Cloud Monitoring proporciona visibilidad del rendimiento, del tiempo de actividad y del estado general de las aplicaciones basadas en la nube. Google Cloud Observability recopila y transfiere métricas, eventos y metadatos de los clústeres de Dataproc, incluidas las métricas de HDFS, YARN, trabajo y operaciones por clúster, para generar estadísticas a través de paneles y gráficos (consulta Métricas de Dataproc para Cloud Monitoring).
Consulta los precios de Cloud Monitoring para comprender tus costos.
Consulta Cuotas y límites de Monitoring para obtener información sobre la retención de los datos de métricas.
Recopilación de métricas de recursos de Dataproc
Cloud Monitoring recopila métricas relacionadas con los siguientes recursos de Dataproc:
- Clúster de Cloud Dataproc
- Trabajo de Cloud Dataproc (Cloud Dataproc Job)
- Lote de Cloud Dataproc
- Sesión de Cloud Dataproc
Las métricas de recursos de Dataproc se recopilan en el siguiente formato:
dataproc.googleapis.com/RESOURCE/METRIC,
y abarcan la recopilación de varias métricas de OSS.
Consulta las métricas de recursos de Dataproc
Para seleccionar y ver las métricas de recursos de Dataproc en el Explorador de métricas, escribe "dataproc" en el cuadro Filter by resource or metric name y, luego, selecciona un recurso de "Cloud Dataproc".
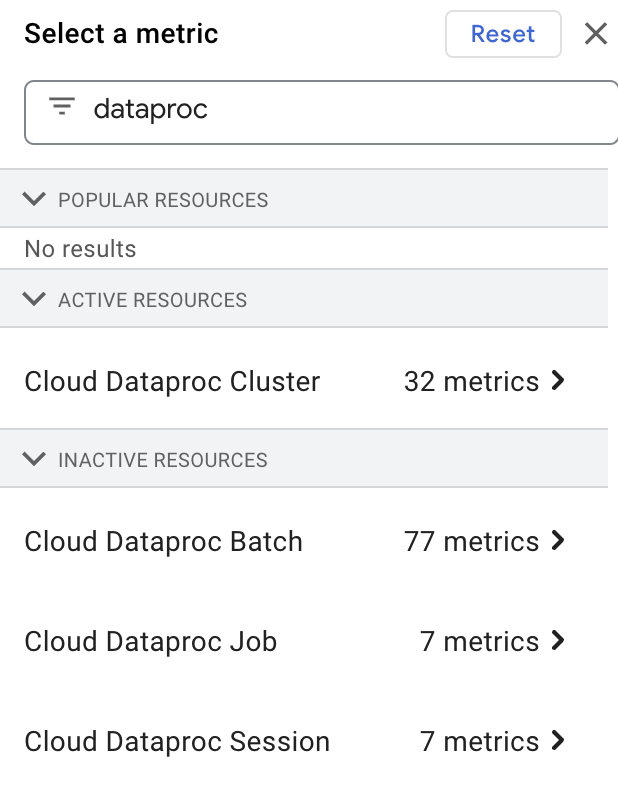
Recopilación de métricas personalizadas
Cuando creas un clúster de Dataproc, puedes habilitar la recopilación de métricas de una o más fuentes de métricas personalizadas. Se recopila un conjunto estándar de métricas de cada fuente de métricas habilitada, a menos que especifiques las métricas que se recopilarán de una fuente de métricas (las métricas especificadas por el usuario se denominan "invalidaciones" de métricas).
Las métricas personalizadas de OSS se recopilan en el siguiente formato:
custom.googleapis.com/OSS_COMPONENT/METRIC
Ejemplos de métricas personalizadas de OSS:
custom.googleapis.com/spark/driver/DAGScheduler/job/allJobs custom.googleapis.com/hiveserver2/memory/MaxNonHeapMemory
Habilita la recopilación de métricas personalizadas
Puedes usar gcloud CLI o la API de Dataproc para habilitar la recopilación de métricas personalizadas de una o más fuentes de métricas.
gcloud CLI
Recopilación de métricas personalizadas
Usa la marca
gcloud dataproc clusters create --metric-sources para habilitar la recopilación de métricas personalizadas de una o más fuentes de métricas.
gcloud dataproc clusters create cluster-name \ --metric-sources=METRIC_SOURCE(s) \ ... other flags
Notas:
--metric-sources: Se requiere para habilitar la recopilación de métricas personalizadas. Especifica una o más de las siguientes fuentes de métricas:spark,flink,hdfs,yarn,spark-history-server,hiveserver2,hivemetastoreymonitoring-agent-defaults. El nombre de la fuente de la métrica no distingue mayúsculas de minúsculas. Por ejemplo, se acepta "yarn" o "YARN".- monitoring-agent-defaults no está disponible en los clústeres con la versión de imagen 2.2. Puedes instalar el Agente de operaciones, que recopila registros de syslog y métricas de host .
Anula la recopilación de métricas
De manera opcional, agrega la marca --metric-overrides o --metric-overrides-file para habilitar la recopilación de una o más métricas personalizadas de una o más fuentes de métricas.
-
Cualquiera de las métricas personalizadas y todas las métricas de Spark se pueden incluir en la recopilación como una anulación de métrica. Los valores de reemplazo de las métricas distinguen mayúsculas de minúsculas y deben proporcionarse, si corresponde, en formato CamelCase.
Ejemplos:
sparkHistoryServer:JVM:Memory:NonHeapMemoryUsage.committedhiveserver2:JVM:Memory:NonHeapMemoryUsage.usedyarn:ResourceManager:JvmMetrics:MemHeapMaxM
-
Solo se recopilarán las métricas anuladas especificadas de una fuente de métricas determinada. Por ejemplo, si una o más métricas de
spark:executivese indican como anulaciones de métricas, no se recopilarán otras métricas deSPARK. La recopilación de métricas personalizadas de otras fuentes de métricas no se ve afectada. Por ejemplo, si se habilitan las fuentes de métricasSPARKyYARN, y se proporcionan anulaciones solo para las métricas de Spark, se recopilará el conjunto estándar de métricas de YARN habilitadas. -
Debe estar habilitada la fuente de la anulación de métricas especificada. Por ejemplo, si se proporcionan una o más métricas de
spark:drivercomo anulaciones de métricas, se debe habilitar la fuente de métricas despark(--metric-sources=spark).
Lista de métricas de anulación
gcloud dataproc clusters create cluster-name \ --metric-sources=METRIC_SOURCE(s) \ --metric-overrides=LIST_OF_METRIC_OVERRIDES \ ... other flags
Notas:
--metric-sources: Se requiere para habilitar la recopilación de métricas personalizadas. Especifica una o más de las siguientes fuentes de métricas:spark,flink,hdfs,yarn,spark-history-server,hiveserver2,hivemetastoreymonitoring-agent-defaults. El nombre de la fuente de la métrica no distingue mayúsculas de minúsculas. Por ejemplo, se acepta "yarn" o "YARN".--metric-overrides: Proporciona una lista de métricas en el siguiente formato:METRIC_SOURCE:INSTANCE:GROUP:METRIC
Ejemplo:
--metric-overrides=sparkHistoryServer:JVM:Memory:NonHeapMemoryUsage.committedEsta marca es una alternativa a la marca
--metric-overrides-filey no se puede usar con ella.
Anula el archivo de métricas
gcloud dataproc clusters create cluster-name \ --metric-sources=METRIC-SOURCE(s) \ --metric-overrides-file=METRIC_OVERRIDES_FILENAME \ ... other flags
Notas:
-
--metric-sources: Se requiere para habilitar la recopilación de métricas personalizadas. Especifica una o más de las siguientes fuentes de métricas:spark,flink,hdfs,yarn,spark-history-server,hiveserver2,hivemetastoreymonitoring-agent-defaults. El nombre de la fuente de la métrica no distingue mayúsculas de minúsculas. Por ejemplo, se acepta "yarn" o "YARN". -
--metric-overrides-file: Especifica un archivo local o de Cloud Storage (gs://bucket/filename) que contenga una o más métricas en el siguiente formato:METRIC_SOURCE:INSTANCE:GROUP:METRIC
Usa el formato camelcase según corresponda.Ejemplos:
--metric-overrides-file=gs://my-bucket/my-filename.txt--metric-overrides-file=./local-directory/local-filename.txtEsta marca es una alternativa a la marca
--metric-overridesy no se puede usar con ella.
API de REST
Usa DataprocMetricConfig como parte de una solicitud clusters.create para habilitar la recopilación de métricas personalizadas. Nota: monitoring-agent-defaults no está disponible en los clústeres con la versión de imagen 2.2, a menos que se instale el Agente de operaciones.
Cómo ver las métricas personalizadas
Puedes seleccionar y ver las métricas de recursos de Dataproc en el Explorador de métricas. Para ello, selecciona el recurso VM Instance y, luego, Custom metrics.
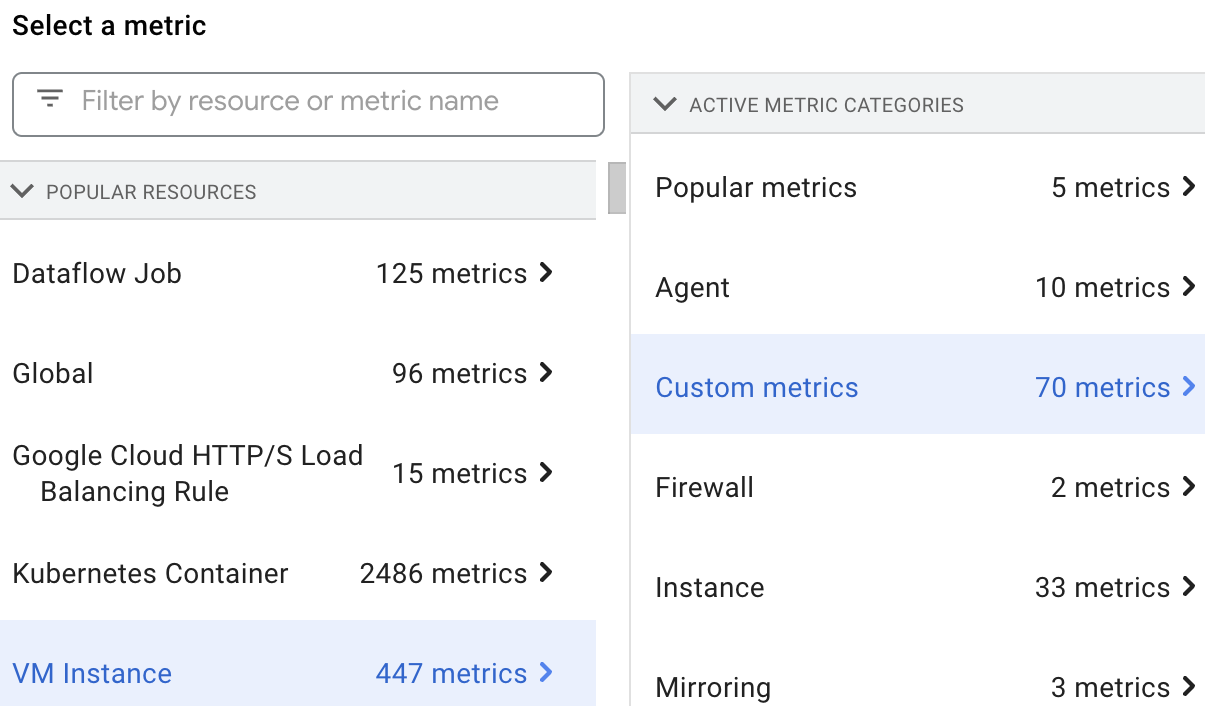
Métricas personalizadas
Puedes habilitar Dataproc para que recopile las métricas personalizadas que se indican en las siguientes tablas.
La columna Métricas habilitadas está marcada con una "s" si Dataproc recopila la métrica cuando habilitas la fuente de métricas asociada.
Cualquiera de las métricas que se enumeran para una fuente de métricas, y todas las métricas de Spark, se pueden habilitar para la recopilación si anulas la recopilación del conjunto estándar de métricas habilitadas para la fuente de métricas (consulta Cómo habilitar la recopilación de métricas personalizadas).
Dataproc usa el agente de supervisión para recopilar métricas. Habilitar cualquier fuente de métricas permite la recopilación de métricas del agente. Estas métricas no se facturan a los usuarios. Dataproc las usa para diagnosticar problemas de recopilación de métricas.
Métricas de Hadoop
Métricas de HDFS
| Métrica | Nombre del Explorador de métricas | Métricas habilitadas |
|---|---|---|
| hdfs:NameNode:FSNamesystem:CapacityTotalGB | dfs/FSNamesystem/CapacityTotalGB | y |
| hdfs:NameNode:FSNamesystem:CapacityUsedGB | dfs/FSNamesystem/CapacityUsedGB | y |
| hdfs:NameNode:FSNamesystem:CapacityRemainingGB | dfs/FSNamesystem/CapacityRemainingGB | y |
| hdfs:NameNode:FSNamesystem:FilesTotal | dfs/FSNamesystem/FilesTotal | y |
| hdfs:NameNode:FSNamesystem:MissingBlocks | dfs/FSNamesystem/MissingBlocks | n |
| hdfs:NameNode:FSNamesystem:ExpiredHeartbeats | dfs/FSNamesystem/ExpiredHeartbeats | n |
| hdfs:NameNode:FSNamesystem:TransactionsSinceLastCheckpoint | dfs/FSNamesystem/TransactionsSinceLastCheckpoint | n |
| hdfs:NameNode:FSNamesystem:TransactionsSinceLastLogRoll | dfs/FSNamesystem/TransactionsSinceLastLogRoll | n |
| hdfs:NameNode:FSNamesystem:LastWrittenTransactionId | dfs/FSNamesystem/LastWrittenTransactionId | n |
| hdfs:NameNode:FSNamesystem:CapacityTotal | dfs/FSNamesystem/CapacityTotal | n |
| hdfs:NameNode:FSNamesystem:CapacityUsed | dfs/FSNamesystem/CapacityUsed | n |
| hdfs:NameNode:FSNamesystem:CapacityRemaining | dfs/FSNamesystem/CapacityRemaining | n |
| hdfs:NameNode:FSNamesystem:CapacityUsedNonDFS | dfs/FSNamesystem/CapacityUsedNonDFS | n |
| hdfs:NameNode:FSNamesystem:TotalLoad | dfs/FSNamesystem/TotalLoad | n |
| hdfs:NameNode:FSNamesystem:SnapshottableDirectories | dfs/FSNamesystem/SnapshottableDirectories | n |
| hdfs:NameNode:FSNamesystem:Snapshots | dfs/FSNamesystem/Snapshots | n |
| hdfs:NameNode:FSNamesystem:BlocksTotal | dfs/FSNamesystem/BlocksTotal | n |
| hdfs:NameNode:FSNamesystem:PendingReplicationBlocks | dfs/FSNamesystem/PendingReplicationBlocks | n |
| hdfs:NameNode:FSNamesystem:UnderReplicatedBlocks | dfs/FSNamesystem/UnderReplicatedBlocks | n |
| hdfs:NameNode:FSNamesystem:CorruptBlocks | dfs/FSNamesystem/CorruptBlocks | n |
| hdfs:NameNode:FSNamesystem:ScheduledReplicationBlocks | dfs/FSNamesystem/ScheduledReplicationBlocks | n |
| hdfs:NameNode:FSNamesystem:PendingDeletionBlocks | dfs/FSNamesystem/PendingDeletionBlocks | n |
| hdfs:NameNode:FSNamesystem:ExcessBlocks | dfs/FSNamesystem/ExcessBlocks | n |
| hdfs:NameNode:FSNamesystem:PostponedMisreplicatedBlocks | dfs/FSNamesystem/PostponedMisreplicatedBlocks | n |
| hdfs:NameNode:FSNamesystem:PendingDataNodeMessageCourt | dfs/FSNamesystem/PendingDataNodeMessageCourt | n |
| hdfs:NameNode:FSNamesystem:MillisSinceLastLoadedEdits | dfs/FSNamesystem/MillisSinceLastLoadedEdits | n |
| hdfs:NameNode:FSNamesystem:BlockCapacity | dfs/FSNamesystem/BlockCapacity | n |
| hdfs:NameNode:FSNamesystem:StaleDataNodes | dfs/FSNamesystem/StaleDataNodes | n |
| hdfs:NameNode:FSNamesystem:TotalFiles | dfs/FSNamesystem/TotalFiles | n |
| hdfs:NameNode:JvmMetrics:MemHeapUsedM | dfs/jvm/MemHeapUsedM | n |
| hdfs:NameNode:JvmMetrics:MemHeapCommittedM | dfs/jvm/MemHeapCommittedM | n |
| hdfs:NameNode:JvmMetrics:MemHeapMaxM | dfs/jvm/MemHeapMaxM | n |
| hdfs:NameNode:JvmMetrics:MemMaxM | dfs/jvm/MemMaxM | n |
Métricas de YARN
| Métrica | Nombre del Explorador de métricas | Métricas habilitadas |
|---|---|---|
| yarn:ResourceManager:ClusterMetrics:NumActiveNMs | yarn/ClusterMetrics/NumActiveNMs | y |
| yarn:ResourceManager:ClusterMetrics:NumDecommissionedNMs | yarn/ClusterMetrics/NumDecommissionedNMs | n |
| yarn:ResourceManager:ClusterMetrics:NumLostNMs | yarn/ClusterMetrics/NumLostNMs | n |
| yarn:ResourceManager:ClusterMetrics:NumUnhealthyNMs | yarn/ClusterMetrics/NumUnhealthyNMs | n |
| yarn:ResourceManager:ClusterMetrics:NumRebootedNMs | yarn/ClusterMetrics/NumRebootedNMs | n |
| yarn:ResourceManager:QueueMetrics:running_0 | yarn/QueueMetrics/running_0 | y |
| yarn:ResourceManager:QueueMetrics:running_60 | yarn/QueueMetrics/running_60 | y |
| yarn:ResourceManager:QueueMetrics:running_300 | yarn/QueueMetrics/running_300 | y |
| yarn:ResourceManager:QueueMetrics:running_1440 | yarn/QueueMetrics/running_1440 | y |
| yarn:ResourceManager:QueueMetrics:AppsSubmitted | yarn/QueueMetrics/AppsSubmitted | y |
| yarn:ResourceManager:QueueMetrics:AvailableMB | yarn/QueueMetrics/AvailableMB | y |
| yarn:ResourceManager:QueueMetrics:PendingContainers | yarn/QueueMetrics/PendingContainers | y |
| yarn:ResourceManager:QueueMetrics:AppsRunning | yarn/QueueMetrics/AppsRunning | n |
| yarn:ResourceManager:QueueMetrics:AppsPending | yarn/QueueMetrics/AppsPending | n |
| yarn:ResourceManager:QueueMetrics:AppsCompleted | yarn/QueueMetrics/AppsCompleted | n |
| yarn:ResourceManager:QueueMetrics:AppsKilled | yarn/QueueMetrics/AppsKilled | n |
| yarn:ResourceManager:QueueMetrics:AppsFailed | yarn/QueueMetrics/AppsFailed | n |
| yarn:ResourceManager:QueueMetrics:AllocatedMB | yarn/QueueMetrics/AllocatedMB | n |
| yarn:ResourceManager:QueueMetrics:AllocatedVCores | yarn/QueueMetrics/AllocatedVCores | n |
| yarn:ResourceManager:QueueMetrics:AllocatedContainers | yarn/QueueMetrics/AllocatedContainers | n |
| yarn:ResourceManager:QueueMetrics:AggregateContainersAllocated | yarn/QueueMetrics/AggregateContainersAllocated | n |
| yarn:ResourceManager:QueueMetrics:AggregateContainersReleased | yarn/QueueMetrics/AggregateContainersReleased | n |
| yarn:ResourceManager:QueueMetrics:AvailableVCores | yarn/QueueMetrics/AvailableVCores | n |
| yarn:ResourceManager:QueueMetrics:PendingMB | yarn/QueueMetrics/PendingMB | n |
| yarn:ResourceManager:QueueMetrics:PendingVCores | yarn/QueueMetrics/PendingVCores | n |
| yarn:ResourceManager:QueueMetrics:ReservedMB | yarn/QueueMetrics/ReservedMB | n |
| yarn:ResourceManager:QueueMetrics:ReservedVCores | yarn/QueueMetrics/ReservedVCores | n |
| yarn:ResourceManager:QueueMetrics:ReservedContainers | yarn/QueueMetrics/ReservedContainers | n |
| yarn:ResourceManager:QueueMetrics:ActiveUsers | yarn/QueueMetrics/ActiveUsers | n |
| yarn:ResourceManager:QueueMetrics:ActiveApplications | yarn/QueueMetrics/ActiveApplications | n |
| yarn:ResourceManager:QueueMetrics:FairShareMB | yarn/QueueMetrics/FairShareMB | n |
| yarn:ResourceManager:QueueMetrics:FairShareVCores | yarn/QueueMetrics/FairShareVCores | n |
| yarn:ResourceManager:QueueMetrics:MinShareMB | yarn/QueueMetrics/MinShareMB | n |
| yarn:ResourceManager:QueueMetrics:MinShareVCores | yarn/QueueMetrics/MinShareVCores | n |
| yarn:ResourceManager:QueueMetrics:MaxShareMB | yarn/QueueMetrics/MaxShareMB | n |
| yarn:ResourceManager:QueueMetrics:MaxShareVCores | yarn/QueueMetrics/MaxShareVCores | n |
| yarn:ResourceManager:JvmMetrics:MemHeapUsedM | yarn/jvm/MemHeapUsedM | n |
| yarn:ResourceManager:JvmMetrics:MemHeapCommittedM | yarn/jvm/MemHeapCommittedM | n |
| yarn:ResourceManager:JvmMetrics:MemHeapMaxM | yarn/jvm/MemHeapMaxM | n |
| yarn:ResourceManager:JvmMetrics:MemMaxM | yarn/jvm/MemMaxM | n |
Métricas de Spark
Métricas del controlador de Spark
| Métrica | Nombre del Explorador de métricas | Métricas habilitadas |
|---|---|---|
| spark:driver:BlockManager:disk.diskSpaceUsed_MB | spark/driver/BlockManager/disk/diskSpaceUsed_MB | y |
| spark:driver:BlockManager:memory.maxMem_MB | spark/driver/BlockManager/memory/maxMem_MB | y |
| spark:driver:BlockManager:memory.memUsed_MB | spark/driver/BlockManager/memory/memUsed_MB | y |
| spark:driver:DAGScheduler:job.allJobs | spark/driver/DAGScheduler/job/allJobs | y |
| spark:driver:DAGScheduler:stage.failedStages | spark/driver/DAGScheduler/stage/failedStages | y |
| spark:driver:DAGScheduler:stage.waitingStages | spark/driver/DAGScheduler/stage/waitingStages | y |
Métricas del ejecutor de Spark
| Métrica | Nombre del Explorador de métricas | Métricas habilitadas |
|---|---|---|
| spark:executor:executor:bytesRead | spark/executor/bytesRead | y |
| spark:executor:executor:bytesWritten | spark/executor/bytesWritten | y |
| spark:executor:executor:cpuTime | spark/executor/cpuTime | y |
| spark:executor:executor:diskBytesSpilled | spark/executor/diskBytesSpilled | y |
| spark:executor:executor:recordsRead | spark/executor/recordsRead | y |
| spark:executor:executor:recordsWritten | spark/executor/recordsWritten | y |
| spark:executor:executor:runTime | spark/executor/runTime | y |
| spark:executor:executor:shuffleRecordsRead | spark/executor/shuffleRecordsRead | y |
| spark:executor:executor:shuffleRecordsWritten | spark/executor/shuffleRecordsWritten | y |
Métricas de Flink
| Métrica | Nombre del Explorador de métricas | Métricas habilitadas |
|---|---|---|
| flink:jobmanager:numRegisteredTaskManagers | flink/jobmanager/numRegisteredTaskManagers | n |
| flink:jobmanager:numRunningJobs | flink/jobmanager/numRunningJobs | n |
| flink:jobmanager:Status.JVM.ClassLoader.ClassesLoaded | flink/jobmanager/Status.JVM.ClassLoader.ClassesLoaded | n |
| flink:jobmanager:Status.JVM.ClassLoader.ClassesUnloaded | flink/jobmanager/Status.JVM.ClassLoader.ClassesUnloaded | n |
| flink:jobmanager:Status.JVM.CPU.Load | flink/jobmanager/Status.JVM.CPU.Load | n |
| flink:jobmanager:Status.JVM.CPU.Time | flink/jobmanager/Status.JVM.CPU.Time | y |
| flink:jobmanager:Status.JVM.GarbageCollector.PSMarkSweep.Count | flink/jobmanager/Status.JVM.GarbageCollector.PSMarkSweep.Count | n |
| flink:jobmanager:Status.JVM.GarbageCollector.PSMarkSweep.Time | flink/jobmanager/Status.JVM.GarbageCollector.PSMarkSweep.Time | n |
| flink:jobmanager:Status.JVM.GarbageCollector.PSScavenge.Count | flink/jobmanager/Status.JVM.GarbageCollector.PSScavenge.Count | n |
| flink:jobmanager:Status.JVM.GarbageCollector.PSScavenge.Time | flink/jobmanager/Status.JVM.GarbageCollector.PSScavenge.Time | n |
| flink:jobmanager:Status.JVM.Memory.Direct.Count | flink/jobmanager/Status.JVM.Memory.Direct.Count | y |
| flink:jobmanager:Status.JVM.Memory.Direct.MemoryUsed | flink/jobmanager/Status.JVM.Memory.Direct.MemoryUsed | y |
| flink:jobmanager:Status.JVM.Memory.Direct.TotalCapacity | flink/jobmanager/Status.JVM.Memory.Direct.TotalCapacity | y |
| flink:jobmanager:Status.JVM.Memory.Heap.Committed | flink/jobmanager/Status.JVM.Memory.Heap.Committed | y |
| flink:jobmanager:Status.JVM.Memory.Heap.Max | flink/jobmanager/Status.JVM.Memory.Heap.Max | y |
| flink:jobmanager:Status.JVM.Memory.Heap.Used | flink/jobmanager/Status.JVM.Memory.Heap.Used | y |
| flink:jobmanager:Status.JVM.Memory.Mapped.Count | flink/jobmanager/Status.JVM.Memory.Mapped.Count | y |
| flink:jobmanager:Status.JVM.Memory.Mapped.MemoryUsed | flink/jobmanager/Status.JVM.Memory.Mapped.MemoryUsed | y |
| flink:jobmanager:Status.JVM.Memory.Mapped.TotalCapacity | flink/jobmanager/Status.JVM.Memory.Mapped.TotalCapacity | y |
| flink:jobmanager:Status.JVM.Memory.Metaspace.Committed | flink/jobmanager/Status.JVM.Memory.Metaspace.Committed | n |
| flink:jobmanager:Status.JVM.Memory.Metaspace.Max | flink/jobmanager/Status.JVM.Memory.Metaspace.Max | n |
| flink:jobmanager:Status.JVM.Memory.Metaspace.Used | flink/jobmanager/Status.JVM.Memory.Metaspace.Used | n |
| flink:jobmanager:Status.JVM.Memory.NonHeap.Committed | flink/jobmanager/Status.JVM.Memory.NonHeap.Committed | n |
| flink:jobmanager:Status.JVM.Memory.NonHeap.Max | flink/jobmanager/Status.JVM.Memory.NonHeap.Max | n |
| flink:jobmanager:Status.JVM.Memory.NonHeap.Used | flink/jobmanager/Status.JVM.Memory.NonHeap.Used | n |
| flink:jobmanager:Status.JVM.Threads.Count | flink/jobmanager/Status.JVM.Threads.Count | n |
| flink:jobmanager:taskSlotsAvailable | flink/jobmanager/taskSlotsAvailable | y |
| flink:jobmanager:taskSlotsTotal | flink/jobmanager/taskSlotsTotal | y |
| flink:operator:numRecordsIn | flink/operator/numRecordsIn | n |
| flink:operator:numRecordsInPerSecond.count | flink/operator/numRecordsInPerSecond.count | n |
| flink:operator:numRecordsInPerSecond.rate | flink/operator/numRecordsInPerSecond.rate | n |
| flink:operator:numRecordsOut | flink/operator/numRecordsOut | n |
| flink:operator:numRecordsOutPerSecond.count | flink/operator/numRecordsOutPerSecond.count | n |
| flink:operator:numRecordsOutPerSecond.rate | flink/operator/numRecordsOutPerSecond.rate | n |
| flink:operator:numSplitsProcessed | flink/operator/numSplitsProcessed | n |
| flink:task:buffers.inPoolUsage | flink/task/buffers.inPoolUsage | n |
| flink:task:buffers.inputExclusiveBuffersUsage | flink/task/buffers.inputExclusiveBuffersUsage | n |
| flink:task:buffers.inputFloatingBuffersUsage | flink/task/buffers.inputFloatingBuffersUsage | n |
| flink:task:buffers.inputQueueLength | flink/task/buffers.inputQueueLength | n |
| flink:task:buffers.outPoolUsage | flink/task/buffers.outPoolUsage | n |
| flink:task:buffers.outputQueueLength | flink/task/buffers.outputQueueLength | n |
| flink:task:idleTimeMsPerSecond.count | flink/task/idleTimeMsPerSecond.count | n |
| flink:task:idleTimeMsPerSecond.rate | flink/task/idleTimeMsPerSecond.rate | n |
| flink:task:numBuffersInLocal | flink/task/numBuffersInLocal | n |
| flink:task:numBuffersInLocalPerSecond.count | flink/task/numBuffersInLocalPerSecond.count | n |
| flink:task:numBuffersInLocalPerSecond.rate | flink/task/numBuffersInLocalPerSecond.rate | n |
| flink:task:numBuffersInRemote | flink/task/numBuffersInRemote | n |
| flink:task:numBuffersInRemotePerSecond.count | flink/task/numBuffersInRemotePerSecond.count | n |
| flink:task:numBuffersInRemotePerSecond.rate | flink/task/numBuffersInRemotePerSecond.rate | n |
| flink:task:numBuffersOut | flink/task/numBuffersOut | n |
| flink:task:numBuffersOutPerSecond.count | flink/task/numBuffersOutPerSecond.count | n |
| flink:task:numBuffersOutPerSecond.rate | flink/task/numBuffersOutPerSecond.rate | n |
| flink:task:numBytesIn | flink/task/numBytesIn | n |
| flink:task:numBytesInLocal | flink/task/numBytesInLocal | n |
| flink:task:numBytesInLocalPerSecond.count | flink/task/numBytesInLocalPerSecond.count | n |
| flink:task:numBytesInLocalPerSecond.rate | flink/task/numBytesInLocalPerSecond.rate | n |
| flink:task:numBytesInPerSecond.count | flink/task/numBytesInPerSecond.count | n |
| flink:task:numBytesInPerSecond.rate | flink/task/numBytesInPerSecond.rate | n |
| flink:task:numBytesInRemote | flink/task/numBytesInRemote | n |
| flink:task:numBytesInRemotePerSecond.count | flink/task/numBytesInRemotePerSecond.count | n |
| flink:task:numBytesInRemotePerSecond.rate | flink/task/numBytesInRemotePerSecond.rate | n |
| flink:task:numBytesOut | flink/task/numBytesOut | n |
| flink:task:numBytesOutPerSecond.count | flink/task/numBytesOutPerSecond.count | n |
| flink:task:numBytesOutPerSecond.rate | flink/task/numBytesOutPerSecond.rate | n |
| flink:task:numRecordsIn | flink/task/numRecordsIn | n |
| flink:task:numRecordsInPerSecond.count | flink/task/numRecordsInPerSecond.count | n |
| flink:task:numRecordsInPerSecond.rate | flink/task/numRecordsInPerSecond.rate | n |
| flink:task:numRecordsOut | flink/task/numRecordsOut | n |
| flink:task:numRecordsOutPerSecond.count | flink/task/numRecordsOutPerSecond.count | n |
| flink:task:numRecordsOutPerSecond.rate | flink/task/numRecordsOutPerSecond.rate | n |
| flink:task:Shuffle.Netty.Input.Buffers.inPoolUsage | flink/task/Shuffle.Netty.Input.Buffers.inPoolUsage | n |
| flink:task:Shuffle.Netty.Input.Buffers.inputExclusiveBuffersUsage | flink/task/Shuffle.Netty.Input.Buffers.inputExclusiveBuffersUsage | n |
| flink:task:Shuffle.Netty.Input.Buffers.inputFloatingBuffersUsage | flink/task/Shuffle.Netty.Input.Buffers.inputFloatingBuffersUsage | n |
| flink:task:Shuffle.Netty.Input.Buffers.inputQueueLength | flink/task/Shuffle.Netty.Input.Buffers.inputQueueLength | n |
| flink:task:Shuffle.Netty.Input.numBuffersInLocal | flink/task/Shuffle.Netty.Input.numBuffersInLocal | n |
| flink:task:Shuffle.Netty.Input.numBuffersInLocalPerSecond.count | flink/task/Shuffle.Netty.Input.numBuffersInLocalPerSecond.count | n |
| flink:task:Shuffle.Netty.Input.numBuffersInLocalPerSecond.rate | flink/task/Shuffle.Netty.Input.numBuffersInLocalPerSecond.rate | n |
| flink:task:Shuffle.Netty.Input.numBuffersInRemote | flink/task/Shuffle.Netty.Input.numBuffersInRemote | n |
| flink:task:Shuffle.Netty.Input.numBuffersInRemotePerSecond.count | flink/task/Shuffle.Netty.Input.numBuffersInRemotePerSecond.count | n |
| flink:task:Shuffle.Netty.Input.numBuffersInRemotePerSecond.rate | flink/task/Shuffle.Netty.Input.numBuffersInRemotePerSecond.rate | n |
| flink:task:Shuffle.Netty.Input.numBytesInLocal | flink/task/Shuffle.Netty.Input.numBytesInLocal | n |
| flink:task:Shuffle.Netty.Input.numBytesInLocalPerSecond.count | flink/task/Shuffle.Netty.Input.numBytesInLocalPerSecond.count | n |
| flink:task:Shuffle.Netty.Input.numBytesInLocalPerSecond.rate | flink/task/Shuffle.Netty.Input.numBytesInLocalPerSecond.rate | n |
| flink:task:Shuffle.Netty.Input.numBytesInRemote | flink/task/Shuffle.Netty.Input.numBytesInRemote | n |
| flink:task:Shuffle.Netty.Input.numBytesInRemotePerSecond.count | flink/task/Shuffle.Netty.Input.numBytesInRemotePerSecond.count | n |
| flink:task:Shuffle.Netty.Input.numBytesInRemotePerSecond.rate | flink/task/Shuffle.Netty.Input.numBytesInRemotePerSecond.rate | n |
| flink:task:Shuffle.Netty.Output.Buffers.outPoolUsage | flink/task/Shuffle.Netty.Output.Buffers.outPoolUsage | n |
| flink:task:Shuffle.Netty.Output.Buffers.outputQueueLength | flink/task/Shuffle.Netty.Output.Buffers.outputQueueLength | n |
| flink:taskmanager:Status.flink.Memory.Managed.Total | flink/taskmanager/Status.flink.Memory.Managed.Total | n |
| flink:taskmanager:Status.flink.Memory.Managed.Used | flink/taskmanager/Status.flink.Memory.Managed.Used | n |
| flink:taskmanager:Status.JVM.ClassLoader.ClassesLoaded | flink/taskmanager/Status.JVM.ClassLoader.ClassesLoaded | n |
| flink:taskmanager:Status.JVM.ClassLoader.ClassesUnloaded | flink/taskmanager/Status.JVM.ClassLoader.ClassesUnloaded | n |
| flink:taskmanager:Status.JVM.CPU.Load | flink/taskmanager/Status.JVM.CPU.Load | n |
| flink:taskmanager:Status.JVM.CPU.Time | flink/taskmanager/Status.JVM.CPU.Time | y |
| flink:taskmanager:Status.JVM.GarbageCollector.PSMarkSweep.Count | flink/taskmanager/Status.JVM.GarbageCollector.PSMarkSweep.Count | n |
| flink:taskmanager:Status.JVM.GarbageCollector.PSMarkSweep.Time | flink/taskmanager/Status.JVM.GarbageCollector.PSMarkSweep.Time | n |
| flink:taskmanager:Status.JVM.GarbageCollector.PSScavenge.Count | flink/taskmanager/Status.JVM.GarbageCollector.PSScavenge.Count | n |
| flink:taskmanager:Status.JVM.GarbageCollector.PSScavenge.Time | flink/taskmanager/Status.JVM.GarbageCollector.PSScavenge.Time | n |
| flink:taskmanager:Status.JVM.Memory.Direct.Count | flink/taskmanager/Status.JVM.Memory.Direct.Count | y |
| flink:taskmanager:Status.JVM.Memory.Direct.MemoryUsed | flink/taskmanager/Status.JVM.Memory.Direct.MemoryUsed | y |
| flink:taskmanager:Status.JVM.Memory.Direct.TotalCapacity | flink/taskmanager/Status.JVM.Memory.Direct.TotalCapacity | y |
| flink:taskmanager:Status.JVM.Memory.Heap.Committed | flink/taskmanager/Status.JVM.Memory.Heap.Committed | y |
| flink:taskmanager:Status.JVM.Memory.Heap.Max | flink/taskmanager/Status.JVM.Memory.Heap.Max | y |
| flink:taskmanager:Status.JVM.Memory.Heap.Used | flink/taskmanager/Status.JVM.Memory.Heap.Used | y |
| flink:taskmanager:Status.JVM.Memory.Mapped.Count | flink/taskmanager/Status.JVM.Memory.Mapped.Count | y |
| flink:taskmanager:Status.JVM.Memory.Mapped.MemoryUsed | flink/taskmanager/Status.JVM.Memory.Mapped.MemoryUsed | y |
| flink:taskmanager:Status.JVM.Memory.Mapped.TotalCapacity | flink/taskmanager/Status.JVM.Memory.Mapped.TotalCapacity | y |
| flink:taskmanager:Status.JVM.Memory.Metaspace.Committed | flink/taskmanager/Status.JVM.Memory.Metaspace.Committed | n |
| flink:taskmanager:Status.JVM.Memory.Metaspace.Max | flink/taskmanager/Status.JVM.Memory.Metaspace.Max | n |
| flink:taskmanager:Status.JVM.Memory.Metaspace.Used | flink/taskmanager/Status.JVM.Memory.Metaspace.Used | n |
| flink:taskmanager:Status.JVM.Memory.NonHeap.Committed | flink/taskmanager/Status.JVM.Memory.NonHeap.Committed | n |
| flink:taskmanager:Status.JVM.Memory.NonHeap.Max | flink/taskmanager/Status.JVM.Memory.NonHeap.Max | n |
| flink:taskmanager:Status.JVM.Memory.NonHeap.Used | flink/taskmanager/Status.JVM.Memory.NonHeap.Used | n |
| flink:taskmanager:Status.JVM.Threads.Count | flink/taskmanager/Status.JVM.Threads.Count | n |
| flink:taskmanager:Status.Network.AvailableMemorySegments | flink/taskmanager/Status.Network.AvailableMemorySegments | n |
| flink:taskmanager:Status.Network.TotalMemorySegments | flink/taskmanager/Status.Network.TotalMemorySegments | n |
| flink:taskmanager:Status.Shuffle.Netty.AvailableMemory | flink/taskmanager/Status.Shuffle.Netty.AvailableMemory | n |
| flink:taskmanager:Status.Shuffle.Netty.AvailableMemorySegments | flink/taskmanager/Status.Shuffle.Netty.AvailableMemorySegments | n |
| flink:taskmanager:Status.Shuffle.Netty.TotalMemory | flink/taskmanager/Status.Shuffle.Netty.TotalMemory | n |
| flink:taskmanager:Status.Shuffle.Netty.TotalMemorySegments | flink/taskmanager/Status.Shuffle.Netty.TotalMemorySegments | n |
| flink:taskmanager:Status.Shuffle.Netty.UsedMemory | flink/taskmanager/Status.Shuffle.Netty.UsedMemory | n |
| flink:taskmanager:Status.Shuffle.Netty.UsedMemorySegments | flink/taskmanager/Status.Shuffle.Netty.UsedMemorySegments | n |
Métricas del servidor de historial de Spark
Dataproc recopila las siguientes métricas de memoria de la JVM del servicio de historial de Spark:
| Métrica | Nombre del Explorador de métricas | Métricas habilitadas |
|---|---|---|
| sparkHistoryServer:JVM:Memory:HeapMemoryUsage.committed | sparkHistoryServer/memory/CommittedHeapMemory | y |
| sparkHistoryServer:JVM:Memory:HeapMemoryUsage.used | sparkHistoryServer/memory/UsedHeapMemory | y |
| sparkHistoryServer:JVM:Memory:HeapMemoryUsage.max | sparkHistoryServer/memory/MaxHeapMemory | y |
| sparkHistoryServer:JVM:Memory:NonHeapMemoryUsage.committed | sparkHistoryServer/memory/CommittedNonHeapMemory | y |
| sparkHistoryServer:JVM:Memory:NonHeapMemoryUsage.used | sparkHistoryServer/memory/UsedNonHeapMemory | y |
| sparkHistoryServer:JVM:Memory:NonHeapMemoryUsage.max | sparkHistoryServer/memory/MaxNonHeapMemory | y |
Métricas de HiveServer 2
| Métrica | Nombre del Explorador de métricas | Métricas habilitadas |
|---|---|---|
| hiveserver2:JVM:Memory:HeapMemoryUsage.committed | hiveserver2/memory/CommittedHeapMemory | y |
| hiveserver2:JVM:Memory:HeapMemoryUsage.used | hiveserver2/memory/UsedHeapMemory | y |
| hiveserver2:JVM:Memory:HeapMemoryUsage.max | hiveserver2/memory/MaxHeapMemory | y |
| hiveserver2:JVM:Memory:NonHeapMemoryUsage.committed | hiveserver2/memory/CommittedNonHeapMemory | y |
| hiveserver2:JVM:Memory:NonHeapMemoryUsage.used | hiveserver2/memory/UsedNonHeapMemory | y |
| hiveserver2:JVM:Memory:NonHeapMemoryUsage.max | hiveserver2/memory/MaxNonHeapMemory | y |
Métricas de Hive Metastore
| Métrica | Nombre del Explorador de métricas | Métricas habilitadas |
|---|---|---|
| hivemetastore:API:GetDatabase:Mean | hivemetastore/get_database/mean | y |
| hivemetastore:API:CreateDatabase:Mean | hivemetastore/create_database/mean | y |
| hivemetastore:API:DropDatabase:Mean | hivemetastore/drop_database/mean | y |
| hivemetastore:API:AlterDatabase:Mean | hivemetastore/alter_database/mean | y |
| hivemetastore:API:GetAllDatabases:Mean | hivemetastore/get_all_databases/mean | y |
| hivemetastore:API:CreateTable:Mean | hivemetastore/create_table/mean | y |
| hivemetastore:API:DropTable:Mean | hivemetastore/drop_table/mean | y |
| hivemetastore:API:AlterTable:Mean | hivemetastore/alter_table/mean | y |
| hivemetastore:API:GetTable:Mean | hivemetastore/get_table/mean | y |
| hivemetastore:API:GetAllTables:Mean | hivemetastore/get_all_tables/mean | y |
| hivemetastore:API:AddPartitionsReq:Mean | hivemetastore/add_partitions_req/mean | y |
| hivemetastore:API:DropPartition:Mean | hivemetastore/drop_partition/mean | y |
| hivemetastore:API:AlterPartition:Mean | hivemetastore/alter_partition/mean | y |
| hivemetastore:API:GetPartition:Mean | hivemetastore/get_partition/mean | y |
| hivemetastore:API:GetPartitionNames:Mean | hivemetastore/get_partition_names/mean | y |
| hivemetastore:API:GetPartitionsPs:Mean | hivemetastore/get_partitions_ps/mean | y |
| hivemetastore:API:GetPartitionsPsWithAuth:Mean | hivemetastore/get_partitions_ps_with_auth/mean | y |
Medidas de métricas de Hive Metastore
| Medida estadística | Métrica de ejemplo | Nombre de la métrica de muestra |
|---|---|---|
| Máx. | hivemetastore:API:GetDatabase:Max | hivemetastore/get_database/max |
| Mín. | hivemetastore:API:GetDatabase:Min | hivemetastore/get_database/min |
| Media | hivemetastore:API:GetDatabase:Mean | hivemetastore/get_database/mean |
| Recuento | hivemetastore:API:GetDatabase:Count | hivemetastore/get_database/count |
| 50thPercentile | hivemetastore:API:GetDatabase:50thPercentile | hivemetastore/get_database/median |
| 75thPercentile | hivemetastore:API:GetDatabase:75thPercentile | hivemetastore/get_database/75th_percentile |
| 95thPercentile | hivemetastore:API:GetDatabase:95thPercentile | hivemetastore/get_database/95th_percentile |
| 98thPercentile | hivemetastore:API:GetDatabase:98thPercentile | hivemetastore/get_database/percentil_98 |
| 99thPercentile | hivemetastore:API:GetDatabase:99thPercentile | hivemetastore/get_database/99th_percentile |
| 999thPercentile | hivemetastore:API:GetDatabase:999thPercentile | hivemetastore/get_database/999th_percentile |
| StdDev | hivemetastore:API:GetDatabase:StdDev | hivemetastore/get_database/stddev |
| FifteenMinuteRate | hivemetastore:API:GetDatabase:FifteenMinuteRate | hivemetastore/get_database/15min_rate |
| FiveMinuteRate | hivemetastore:API:GetDatabase:FiveMinuteRate | hivemetastore/get_database/5min_rate |
| OneMinuteRate | hivemetastore:API:GetDatabase:OneMinuteRate | hivemetastore/get_database/1min_rate |
| MeanRate | hivemetastore:API:GetDatabase:MeanRate | hivemetastore/get_database/mean_rate |
Métricas del agente de supervisión de Dataproc
Dataproc recopila las siguientes métricas del agente de supervisión de Dataproc cuando configuras --metric-sources=monitoring-agent-defaults.
Estas métricas se publican con el prefijo agent.googleapis.com.
CPU
agent.googleapis.com/cpu/load_15m
agent.googleapis.com/cpu/load_1m
agent.googleapis.com/cpu/load_5m
agent.googleapis.com/cpu/usage_time*
agent.googleapis.com/cpu/utilization*
Disco
agent.googleapis.com/disk/bytes_used
agent.googleapis.com/disk/io_time
agent.googleapis.com/disk/merged_operations
agent.googleapis.com/disk/operation_count
agent.googleapis.com/disk/operation_time
agent.googleapis.com/disk/pending_operations
agent.googleapis.com/disk/percent_used
agent.googleapis.com/disk/read_bytes_count
Swap
agent.googleapis.com/swap/bytes_used
agent.googleapis.com/swap/io
agent.googleapis.com/swap/percent_used
Memoria
agent.googleapis.com/memory/bytes_used
agent.googleapis.com/memory/percent_used
Procesos: Algunos atributos siguen políticas de cuotas únicas.
agent.googleapis.com/processes/count_by_state
agent.googleapis.com/processes/cpu_time
agent.googleapis.com/processes/disk/read_bytes_count
agent.googleapis.com/processes/disk/write_bytes_count
agent.googleapis.com/processes/fork_count
agent.googleapis.com/processes/rss_usage
agent.googleapis.com/processes/vm_usage
Interface
agent.googleapis.com/interface/errors
agent.googleapis.com/interface/packets
agent.googleapis.com/interface/traffic
Red
agent.googleapis.com/network/tcp_connections
Compila un panel de Monitoring
Puedes compilar un panel de Monitoring que muestre gráficos de métricas seleccionadas de Dataproc.
Selecciona + CREAR PANEL en la página Descripción general de los paneles de Monitoring. Ingresa un nombre para el panel y, luego, haz clic en Agregar gráfico en el menú superior derecho para abrir la ventana Agregar gráfico. Selecciona "Cloud Dataproc Cluster" (clúster de Cloud Dataproc) como el tipo de recurso. Selecciona una o varias métricas y propiedades de estas y de gráficos. Luego, guarda el gráfico.
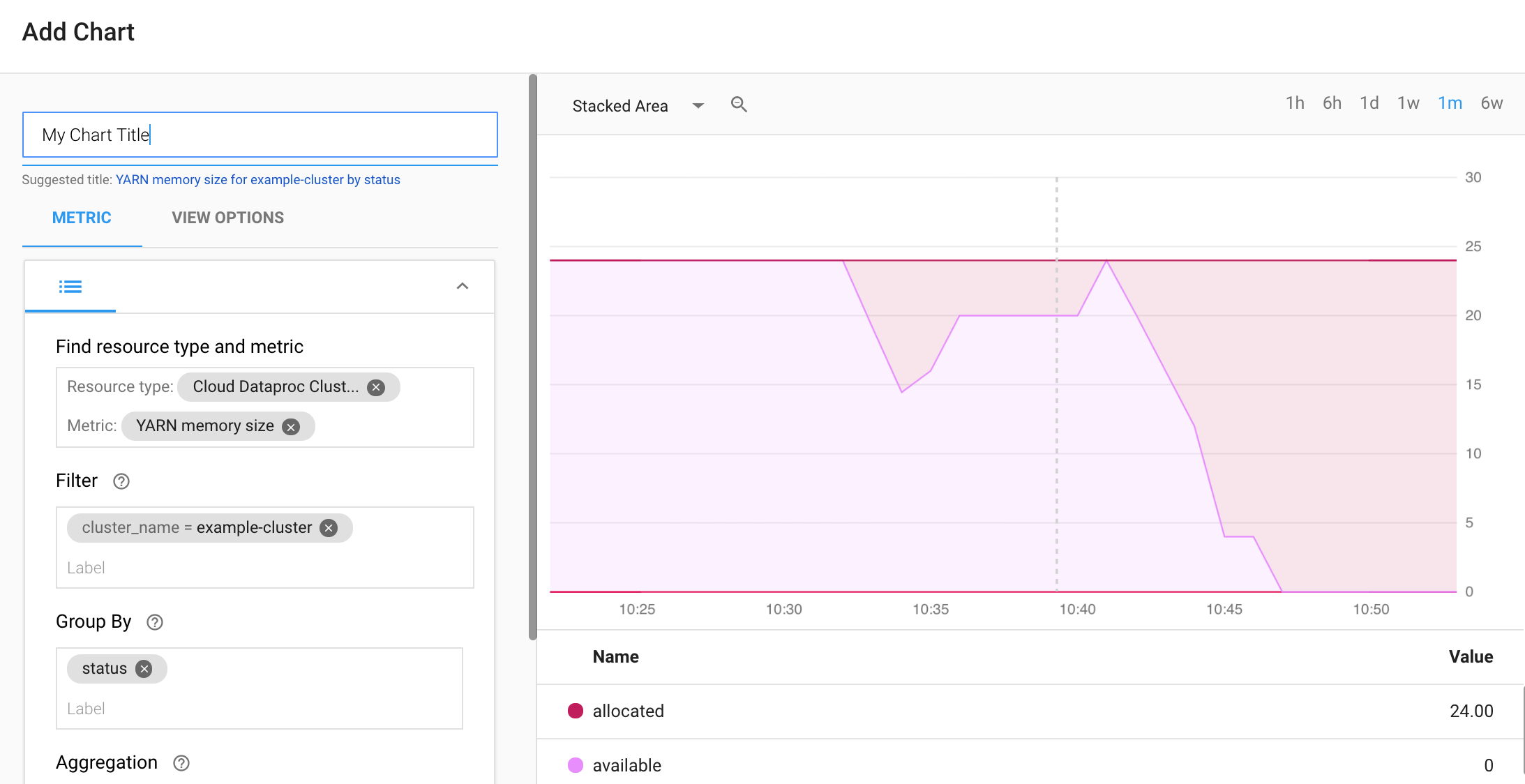
Puedes agregar gráficos adicionales a tu panel. Después de guardar el panel, su título aparecerá en la página Descripción general de los paneles de Monitoring. Los gráficos de paneles pueden verse, actualizarse y borrarse en la página de visualización de paneles.
Qué sigue
- Consulta la documentación de Cloud Monitoring.
- Aprende a crear alertas de métricas de Dataproc