Dataproc ジョブとクラスタのログは、Cloud Logging で表示、検索、フィルタ、アーカイブを行えます。
費用については、Google Cloud Observability の料金をご覧ください。
ログの保持期間については、ログの保持期間をご覧ください。
すべてのログを無効にする、または Logging からログを除外するには、ログの除外をご覧ください。
Logging から Cloud Storage、BigQuery、Pub/Sub にログを転送するには、ルーティングとストレージの概要をご覧ください。
コンポーネントのロギングレベル
クラスタを作成するときに、Spark、Hadoop、Flink などの Dataproc コンポーネントのロギングレベルを、コンポーネント固有の log4j クラスタ プロパティ(hadoop-log4j など)で設定します。クラスタベースのコンポーネントのロギングレベルは、YARN ResourceManager などのサービス デーモンと、クラスタ上で実行されるジョブに適用されます。
Presto コンポーネントなど、コンポーネントで log4j プロパティがサポートされていない場合は、コンポーネントの log4j.properties または log4j2.properties ファイルを編集する初期化アクションを作成します。
ジョブ固有のコンポーネント ロギング レベル: ジョブを送信するときにコンポーネント ロギング レベルを設定することもできます。これらのロギングレベルはジョブに適用され、クラスタの作成時に設定されたロギングレベルよりも優先されます。詳細については、クラスタ プロパティとジョブ プロパティの比較をご覧ください。
Spark コンポーネントと Hive コンポーネントのバージョンのロギングレベル:
Spark 3.3.X と Hive 3.X のコンポーネントでは log4j2 プロパティを使用しますが、以前のバージョンのコンポーネントでは log4j プロパティを使用します(Apache Log4j2 を参照)。spark-log4j: 接頭辞を使用して、クラスタに Spark ロギングレベルを設定します。
例:
log4j.logger.org.apache.sparkを設定する Spark 3.1 を使用する Dataproc イメージ バージョン 2.0。gcloud dataproc clusters create ... \ --properties spark-log4j:log4j.logger.org.apache.spark=DEBUG
例:
logger.sparkRoot.levelを設定する Spark 3.3 を使用する Dataproc イメージ バージョン 2.1。gcloud dataproc clusters create ...\ --properties spark-log4j:logger.sparkRoot.level=debug
ジョブドライバのロギングレベル
Dataproc はジョブドライバ プログラムに対してデフォルトのロギングレベル INFO を使用します。gcloud dataproc jobs submit --driver-log-levels フラグを使用すると、1 つ以上のパッケージに対してこの設定を変更できます。
例:
Cloud Storage ファイルを読み取る Spark ジョブを送信するときに、DEBUG ロギングレベルを設定します。
gcloud dataproc jobs submit spark ...\ --driver-log-levels org.apache.spark=DEBUG,com.google.cloud.hadoop.gcsio=DEBUG
例:
root ロガーのレベルを WARN、com.example ロガーのレベルを INFO に設定します。
gcloud dataproc jobs submit hadoop ...\ --driver-log-levels root=WARN,com.example=INFO
Spark エグゼキュータのロギングレベル
Spark エグゼキュータのロギングレベルを構成するには:
log4j 構成ファイルを準備して Cloud Storage にアップロードする
。ジョブを送信するときに、構成ファイルを参照します。
例:
gcloud dataproc jobs submit spark ...\ --file gs://my-bucket/path/spark-log4j.properties \ --properties spark.executor.extraJavaOptions=-Dlog4j.configuration=file:spark-log4j.properties
Spark は、Cloud Storage プロパティ ファイルをジョブのローカル作業ディレクトリ(-Dlog4j.configuration で file:<name> として参照)にダウンロードします。
Logging の Dataproc ジョブのログ
ロギングで Dataproc ジョブドライバのログを有効にする方法については、Dataproc ジョブの出力とログをご覧ください。
Logging のジョブのログにアクセスする
Dataproc のジョブログには、ログ エクスプローラ、gcloud logging コマンド、または Logging API を使用してアクセスします。
コンソール
Cloud Dataproc ジョブリソースの下に、Dataproc ジョブドライバと YARN コンテナのログが一覧表示されます。
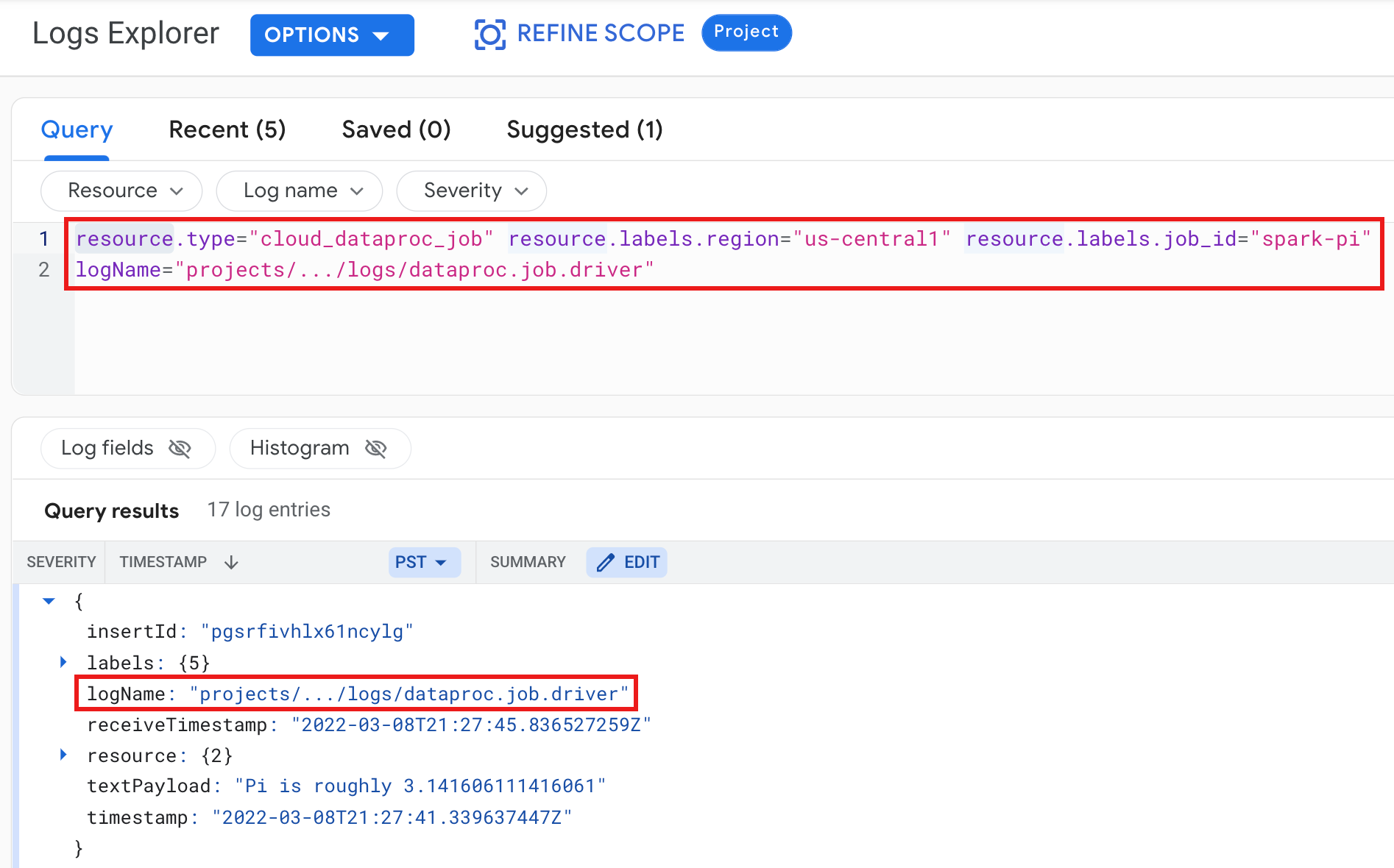
例: 次の内容を指定してログ エクスプローラ クエリを実行した後のジョブドライバのログ。
- リソース:
Cloud Dataproc Job - ログ名:
dataproc.job.driver
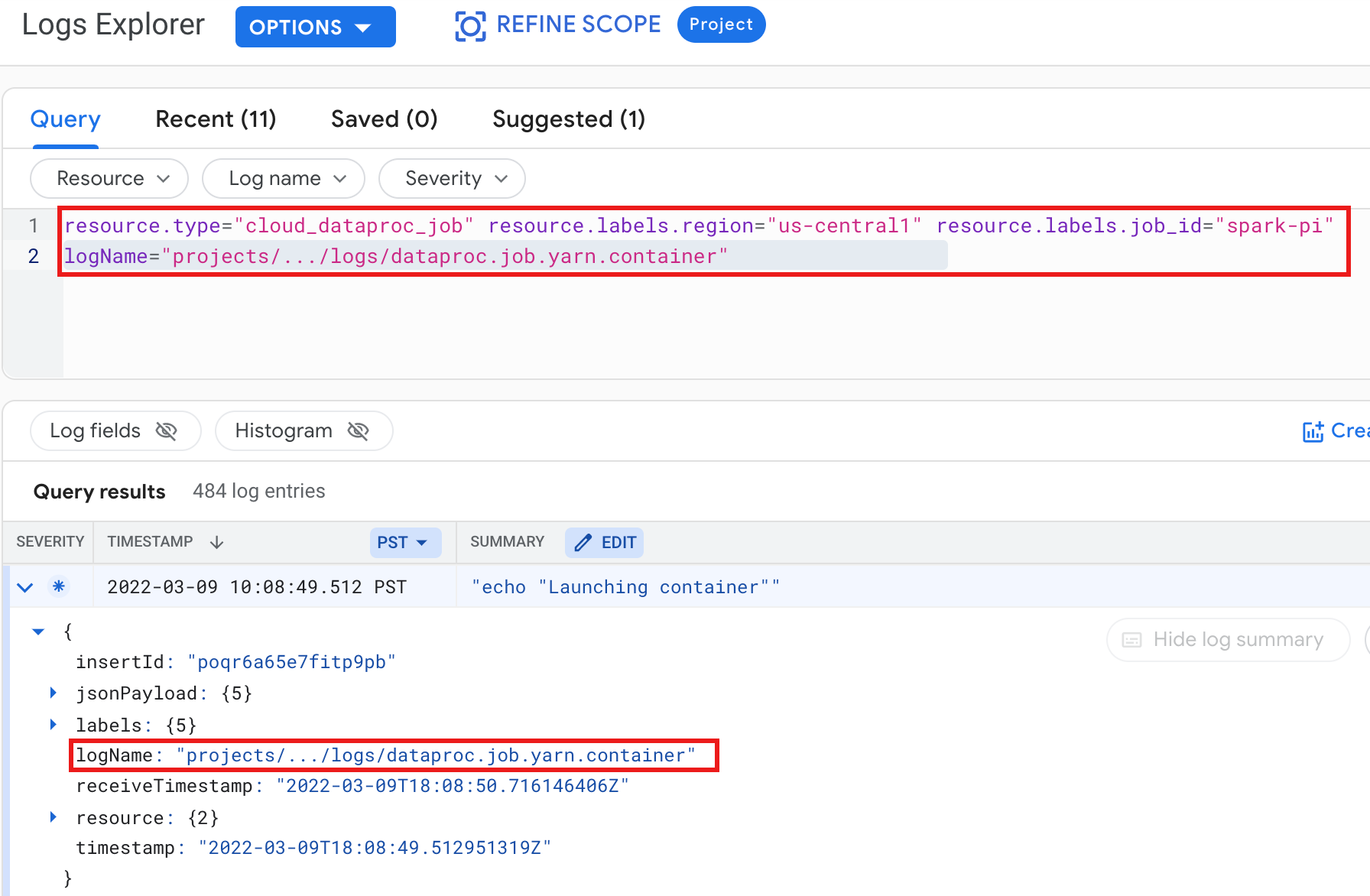
例: 次の内容を指定してログ エクスプローラ クエリを実行した後の YARN コンテナログ。
- リソース:
Cloud Dataproc Job - ログ名:
dataproc.job.yarn.container
gcloud
ジョブのログエントリは、gcloud logging read コマンドを使用して読み取ることが可能です。リソース引数は引用符("...")で囲む必要があります。次のコマンドでは、返されたログエントリをクラスタラベルでフィルタリングします。
gcloud logging read \ "resource.type=cloud_dataproc_job \ resource.labels.region=cluster-region \ resource.labels.job_id=my-job-id"
出力例(一部):
jsonPayload: class: org.apache.hadoop.hdfs.StateChange filename: hadoop-hdfs-namenode-test-dataproc-resize-cluster-20190410-38an-m-0.log ,,, logName: projects/project-id/logs/hadoop-hdfs-namenode --- jsonPayload: class: SecurityLogger.org.apache.hadoop.security.authorize.ServiceAuthorizationManager filename: cluster-name-dataproc-resize-cluster-20190410-38an-m-0.log ... logName: projects/google.com:hadoop-cloud-dev/logs/hadoop-hdfs-namenode
REST API
Logging REST API を使用してログエントリを一覧表示できます(entries.list をご覧ください)。
Logging の Dataproc クラスタログ
Dataproc では、次の Apache Hadoop、Spark、Hive、Zookeeper などの Dataproc クラスタログを Cloud Logging にエクスポートします。
| ログタイプ | ログ名 | 説明 | メモ |
|---|---|---|---|
| マスター デーモンのログ | hadoop-hdfs hadoop-hdfs-namenode hadoop-hdfs-secondarynamenode hadoop-hdfs-zkfc hadoop-yarn-resourcemanager hadoop-yarn-timelineserver hive-metastore hive-server2 mapred-mapred-historyserver zookeeper |
ジャーナル ノード HDFS namenode HDFS セカンダリ namenode Zookeeper フェイルオーバー コントローラ YARN リソース管理者 YARN タイムライン サーバー Hive メタストア Hive サーバー 2 Mapreduce ジョブヒストリ サーバー Zookeeper サーバー |
|
| ワーカー デーモンのログ |
hadoop-hdfs-datanode hadoop-yarn-nodemanager |
HDFS datanode YARN nodemanager |
|
| システムログ |
autoscaler google.dataproc.agent google.dataproc.startup |
Dataproc オートスケーラー ログ Dataproc エージェント ログ Dataproc 起動スクリプトログ + 初期化アクションログ |
|
| 拡張(追加)ログ |
knox gateway-audit zeppelin ranger-usersync jupyter_notebook jupyter_kernel_gateway spark-history-server |
/var/log/ サブディレクトリ内のすべてのログが、次のいずれかに一致する:knox(gateway-audit.log を含む) zeppelin ranger-usersync jupyter_notebook jupyter_kernel_gateway spark-history-server |
dataproc:dataproc.logging.extended.enabled=false プロパティを設定すると、クラスタでの拡張ログの収集が無効になります。 |
| VM の syslog |
syslog |
クラスタのマスターノードとワーカーノードの syslog |
dataproc:dataproc.logging.syslog.enabled=false プロパティを設定すると、クラスタでの VM syslog の収集が無効になります。 |
Cloud Logging でクラスタログにアクセスする
Dataproc クラスタのログにアクセスするには、ログ エクスプローラ、gcloud logging コマンド、または Logging API を使用します。
コンソール
次のクエリを実行して、ログ エクスプローラでクラスタログを表示します。
- リソース:
Cloud Dataproc Cluster - ログ名: log name
gcloud
クラスタのログエントリは、gcloud logging read コマンドを使用して読み取ることが可能です。リソース引数は引用符("...")で囲む必要があります。次のコマンドでは、返されたログエントリをクラスタラベルでフィルタリングします。
gcloud logging read <<'EOF' "resource.type=cloud_dataproc_cluster resource.labels.region=cluster-region resource.labels.cluster_name=cluster-name resource.labels.cluster_uuid=cluster-uuid" EOF
出力例(一部):
jsonPayload: class: org.apache.hadoop.yarn.server.resourcemanager.ResourceTrackerService filename: hadoop-yarn-resourcemanager-cluster-name-m.log ... logName: projects/project-id/logs/hadoop-yarn-resourcemanager --- jsonPayload: class: org.apache.hadoop.yarn.server.resourcemanager.ResourceTrackerService filename: hadoop-yarn-resourcemanager-component-gateway-cluster-m.log ... logName: projects/project-id/logs/hadoop-yarn-resourcemanager
REST API
Logging REST API を使用してログエントリを一覧表示できます(entries.list をご覧ください)。
権限
Logging にログを書き込むには、Dataproc VM サービス アカウントに logging.logWriter IAM ロールが必要です。デフォルトの Dataproc サービス アカウントは、このロールを持っています。カスタム サービス アカウントを使用する場合は、このロールをサービス アカウントに割り当てる必要があります。
ログの保護
デフォルトでは、Logging のログは保存時に暗号化されます。顧客管理の暗号鍵(CMEK)を有効にしてログを暗号化できます。CMEK のサポートの詳細については、ログルーター データを保護する鍵を管理すると Logging ストレージ データを保護する鍵を管理するをご覧ください。
次のステップ
- Google Cloud Observability を確認する。