Un recurso NodeGroup de Dataproc es un grupo de nodos de clúster de Dataproc que ejecutan un rol asignado. En esta página se describe el grupo de nodos de controlador, que es un grupo de máquinas virtuales de Compute Engine a las que se les asigna el rol Driver para ejecutar controladores de trabajos en el clúster de Dataproc.
Cuándo usar grupos de nodos de controladores
- Usa grupos de nodos de controlador solo cuando necesites ejecutar muchos trabajos simultáneos en un clúster compartido.
- Aumenta los recursos del nodo maestro antes de usar grupos de nodos de controlador para evitar las limitaciones de los grupos de nodos de controlador.
Cómo ayudan los nodos de controlador a ejecutar trabajos simultáneos
Dataproc inicia un proceso de controlador de tareas en un nodo maestro de clúster de Dataproc para cada tarea. El proceso del controlador, a su vez, ejecuta un controlador de aplicación, como spark-submit, como su proceso secundario.
Sin embargo, el número de tareas simultáneas que se ejecutan en el maestro está limitado por los recursos disponibles en el nodo maestro. Como los nodos maestros de Dataproc no se pueden escalar, una tarea puede fallar o sufrir limitaciones cuando los recursos del nodo maestro no son suficientes para ejecutarla.
Los grupos de nodos de controlador son grupos de nodos especiales gestionados por YARN, por lo que la simultaneidad de las tareas no está limitada por los recursos del nodo maestro. En los clústeres con un grupo de nodos de controlador, los controladores de aplicaciones se ejecutan en los nodos de controlador. Cada nodo de controlador puede ejecutar varios controladores de aplicaciones si el nodo tiene suficientes recursos.
Ventajas
Si usas un clúster de Dataproc con un grupo de nodos de controlador, puedes hacer lo siguiente:
- Escalar horizontalmente los recursos del controlador de trabajos para ejecutar más trabajos simultáneos
- Escalar los recursos del controlador por separado de los recursos de los trabajadores
- Obtener una reducción de escala más rápida en clústeres de imágenes de Dataproc 2.0 y versiones posteriores. En estos clústeres, el maestro de la aplicación se ejecuta en un controlador de Spark en un grupo de nodos de controlador (el valor predeterminado de
spark.yarn.unmanagedAM.enabledestrue). - Personaliza el inicio del nodo de controlador. Puedes añadir
{ROLE} == 'Driver'en un script de inicialización para que el script realice acciones en un grupo de nodos de controlador en selección de nodos.
Limitaciones
- Los grupos de nodos no se admiten en las plantillas de flujo de trabajo de Dataproc.
- Los clústeres de grupos de nodos no se pueden detener, reiniciar ni escalar automáticamente.
- El maestro de aplicaciones MapReduce se ejecuta en nodos de trabajo. El escalado horizontal de los nodos de trabajo puede ser lento si habilitas la retirada gradual.
- La simultaneidad de los trabajos se ve afectada por la
dataproc:agent.process.threads.job.maxpropiedad de clúster. Por ejemplo, si hay tres maestros y esta propiedad tiene el valor predeterminado100, la simultaneidad máxima de trabajos a nivel de clúster es300.
Grupo de nodos de controlador en comparación con el modo de clúster de Spark
| Función | Modo de clúster de Spark | Grupo de nodos de controlador |
|---|---|---|
| Reducción de los nodos de trabajador | Los controladores de larga duración se ejecutan en los mismos nodos de trabajo que los contenedores de corta duración, lo que hace que el escalado horizontal de los trabajadores mediante la retirada gradual sea lento. | Los nodos de trabajador se reducen más rápido cuando los controladores se ejecutan en grupos de nodos. |
| Salida del controlador transmitida | Requiere buscar en los registros de YARN para encontrar el nodo en el que se ha programado el controlador. | La salida del controlador se transmite a Cloud Storage y se puede ver en la consola Google Cloud y en la salida del comando gcloud dataproc jobs wait una vez que se completa una tarea. |
Permisos de gestión de identidades y accesos de grupos de nodos de controladores
Los siguientes permisos de IAM están asociados a las acciones relacionadas con los grupos de nodos de Dataproc.
| Permiso | Acción |
|---|---|
dataproc.nodeGroups.create
|
Crea grupos de nodos de Dataproc. Si un usuario tiene el permiso dataproc.clusters.create en el proyecto, se le concederá este permiso. |
dataproc.nodeGroups.get |
Obtiene los detalles de un grupo de nodos de Dataproc. |
dataproc.nodeGroups.update |
Cambiar el tamaño de un grupo de nodos de Dataproc. |
Operaciones de grupos de nodos de controladores
Puedes usar la CLI de gcloud y la API de Dataproc para crear, obtener, cambiar el tamaño, eliminar y enviar un trabajo a un grupo de nodos de controlador de Dataproc.
Crear un clúster de grupo de nodos de controlador
Un grupo de nodos de controlador está asociado a un clúster de Dataproc. Creas un grupo de nodos como parte del proceso de creación de un clúster de Dataproc. Puedes usar la CLI de gcloud o la API REST de Dataproc para crear un clúster de Dataproc con un grupo de nodos de controlador.
gcloud
gcloud dataproc clusters create CLUSTER_NAME \ --region=REGION \ --driver-pool-size=SIZE \ --driver-pool-id=NODE_GROUP_ID
Marcas obligatorias:
- CLUSTER_NAME: el nombre del clúster, que debe ser único en un proyecto. El nombre debe empezar por una letra minúscula y puede contener hasta 51 letras minúsculas, números y guiones. No puede terminar en un guion. El nombre de un clúster eliminado se puede reutilizar.
- REGION: la región en la que se ubicará el clúster.
- SIZE: Número de nodos de controlador del grupo de nodos. El número de nodos que se necesitan depende de la carga de trabajo y del tipo de máquina del grupo de controladores. El número de nodos del grupo de controladores mínimo es igual a la memoria total o a las vCPUs que necesitan los controladores de la tarea dividido entre la memoria o las vCPUs de la máquina de cada grupo de controladores.
- NODE_GROUP_ID: opcional y recomendado. El ID debe ser único en el clúster. Usa este ID para identificar el grupo de controladores en operaciones futuras, como cambiar el tamaño del grupo de nodos. Si no se especifica, Dataproc genera el ID del grupo de nodos.
Marca recomendada:
--enable-component-gateway: añade esta marca para habilitar la pasarela de componentes de Dataproc, que proporciona acceso a la interfaz web de YARN. En las páginas Aplicación e Interfaz de usuario de YARN y Programador se muestra el estado del clúster y de los trabajos, la memoria de la cola de aplicaciones, la capacidad de los núcleos y otras métricas.
Marcas adicionales: se pueden añadir las siguientes marcas driver-pool opcionales al comando gcloud dataproc clusters create para personalizar el grupo de nodos.
| Bandera | Valor predeterminado |
|---|---|
--driver-pool-id |
Un identificador de cadena generado por el servicio si no se define mediante la marca. Este ID se puede usar para identificar el grupo de nodos al realizar operaciones futuras en el grupo de nodos, como cambiar su tamaño. |
--driver-pool-machine-type |
n1-standard-4 |
--driver-pool-accelerator |
No hay ningún valor predeterminado. Cuando se especifica un acelerador, es obligatorio indicar el tipo de GPU, pero el número de GPUs es opcional. |
--num-driver-pool-local-ssds |
Sin opción predeterminada |
--driver-pool-local-ssd-interface |
Sin opción predeterminada |
--driver-pool-boot-disk-type |
pd-standard |
--driver-pool-boot-disk-size |
1000 GB |
--driver-pool-min-cpu-platform |
AUTOMATIC |
REST
Completa un AuxiliaryNodeGroup como parte de una solicitud de la API de Dataproc cluster.create.
Antes de usar los datos de la solicitud, haz las siguientes sustituciones:
- PROJECT_ID: obligatorio. ID del proyecto de Google Cloud.
- REGION: obligatorio. Región del clúster de Dataproc.
- CLUSTER_NAME: obligatorio. El nombre del clúster, que debe ser único en un proyecto. El nombre debe empezar por una letra minúscula y puede contener hasta 51 letras minúsculas, números y guiones. No puede terminar en un guion. El nombre de un clúster eliminado se puede volver a utilizar.
- SIZE: obligatorio. Número de nodos del grupo de nodos.
- NODE_GROUP_ID: Opcional y recomendado. El ID debe ser único en el clúster. Usa este ID para identificar el grupo de controladores en operaciones futuras, como cambiar el tamaño del grupo de nodos. Si no se especifica, Dataproc genera el ID del grupo de nodos.
Opciones adicionales: consulta NodeGroup.
Método HTTP y URL:
POST https://dataproc.googleapis.com/v1/projects/PROJECT_ID/regions/REGION/clusters
Cuerpo JSON de la solicitud:
{
"clusterName":"CLUSTER_NAME",
"config": {
"softwareConfig": {
"imageVersion":""
},
"endpointConfig": {
"enableHttpPortAccess": true
},
"auxiliaryNodeGroups": [{
"nodeGroup":{
"roles":["DRIVER"],
"nodeGroupConfig": {
"numInstances": SIZE
}
},
"nodeGroupId": "NODE_GROUP_ID"
}]
}
}
Para enviar tu solicitud, despliega una de estas opciones:
Deberías recibir una respuesta JSON similar a la siguiente:
{
"projectId": "PROJECT_ID",
"clusterName": "CLUSTER_NAME",
"config": {
...
"auxiliaryNodeGroups": [
{
"nodeGroup": {
"name": "projects/PROJECT_ID/regions/REGION/clusters/CLUSTER_NAME/nodeGroups/NODE_GROUP_ID",
"roles": [
"DRIVER"
],
"nodeGroupConfig": {
"numInstances": SIZE,
"instanceNames": [
"CLUSTER_NAME-np-q1gp",
"CLUSTER_NAME-np-xfc0"
],
"imageUri": "https://www.googleapis.com/compute/v1/projects/cloud-dataproc-ci/global/images/dataproc-2-0-deb10-...-rc01",
"machineTypeUri": "https://www.googleapis.com/compute/v1/projects/PROJECT_ID/zones/REGION-a/machineTypes/n1-standard-4",
"diskConfig": {
"bootDiskSizeGb": 1000,
"bootDiskType": "pd-standard"
},
"managedGroupConfig": {
"instanceTemplateName": "dataproc-2a8224d2-...",
"instanceGroupManagerName": "dataproc-2a8224d2-..."
},
"minCpuPlatform": "AUTOMATIC",
"preemptibility": "NON_PREEMPTIBLE"
}
},
"nodeGroupId": "NODE_GROUP_ID"
}
]
},
}
Obtener metadatos de clúster de grupos de nodos de controladores
Puedes usar el comando
gcloud dataproc node-groups describe
o la API de Dataproc para
obtener los metadatos del grupo de nodos de controlador.
gcloud
gcloud dataproc node-groups describe NODE_GROUP_ID \ --cluster=CLUSTER_NAME \ --region=REGION
Marcas obligatorias:
- NODE_GROUP_ID: puedes ejecutar
gcloud dataproc clusters describe CLUSTER_NAMEpara ver el ID del grupo de nodos. - CLUSTER_NAME: nombre del clúster.
- REGION: la región del clúster.
REST
Antes de usar los datos de la solicitud, haz las siguientes sustituciones:
- PROJECT_ID: obligatorio. ID del proyecto de Google Cloud.
- REGION: obligatorio. La región del clúster.
- CLUSTER_NAME: obligatorio. El nombre del clúster.
- NODE_GROUP_ID: obligatorio. Puedes ejecutar
gcloud dataproc clusters describe CLUSTER_NAMEpara ver el ID del grupo de nodos.
Método HTTP y URL:
GET https://dataproc.googleapis.com/v1/projects/PROJECT_ID/regions/REGION/clusters/CLUSTER_NAMEnodeGroups/Node_GROUP_ID
Para enviar tu solicitud, despliega una de estas opciones:
Deberías recibir una respuesta JSON similar a la siguiente:
{
"name": "projects/PROJECT_ID/regions/REGION/clusters/CLUSTER_NAME/nodeGroups/NODE_GROUP_ID",
"roles": [
"DRIVER"
],
"nodeGroupConfig": {
"numInstances": 5,
"imageUri": "https://www.googleapis.com/compute/v1/projects/cloud-dataproc-ci/global/images/dataproc-2-0-deb10-...-rc01",
"machineTypeUri": "https://www.googleapis.com/compute/v1/projects/PROJECT_ID/zones/REGION-a/machineTypes/n1-standard-4",
"diskConfig": {
"bootDiskSizeGb": 1000,
"bootDiskType": "pd-standard"
},
"managedGroupConfig": {
"instanceTemplateName": "dataproc-driver-pool-mcia3j656h2fy",
"instanceGroupManagerName": "dataproc-driver-pool-mcia3j656h2fy"
},
"minCpuPlatform": "AUTOMATIC",
"preemptibility": "NON_PREEMPTIBLE"
}
}
Cambiar el tamaño de un grupo de nodos de controlador
Puedes usar el comando
gcloud dataproc node-groups resize
o la API de Dataproc
para añadir o quitar nodos de controlador de un grupo de nodos de controlador de clúster.
gcloud
gcloud dataproc node-groups resize NODE_GROUP_ID \ --cluster=CLUSTER_NAME \ --region=REGION \ --size=SIZE
Marcas obligatorias:
- NODE_GROUP_ID: puedes ejecutar
gcloud dataproc clusters describe CLUSTER_NAMEpara ver el ID del grupo de nodos. - CLUSTER_NAME: nombre del clúster.
- REGION: la región del clúster.
- SIZE: especifica el nuevo número de nodos de controlador del grupo de nodos.
Marca opcional:
--graceful-decommission-timeout=TIMEOUT_DURATION: Cuando reduces la escala de un grupo de nodos, puedes añadir esta marca para especificar una retirada gradual TIMEOUT_DURATION para evitar la finalización inmediata de los controladores de trabajos. Recomendación: Define una duración de tiempo de espera que sea al menos igual a la duración del trabajo más largo que se esté ejecutando en el grupo de nodos (no se admite la recuperación de controladores fallidos).
Ejemplo: comando de escalado vertical de la CLI de gcloud NodeGroup:
gcloud dataproc node-groups resize NODE_GROUP_ID \ --cluster=CLUSTER_NAME \ --region=REGION \ --size=4
Ejemplo: comando de reducción de la CLI de gcloud NodeGroup:
gcloud dataproc node-groups resize NODE_GROUP_ID \ --cluster=CLUSTER_NAME \ --region=REGION \ --size=1 \ --graceful-decommission-timeout="100s"
REST
Antes de usar los datos de la solicitud, haz las siguientes sustituciones:
- PROJECT_ID: obligatorio. ID del proyecto de Google Cloud.
- REGION: obligatorio. La región del clúster.
- NODE_GROUP_ID: obligatorio. Puedes ejecutar
gcloud dataproc clusters describe CLUSTER_NAMEpara ver el ID del grupo de nodos. - SIZE: obligatorio. Nuevo número de nodos del grupo de nodos.
- TIMEOUT_DURATION: opcional. Cuando se reduce la escala de un grupo de nodos, puedes añadir un
gracefulDecommissionTimeoutal cuerpo de la solicitud para evitar que los controladores de tareas se terminen inmediatamente. Recomendación: Define una duración de tiempo de espera que sea al menos igual a la duración del trabajo más largo que se esté ejecutando en el grupo de nodos (no se admite la recuperación de controladores fallidos).Ejemplo:
{ "size": SIZE, "gracefulDecommissionTimeout": "TIMEOUT_DURATION" }
Método HTTP y URL:
POST https://dataproc.googleapis.com/v1/projects/PROJECT_ID/regions/REGION/clusters/CLUSTER_NAME/nodeGroups/Node_GROUP_ID:resize
Cuerpo JSON de la solicitud:
{
"size": SIZE,
}
Para enviar tu solicitud, despliega una de estas opciones:
Deberías recibir una respuesta JSON similar a la siguiente:
{
"name": "projects/PROJECT_ID/regions/REGION/operations/OPERATION_ID",
"metadata": {
"@type": "type.googleapis.com/google.cloud.dataproc.v1.NodeGroupOperationMetadata",
"nodeGroupId": "NODE_GROUP_ID",
"clusterUuid": "CLUSTER_UUID",
"status": {
"state": "PENDING",
"innerState": "PENDING",
"stateStartTime": "2022-12-01T23:34:53.064308Z"
},
"operationType": "RESIZE",
"description": "Scale "up or "down" a GCE node pool to SIZE nodes."
}
}
Eliminar un clúster de grupos de nodos de controladores
Cuando eliminas un clúster de Dataproc, se eliminan los grupos de nodos asociados al clúster.
Enviar una tarea
Puedes usar el comando gcloud dataproc jobs submit o la API de Dataproc para enviar una tarea a un clúster con un grupo de nodos de controlador.
gcloud
gcloud dataproc jobs submit JOB_COMMAND \ --cluster=CLUSTER_NAME \ --region=REGION \ --driver-required-memory-mb=DRIVER_MEMORY \ --driver-required-vcores=DRIVER_VCORES \ DATAPROC_FLAGS \ -- JOB_ARGS
Marcas obligatorias:
- JOB_COMMAND: especifica el comando del trabajo.
- CLUSTER_NAME: nombre del clúster.
- DRIVER_MEMORY: cantidad de memoria de controladores de trabajos en MB necesaria para ejecutar un trabajo (consulta Controles de memoria de Yarn).
- DRIVER_VCORES: número de vCPUs necesarias para ejecutar un trabajo.
Marcas adicionales:
- DATAPROC_FLAGS: añade las marcas adicionales de gcloud dataproc jobs submit que estén relacionadas con el tipo de tarea.
- JOB_ARGS: añade los argumentos que quieras (después de
--) para pasárselos al trabajo.
Ejemplos: puedes ejecutar los siguientes ejemplos desde una sesión de terminal SSH en un clúster de grupo de nodos de controlador de Dataproc.
Tarea de Spark para estimar el valor de
pi:gcloud dataproc jobs submit spark \ --cluster=CLUSTER_NAME \ --region=REGION \ --driver-required-memory-mb=2048 \ --driver-required-vcores=2 \ --class=org.apache.spark.examples.SparkPi \ --jars=file:///usr/lib/spark/examples/jars/spark-examples.jar \ -- 1000
Tarea de recuento de palabras de Spark:
gcloud dataproc jobs submit spark \ --cluster=CLUSTER_NAME \ --region=REGION \ --driver-required-memory-mb=2048 \ --driver-required-vcores=2 \ --class=org.apache.spark.examples.JavaWordCount \ --jars=file:///usr/lib/spark/examples/jars/spark-examples.jar \ -- 'gs://apache-beam-samples/shakespeare/macbeth.txt'
Tarea de PySpark para estimar el valor de
pi:gcloud dataproc jobs submit pyspark \ file:///usr/lib/spark/examples/src/main/python/pi.py \ --cluster=CLUSTER_NAME \ --region=REGION \ --driver-required-memory-mb=2048 \ --driver-required-vcores=2 \ -- 1000
Tarea MapReduce TeraGen de Hadoop:
gcloud dataproc jobs submit hadoop \ --cluster=CLUSTER_NAME \ --region=REGION \ --driver-required-memory-mb=2048 \ --driver-required-vcores=2 \ --jar file:///usr/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar \ -- teragen 1000 \ hdfs:///gen1/test
REST
Antes de usar los datos de la solicitud, haz las siguientes sustituciones:
- PROJECT_ID: obligatorio. ID del proyecto de Google Cloud.
- REGION: obligatorio. Región del clúster de Dataproc
- CLUSTER_NAME: obligatorio. El nombre del clúster, que debe ser único en un proyecto. El nombre debe empezar por una letra minúscula y puede contener hasta 51 letras minúsculas, números y guiones. No puede terminar en un guion. El nombre de un clúster eliminado se puede volver a utilizar.
- DRIVER_MEMORY: obligatorio. Cantidad de memoria de los controladores de trabajos en MB necesaria para ejecutar un trabajo (consulta Controles de memoria de Yarn).
- DRIVER_VCORES: obligatorio. Número de vCPUs necesarias para ejecutar un trabajo.
pi).
Método HTTP y URL:
POST https://dataproc.googleapis.com/v1/projects/PROJECT_ID/regions/REGION/jobs:submit
Cuerpo JSON de la solicitud:
{
"job": {
"placement": {
"clusterName": "CLUSTER_NAME",
},
"driverSchedulingConfig": {
"memoryMb]": DRIVER_MEMORY,
"vcores": DRIVER_VCORES
},
"sparkJob": {
"jarFileUris": "file:///usr/lib/spark/examples/jars/spark-examples.jar",
"args": [
"10000"
],
"mainClass": "org.apache.spark.examples.SparkPi"
}
}
}
Para enviar tu solicitud, despliega una de estas opciones:
Deberías recibir una respuesta JSON similar a la siguiente:
{
"reference": {
"projectId": "PROJECT_ID",
"jobId": "job-id"
},
"placement": {
"clusterName": "CLUSTER_NAME",
"clusterUuid": "cluster-Uuid"
},
"sparkJob": {
"mainClass": "org.apache.spark.examples.SparkPi",
"args": [
"1000"
],
"jarFileUris": [
"file:///usr/lib/spark/examples/jars/spark-examples.jar"
]
},
"status": {
"state": "PENDING",
"stateStartTime": "start-time"
},
"jobUuid": "job-Uuid"
}
Python
- Instalar la biblioteca de cliente
- Configurar credenciales predeterminadas de la aplicación
- Ejecuta el código.
- Tarea de Spark para estimar el valor de pi:
- Tarea de PySpark para imprimir "hola mundo":
Ver registros de tarea
Para ver el estado de los trabajos y depurar los problemas relacionados con ellos, puedes consultar los registros del controlador mediante la CLI de gcloud o la Google Cloud consola.
gcloud
Los registros del controlador de tareas se transmiten a la salida de la CLI de gcloud o a laGoogle Cloud consola durante la ejecución de la tarea. Los registros de controladores se conservan en el segmento de almacenamiento provisional del clúster de Dataproc en Cloud Storage.
Ejecuta el siguiente comando de gcloud CLI para enumerar la ubicación de los registros de controladores en Cloud Storage:
gcloud dataproc jobs describe JOB_ID \ --region=REGION
La ubicación de Cloud Storage de los registros de controladores se indica como driverOutputResourceUri en la salida del comando, con el siguiente formato:
driverOutputResourceUri: gs://CLUSTER_STAGING_BUCKET/google-cloud-dataproc-metainfo/CLUSTER_UUID/jobs/JOB_ID
Consola
Para ver los registros de clústeres de grupos de nodos, sigue estos pasos:
Puedes usar el siguiente formato de consulta del Explorador de registros para buscar registros:
resource.type="cloud_dataproc_cluster" resource.labels.project_id="PROJECT_ID" resource.labels.cluster_name="CLUSTER_NAME" log_name="projects/PROJECT_ID/logs/LOG_TYPE>"
- PROJECT_ID: Google Cloud ID de proyecto.
- CLUSTER_NAME: nombre del clúster.
- LOG_TYPE:
- Registros de usuarios de Yarn:
yarn-userlogs - Registros del gestor de recursos de Yarn:
hadoop-yarn-resourcemanager - Registros del gestor de nodos de Yarn:
hadoop-yarn-nodemanager
- Registros de usuarios de Yarn:
Monitorizar métricas
Los controladores de tareas de grupos de nodos de Dataproc se ejecutan en una cola secundaria dataproc-driverpool-driver-queue de una partición dataproc-driverpool.
Métricas de grupos de nodos de controlador
En la siguiente tabla se enumeran las métricas de controlador de grupo de nodos asociadas, que se recogen de forma predeterminada en los grupos de nodos de controlador.
| Métrica de grupo de nodos de controlador | Descripción |
|---|---|
yarn:ResourceManager:DriverPoolsQueueMetrics:AvailableMB |
Cantidad de memoria disponible en mebibytes en
dataproc-driverpool-driver-queue en la partición
dataproc-driverpool.
|
yarn:ResourceManager:DriverPoolsQueueMetrics:PendingContainers |
Número de contenedores pendientes (en cola) en dataproc-driverpool-driver-queue de la partición dataproc-driverpool. |
Métricas de la cola secundaria
En la tabla siguiente se enumeran las métricas de la cola secundaria. Las métricas se recogen de forma predeterminada en los grupos de nodos de controlador y se pueden habilitar para que se recojan en cualquier clúster de Dataproc.
| Métrica de cola secundaria | Descripción |
|---|---|
yarn:ResourceManager:ChildQueueMetrics:AvailableMB |
Cantidad de memoria disponible en mebibytes en esta cola de la partición predeterminada. |
yarn:ResourceManager:ChildQueueMetrics:PendingContainers |
Número de contenedores pendientes (en cola) de esta cola en la partición predeterminada. . |
yarn:ResourceManager:ChildQueueMetrics:running_0 |
Número de tareas con un tiempo de ejecución entre 0 y 60 minutos en esta cola de todas las particiones. |
yarn:ResourceManager:ChildQueueMetrics:running_60 |
Número de tareas con un tiempo de ejecución entre 60 y 300 minutos en esta cola de todas las particiones. |
yarn:ResourceManager:ChildQueueMetrics:running_300 |
Número de tareas con un tiempo de ejecución entre 300 y 1440 minutos en esta cola de todas las particiones. |
yarn:ResourceManager:ChildQueueMetrics:running_1440 |
Número de tareas con un tiempo de ejecución superior a 1440 minutos en esta cola en todas las particiones. |
yarn:ResourceManager:ChildQueueMetrics:AppsSubmitted |
Número de aplicaciones enviadas a esta cola en todas las particiones. |
Para ver YARN ChildQueueMetrics y DriverPoolsQueueMetrics en la consolaGoogle Cloud , sigue estos pasos:
Selecciona los recursos Instancia de VM → Personalizado en el explorador de métricas.
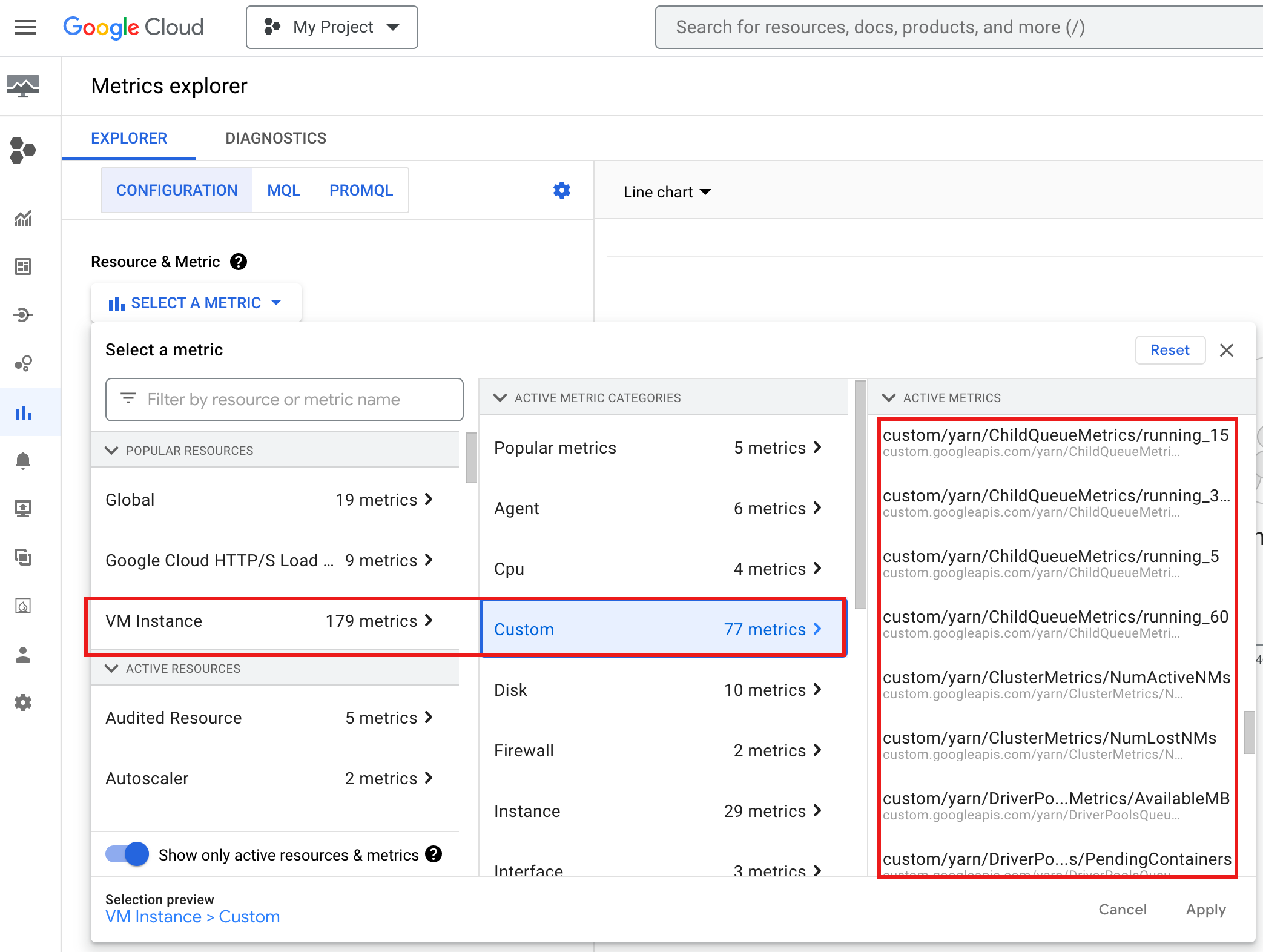
Depurar el controlador de tareas de un grupo de nodos
En esta sección se proporcionan las condiciones y los errores de los grupos de nodos de controladores, así como recomendaciones para solucionar las condiciones o los errores.
Condiciones
Estado:
yarn:ResourceManager:DriverPoolsQueueMetrics:AvailableMBse acerca a0. Esto indica que las colas de los controladores de clúster se están quedando sin memoria.Recomendación: Aumenta el tamaño del grupo de conductores.
Condición:
yarn:ResourceManager:DriverPoolsQueueMetrics:PendingContainerses mayor que 0. Esto puede indicar que los grupos de controladores de clúster se están quedando sin memoria y que YARN está poniendo en cola los trabajos.Recomendación: Aumenta el tamaño del grupo de conductores.
Errores
Error:
Cluster <var>CLUSTER_NAME</var> requires driver scheduling config to run SPARK job because it contains a node pool with role DRIVER. Positive values are required for all driver scheduling config values.Recomendación: Asigna a
driver-required-memory-mbydriver-required-vcoresnúmeros positivos.Error:
Container exited with a non-zero exit code 137.Recomendación: aumenta
driver-required-memory-mbal uso de memoria del trabajo.