Cloud Monitoring offre maggiore visibilità su prestazioni, uptime e integrità complessiva delle applicazioni basate su cloud. Google Cloud Observability raccoglie e inserisce metriche, eventi e metadati dai cluster Dataproc, incluse le metriche HDFS, YARN, dei job e delle operazioni per cluster, per generare approfondimenti tramite dashboard e grafici (vedi Metriche Dataproc di Cloud Monitoring).
Consulta la pagina Prezzi di Cloud Monitoring per comprendere i costi.
Per informazioni sulla conservazione dei dati delle metriche, consulta Quote e limiti di Monitoring.
Raccolta delle metriche delle risorse Dataproc
Cloud Monitoring raccoglie le metriche relative alle seguenti risorse Dataproc:
- Cluster Cloud Dataproc
- Job Cloud Dataproc
- Batch Cloud Dataproc
- Sessione Cloud Dataproc
Le metriche delle risorse Dataproc vengono raccolte nel seguente formato:
dataproc.googleapis.com/RESOURCE/METRIC,
e includono la raccolta di diverse metriche OSS.
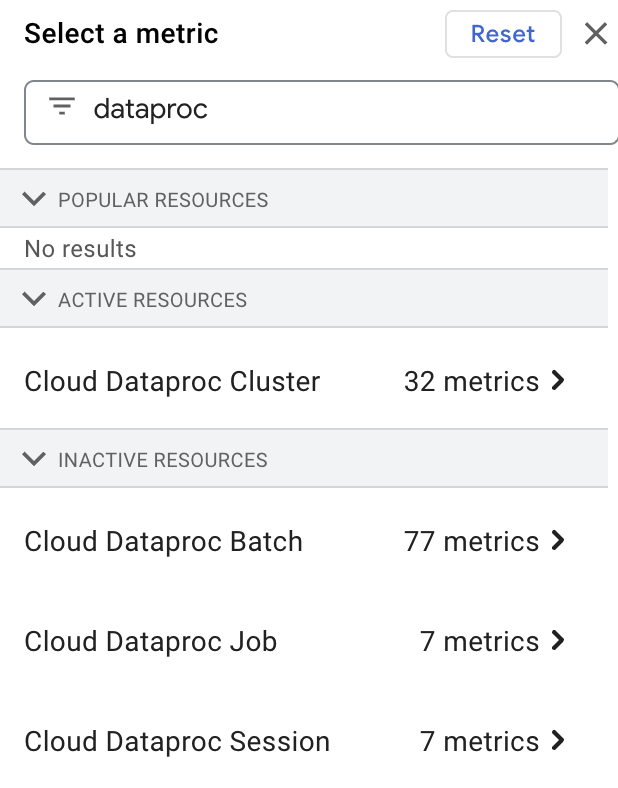
Visualizza le metriche delle risorse Dataproc
Puoi selezionare e visualizzare le metriche delle risorse Dataproc in
Metrics Explorer
digitando "dataproc" nella casella Filter by resource or metric name, quindi selezionando
una risorsa "Cloud Dataproc".
Raccolta di metriche personalizzate
Quando crei un cluster Dataproc, puoi abilitare la raccolta di metriche da una o più origini metrica personalizzata. Viene raccolto un insieme standard di metriche da ogni origine metriche abilitata, a meno che tu non specifichi le metriche da raccogliere da un'origine metriche (le metriche specificate dall'utente sono chiamate "override" delle metriche).
Le metriche OSS personalizzate vengono raccolte nel seguente formato:
custom.googleapis.com/OSS_COMPONENT/METRIC
Esempi di metriche OSS personalizzate:
custom.googleapis.com/spark/driver/DAGScheduler/job/allJobs custom.googleapis.com/hiveserver2/memory/MaxNonHeapMemory
Abilita la raccolta metrica personalizzata
Puoi utilizzare gcloud CLI o l'API Dataproc per abilitare la raccolta di metriche personalizzate da una o più origini metriche.
Interfaccia a riga di comando gcloud
Raccolta di metriche personalizzate
Utilizza il flag
gcloud dataproc clusters create --metric-sources
per attivare la raccolta di
metriche personalizzate
da una o più origini metriche.
gcloud dataproc clusters create cluster-name \ --metric-sources=METRIC_SOURCE(s) \ ... other flags
Note:
--metric-sources: obbligatorio per abilitare la raccolta di metrica personalizzata. Specifica una o più delle seguenti origini delle metriche:spark,flink,hdfs,yarn,spark-history-server,hiveserver2,hivemetastoreemonitoring-agent-defaults. Il nome dell'origine della metrica non fa distinzione tra maiuscole e minuscole, ad esempio sono accettabili sia "yarn" sia "YARN".- monitoring-agent-defaults non sono disponibili nei cluster con versione immagine 2.2. Puoi installare Ops Agent, che raccoglie log syslog e metriche host .
Eseguire l'override della raccolta delle metriche
(Facoltativo) Aggiungi il flag
--metric-overrides o
--metric-overrides-file
per attivare la raccolta di una o più
metriche personalizzate
da una o più origini metriche.
-
Qualsiasi metrica personalizzata e tutte le
metriche Spark,
possono essere elencate per la raccolta come override delle metriche. I valori delle metriche di override
sono sensibili alle maiuscole e devono essere forniti, se appropriato, nel formato CamelCase.
Esempi:
sparkHistoryServer:JVM:Memory:NonHeapMemoryUsage.committedhiveserver2:JVM:Memory:NonHeapMemoryUsage.usedyarn:ResourceManager:JvmMetrics:MemHeapMaxM
-
Verranno raccolte solo le metriche sostituite specificate da una determinata
origine metrica. Ad esempio, se una o più
spark:executivemetriche sono elencate come override delle metriche, le altreSPARKmetriche non verranno raccolte. La raccolta di metriche personalizzate da altre origini metriche non è interessata. Ad esempio, se sono abilitate entrambe le origini metricheSPARKeYARNe vengono forniti override solo per le metriche Spark, verrà raccolto il set standard di metriche YARN abilitate. -
L'origine dell'override della metrica specificata deve essere attivata. Ad esempio, se una o più metriche
spark:drivervengono fornite come override delle metriche, l'origine della metricasparkdeve essere abilitata (--metric-sources=spark).
Elenco di override delle metriche
gcloud dataproc clusters create cluster-name \ --metric-sources=METRIC_SOURCE(s) \ --metric-overrides=LIST_OF_METRIC_OVERRIDES \ ... other flags
Note:
--metric-sources: obbligatorio per abilitare la raccolta di metrica personalizzata. Specifica una o più delle seguenti origini delle metriche:spark,flink,hdfs,yarn,spark-history-server,hiveserver2,hivemetastoreemonitoring-agent-defaults. Il nome dell'origine della metrica non fa distinzione tra maiuscole e minuscole, ad esempio sono accettabili sia "yarn" sia "YARN".--metric-overrides: fornisci un elenco di metriche nel seguente formato:METRIC_SOURCE:INSTANCE:GROUP:METRIC
Esempio:
--metric-overrides=sparkHistoryServer:JVM:Memory:NonHeapMemoryUsage.committedQuesto flag è un'alternativa al flag
--metric-overrides-filee non può essere utilizzato con quest'ultimo.
File di override delle metriche
gcloud dataproc clusters create cluster-name \ --metric-sources=METRIC-SOURCE(s) \ --metric-overrides-file=METRIC_OVERRIDES_FILENAME \ ... other flags
Note:
-
--metric-sources: obbligatorio per abilitare la raccolta di metrica personalizzata. Specifica una o più delle seguenti origini delle metriche:spark,flink,hdfs,yarn,spark-history-server,hiveserver2,hivemetastoreemonitoring-agent-defaults. Il nome dell'origine della metrica non fa distinzione tra maiuscole e minuscole, ad esempio sono accettabili sia "yarn" sia "YARN". -
--metric-overrides-file: specifica un file locale o Cloud Storage (gs://bucket/filename) che contiene una o più metriche nel seguente formato:METRIC_SOURCE:INSTANCE:GROUP:METRIC
Utilizza il formato camel case in modo appropriato.Esempi:
--metric-overrides-file=gs://my-bucket/my-filename.txt--metric-overrides-file=./local-directory/local-filename.txtQuesto flag è un'alternativa al flag
--metric-overridese non può essere utilizzato con quest'ultimo.
API REST
Utilizza DataprocMetricConfig come parte di una richiesta clusters.create per attivare la raccolta di metriche personalizzate. Nota: monitoring-agent-defaults non sono disponibili nei cluster con versione immagine 2.2, a meno che non sia installato Ops Agent.
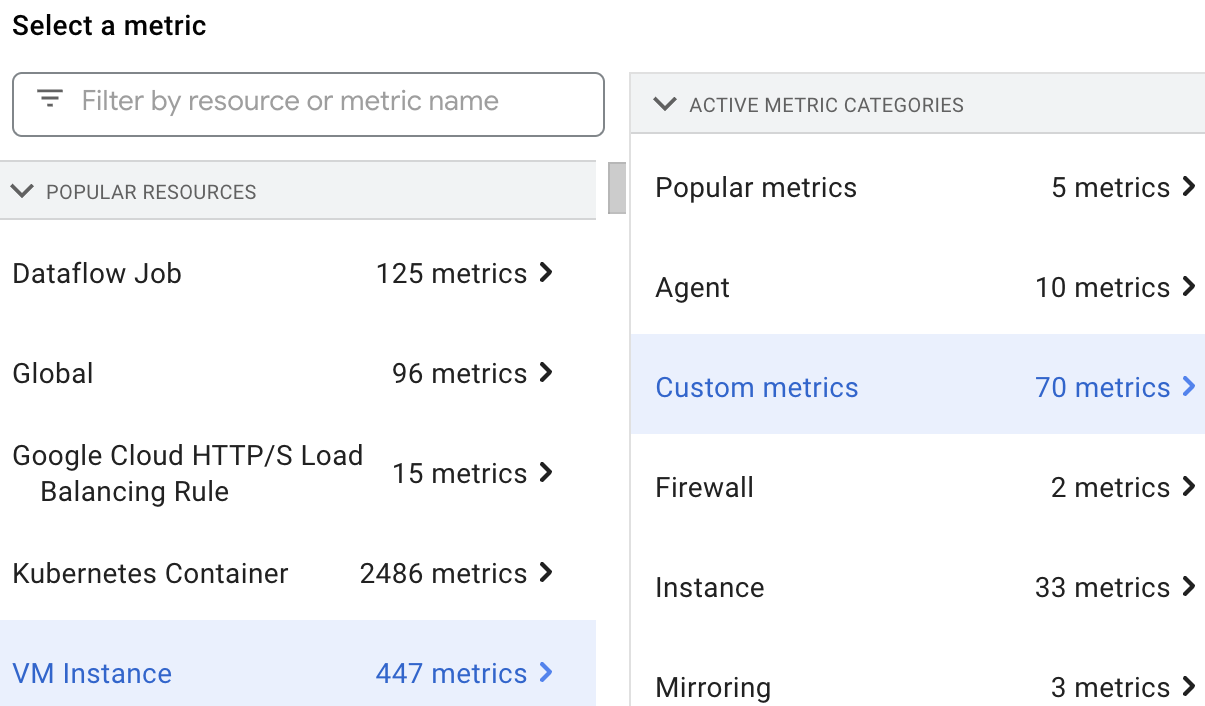
Visualizzare le metriche personalizzate
Puoi selezionare e visualizzare le metriche delle risorse Dataproc in
Esplora metriche
selezionando la risorsa VM Instance e poi Custom metrics.
Metriche personalizzate
Puoi abilitare Dataproc per raccogliere le metriche personalizzate elencate nelle tabelle seguenti.
La colonna Metriche abilitate è contrassegnata con "y" se Dataproc raccoglie la metrica quando abiliti l'origine metrica associata.
Qualsiasi metrica elencata per un'origine metrica e tutte le metriche Spark possono essere abilitate per la raccolta se esegui l'override della raccolta del set standard di metriche abilitate per l'origine metrica (vedi Abilitare la raccolta di metrica personalizzata personalizzate).
Dataproc utilizza l'agente di monitoraggio per raccogliere le metriche. L'abilitazione di qualsiasi origine metrica consente la raccolta delle metriche dell'agente. Queste metriche non vengono fatturate agli utenti. Dataproc le utilizza per diagnosticare i problemi di raccolta delle metriche.
Metriche Hadoop
Metriche HDFS
| Metrica | Nome di Metrics Explorer | Metriche abilitate |
|---|---|---|
| hdfs:NameNode:FSNamesystem:CapacityTotalGB | dfs/FSNamesystem/CapacityTotalGB | y |
| hdfs:NameNode:FSNamesystem:CapacityUsedGB | dfs/FSNamesystem/CapacityUsedGB | y |
| hdfs:NameNode:FSNamesystem:CapacityRemainingGB | dfs/FSNamesystem/CapacityRemainingGB | y |
| hdfs:NameNode:FSNamesystem:FilesTotal | dfs/FSNamesystem/FilesTotal | y |
| hdfs:NameNode:FSNamesystem:MissingBlocks | dfs/FSNamesystem/MissingBlocks | n |
| hdfs:NameNode:FSNamesystem:ExpiredHeartbeats | dfs/FSNamesystem/ExpiredHeartbeats | n |
| hdfs:NameNode:FSNamesystem:TransactionsSinceLastCheckpoint | dfs/FSNamesystem/TransactionsSinceLastCheckpoint | n |
| hdfs:NameNode:FSNamesystem:TransactionsSinceLastLogRoll | dfs/FSNamesystem/TransactionsSinceLastLogRoll | n |
| hdfs:NameNode:FSNamesystem:LastWrittenTransactionId | dfs/FSNamesystem/LastWrittenTransactionId | n |
| hdfs:NameNode:FSNamesystem:CapacityTotal | dfs/FSNamesystem/CapacityTotal | n |
| hdfs:NameNode:FSNamesystem:CapacityUsed | dfs/FSNamesystem/CapacityUsed | n |
| hdfs:NameNode:FSNamesystem:CapacityRemaining | dfs/FSNamesystem/CapacityRemaining | n |
| hdfs:NameNode:FSNamesystem:CapacityUsedNonDFS | dfs/FSNamesystem/CapacityUsedNonDFS | n |
| hdfs:NameNode:FSNamesystem:TotalLoad | dfs/FSNamesystem/TotalLoad | n |
| hdfs:NameNode:FSNamesystem:SnapshottableDirectories | dfs/FSNamesystem/SnapshottableDirectories | n |
| hdfs:NameNode:FSNamesystem:Snapshots | dfs/FSNamesystem/Snapshots | n |
| hdfs:NameNode:FSNamesystem:BlocksTotal | dfs/FSNamesystem/BlocksTotal | n |
| hdfs:NameNode:FSNamesystem:PendingReplicationBlocks | dfs/FSNamesystem/PendingReplicationBlocks | n |
| hdfs:NameNode:FSNamesystem:UnderReplicatedBlocks | dfs/FSNamesystem/UnderReplicatedBlocks | n |
| hdfs:NameNode:FSNamesystem:CorruptBlocks | dfs/FSNamesystem/CorruptBlocks | n |
| hdfs:NameNode:FSNamesystem:ScheduledReplicationBlocks | dfs/FSNamesystem/ScheduledReplicationBlocks | n |
| hdfs:NameNode:FSNamesystem:PendingDeletionBlocks | dfs/FSNamesystem/PendingDeletionBlocks | n |
| hdfs:NameNode:FSNamesystem:ExcessBlocks | dfs/FSNamesystem/ExcessBlocks | n |
| hdfs:NameNode:FSNamesystem:PostponedMisreplicatedBlocks | dfs/FSNamesystem/PostponedMisreplicatedBlocks | n |
| hdfs:NameNode:FSNamesystem:PendingDataNodeMessageCourt | dfs/FSNamesystem/PendingDataNodeMessageCourt | n |
| hdfs:NameNode:FSNamesystem:MillisSinceLastLoadedEdits | dfs/FSNamesystem/MillisSinceLastLoadedEdits | n |
| hdfs:NameNode:FSNamesystem:BlockCapacity | dfs/FSNamesystem/BlockCapacity | n |
| hdfs:NameNode:FSNamesystem:StaleDataNodes | dfs/FSNamesystem/StaleDataNodes | n |
| hdfs:NameNode:FSNamesystem:TotalFiles | dfs/FSNamesystem/TotalFiles | n |
| hdfs:NameNode:JvmMetrics:MemHeapUsedM | dfs/jvm/MemHeapUsedM | n |
| hdfs:NameNode:JvmMetrics:MemHeapCommittedM | dfs/jvm/MemHeapCommittedM | n |
| hdfs:NameNode:JvmMetrics:MemHeapMaxM | dfs/jvm/MemHeapMaxM | n |
| hdfs:NameNode:JvmMetrics:MemMaxM | dfs/jvm/MemMaxM | n |
Metriche YARN
| Metrica | Nome di Metrics Explorer | Metriche abilitate |
|---|---|---|
| yarn:ResourceManager:ClusterMetrics:NumActiveNMs | yarn/ClusterMetrics/NumActiveNMs | y |
| yarn:ResourceManager:ClusterMetrics:NumDecommissionedNMs | yarn/ClusterMetrics/NumDecommissionedNMs | n |
| yarn:ResourceManager:ClusterMetrics:NumLostNMs | yarn/ClusterMetrics/NumLostNMs | n |
| yarn:ResourceManager:ClusterMetrics:NumUnhealthyNMs | yarn/ClusterMetrics/NumUnhealthyNMs | n |
| yarn:ResourceManager:ClusterMetrics:NumRebootedNMs | yarn/ClusterMetrics/NumRebootedNMs | n |
| yarn:ResourceManager:QueueMetrics:running_0 | yarn/QueueMetrics/running_0 | y |
| yarn:ResourceManager:QueueMetrics:running_60 | yarn/QueueMetrics/running_60 | y |
| yarn:ResourceManager:QueueMetrics:running_300 | yarn/QueueMetrics/running_300 | y |
| yarn:ResourceManager:QueueMetrics:running_1440 | yarn/QueueMetrics/running_1440 | y |
| yarn:ResourceManager:QueueMetrics:AppsSubmitted | yarn/QueueMetrics/AppsSubmitted | y |
| yarn:ResourceManager:QueueMetrics:AvailableMB | yarn/QueueMetrics/AvailableMB | y |
| yarn:ResourceManager:QueueMetrics:PendingContainers | yarn/QueueMetrics/PendingContainers | y |
| yarn:ResourceManager:QueueMetrics:AppsRunning | yarn/QueueMetrics/AppsRunning | n |
| yarn:ResourceManager:QueueMetrics:AppsPending | yarn/QueueMetrics/AppsPending | n |
| yarn:ResourceManager:QueueMetrics:AppsCompleted | yarn/QueueMetrics/AppsCompleted | n |
| yarn:ResourceManager:QueueMetrics:AppsKilled | yarn/QueueMetrics/AppsKilled | n |
| yarn:ResourceManager:QueueMetrics:AppsFailed | yarn/QueueMetrics/AppsFailed | n |
| yarn:ResourceManager:QueueMetrics:AllocatedMB | yarn/QueueMetrics/AllocatedMB | n |
| yarn:ResourceManager:QueueMetrics:AllocatedVCores | yarn/QueueMetrics/AllocatedVCores | n |
| yarn:ResourceManager:QueueMetrics:AllocatedContainers | yarn/QueueMetrics/AllocatedContainers | n |
| yarn:ResourceManager:QueueMetrics:AggregateContainersAllocated | yarn/QueueMetrics/AggregateContainersAllocated | n |
| yarn:ResourceManager:QueueMetrics:AggregateContainersReleased | yarn/QueueMetrics/AggregateContainersReleased | n |
| yarn:ResourceManager:QueueMetrics:AvailableVCores | yarn/QueueMetrics/AvailableVCores | n |
| yarn:ResourceManager:QueueMetrics:PendingMB | yarn/QueueMetrics/PendingMB | n |
| yarn:ResourceManager:QueueMetrics:PendingVCores | yarn/QueueMetrics/PendingVCores | n |
| yarn:ResourceManager:QueueMetrics:ReservedMB | yarn/QueueMetrics/ReservedMB | n |
| yarn:ResourceManager:QueueMetrics:ReservedVCores | yarn/QueueMetrics/ReservedVCores | n |
| yarn:ResourceManager:QueueMetrics:ReservedContainers | yarn/QueueMetrics/ReservedContainers | n |
| yarn:ResourceManager:QueueMetrics:ActiveUsers | yarn/QueueMetrics/ActiveUsers | n |
| yarn:ResourceManager:QueueMetrics:ActiveApplications | yarn/QueueMetrics/ActiveApplications | n |
| yarn:ResourceManager:QueueMetrics:FairShareMB | yarn/QueueMetrics/FairShareMB | n |
| yarn:ResourceManager:QueueMetrics:FairShareVCores | yarn/QueueMetrics/FairShareVCores | n |
| yarn:ResourceManager:QueueMetrics:MinShareMB | yarn/QueueMetrics/MinShareMB | n |
| yarn:ResourceManager:QueueMetrics:MinShareVCores | yarn/QueueMetrics/MinShareVCores | n |
| yarn:ResourceManager:QueueMetrics:MaxShareMB | yarn/QueueMetrics/MaxShareMB | n |
| yarn:ResourceManager:QueueMetrics:MaxShareVCores | yarn/QueueMetrics/MaxShareVCores | n |
| yarn:ResourceManager:JvmMetrics:MemHeapUsedM | yarn/jvm/MemHeapUsedM | n |
| yarn:ResourceManager:JvmMetrics:MemHeapCommittedM | yarn/jvm/MemHeapCommittedM | n |
| yarn:ResourceManager:JvmMetrics:MemHeapMaxM | yarn/jvm/MemHeapMaxM | n |
| yarn:ResourceManager:JvmMetrics:MemMaxM | yarn/jvm/MemMaxM | n |
Metriche di Spark
Metriche del driver Spark
| Metrica | Nome di Metrics Explorer | Metriche abilitate |
|---|---|---|
| spark:driver:BlockManager:disk.diskSpaceUsed_MB | spark/driver/BlockManager/disk/diskSpaceUsed_MB | y |
| spark:driver:BlockManager:memory.maxMem_MB | spark/driver/BlockManager/memory/maxMem_MB | y |
| spark:driver:BlockManager:memory.memUsed_MB | spark/driver/BlockManager/memory/memUsed_MB | y |
| spark:driver:DAGScheduler:job.allJobs | spark/driver/DAGScheduler/job/allJobs | y |
| spark:driver:DAGScheduler:stage.failedStages | spark/driver/DAGScheduler/stage/failedStages | y |
| spark:driver:DAGScheduler:stage.waitingStages | spark/driver/DAGScheduler/stage/waitingStages | y |
Metriche dell'esecutore Spark
| Metrica | Nome di Metrics Explorer | Metriche abilitate |
|---|---|---|
| spark:executor:executor:bytesRead | spark/executor/bytesRead | y |
| spark:executor:executor:bytesWritten | spark/executor/bytesWritten | y |
| spark:executor:executor:cpuTime | spark/executor/cpuTime | y |
| spark:executor:executor:diskBytesSpilled | spark/executor/diskBytesSpilled | y |
| spark:executor:executor:recordsRead | spark/executor/recordsRead | y |
| spark:executor:executor:recordsWritten | spark/executor/recordsWritten | y |
| spark:executor:executor:runTime | spark/executor/runTime | y |
| spark:executor:executor:shuffleRecordsRead | spark/executor/shuffleRecordsRead | y |
| spark:executor:executor:shuffleRecordsWritten | spark/executor/shuffleRecordsWritten | y |
Metriche Flink
| Metrica | Nome di Metrics Explorer | Metriche abilitate |
|---|---|---|
| flink:jobmanager:numRegisteredTaskManagers | flink/jobmanager/numRegisteredTaskManagers | n |
| flink:jobmanager:numRunningJobs | flink/jobmanager/numRunningJobs | n |
| flink:jobmanager:Status.JVM.ClassLoader.ClassesLoaded | flink/jobmanager/Status.JVM.ClassLoader.ClassesLoaded | n |
| flink:jobmanager:Status.JVM.ClassLoader.ClassesUnloaded | flink/jobmanager/Status.JVM.ClassLoader.ClassesUnloaded | n |
| flink:jobmanager:Status.JVM.CPU.Load | flink/jobmanager/Status.JVM.CPU.Load | n |
| flink:jobmanager:Status.JVM.CPU.Time | flink/jobmanager/Status.JVM.CPU.Time | y |
| flink:jobmanager:Status.JVM.GarbageCollector.PSMarkSweep.Count | flink/jobmanager/Status.JVM.GarbageCollector.PSMarkSweep.Count | n |
| flink:jobmanager:Status.JVM.GarbageCollector.PSMarkSweep.Time | flink/jobmanager/Status.JVM.GarbageCollector.PSMarkSweep.Time | n |
| flink:jobmanager:Status.JVM.GarbageCollector.PSScavenge.Count | flink/jobmanager/Status.JVM.GarbageCollector.PSScavenge.Count | n |
| flink:jobmanager:Status.JVM.GarbageCollector.PSScavenge.Time | flink/jobmanager/Status.JVM.GarbageCollector.PSScavenge.Time | n |
| flink:jobmanager:Status.JVM.Memory.Direct.Count | flink/jobmanager/Status.JVM.Memory.Direct.Count | y |
| flink:jobmanager:Status.JVM.Memory.Direct.MemoryUsed | flink/jobmanager/Status.JVM.Memory.Direct.MemoryUsed | y |
| flink:jobmanager:Status.JVM.Memory.Direct.TotalCapacity | flink/jobmanager/Status.JVM.Memory.Direct.TotalCapacity | y |
| flink:jobmanager:Status.JVM.Memory.Heap.Committed | flink/jobmanager/Status.JVM.Memory.Heap.Committed | y |
| flink:jobmanager:Status.JVM.Memory.Heap.Max | flink/jobmanager/Status.JVM.Memory.Heap.Max | y |
| flink:jobmanager:Status.JVM.Memory.Heap.Used | flink/jobmanager/Status.JVM.Memory.Heap.Used | y |
| flink:jobmanager:Status.JVM.Memory.Mapped.Count | flink/jobmanager/Status.JVM.Memory.Mapped.Count | y |
| flink:jobmanager:Status.JVM.Memory.Mapped.MemoryUsed | flink/jobmanager/Status.JVM.Memory.Mapped.MemoryUsed | y |
| flink:jobmanager:Status.JVM.Memory.Mapped.TotalCapacity | flink/jobmanager/Status.JVM.Memory.Mapped.TotalCapacity | y |
| flink:jobmanager:Status.JVM.Memory.Metaspace.Committed | flink/jobmanager/Status.JVM.Memory.Metaspace.Committed | n |
| flink:jobmanager:Status.JVM.Memory.Metaspace.Max | flink/jobmanager/Status.JVM.Memory.Metaspace.Max | n |
| flink:jobmanager:Status.JVM.Memory.Metaspace.Used | flink/jobmanager/Status.JVM.Memory.Metaspace.Used | n |
| flink:jobmanager:Status.JVM.Memory.NonHeap.Committed | flink/jobmanager/Status.JVM.Memory.NonHeap.Committed | n |
| flink:jobmanager:Status.JVM.Memory.NonHeap.Max | flink/jobmanager/Status.JVM.Memory.NonHeap.Max | n |
| flink:jobmanager:Status.JVM.Memory.NonHeap.Used | flink/jobmanager/Status.JVM.Memory.NonHeap.Used | n |
| flink:jobmanager:Status.JVM.Threads.Count | flink/jobmanager/Status.JVM.Threads.Count | n |
| flink:jobmanager:taskSlotsAvailable | flink/jobmanager/taskSlotsAvailable | y |
| flink:jobmanager:taskSlotsTotal | flink/jobmanager/taskSlotsTotal | y |
| flink:operator:numRecordsIn | flink/operator/numRecordsIn | n |
| flink:operator:numRecordsInPerSecond.count | flink/operator/numRecordsInPerSecond.count | n |
| flink:operator:numRecordsInPerSecond.rate | flink/operator/numRecordsInPerSecond.rate | n |
| flink:operator:numRecordsOut | flink/operator/numRecordsOut | n |
| flink:operator:numRecordsOutPerSecond.count | flink/operator/numRecordsOutPerSecond.count | n |
| flink:operator:numRecordsOutPerSecond.rate | flink/operator/numRecordsOutPerSecond.rate | n |
| flink:operator:numSplitsProcessed | flink/operator/numSplitsProcessed | n |
| flink:task:buffers.inPoolUsage | flink/task/buffers.inPoolUsage | n |
| flink:task:buffers.inputExclusiveBuffersUsage | flink/task/buffers.inputExclusiveBuffersUsage | n |
| flink:task:buffers.inputFloatingBuffersUsage | flink/task/buffers.inputFloatingBuffersUsage | n |
| flink:task:buffers.inputQueueLength | flink/task/buffers.inputQueueLength | n |
| flink:task:buffers.outPoolUsage | flink/task/buffers.outPoolUsage | n |
| flink:task:buffers.outputQueueLength | flink/task/buffers.outputQueueLength | n |
| flink:task:idleTimeMsPerSecond.count | flink/task/idleTimeMsPerSecond.count | n |
| flink:task:idleTimeMsPerSecond.rate | flink/task/idleTimeMsPerSecond.rate | n |
| flink:task:numBuffersInLocal | flink/task/numBuffersInLocal | n |
| flink:task:numBuffersInLocalPerSecond.count | flink/task/numBuffersInLocalPerSecond.count | n |
| flink:task:numBuffersInLocalPerSecond.rate | flink/task/numBuffersInLocalPerSecond.rate | n |
| flink:task:numBuffersInRemote | flink/task/numBuffersInRemote | n |
| flink:task:numBuffersInRemotePerSecond.count | flink/task/numBuffersInRemotePerSecond.count | n |
| flink:task:numBuffersInRemotePerSecond.rate | flink/task/numBuffersInRemotePerSecond.rate | n |
| flink:task:numBuffersOut | flink/task/numBuffersOut | n |
| flink:task:numBuffersOutPerSecond.count | flink/task/numBuffersOutPerSecond.count | n |
| flink:task:numBuffersOutPerSecond.rate | flink/task/numBuffersOutPerSecond.rate | n |
| flink:task:numBytesIn | flink/task/numBytesIn | n |
| flink:task:numBytesInLocal | flink/task/numBytesInLocal | n |
| flink:task:numBytesInLocalPerSecond.count | flink/task/numBytesInLocalPerSecond.count | n |
| flink:task:numBytesInLocalPerSecond.rate | flink/task/numBytesInLocalPerSecond.rate | n |
| flink:task:numBytesInPerSecond.count | flink/task/numBytesInPerSecond.count | n |
| flink:task:numBytesInPerSecond.rate | flink/task/numBytesInPerSecond.rate | n |
| flink:task:numBytesInRemote | flink/task/numBytesInRemote | n |
| flink:task:numBytesInRemotePerSecond.count | flink/task/numBytesInRemotePerSecond.count | n |
| flink:task:numBytesInRemotePerSecond.rate | flink/task/numBytesInRemotePerSecond.rate | n |
| flink:task:numBytesOut | flink/task/numBytesOut | n |
| flink:task:numBytesOutPerSecond.count | flink/task/numBytesOutPerSecond.count | n |
| flink:task:numBytesOutPerSecond.rate | flink/task/numBytesOutPerSecond.rate | n |
| flink:task:numRecordsIn | flink/task/numRecordsIn | n |
| flink:task:numRecordsInPerSecond.count | flink/task/numRecordsInPerSecond.count | n |
| flink:task:numRecordsInPerSecond.rate | flink/task/numRecordsInPerSecond.rate | n |
| flink:task:numRecordsOut | flink/task/numRecordsOut | n |
| flink:task:numRecordsOutPerSecond.count | flink/task/numRecordsOutPerSecond.count | n |
| flink:task:numRecordsOutPerSecond.rate | flink/task/numRecordsOutPerSecond.rate | n |
| flink:task:Shuffle.Netty.Input.Buffers.inPoolUsage | flink/task/Shuffle.Netty.Input.Buffers.inPoolUsage | n |
| flink:task:Shuffle.Netty.Input.Buffers.inputExclusiveBuffersUsage | flink/task/Shuffle.Netty.Input.Buffers.inputExclusiveBuffersUsage | n |
| flink:task:Shuffle.Netty.Input.Buffers.inputFloatingBuffersUsage | flink/task/Shuffle.Netty.Input.Buffers.inputFloatingBuffersUsage | n |
| flink:task:Shuffle.Netty.Input.Buffers.inputQueueLength | flink/task/Shuffle.Netty.Input.Buffers.inputQueueLength | n |
| flink:task:Shuffle.Netty.Input.numBuffersInLocal | flink/task/Shuffle.Netty.Input.numBuffersInLocal | n |
| flink:task:Shuffle.Netty.Input.numBuffersInLocalPerSecond.count | flink/task/Shuffle.Netty.Input.numBuffersInLocalPerSecond.count | n |
| flink:task:Shuffle.Netty.Input.numBuffersInLocalPerSecond.rate | flink/task/Shuffle.Netty.Input.numBuffersInLocalPerSecond.rate | n |
| flink:task:Shuffle.Netty.Input.numBuffersInRemote | flink/task/Shuffle.Netty.Input.numBuffersInRemote | n |
| flink:task:Shuffle.Netty.Input.numBuffersInRemotePerSecond.count | flink/task/Shuffle.Netty.Input.numBuffersInRemotePerSecond.count | n |
| flink:task:Shuffle.Netty.Input.numBuffersInRemotePerSecond.rate | flink/task/Shuffle.Netty.Input.numBuffersInRemotePerSecond.rate | n |
| flink:task:Shuffle.Netty.Input.numBytesInLocal | flink/task/Shuffle.Netty.Input.numBytesInLocal | n |
| flink:task:Shuffle.Netty.Input.numBytesInLocalPerSecond.count | flink/task/Shuffle.Netty.Input.numBytesInLocalPerSecond.count | n |
| flink:task:Shuffle.Netty.Input.numBytesInLocalPerSecond.rate | flink/task/Shuffle.Netty.Input.numBytesInLocalPerSecond.rate | n |
| flink:task:Shuffle.Netty.Input.numBytesInRemote | flink/task/Shuffle.Netty.Input.numBytesInRemote | n |
| flink:task:Shuffle.Netty.Input.numBytesInRemotePerSecond.count | flink/task/Shuffle.Netty.Input.numBytesInRemotePerSecond.count | n |
| flink:task:Shuffle.Netty.Input.numBytesInRemotePerSecond.rate | flink/task/Shuffle.Netty.Input.numBytesInRemotePerSecond.rate | n |
| flink:task:Shuffle.Netty.Output.Buffers.outPoolUsage | flink/task/Shuffle.Netty.Output.Buffers.outPoolUsage | n |
| flink:task:Shuffle.Netty.Output.Buffers.outputQueueLength | flink/task/Shuffle.Netty.Output.Buffers.outputQueueLength | n |
| flink:taskmanager:Status.flink.Memory.Managed.Total | flink/taskmanager/Status.flink.Memory.Managed.Total | n |
| flink:taskmanager:Status.flink.Memory.Managed.Used | flink/taskmanager/Status.flink.Memory.Managed.Used | n |
| flink:taskmanager:Status.JVM.ClassLoader.ClassesLoaded | flink/taskmanager/Status.JVM.ClassLoader.ClassesLoaded | n |
| flink:taskmanager:Status.JVM.ClassLoader.ClassesUnloaded | flink/taskmanager/Status.JVM.ClassLoader.ClassesUnloaded | n |
| flink:taskmanager:Status.JVM.CPU.Load | flink/taskmanager/Status.JVM.CPU.Load | n |
| flink:taskmanager:Status.JVM.CPU.Time | flink/taskmanager/Status.JVM.CPU.Time | y |
| flink:taskmanager:Status.JVM.GarbageCollector.PSMarkSweep.Count | flink/taskmanager/Status.JVM.GarbageCollector.PSMarkSweep.Count | n |
| flink:taskmanager:Status.JVM.GarbageCollector.PSMarkSweep.Time | flink/taskmanager/Status.JVM.GarbageCollector.PSMarkSweep.Time | n |
| flink:taskmanager:Status.JVM.GarbageCollector.PSScavenge.Count | flink/taskmanager/Status.JVM.GarbageCollector.PSScavenge.Count | n |
| flink:taskmanager:Status.JVM.GarbageCollector.PSScavenge.Time | flink/taskmanager/Status.JVM.GarbageCollector.PSScavenge.Time | n |
| flink:taskmanager:Status.JVM.Memory.Direct.Count | flink/taskmanager/Status.JVM.Memory.Direct.Count | y |
| flink:taskmanager:Status.JVM.Memory.Direct.MemoryUsed | flink/taskmanager/Status.JVM.Memory.Direct.MemoryUsed | y |
| flink:taskmanager:Status.JVM.Memory.Direct.TotalCapacity | flink/taskmanager/Status.JVM.Memory.Direct.TotalCapacity | y |
| flink:taskmanager:Status.JVM.Memory.Heap.Committed | flink/taskmanager/Status.JVM.Memory.Heap.Committed | y |
| flink:taskmanager:Status.JVM.Memory.Heap.Max | flink/taskmanager/Status.JVM.Memory.Heap.Max | y |
| flink:taskmanager:Status.JVM.Memory.Heap.Used | flink/taskmanager/Status.JVM.Memory.Heap.Used | y |
| flink:taskmanager:Status.JVM.Memory.Mapped.Count | flink/taskmanager/Status.JVM.Memory.Mapped.Count | y |
| flink:taskmanager:Status.JVM.Memory.Mapped.MemoryUsed | flink/taskmanager/Status.JVM.Memory.Mapped.MemoryUsed | y |
| flink:taskmanager:Status.JVM.Memory.Mapped.TotalCapacity | flink/taskmanager/Status.JVM.Memory.Mapped.TotalCapacity | y |
| flink:taskmanager:Status.JVM.Memory.Metaspace.Committed | flink/taskmanager/Status.JVM.Memory.Metaspace.Committed | n |
| flink:taskmanager:Status.JVM.Memory.Metaspace.Max | flink/taskmanager/Status.JVM.Memory.Metaspace.Max | n |
| flink:taskmanager:Status.JVM.Memory.Metaspace.Used | flink/taskmanager/Status.JVM.Memory.Metaspace.Used | n |
| flink:taskmanager:Status.JVM.Memory.NonHeap.Committed | flink/taskmanager/Status.JVM.Memory.NonHeap.Committed | n |
| flink:taskmanager:Status.JVM.Memory.NonHeap.Max | flink/taskmanager/Status.JVM.Memory.NonHeap.Max | n |
| flink:taskmanager:Status.JVM.Memory.NonHeap.Used | flink/taskmanager/Status.JVM.Memory.NonHeap.Used | n |
| flink:taskmanager:Status.JVM.Threads.Count | flink/taskmanager/Status.JVM.Threads.Count | n |
| flink:taskmanager:Status.Network.AvailableMemorySegments | flink/taskmanager/Status.Network.AvailableMemorySegments | n |
| flink:taskmanager:Status.Network.TotalMemorySegments | flink/taskmanager/Status.Network.TotalMemorySegments | n |
| flink:taskmanager:Status.Shuffle.Netty.AvailableMemory | flink/taskmanager/Status.Shuffle.Netty.AvailableMemory | n |
| flink:taskmanager:Status.Shuffle.Netty.AvailableMemorySegments | flink/taskmanager/Status.Shuffle.Netty.AvailableMemorySegments | n |
| flink:taskmanager:Status.Shuffle.Netty.TotalMemory | flink/taskmanager/Status.Shuffle.Netty.TotalMemory | n |
| flink:taskmanager:Status.Shuffle.Netty.TotalMemorySegments | flink/taskmanager/Status.Shuffle.Netty.TotalMemorySegments | n |
| flink:taskmanager:Status.Shuffle.Netty.UsedMemory | flink/taskmanager/Status.Shuffle.Netty.UsedMemory | n |
| flink:taskmanager:Status.Shuffle.Netty.UsedMemorySegments | flink/taskmanager/Status.Shuffle.Netty.UsedMemorySegments | n |
Metriche del server di cronologia Spark
Dataproc raccoglie le seguenti metriche di memoria JVM del servizio di cronologia Spark:
| Metrica | Nome di Metrics Explorer | Metriche abilitate |
|---|---|---|
| sparkHistoryServer:JVM:Memory:HeapMemoryUsage.committed | sparkHistoryServer/memory/CommittedHeapMemory | y |
| sparkHistoryServer:JVM:Memory:HeapMemoryUsage.used | sparkHistoryServer/memory/UsedHeapMemory | y |
| sparkHistoryServer:JVM:Memory:HeapMemoryUsage.max | sparkHistoryServer/memory/MaxHeapMemory | y |
| sparkHistoryServer:JVM:Memory:NonHeapMemoryUsage.committed | sparkHistoryServer/memory/CommittedNonHeapMemory | y |
| sparkHistoryServer:JVM:Memory:NonHeapMemoryUsage.used | sparkHistoryServer/memory/UsedNonHeapMemory | y |
| sparkHistoryServer:JVM:Memory:NonHeapMemoryUsage.max | sparkHistoryServer/memory/MaxNonHeapMemory | y |
Metriche di HiveServer 2
| Metrica | Nome di Metrics Explorer | Metriche abilitate |
|---|---|---|
| hiveserver2:JVM:Memory:HeapMemoryUsage.committed | hiveserver2/memory/CommittedHeapMemory | y |
| hiveserver2:JVM:Memory:HeapMemoryUsage.used | hiveserver2/memory/UsedHeapMemory | y |
| hiveserver2:JVM:Memory:HeapMemoryUsage.max | hiveserver2/memory/MaxHeapMemory | y |
| hiveserver2:JVM:Memory:NonHeapMemoryUsage.committed | hiveserver2/memory/CommittedNonHeapMemory | y |
| hiveserver2:JVM:Memory:NonHeapMemoryUsage.used | hiveserver2/memory/UsedNonHeapMemory | y |
| hiveserver2:JVM:Memory:NonHeapMemoryUsage.max | hiveserver2/memory/MaxNonHeapMemory | y |
Metriche del metastore Hive
| Metrica | Nome di Metrics Explorer | Metriche abilitate |
|---|---|---|
| hivemetastore:API:GetDatabase:Mean | hivemetastore/get_database/mean | y |
| hivemetastore:API:CreateDatabase:Mean | hivemetastore/create_database/mean | y |
| hivemetastore:API:DropDatabase:Mean | hivemetastore/drop_database/mean | y |
| hivemetastore:API:AlterDatabase:Mean | hivemetastore/alter_database/mean | y |
| hivemetastore:API:GetAllDatabases:Mean | hivemetastore/get_all_databases/mean | y |
| hivemetastore:API:CreateTable:Mean | hivemetastore/create_table/mean | y |
| hivemetastore:API:DropTable:Mean | hivemetastore/drop_table/mean | y |
| hivemetastore:API:AlterTable:Mean | hivemetastore/alter_table/mean | y |
| hivemetastore:API:GetTable:Mean | hivemetastore/get_table/mean | y |
| hivemetastore:API:GetAllTables:Mean | hivemetastore/get_all_tables/mean | y |
| hivemetastore:API:AddPartitionsReq:Mean | hivemetastore/add_partitions_req/mean | y |
| hivemetastore:API:DropPartition:Mean | hivemetastore/drop_partition/mean | y |
| hivemetastore:API:AlterPartition:Mean | hivemetastore/alter_partition/mean | y |
| hivemetastore:API:GetPartition:Mean | hivemetastore/get_partition/mean | y |
| hivemetastore:API:GetPartitionNames:Mean | hivemetastore/get_partition_names/mean | y |
| hivemetastore:API:GetPartitionsPs:Mean | hivemetastore/get_partitions_ps/mean | y |
| hivemetastore:API:GetPartitionsPsWithAuth:Mean | hivemetastore/get_partitions_ps_with_auth/mean | y |
Misure delle metriche del metastore Hive
| Misura statistica | Metrica di esempio | Nome della metrica di esempio |
|---|---|---|
| Max | hivemetastore:API:GetDatabase:Max | hivemetastore/get_database/max |
| Min | hivemetastore:API:GetDatabase:Min | hivemetastore/get_database/min |
| Media | hivemetastore:API:GetDatabase:Mean | hivemetastore/get_database/mean |
| Conteggio | hivemetastore:API:GetDatabase:Count | hivemetastore/get_database/count |
| 50° percentile | hivemetastore:API:GetDatabase:50thPercentile | hivemetastore/get_database/median |
| 75° percentile | hivemetastore:API:GetDatabase:75thPercentile | hivemetastore/get_database/75th_percentile |
| 95° percentile | hivemetastore:API:GetDatabase:95thPercentile | hivemetastore/get_database/95th_percentile |
| 98thPercentile | hivemetastore:API:GetDatabase:98thPercentile | hivemetastore/get_database/98th_percentile |
| 99° percentile | hivemetastore:API:GetDatabase:99thPercentile | hivemetastore/get_database/99th_percentile |
| 999thPercentile | hivemetastore:API:GetDatabase:999thPercentile | hivemetastore/get_database/999th_percentile |
| StdDev | hivemetastore:API:GetDatabase:StdDev | hivemetastore/get_database/stddev |
| FifteenMinuteRate | hivemetastore:API:GetDatabase:FifteenMinuteRate | hivemetastore/get_database/15min_rate |
| FiveMinuteRate | hivemetastore:API:GetDatabase:FiveMinuteRate | hivemetastore/get_database/5min_rate |
| OneMinuteRate | hivemetastore:API:GetDatabase:OneMinuteRate | hivemetastore/get_database/1min_rate |
| MeanRate | hivemetastore:API:GetDatabase:MeanRate | hivemetastore/get_database/mean_rate |
Metriche dell'agente di monitoraggio Dataproc
Dataproc raccoglie le seguenti
metriche dell'agente di monitoraggio Dataproc
quando imposti --metric-sources=monitoring-agent-defaults.
Queste metriche vengono pubblicate con il prefisso agent.googleapis.com.
CPU
agent.googleapis.com/cpu/load_15m
agent.googleapis.com/cpu/load_1m
agent.googleapis.com/cpu/load_5m
agent.googleapis.com/cpu/usage_time*
agent.googleapis.com/cpu/utilization*
Disco
agent.googleapis.com/disk/bytes_used
agent.googleapis.com/disk/io_time
agent.googleapis.com/disk/merged_operations
agent.googleapis.com/disk/operation_count
agent.googleapis.com/disk/operation_time
agent.googleapis.com/disk/pending_operations
agent.googleapis.com/disk/percent_used
agent.googleapis.com/disk/read_bytes_count
Swap
agent.googleapis.com/swap/bytes_used
agent.googleapis.com/swap/io
agent.googleapis.com/swap/percent_used
Memoria
agent.googleapis.com/memory/bytes_used
agent.googleapis.com/memory/percent_used
Processi: alcuni attributi seguono norme relative alle quote uniche.
agent.googleapis.com/processes/count_by_state
agent.googleapis.com/processes/cpu_time
agent.googleapis.com/processes/disk/read_bytes_count
agent.googleapis.com/processes/disk/write_bytes_count
agent.googleapis.com/processes/fork_count
agent.googleapis.com/processes/rss_usage
agent.googleapis.com/processes/vm_usage
Interfaccia
agent.googleapis.com/interface/errors
agent.googleapis.com/interface/packets
agent.googleapis.com/interface/traffic
Rete
agent.googleapis.com/network/tcp_connections
Crea una dashboard Monitoring
Puoi creare una dashboard di Monitoring che mostri i grafici delle metriche Dataproc selezionate.
Seleziona + CREA DASHBOARD dalla pagina Panoramica delle dashboard di monitoraggio. Fornisci un nome per la dashboard, poi fai clic su Aggiungi grafico nel menu in alto a destra per aprire la finestra Aggiungi grafico. Seleziona "Cluster Cloud Dataproc" come tipo di risorsa. Seleziona una o più metriche e proprietà di metriche e grafici. Quindi Salva il grafico.
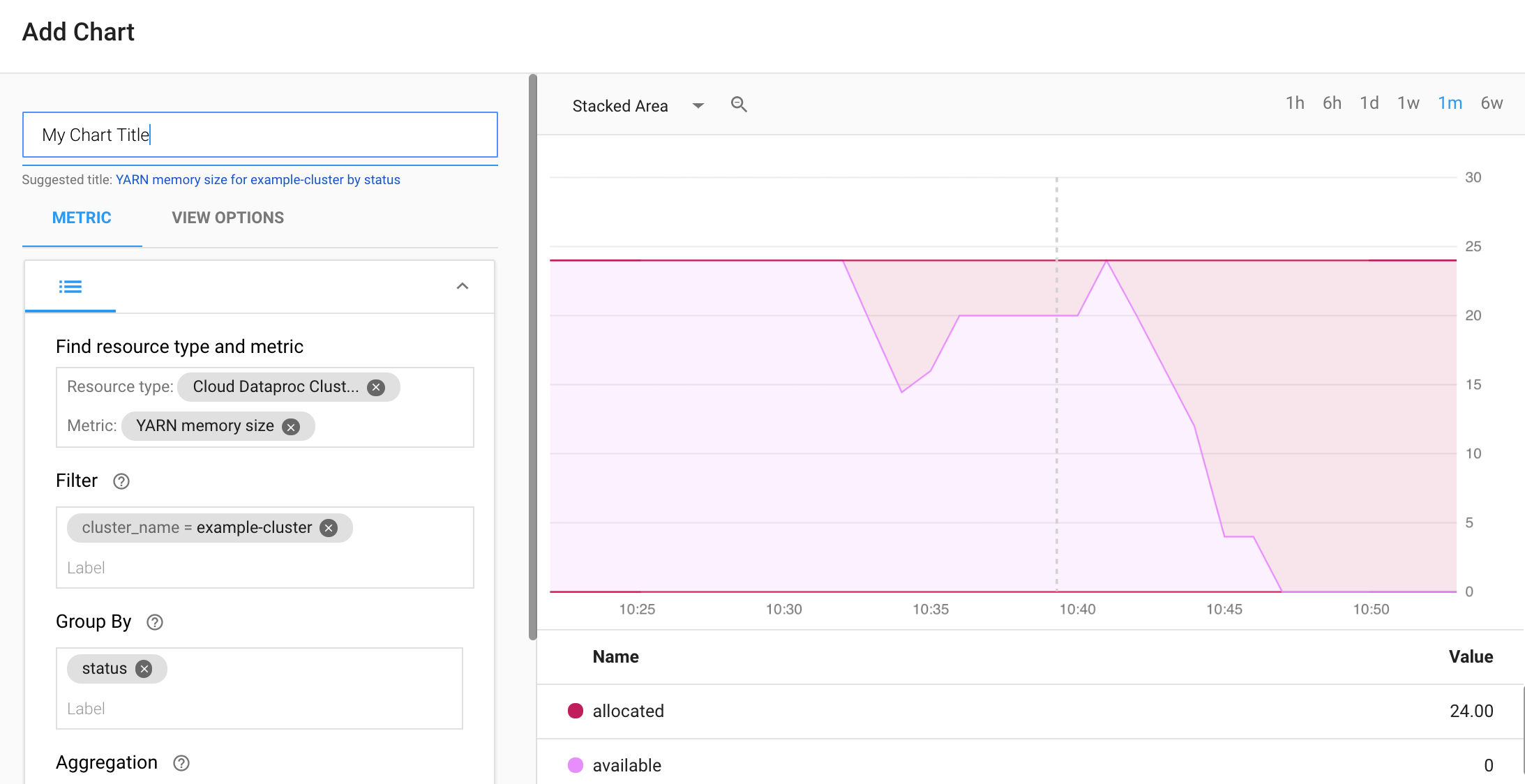
Puoi aggiungere altri grafici alla dashboard. Dopo aver salvato la dashboard, il relativo titolo viene visualizzato nella pagina Panoramica delle dashboard di Monitoring. I grafici della dashboard possono essere visualizzati, aggiornati ed eliminati dalla pagina di visualizzazione della dashboard.
Passaggi successivi
- Consulta la documentazione di Cloud Monitoring.
- Scopri come creare avvisi per le metriche Dataproc