El conector de BigQuery para Apache Spark permite a los científicos de datos combinar la potencia del motor SQL de BigQuery, que se puede escalar sin problemas, con las funciones de aprendizaje automático de Apache Spark. En este tutorial, se muestra cómo usar Dataproc, BigQuery y Apache Spark ML para realizar aprendizaje automático en un conjunto de datos.
Objetivos
Usa la regresión lineal para crear un modelo del peso al nacer en función de cinco factores:- semanas de gestación
- Edad de la madre
- Edad del padre
- Aumento de peso de la madre durante el embarazo
- Puntuación de Apgar
Usa las siguientes herramientas:
- BigQuery, para preparar la tabla de entrada de regresión lineal, que se escribe en tu proyecto Google Cloud
- Python para consultar y gestionar datos en BigQuery
- Apache Spark para acceder a la tabla de regresión lineal resultante
- Spark ML para crear y evaluar el modelo
- Tarea de PySpark de Dataproc para invocar funciones de Spark ML
Costes
En este documento, se utilizan los siguientes componentes facturables de Google Cloud:
- Compute Engine
- Dataproc
- BigQuery
Para generar una estimación de costes basada en el uso previsto,
utiliza la calculadora de precios.
Antes de empezar
Un clúster de Dataproc tiene instalados los componentes de Spark, incluido Spark ML. Para configurar un clúster de Dataproc y ejecutar el código de este ejemplo, debes hacer lo siguiente:
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Enable the Dataproc, BigQuery, Compute Engine APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Install the Google Cloud CLI.
-
Si utilizas un proveedor de identidades (IdP) externo, primero debes iniciar sesión en la CLI de gcloud con tu identidad federada.
-
Para inicializar gcloud CLI, ejecuta el siguiente comando:
gcloud init -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Enable the Dataproc, BigQuery, Compute Engine APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Install the Google Cloud CLI.
-
Si utilizas un proveedor de identidades (IdP) externo, primero debes iniciar sesión en la CLI de gcloud con tu identidad federada.
-
Para inicializar gcloud CLI, ejecuta el siguiente comando:
gcloud init - Crea un clúster de Dataproc en tu proyecto. Tu clúster debe ejecutar una versión de Dataproc con Spark 2.0 o una versión posterior (incluidas las bibliotecas de aprendizaje automático).
Crea un conjunto de datos en tu proyecto.
- Ve a la interfaz web de BigQuery.
- En el panel de navegación de la izquierda, haga clic en el nombre de su proyecto y, a continuación, en CREATE DATASET (CREAR CONJUNTO DE DATOS).
- En el cuadro de diálogo Crear conjunto de datos, haz lo siguiente:
- En ID del conjunto de datos, introduce "natality_regression".
- En Ubicación de los datos, puedes elegir una ubicación para el conjunto de datos. La ubicación predeterminada es
US multi-region. Una vez creado el conjunto de datos, la ubicación no se puede cambiar. - En Vencimiento predeterminado de la tabla, elija una de las siguientes opciones:
- Nunca (opción predeterminada): debes eliminar la tabla manualmente.
- Número de días: la tabla se eliminará transcurrido el número de días especificado desde su creación.
- En Cifrado, elija una de las siguientes opciones:
- Google-owned and Google-managed encryption key (predeterminado).
- Clave gestionada por el cliente: consulta Proteger datos con claves de Cloud KMS.
- Haz clic en Crear conjunto de datos.
Ejecuta una consulta en el conjunto de datos público de natalidad y, a continuación, guarda los resultados de la consulta en una tabla nueva de tu conjunto de datos.
- Copia y pega la siguiente consulta en el editor de consultas y, a continuación, haz clic en Ejecutar.
CREATE OR REPLACE TABLE natality_regression.regression_input as SELECT weight_pounds, mother_age, father_age, gestation_weeks, weight_gain_pounds, apgar_5min FROM `bigquery-public-data.samples.natality` WHERE weight_pounds IS NOT NULL AND mother_age IS NOT NULL AND father_age IS NOT NULL AND gestation_weeks IS NOT NULL AND weight_gain_pounds IS NOT NULL AND apgar_5min IS NOT NULL
- Una vez completada la consulta (en aproximadamente un minuto), los resultados se guardarán como tabla de BigQuery "regression_input" en el conjunto de datos
natality_regressionde tu proyecto.
- Copia y pega la siguiente consulta en el editor de consultas y, a continuación, haz clic en Ejecutar.
Consulta las instrucciones para instalar Python y la biblioteca de cliente de Google Cloud para Python (necesaria para ejecutar el código) en la sección Configurar un entorno de desarrollo de Python. Se recomienda instalar y usar un Python
virtualenv.Copie y pegue el código
natality_tutorial.pyque aparece más abajo en un shellpythonde su máquina local. Pulsa la tecla<return>en el shell para ejecutar el código y crear un conjunto de datos de BigQuery "natality_regression" en tu proyectoGoogle Cloud predeterminado con una tabla "regression_input" que se rellena con un subconjunto de los datos públicos denatality.Confirma la creación del conjunto de datos
natality_regressiony de la tablaregression_input.
Copia y pega el siguiente código en un archivo
natality_sparkml.pynuevo de tu máquina local."""Run a linear regression using Apache Spark ML. In the following PySpark (Spark Python API) code, we take the following actions: * Load a previously created linear regression (BigQuery) input table into our Cloud Dataproc Spark cluster as an RDD (Resilient Distributed Dataset) * Transform the RDD into a Spark Dataframe * Vectorize the features on which the model will be trained * Compute a linear regression using Spark ML """ from pyspark.context import SparkContext from pyspark.ml.linalg import Vectors from pyspark.ml.regression import LinearRegression from pyspark.sql.session import SparkSession # The imports, above, allow us to access SparkML features specific to linear # regression as well as the Vectors types. # Define a function that collects the features of interest # (mother_age, father_age, and gestation_weeks) into a vector. # Package the vector in a tuple containing the label (`weight_pounds`) for that # row. def vector_from_inputs(r): return (r["weight_pounds"], Vectors.dense(float(r["mother_age"]), float(r["father_age"]), float(r["gestation_weeks"]), float(r["weight_gain_pounds"]), float(r["apgar_5min"]))) sc = SparkContext() spark = SparkSession(sc) # Read the data from BigQuery as a Spark Dataframe. natality_data = spark.read.format("bigquery").option( "table", "natality_regression.regression_input").load() # Create a view so that Spark SQL queries can be run against the data. natality_data.createOrReplaceTempView("natality") # As a precaution, run a query in Spark SQL to ensure no NULL values exist. sql_query = """ SELECT * from natality where weight_pounds is not null and mother_age is not null and father_age is not null and gestation_weeks is not null """ clean_data = spark.sql(sql_query) # Create an input DataFrame for Spark ML using the above function. training_data = clean_data.rdd.map(vector_from_inputs).toDF(["label", "features"]) training_data.cache() # Construct a new LinearRegression object and fit the training data. lr = LinearRegression(maxIter=5, regParam=0.2, solver="normal") model = lr.fit(training_data) # Print the model summary. print("Coefficients:" + str(model.coefficients)) print("Intercept:" + str(model.intercept)) print("R^2:" + str(model.summary.r2)) model.summary.residuals.show()
Copia el archivo
natality_sparkml.pylocal en un segmento de Cloud Storage de tu proyecto.gcloud storage cp natality_sparkml.py gs://bucket-name
Ejecuta la regresión desde la página Enviar una tarea de Dataproc.
En el campo Archivo principal de Python, inserta el
gs://URI del segmento de Cloud Storage en el que se encuentra tu copia del archivonatality_sparkml.py.Selecciona
PySparkcomo Tipo de trabajo.Inserta
gs://spark-lib/bigquery/spark-bigquery-latest_2.12.jaren el campo Archivos JAR. De esta forma, el conector spark-bigquery-connector estará disponible para la aplicación PySpark en el tiempo de ejecución, lo que le permitirá leer datos de BigQuery en un DataFrame de Spark.Rellena los campos ID de trabajo, Región y Clúster.
Haz clic en Enviar para ejecutar el trabajo en tu clúster.
Copia y pega el siguiente código en un archivo
natality_sparkml.pynuevo de tu máquina local."""Run a linear regression using Apache Spark ML. In the following PySpark (Spark Python API) code, we take the following actions: * Load a previously created linear regression (BigQuery) input table into our Cloud Dataproc Spark cluster as an RDD (Resilient Distributed Dataset) * Transform the RDD into a Spark Dataframe * Vectorize the features on which the model will be trained * Compute a linear regression using Spark ML """ from pyspark.context import SparkContext from pyspark.ml.linalg import Vectors from pyspark.ml.regression import LinearRegression from pyspark.sql.session import SparkSession # The imports, above, allow us to access SparkML features specific to linear # regression as well as the Vectors types. # Define a function that collects the features of interest # (mother_age, father_age, and gestation_weeks) into a vector. # Package the vector in a tuple containing the label (`weight_pounds`) for that # row. def vector_from_inputs(r): return (r["weight_pounds"], Vectors.dense(float(r["mother_age"]), float(r["father_age"]), float(r["gestation_weeks"]), float(r["weight_gain_pounds"]), float(r["apgar_5min"]))) sc = SparkContext() spark = SparkSession(sc) # Read the data from BigQuery as a Spark Dataframe. natality_data = spark.read.format("bigquery").option( "table", "natality_regression.regression_input").load() # Create a view so that Spark SQL queries can be run against the data. natality_data.createOrReplaceTempView("natality") # As a precaution, run a query in Spark SQL to ensure no NULL values exist. sql_query = """ SELECT * from natality where weight_pounds is not null and mother_age is not null and father_age is not null and gestation_weeks is not null """ clean_data = spark.sql(sql_query) # Create an input DataFrame for Spark ML using the above function. training_data = clean_data.rdd.map(vector_from_inputs).toDF(["label", "features"]) training_data.cache() # Construct a new LinearRegression object and fit the training data. lr = LinearRegression(maxIter=5, regParam=0.2, solver="normal") model = lr.fit(training_data) # Print the model summary. print("Coefficients:" + str(model.coefficients)) print("Intercept:" + str(model.intercept)) print("R^2:" + str(model.summary.r2)) model.summary.residuals.show()
Copia el archivo
natality_sparkml.pylocal en un segmento de Cloud Storage de tu proyecto.gcloud storage cp natality_sparkml.py gs://bucket-name
Envía la tarea de Pyspark al servicio Dataproc ejecutando el comando
gcloud, que se muestra a continuación, desde una ventana de terminal de tu máquina local.- El valor de la marca --jars hace que el conector spark-bigquery esté disponible para el trabajo de PySpark en el tiempo de ejecución, lo que le permite leer datos de BigQuery en un DataFrame de Spark.
gcloud dataproc jobs submit pyspark \ gs://your-bucket/natality_sparkml.py \ --cluster=cluster-name \ --region=region \ --jars=gs://spark-lib/bigquery/spark-bigquery-with-dependencies_SCALA_VERSION-CONNECTOR_VERSION.jar
- El valor de la marca --jars hace que el conector spark-bigquery esté disponible para el trabajo de PySpark en el tiempo de ejecución, lo que le permite leer datos de BigQuery en un DataFrame de Spark.
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
- Consulta los consejos para ajustar las tareas de Spark.
Crear un subconjunto de datos de natalidad de BigQuery
En esta sección, crearás un conjunto de datos en tu proyecto y, a continuación, una tabla en el conjunto de datos en la que copiarás un subconjunto de datos de natalidad del conjunto de datos de BigQuery público natality. Más adelante en este tutorial, utilizarás los datos del subconjunto de esta tabla para predecir el peso al nacer en función de la edad de la madre, la edad del padre y las semanas de gestación.
Puedes crear el subconjunto de datos con la Google Cloud consola o ejecutando una secuencia de comandos de Python en tu máquina local.
Consola
Python
Antes de probar este ejemplo, sigue las Python instrucciones de configuración de la guía de inicio rápido de Dataproc con bibliotecas de cliente. Para obtener más información, consulta la documentación de referencia de la API Python de Dataproc.
Para autenticarte en Dataproc, configura las credenciales predeterminadas de la aplicación. Para obtener más información, consulta el artículo Configurar la autenticación en un entorno de desarrollo local.
Ejecutar una regresión lineal
En esta sección, ejecutarás una regresión lineal de PySpark enviando el trabajo al servicio Dataproc mediante la Google Cloud consola
o ejecutando el comando gcloud desde una terminal local.
Consola
Cuando se complete la tarea, el resumen del modelo de salida de regresión lineal aparecerá en la ventana Detalles de la tarea de Dataproc.
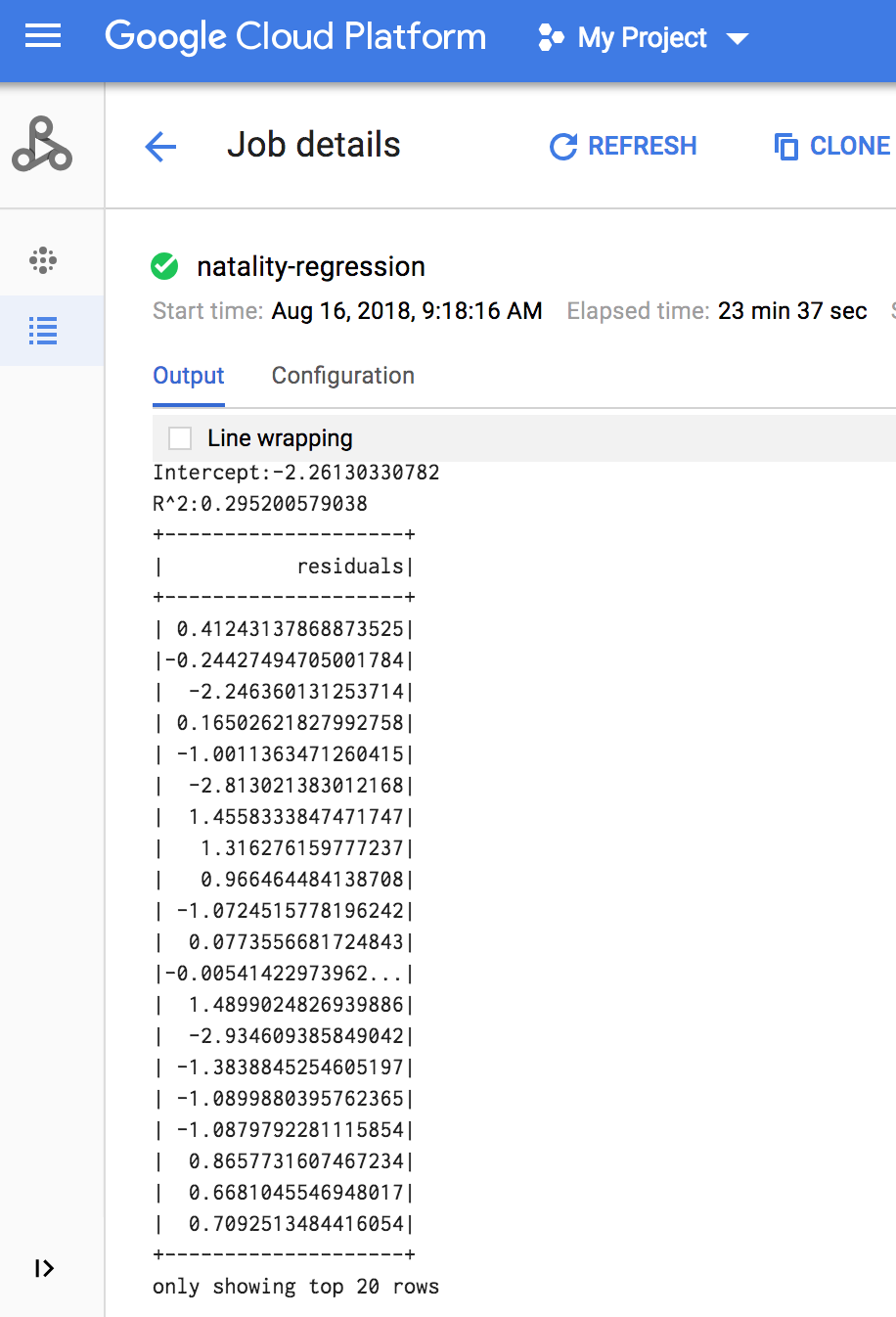
gcloud
La salida de la regresión lineal (resumen del modelo) aparece en la ventana del terminal cuando se completa la tarea.
<<< # Print the model summary. ... print "Coefficients:" + str(model.coefficients) Coefficients:[0.0166657454602,-0.00296751984046,0.235714392936,0.00213002070133,-0.00048577251587] <<< print "Intercept:" + str(model.intercept) Intercept:-2.26130330748 <<< print "R^2:" + str(model.summary.r2) R^2:0.295200579035 <<< model.summary.residuals.show() +--------------------+ | residuals| +--------------------+ | -0.7234737533344147| | -0.985466980630501| | -0.6669710598385468| | 1.4162434829714794| |-0.09373154375186754| |-0.15461747949235072| | 0.32659061654192545| | 1.5053877697929803| | -0.640142797263989| | 1.229530260294963| |-0.03776160295256...| | -0.5160734239126814| | -1.5165972740062887| | 1.3269085258245008| | 1.7604670124710626| | 1.2348130901905972| | 2.318660276655887| | 1.0936947030883175| | 1.0169768511417363| | -1.7744915698181583| +--------------------+ only showing top 20 rows.
Clean up
After you finish the tutorial, you can clean up the resources that you created so that they stop using quota and incurring charges. The following sections describe how to delete or turn off these resources.
Delete the project
The easiest way to eliminate billing is to delete the project that you created for the tutorial.
To delete the project:
Eliminar el clúster de Dataproc
Consulta Eliminar un clúster.