Neste documento, mostramos como criar uma tabela do Apache Iceberg com metadados no metastore do BigLake usando o serviço de jobs do Dataproc, a CLI do Spark SQL ou a interface da Web Zeppelin executada em um cluster do Dataproc.
Antes de começar
Se ainda não tiver feito isso, crie um Google Cloud projeto, um bucket do Cloud Storage e um cluster do Dataproc.
Configurar seu projeto
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Dataproc, BigQuery, and Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Install the Google Cloud CLI.
-
Ao usar um provedor de identidade (IdP) externo, primeiro faça login na gcloud CLI com sua identidade federada.
-
Para inicializar a gcloud CLI, execute o seguinte comando:
gcloud init -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Dataproc, BigQuery, and Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Install the Google Cloud CLI.
-
Ao usar um provedor de identidade (IdP) externo, primeiro faça login na gcloud CLI com sua identidade federada.
-
Para inicializar a gcloud CLI, execute o seguinte comando:
gcloud init Crie um bucket do Cloud Storage no seu projeto.
- In the Google Cloud console, go to the Cloud Storage Buckets page.
- Click Create.
- On the Create a bucket page, enter your bucket information. To go to the next
step, click Continue.
-
In the Get started section, do the following:
- Enter a globally unique name that meets the bucket naming requirements.
- To add a
bucket label,
expand the Labels section (),
click add_box
Add label, and specify a
keyand avaluefor your label.
-
In the Choose where to store your data section, do the following:
- Select a Location type.
- Choose a location where your bucket's data is permanently stored from the Location type drop-down menu.
- If you select the dual-region location type, you can also choose to enable turbo replication by using the relevant checkbox.
- To set up cross-bucket replication, select
Add cross-bucket replication via Storage Transfer Service and
follow these steps:
Set up cross-bucket replication
- In the Bucket menu, select a bucket.
In the Replication settings section, click Configure to configure settings for the replication job.
The Configure cross-bucket replication pane appears.
- To filter objects to replicate by object name prefix, enter a prefix that you want to include or exclude objects from, then click Add a prefix.
- To set a storage class for the replicated objects, select a storage class from the Storage class menu. If you skip this step, the replicated objects will use the destination bucket's storage class by default.
- Click Done.
-
In the Choose how to store your data section, do the following:
- Select a default storage class for the bucket or Autoclass for automatic storage class management of your bucket's data.
- To enable hierarchical namespace, in the Optimize storage for data-intensive workloads section, select Enable hierarchical namespace on this bucket.
- In the Choose how to control access to objects section, select whether or not your bucket enforces public access prevention, and select an access control method for your bucket's objects.
-
In the Choose how to protect object data section, do the
following:
- Select any of the options under Data protection that you
want to set for your bucket.
- To enable soft delete, click the Soft delete policy (For data recovery) checkbox, and specify the number of days you want to retain objects after deletion.
- To set Object Versioning, click the Object versioning (For version control) checkbox, and specify the maximum number of versions per object and the number of days after which the noncurrent versions expire.
- To enable the retention policy on objects and buckets, click the Retention (For compliance) checkbox, and then do the following:
- To enable Object Retention Lock, click the Enable object retention checkbox.
- To enable Bucket Lock, click the Set bucket retention policy checkbox, and choose a unit of time and a length of time for your retention period.
- To choose how your object data will be encrypted, expand the Data encryption section (), and select a Data encryption method.
- Select any of the options under Data protection that you
want to set for your bucket.
-
In the Get started section, do the following:
- Click Create.
Crie um cluster do Dataproc Para economizar recursos e custos, crie um cluster do Dataproc de nó único para executar os exemplos apresentados neste documento.
A sub-rede na região em que o cluster é criado precisa ter o Acesso privado do Google (PGA) ativado.
.Se você quiser executar o exemplo da interface da Web do Zeppelin neste guia, use ou crie um cluster do Dataproc com o componente opcional do Zeppelin ativado.
Conceda papéis a uma conta de serviço personalizada (se necessário): por padrão, as VMs do cluster do Dataproc usam a conta de serviço padrão do Compute Engine para interagir com o Dataproc. Se você quiser especificar uma conta de serviço personalizada ao criar o cluster, ela precisará ter o papel Worker do Dataproc (
roles/dataproc.worker) ou um papel personalizado com as permissões necessárias do papel de worker.Em uma janela de terminal local ou no Cloud Shell, use um editor de texto, como
viounano, para copiar os comandos a seguir em um arquivoiceberg-table.sqle salve o arquivo no diretório atual.USE CATALOG_NAME; CREATE NAMESPACE IF NOT EXISTS example_namespace; USE example_namespace; DROP TABLE IF EXISTS example_table; CREATE TABLE example_table (id int, data string) USING ICEBERG LOCATION 'gs://BUCKET/WAREHOUSE_FOLDER'; INSERT INTO example_table VALUES (1, 'first row'); ALTER TABLE example_table ADD COLUMNS (newDoubleCol double); DESCRIBE TABLE example_table;
Substitua:
- CATALOG_NAME: nome do catálogo do Iceberg.
- BUCKET e WAREHOUSE_FOLDER: bucket e pasta do Cloud Storage usados para o data warehouse do Iceberg.
Use a gcloud CLI para copiar o
iceberg-table.sqllocal para o bucket no Cloud Storage.gcloud storage cp iceberg-table.sql gs://BUCKET/
Em uma janela de terminal local ou no Cloud Shell, execute o seguinte comando
curlpara fazer o download do arquivo JARiceberg-spark-runtime-3.5_2.12-1.6.1no diretório atual.curl -o iceberg-spark-runtime-3.5_2.12-1.6.1.jar https://storage-download.googleapis.com/maven-central/maven2/org/apache/iceberg/iceberg-spark-runtime-3.5_2.12/1.6.1/iceberg-spark-runtime-3.5_2.12-1.6.1.jar
Usa a gcloud CLI para copiar o arquivo JAR
iceberg-spark-runtime-3.5_2.12-1.6.1local do diretório atual para seu bucket no Cloud Storage.gcloud storage cp iceberg-spark-runtime-3.5_2.12-1.6.1.jar gs://BUCKET/
Execute o seguinte comando gcloud dataproc jobs submit spark-sql localmente em uma janela de terminal ou no Cloud Shell para enviar o job do Spark SQL e criar a tabela do Iceberg.
gcloud dataproc jobs submit spark-sql \ --project=PROJECT_ID \ --cluster=CLUSTER_NAME \ --region=REGION \ --jars="gs://BUCKET/1.6.1/iceberg-spark-runtime-3.5_2.12-1.6.1.jar,gs://spark-lib/bigquery/iceberg-bigquery-catalog-1.6.1-1.0.1-beta.jar" \ --properties="spark.sql.catalog.CATALOG_NAME=org.apache.iceberg.spark.SparkCatalog,spark.sql.catalog.CATALOG_NAME.catalog-impl=org.apache.iceberg.gcp.bigquery.BigQueryMetastoreCatalog,spark.sql.catalog.CATALOG_NAME.gcp_project=PROJECT_ID,spark.sql.catalog.CATALOG_NAME.gcp_location=LOCATION,spark.sql.catalog.CATALOG_NAME.warehouse=gs://BUCKET/WAREHOUSE_FOLDER" \ -f="gs://BUCKETiceberg-table.sql"
Observações:
- PROJECT_ID: o ID do projeto do Google Cloud . Os IDs do projeto estão listados na seção Informações do projeto no Google Cloud painel do console.
- CLUSTER_NAME: o nome do cluster do Dataproc.
- REGION: a região do Compute Engine em que o cluster está localizado.
- CATALOG_NAME: nome do catálogo do Iceberg.
- BUCKET e WAREHOUSE_FOLDER: bucket e pasta do Cloud Storage usados para o data warehouse do Iceberg.
- LOCATION: um local do BigQuery compatível. O local padrão é "US".
--jars: os jars listados são necessários para criar metadados de tabela no BigLake Metastore.--properties: propriedades do catálogo.-f: o arquivo de jobiceberg-table.sqlque você copiou para o bucket no Cloud Storage.
Confira a descrição da tabela na saída do terminal quando o job terminar.
Time taken: 2.194 seconds id int data string newDoubleCol double Time taken: 1.479 seconds, Fetched 3 row(s) Job JOB_ID finished successfully.
Para ver os metadados da tabela no BigQuery
No console do Google Cloud , acesse a página BigQuery.
Ver metadados da tabela Iceberg.

No console Google Cloud , acesse o Dataproc Enviar um job.
Acesse a página "Enviar um job" e preencha os seguintes campos:
- ID do job: aceite o ID sugerido ou insira o seu.
- Região: selecione a região em que o cluster está localizado.
- Cluster: selecione o cluster.
- Tipo de job: selecione
SparkSql. - Tipo de origem da consulta: selecione
Query file. - Arquivo de consulta: inserir
gs://BUCKET/iceberg-table.sql - Arquivos jar: insira o seguinte:
gs://BUCKET/iceberg-spark-runtime-3.5_2.12-1.6.1.jar,gs://spark-lib/bigquery/iceberg-bigquery-catalog-1.6.1-1.0.1-beta.jar
- Propriedades: clique em Adicionar propriedade cinco vezes para criar uma lista de cinco campos de entrada
keyvalue. Depois, copie os seguintes pares Chave e Valor para definir cinco propriedades.# Chave Valor 1. spark.sql.catalog.CATALOG_NAMEorg.apache.iceberg.spark.SparkCatalog2. spark.sql.catalog.CATALOG_NAME.catalog-implorg.apache.iceberg.gcp.bigquery.BigQueryMetastoreCatalog3. spark.sql.catalog.CATALOG_NAME.gcp_projectPROJECT_ID4. spark.sql.catalog.CATALOG_NAME.gcp_locationLOCATION5. spark.sql.catalog.CATALOG_NAME.warehousegs://BUCKET/WAREHOUSE_FOLDER
Observações:
- CATALOG_NAME: nome do catálogo do Iceberg.
- PROJECT_ID: o ID do projeto do Google Cloud . Os IDs do projeto estão listados na seção Informações do projeto no Google Cloud painel do console. região em que o cluster está localizado.
- LOCATION: um local do BigQuery compatível. O local padrão é "US".
- BUCKET e WAREHOUSE_FOLDER: bucket e pasta do Cloud Storage usados para o data warehouse do Iceberg.
Clique em Enviar.
Para monitorar o progresso do job e ver a saída dele, acesse a página Jobs do Dataproc no console do Google Cloud e clique em
Job IDpara abrir a página Detalhes do job.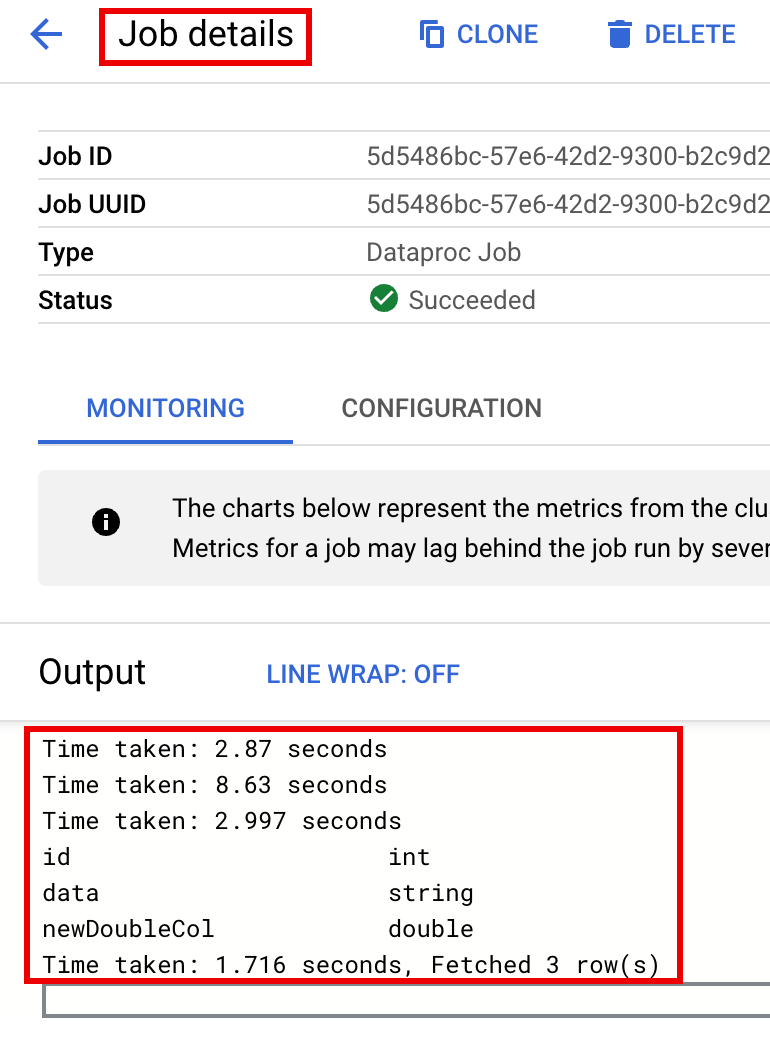
Para ver os metadados da tabela no BigQuery
No console do Google Cloud , acesse a página BigQuery.
Ver metadados da tabela Iceberg.
- PROJECT_ID: o ID do projeto do Google Cloud . Os IDs do projeto estão listados na seção Informações do projeto no painel do console Google Cloud .
- CLUSTER_NAME: o nome do cluster do Dataproc.
- REGION: a região do Compute Engine em que o cluster está localizado.
- CATALOG_NAME: nome do catálogo do Iceberg.
- BUCKET e WAREHOUSE_FOLDER: bucket e pasta do Cloud Storage usados para o data warehouse do Iceberg. LOCATION: um local do BigQuery compatível. O local padrão é "US".
jarFileUris: os jars listados são necessários para criar metadados de tabela no Metastore do BigQuery.properties: propriedades do catálogo.queryFileUri: o arquivo de jobiceberg-table.sqlque você copiou para o bucket no Cloud Storage.No console do Google Cloud , acesse a página BigQuery.
Ver metadados da tabela Iceberg.
Use SSH para se conectar ao nó mestre do cluster do Dataproc.
No terminal da sessão SSH, use o editor de texto
viounanopara copiar os seguintes comandos em um arquivoiceberg-table.sql.SET CATALOG_NAME = `CATALOG_NAME`; SET BUCKET = `BUCKET`; SET WAREHOUSE_FOLDER = `WAREHOUSE_FOLDER`; USE `${CATALOG_NAME}`; CREATE NAMESPACE IF NOT EXISTS `${CATALOG_NAME}`.example_namespace; DROP TABLE IF EXISTS `${CATALOG_NAME}`.example_namespace.example_table; CREATE TABLE `${CATALOG_NAME}`.example_namespace.example_table (id int, data string) USING ICEBERG LOCATION 'gs://${BUCKET}/${WAREHOUSE_FOLDER}'; INSERT INTO `${CATALOG_NAME}`.example_namespace.example_table VALUES (1, 'first row'); ALTER TABLE `${CATALOG_NAME}`.example_namespace.example_table ADD COLUMNS (newDoubleCol double); DESCRIBE TABLE `${CATALOG_NAME}`.example_namespace.example_table;Substitua:
- CATALOG_NAME: nome do catálogo do Iceberg.
- BUCKET e WAREHOUSE_FOLDER: bucket e pasta do Cloud Storage usados para o data warehouse do Iceberg.
No terminal da sessão SSH, execute o comando
spark-sqla seguir para criar a tabela Iceberg.spark-sql \ --packages org.apache.iceberg:iceberg-spark-runtime-3.5_2.12:1.6.1 \ --jars https://storage-download.googleapis.com/maven-central/maven2/org/apache/iceberg/iceberg-spark-runtime-3.5_2.12/1.6.1/iceberg-spark-runtime-3.5_2.12-1.6.1.jar,gs://spark-lib/bigquery/iceberg-bigquery-catalog-1.6.1-1.0.1-beta.jar \ --conf spark.sql.catalog.CATALOG_NAME=org.apache.iceberg.spark.SparkCatalog \ --conf spark.sql.catalog.CATALOG_NAME.catalog-impl=org.apache.iceberg.gcp.bigquery.BigQueryMetastoreCatalog \ --conf spark.sql.catalog.CATALOG_NAME.gcp_project=PROJECT_ID \ --conf spark.sql.catalog.CATALOG_NAME.gcp_location=LOCATION \ --conf spark.sql.catalog.CATALOG_NAME.warehouse=gs://BUCKET/WAREHOUSE_FOLDER \ -f iceberg-table.sql
Substitua:
- PROJECT_ID: o ID do projeto do Google Cloud . Os IDs do projeto estão listados na seção Informações do projeto no Google Cloud painel do console.
- LOCATION: um local do BigQuery compatível. O local padrão é "US".
Ver metadados da tabela no BigQuery
No console do Google Cloud , acesse a página BigQuery.
Ver metadados da tabela Iceberg.
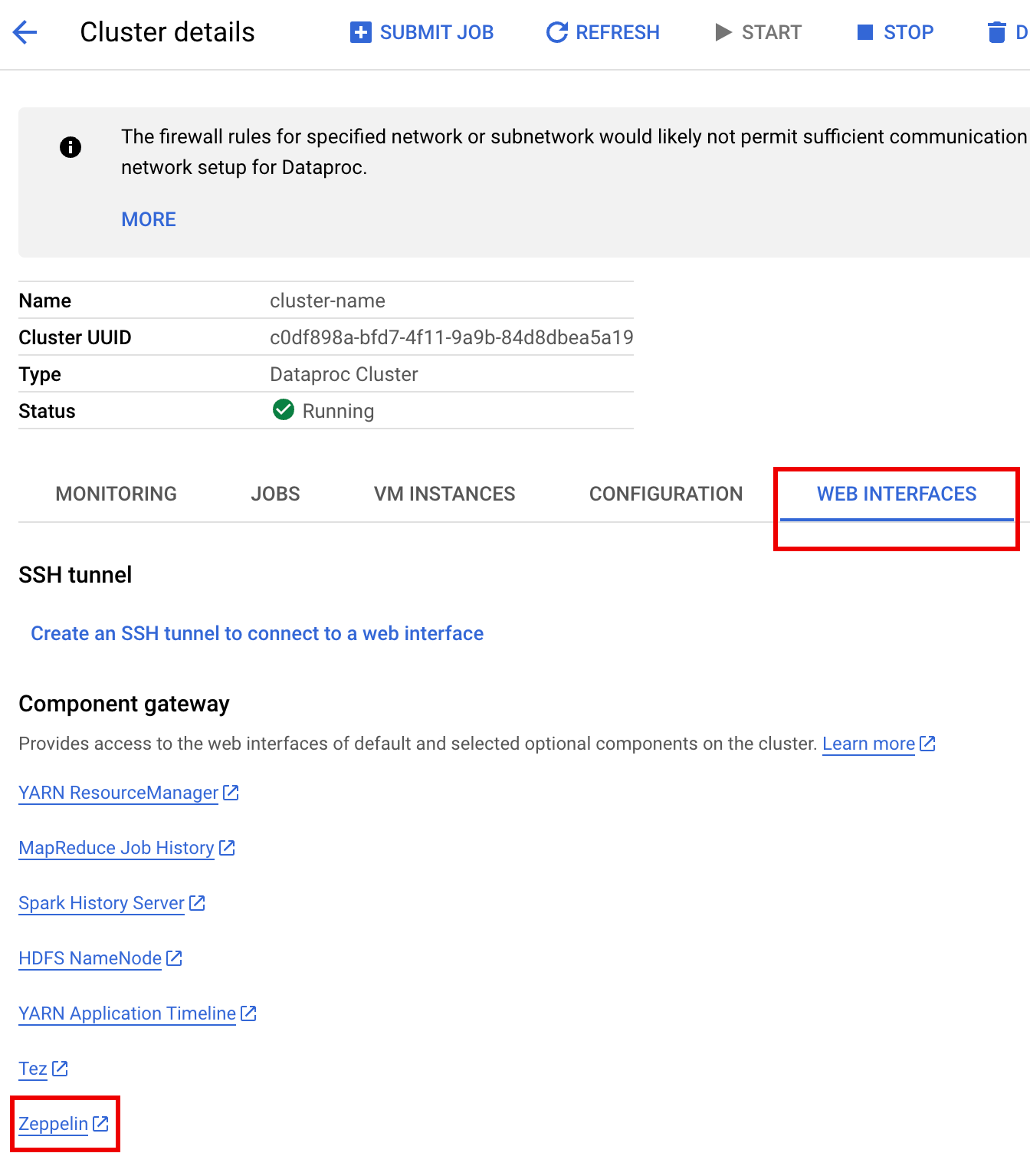
No Google Cloud console, acesse a página Clusters do Dataproc.
Selecione o nome do cluster para abrir a página Detalhes do cluster.
Clique na guia Interfaces da Web para exibir uma lista de links do Gateway de componentes para as interfaces da Web dos componentes padrão e opcionais instalados no cluster.
Clique no link Zeppelin para abrir a interface da Web do Zeppelin.
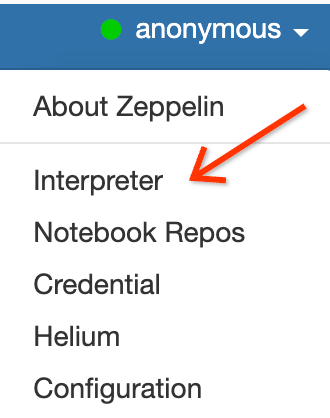
Na interface da Web do Zeppelin, clique no menu anonymous e em Interpreter para abrir a página Interpreters.
Adicione dois jars ao interpretador do Zeppelin Spark da seguinte forma:
- Digite "Spark" na caixa
Search interpreterspara rolar até a seção do interpretador Spark. - Clique em edit.
Cole o seguinte no campo spark.jars:
https://storage-download.googleapis.com/maven-central/maven2/org/apache/iceberg/iceberg-spark-runtime-3.5_2.12/1.6.1/iceberg-spark-runtime-3.5_2.12-1.6.1.jar,gs://spark-lib/bigquery/iceberg-bigquery-catalog-1.6.1-1.0.1-beta.jar

Clique em Salvar na parte de baixo da seção do interpretador do Spark e, em seguida, clique em OK para atualizar o interpretador e reiniciá-lo com as novas configurações.
- Digite "Spark" na caixa
No menu do notebook Zeppelin, clique em Criar nova nota.
Na caixa de diálogo Criar nova nota, insira um nome para o notebook e aceite o interpretador spark padrão. Clique em Criar para abrir o notebook.
Copie o seguinte código PySpark no notebook do Zeppelin depois de preencher as variáveis.
%pyspark
from pyspark.sql import SparkSession
project_id = "PROJECT_ID" catalog = "CATALOG_NAME" namespace = "NAMESPACE" location = "LOCATION" warehouse_dir = "gs://BUCKET/WAREHOUSE_DIRECTORY"
spark = SparkSession.builder \ .appName("BigQuery Metastore Iceberg") \ .config(f"spark.sql.catalog.{catalog}", "org.apache.iceberg.spark.SparkCatalog") \ .config(f"spark.sql.catalog.{catalog}.catalog-impl", "org.apache.iceberg.gcp.bigquery.BigQueryMetastoreCatalog") \ .config(f"spark.sql.catalog.{catalog}.gcp_project", f"{project_id}") \ .config(f"spark.sql.catalog.{catalog}.gcp_location", f"{location}") \ .config(f"spark.sql.catalog.{catalog}.warehouse", f"{warehouse_dir}") \ .getOrCreate()
spark.sql(f"USE `{catalog}`;") spark.sql(f"CREATE NAMESPACE IF NOT EXISTS `{namespace}`;") spark.sql(f"USE `{namespace}`;")
\# Create table and display schema (without LOCATION) spark.sql("DROP TABLE IF EXISTS example_iceberg_table") spark.sql("CREATE TABLE example_iceberg_table (id int, data string) USING ICEBERG") spark.sql("DESCRIBE example_iceberg_table;")
\# Insert table data. spark.sql("INSERT INTO example_iceberg_table VALUES (1, 'first row');")
\# Alter table, then display schema. spark.sql("ALTER TABLE example_iceberg_table ADD COLUMNS (newDoubleCol double);")
\# Select and display the contents of the table. spark.sql("SELECT * FROM example_iceberg_table").show()Substitua:
- PROJECT_ID: o ID do projeto do Google Cloud . Os IDs do projeto estão listados na seção Informações do projeto no Google Cloud painel do console.
- CATALOG_NAME e NAMESPACE: o nome do catálogo e o namespace do Iceberg se combinam para identificar a tabela do Iceberg (
catalog.namespace.table_name). - LOCATION: um local do BigQuery compatível. O local padrão é "US".
- BUCKET e WAREHOUSE_DIRECTORY: bucket e pasta do Cloud Storage usados como diretório do data warehouse do Iceberg.
Clique no ícone de execução ou pressione
Shift-Enterpara executar o código. Quando o job for concluído, a mensagem de status vai mostrar "Spark Job Finished", e a saída vai exibir o conteúdo da tabela:
Ver metadados da tabela no BigQuery
No console do Google Cloud , acesse a página BigQuery.
Ver metadados da tabela Iceberg.
Mapeamento de banco de dados OSS para conjunto de dados do BigQuery
Observe o seguinte mapeamento entre os termos de banco de dados de código aberto e conjunto de dados do BigQuery:
Banco de dados de OSS Conjunto de dados do BigQuery Namespace, banco de dados Conjunto de dados Tabela particionada ou não particionada Tabela Ver Ver Criar uma tabela do Iceberg
Nesta seção, mostramos como criar uma tabela do Iceberg com metadados no metastore do BigLake enviando um código do Spark SQL para o serviço Dataproc, a CLI do Spark SQL e a interface da Web do componente Zeppelin, que são executados em um cluster do Dataproc.
Job do Dataproc
É possível enviar um job ao serviço do Dataproc enviando o job a um cluster do Dataproc usando o consoleGoogle Cloud ou a Google Cloud CLI ou por uma solicitação REST HTTP ou uma chamada programática gRPC das bibliotecas de cliente do Cloud do Dataproc para a API Jobs do Dataproc.
Os exemplos nesta seção mostram como enviar um job do Spark SQL do Dataproc ao serviço do Dataproc para criar uma tabela do Iceberg com metadados no BigQuery usando a CLI gcloud, o console Google Cloud ou a API REST do Dataproc.
Preparar arquivos de job
Siga estas etapas para criar um arquivo de job do Spark SQL. O arquivo contém comandos do Spark SQL para criar e atualizar uma tabela Iceberg.
Em seguida, faça o download e copie o arquivo JAR
iceberg-spark-runtime-3.5_2.12-1.6.1para o Cloud Storage.Enviar o job do Spark SQL
Selecione uma guia para seguir as instruções de envio do job do Spark SQL ao serviço do Dataproc usando a CLI gcloud, o consoleGoogle Cloud ou a API REST do Dataproc.
gcloud
Console
Siga estas etapas para usar o console Google Cloud e enviar o job do Spark SQL ao serviço do Dataproc para criar uma tabela do Iceberg com metadados no metastore do BigLake.
REST
Use a API jobs.submit do Dataproc para enviar o job do Spark SQL ao serviço do Dataproc e criar uma tabela do Iceberg com metadados no metastore do BigLake.
Antes de usar os dados da solicitação abaixo, faça as substituições a seguir:
Método HTTP e URL:
POST https://dataproc.googleapis.com/v1/projects/PROJECT_ID/regions/REGION/jobs:submit
Corpo JSON da solicitação:
{ "projectId": "PROJECT_ID", "job": { "placement": { "clusterName": "CLUSTER_NAME" }, "statusHistory": [], "reference": { "jobId": "", "projectId": "PROJECT_ID" }, "sparkSqlJob": { "properties": { "spark.sql.catalog."CATALOG_NAME": "org.apache.iceberg.spark.SparkCatalog", "spark.sql.catalog."CATALOG_NAME".catalog-impl": "org.apache.iceberg.gcp.bigquery.BigQueryMetastoreCatalog", "spark.sql.catalog."CATALOG_NAME".gcp_project": "PROJECT_ID", "spark.sql.catalog."CATALOG_NAME".gcp_location": "LOCATION", "spark.sql.catalog."CATALOG_NAME".warehouse": "gs://BUCKET/WAREHOUSE_FOLDER" }, "jarFileUris": [ "gs://BUCKET/iceberg-spark-runtime-3.5_2.12-1.5.2.jar,gs://spark-lib/bigquery/iceberg-bigquery-catalog-1.5.2-1.0.1-beta.jar" ], "scriptVariables": {}, "queryFileUri": "gs://BUCKET/iceberg-table.sql" } } }Para enviar a solicitação, expanda uma destas opções:
Você receberá uma resposta JSON semelhante a esta:
{ "reference": { "projectId": "PROJECT_ID", "jobId": "..." }, "placement": { "clusterName": "CLUSTER_NAME", "clusterUuid": "..." }, "status": { "state": "PENDING", "stateStartTime": "..." }, "submittedBy": "USER", "sparkSqlJob": { "queryFileUri": "gs://BUCKET/iceberg-table.sql", "properties": { "spark.sql.catalog.USER_catalog": "org.apache.iceberg.spark.SparkCatalog", "spark.sql.catalog.USER_catalog.catalog-impl": "org.apache.iceberg.gcp.bigquery.BigQueryMetastoreCatalog", "spark.sql.catalog.USER_catalog.gcp_project": "PROJECT_ID", "spark.sql.catalog.USER_catalog.gcp_location": "LOCATION", "spark.sql.catalog.USER_catalog.warehouse": "gs://BUCKET/WAREHOUSE_FOLDER" }, "jarFileUris": [ "gs://BUCKET/iceberg-spark-runtime-3.5_2.12-1.5.2.jar", "gs://spark-lib/bigquery/iceberg-bigquery-catalog-1.5.2-1.0.1-beta.jar" ] }, "driverControlFilesUri": "gs://dataproc-...", "driverOutputResourceUri": "gs://dataproc-.../driveroutput", "jobUuid": "...", "region": "REGION" }Para monitorar o progresso do job e ver a saída dele, acesse a página Jobs do Dataproc no console do Google Cloud e clique em
Job IDpara abrir a página Detalhes do job.
Para ver os metadados da tabela no BigQuery
CLI do Spark SQL
As etapas a seguir mostram como criar uma tabela do Iceberg com metadados da tabela armazenados no metastore do BigLake usando a CLI do Spark SQL em execução no nó principal de um cluster do Dataproc.
Interface da Web do Zeppelin
As etapas a seguir mostram como criar uma tabela do Iceberg com metadados armazenados no metastore do BigLake usando a interface da Web do Zeppelin executada no nó principal de um cluster do Dataproc .