mother_age is not null and father_age is not null and gestation_weeks is not null """ clean_data = spark.sql(sql_query) # Create an input DataFrame for Spark ML using the above function. training_data = clean_data.rdd.map(vector_from_inputs).toDF(["label", "features"]) training_data.cache() # Construct a new LinearRegression object and fit the training data. lr = LinearRegression(maxIter=5, regParam=0.2, solver="normal") model = lr.fit(training_data) # Print the model summary. print("Coefficients:" + str(model.coefficients)) print("Intercept:" + str(model.intercept)) print("R^2:" + str(model.summary.r2)) model.summary.residuals.show()
로컬
natality_sparkml.py파일을 프로젝트의 Cloud Storage 버킷에 복사합니다.gcloud storage cp natality_sparkml.py gs://bucket-name
Dataproc 작업 제출 페이지에서 회귀를 실행합니다.
기본 python 파일 필드에
natality_sparkml.py파일의 사본이 있는 Cloud Storage 버킷의gs://URI를 입력합니다.작업 유형으로
PySpark를 선택합니다.JAR 파일필드에
gs://spark-lib/bigquery/spark-bigquery-latest_2.12.jar을 입력합니다. 이렇게 하면 BigQuery 데이터를 Spark DataFrame으로 읽을 수 있도록 런타임 시 PySpark 애플리케이션에서 Spark-bigquery 커넥터를 사용할 수 있습니다.작업 ID, 리전, 클러스터 필드를 입력합니다.
제출을 클릭하여 클러스터에서 작업을 실행합니다.
다음 코드를 복사하여 로컬 머신의 새
natality_sparkml.py파일에 붙여넣습니다."""Run a linear regression using Apache Spark ML. In the following PySpark (Spark Python API) code, we take the following actions: * Load a previously created linear regression (BigQuery) input table into our Cloud Dataproc Spark cluster as an RDD (Resilient Distributed Dataset) * Transform the RDD into a Spark Dataframe * Vectorize the features on which the model will be trained * Compute a linear regression using Spark ML """ from pyspark.context import SparkContext from pyspark.ml.linalg import Vectors from pyspark.ml.regression import LinearRegression from pyspark.sql.session import SparkSession # The imports, above, allow us to access SparkML features specific to linear # regression as well as the Vectors types. # Define a function that collects the features of interest # (mother_age, father_age, and gestation_weeks) into a vector. # Package the vector in a tuple containing the label (`weight_pounds`) for that # row. def vector_from_inputs(r): return (r["weight_pounds"], Vectors.dense(float(r["mother_age"]), float(r["father_age"]), float(r["gestation_weeks"]), float(r["weight_gain_pounds"]), float(r["apgar_5min"]))) sc = SparkContext() spark = SparkSession(sc) # Read the data from BigQuery as a Spark Dataframe. natality_data = spark.read.format("bigquery").option( "table", "natality_regression.regression_input").load() # Create a view so that Spark SQL queries can be run against the data. natality_data.createOrReplaceTempView("natality") # As a precaution, run a query in Spark SQL to ensure no NULL values exist. sql_query = """ SELECT * from natality where weight_pounds is not null and mother_age is not null and father_age is not null and gestation_weeks is not null """ clean_data = spark.sql(sql_query) # Create an input DataFrame for Spark ML using the above function. training_data = clean_data.rdd.map(vector_from_inputs).toDF(["label", "features"]) training_data.cache() # Construct a new LinearRegression object and fit the training data. lr = LinearRegression(maxIter=5, regParam=0.2, solver="normal") model = lr.fit(training_data) # Print the model summary. print("Coefficients:" + str(model.coefficients)) print("Intercept:" + str(model.intercept)) print("R^2:" + str(model.summary.r2)) model.summary.residuals.show()
로컬
natality_sparkml.py파일을 프로젝트의 Cloud Storage 버킷에 복사합니다.gcloud storage cp natality_sparkml.py gs://bucket-name
아래와 같이 로컬 머신의 터미널 창에서
gcloud명령어를 실행하여 Pyspark 작업을 Dataproc 서비스에 제출합니다.- - jars 플래그 값은 BigQuery 데이터를 Spark DataFrame으로 읽을 수 있도록 런타임 시 PySpark jobv에서 Spark-bigquery 커넥터를 사용할 수 있도록 합니다.
gcloud dataproc jobs submit pyspark \ gs://your-bucket/natality_sparkml.py \ --cluster=cluster-name \ --region=region \ --jars=gs://spark-lib/bigquery/spark-bigquery-with-dependencies_SCALA_VERSION-CONNECTOR_VERSION.jar
- - jars 플래그 값은 BigQuery 데이터를 Spark DataFrame으로 읽을 수 있도록 런타임 시 PySpark jobv에서 Spark-bigquery 커넥터를 사용할 수 있도록 합니다.
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
- Spark 작업 미세 조정 팁 참고하기
BigQuery natality 데이터 하위 집합 만들기
이 섹션에서는 프로젝트에서 데이터세트를 만든 후에, 공개적으로 사용 가능한 natality BigQuery 데이터세트의 출생 비율 데이터 하위 집합을 복사할 테이블을 데이터세트 안에 만듭니다. 이 튜토리얼의 뒷부분에서는 이 테이블에 있는 하위 집합 데이터를 사용하여 모친 연령, 부친 연령, 임신 주수를 기준으로 출생 시 체중을 예측할 것입니다.
Google Cloud 콘솔을 사용하거나 로컬 머신에서 Python 스크립트를 실행하여 데이터 하위 집합을 만들 수 있습니다.
콘솔
Python
이 샘플을 사용해 보기 전에 클라이언트 라이브러리 사용한 Dataproc 빠른 시작의 Python 설정 안내를 따르세요. 자세한 내용은 Dataproc Python API 참고 문서를 참조하세요.
Dataproc에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 로컬 개발 환경의 인증 설정을 참조하세요.
선형 회귀 실행
이 섹션에서 Google Cloud 콘솔을 사용하여 작업을 Dataproc 서비스에 제출하거나 로컬 터미널에서 gcloud 명령어를 실행하여 PySpark 선형 회귀를 실행합니다.
콘솔
작업이 완료되면 Dataproc 작업 세부정보 창에 선형 회귀 출력 모델 요약이 나타납니다.
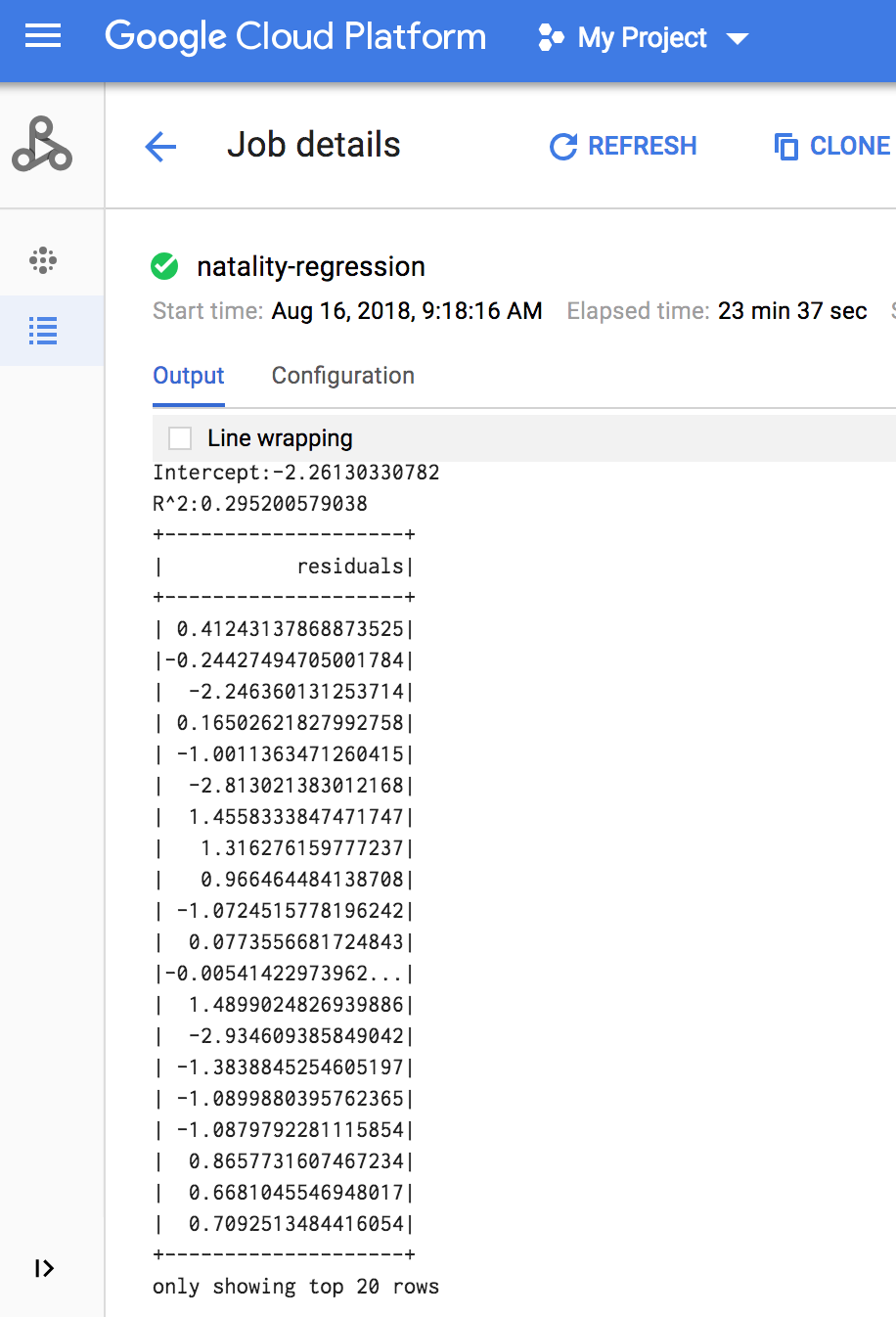
gcloud
작업이 완료되면 선형 회귀 출력(모델 요약)이 터미널 창에 나타납니다.
<<< # Print the model summary. ... print "Coefficients:" + str(model.coefficients) Coefficients:[0.0166657454602,-0.00296751984046,0.235714392936,0.00213002070133,-0.00048577251587] <<< print "Intercept:" + str(model.intercept) Intercept:-2.26130330748 <<< print "R^2:" + str(model.summary.r2) R^2:0.295200579035 <<< model.summary.residuals.show() +--------------------+ | residuals| +--------------------+ | -0.7234737533344147| | -0.985466980630501| | -0.6669710598385468| | 1.4162434829714794| |-0.09373154375186754| |-0.15461747949235072| | 0.32659061654192545| | 1.5053877697929803| | -0.640142797263989| | 1.229530260294963| |-0.03776160295256...| | -0.5160734239126814| | -1.5165972740062887| | 1.3269085258245008| | 1.7604670124710626| | 1.2348130901905972| | 2.318660276655887| | 1.0936947030883175| | 1.0169768511417363| | -1.7744915698181583| +--------------------+ only showing top 20 rows.
Clean up
After you finish the tutorial, you can clean up the resources that you created so that they stop using quota and incurring charges. The following sections describe how to delete or turn off these resources.
Delete the project
The easiest way to eliminate billing is to delete the project that you created for the tutorial.
To delete the project:
Dataproc 클러스터 삭제
클러스터 삭제를 참조하세요.