En este documento, se muestra cómo crear una tabla de Apache Iceberg con metadatos en BigLake Metastore usando el servicio de Dataproc Jobs, la CLI de Spark SQL o la interfaz web de Zeppelin que se ejecuta en un clúster de Dataproc.
Antes de comenzar
Si aún no lo hiciste, crea un Google Cloud proyecto, un bucket de Cloud Storage y un clúster de Dataproc.
Configura tu proyecto
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Dataproc, BigQuery, and Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Install the Google Cloud CLI.
-
Si usas un proveedor de identidad externo (IdP), primero debes acceder a gcloud CLI con tu identidad federada.
-
Para inicializar gcloud CLI, ejecuta el siguiente comando:
gcloud init -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Dataproc, BigQuery, and Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Install the Google Cloud CLI.
-
Si usas un proveedor de identidad externo (IdP), primero debes acceder a gcloud CLI con tu identidad federada.
-
Para inicializar gcloud CLI, ejecuta el siguiente comando:
gcloud init Crea un bucket de Cloud Storage en tu proyecto.
- In the Google Cloud console, go to the Cloud Storage Buckets page.
- Click Create.
- On the Create a bucket page, enter your bucket information. To go to the next
step, click Continue.
-
In the Get started section, do the following:
- Enter a globally unique name that meets the bucket naming requirements.
- To add a
bucket label,
expand the Labels section (),
click add_box
Add label, and specify a
keyand avaluefor your label.
-
In the Choose where to store your data section, do the following:
- Select a Location type.
- Choose a location where your bucket's data is permanently stored from the Location type drop-down menu.
- If you select the dual-region location type, you can also choose to enable turbo replication by using the relevant checkbox.
- To set up cross-bucket replication, select
Add cross-bucket replication via Storage Transfer Service and
follow these steps:
Set up cross-bucket replication
- In the Bucket menu, select a bucket.
In the Replication settings section, click Configure to configure settings for the replication job.
The Configure cross-bucket replication pane appears.
- To filter objects to replicate by object name prefix, enter a prefix that you want to include or exclude objects from, then click Add a prefix.
- To set a storage class for the replicated objects, select a storage class from the Storage class menu. If you skip this step, the replicated objects will use the destination bucket's storage class by default.
- Click Done.
-
In the Choose how to store your data section, do the following:
- Select a default storage class for the bucket or Autoclass for automatic storage class management of your bucket's data.
- To enable hierarchical namespace, in the Optimize storage for data-intensive workloads section, select Enable hierarchical namespace on this bucket.
- In the Choose how to control access to objects section, select whether or not your bucket enforces public access prevention, and select an access control method for your bucket's objects.
-
In the Choose how to protect object data section, do the
following:
- Select any of the options under Data protection that you
want to set for your bucket.
- To enable soft delete, click the Soft delete policy (For data recovery) checkbox, and specify the number of days you want to retain objects after deletion.
- To set Object Versioning, click the Object versioning (For version control) checkbox, and specify the maximum number of versions per object and the number of days after which the noncurrent versions expire.
- To enable the retention policy on objects and buckets, click the Retention (For compliance) checkbox, and then do the following:
- To enable Object Retention Lock, click the Enable object retention checkbox.
- To enable Bucket Lock, click the Set bucket retention policy checkbox, and choose a unit of time and a length of time for your retention period.
- To choose how your object data will be encrypted, expand the Data encryption section (), and select a Data encryption method.
- Select any of the options under Data protection that you
want to set for your bucket.
-
In the Get started section, do the following:
- Click Create.
Crea un clúster de Dataproc. Para ahorrar recursos y costos, puedes crear un clúster de Dataproc de un solo nodo para ejecutar los ejemplos que se presentan en este documento.
La subred de la región en la que se crea el clúster debe tener habilitado el Acceso privado a Google (PGA).
.Si deseas ejecutar el ejemplo de la interfaz web de Zeppelin en esta guía, debes usar o crear un clúster de Dataproc con el componente opcional de Zeppelin habilitado.
Otorga roles a una cuenta de servicio personalizada (si es necesario): De forma predeterminada, las VMs del clúster de Dataproc usan la cuenta de servicio predeterminada de Compute Engine para interactuar con Dataproc. Si deseas especificar una cuenta de servicio personalizada cuando crees tu clúster, esta debe tener el rol de trabajador de Dataproc (
roles/dataproc.worker) o un rol personalizado con los permisos necesarios del rol de trabajador.En una ventana de la terminal local o en Cloud Shell, usa un editor de texto, como
vionano, para copiar los siguientes comandos en un archivoiceberg-table.sqly, luego, guarda el archivo en el directorio actual.USE CATALOG_NAME; CREATE NAMESPACE IF NOT EXISTS example_namespace; USE example_namespace; DROP TABLE IF EXISTS example_table; CREATE TABLE example_table (id int, data string) USING ICEBERG LOCATION 'gs://BUCKET/WAREHOUSE_FOLDER'; INSERT INTO example_table VALUES (1, 'first row'); ALTER TABLE example_table ADD COLUMNS (newDoubleCol double); DESCRIBE TABLE example_table;
Reemplaza lo siguiente:
- CATALOG_NAME: Es el nombre del catálogo de Iceberg.
- BUCKET y WAREHOUSE_FOLDER: Son el bucket y la carpeta de Cloud Storage que se usan para el almacén de Iceberg.
Usa gcloud CLI para copiar el
iceberg-table.sqllocal en tu bucket de Cloud Storage.gcloud storage cp iceberg-table.sql gs://BUCKET/
En una ventana de la terminal local o en Cloud Shell, ejecuta el siguiente comando
curlpara descargar el archivo JARiceberg-spark-runtime-3.5_2.12-1.6.1en el directorio actual.curl -o iceberg-spark-runtime-3.5_2.12-1.6.1.jar https://storage-download.googleapis.com/maven-central/maven2/org/apache/iceberg/iceberg-spark-runtime-3.5_2.12/1.6.1/iceberg-spark-runtime-3.5_2.12-1.6.1.jar
Usa la gcloud CLI para copiar el archivo JAR
iceberg-spark-runtime-3.5_2.12-1.6.1local del directorio actual a tu bucket en Cloud Storage.gcloud storage cp iceberg-spark-runtime-3.5_2.12-1.6.1.jar gs://BUCKET/
Ejecuta el siguiente comando gcloud dataproc jobs submit spark-sql de forma local en una ventana de la terminal local o en Cloud Shell para enviar el trabajo de Spark SQL y crear la tabla de Iceberg.
gcloud dataproc jobs submit spark-sql \ --project=PROJECT_ID \ --cluster=CLUSTER_NAME \ --region=REGION \ --jars="gs://BUCKET/1.6.1/iceberg-spark-runtime-3.5_2.12-1.6.1.jar,gs://spark-lib/bigquery/iceberg-bigquery-catalog-1.6.1-1.0.1-beta.jar" \ --properties="spark.sql.catalog.CATALOG_NAME=org.apache.iceberg.spark.SparkCatalog,spark.sql.catalog.CATALOG_NAME.catalog-impl=org.apache.iceberg.gcp.bigquery.BigQueryMetastoreCatalog,spark.sql.catalog.CATALOG_NAME.gcp_project=PROJECT_ID,spark.sql.catalog.CATALOG_NAME.gcp_location=LOCATION,spark.sql.catalog.CATALOG_NAME.warehouse=gs://BUCKET/WAREHOUSE_FOLDER" \ -f="gs://BUCKETiceberg-table.sql"
Notas:
- PROJECT_ID: El ID de tu proyecto de Google Cloud . Los IDs del proyecto se enumeran en la sección Información del proyecto del panel de la consola Google Cloud .
- CLUSTER_NAME: Es el nombre de tu clúster de Dataproc.
- REGION: La región de Compute Engine en la que se encuentra tu clúster.
- CATALOG_NAME: Es el nombre del catálogo de Iceberg.
- BUCKET y WAREHOUSE_FOLDER: Son el bucket y la carpeta de Cloud Storage que se usan para el almacén de Iceberg.
- LOCATION: Una ubicación de BigQuery compatible. La ubicación predeterminada es "US".
--jars: Los archivos JAR enumerados son necesarios para crear metadatos de tablas en BigLake Metastore.--properties: Propiedades del catálogo.-f: Es el archivo de trabajoiceberg-table.sqlque copiaste en tu bucket de Cloud Storage.
Cuando finalice el trabajo, consulta la descripción de la tabla en el resultado de la terminal.
Time taken: 2.194 seconds id int data string newDoubleCol double Time taken: 1.479 seconds, Fetched 3 row(s) Job JOB_ID finished successfully.
Cómo ver los metadatos de la tabla en BigQuery
En la consola de Google Cloud , ve a la página BigQuery.
Visualiza los metadatos de la tabla de Iceberg.

En la consola de Google Cloud , ve a Enviar un trabajo de Dataproc.
Ve a la página Submit a job y, luego, completa los siguientes campos:
- ID de trabajo: Acepta el ID sugerido o inserta tu propio ID.
- Región: Selecciona la región en la que se encuentra tu clúster.
- Clúster: Selecciona tu clúster.
- Tipo de trabajo: Selecciona
SparkSql. - Tipo de fuente de consulta: Selecciona
Query file. - Archivo de consulta: Inserta
gs://BUCKET/iceberg-table.sql - Archivos JAR: Inserta lo siguiente:
gs://BUCKET/iceberg-spark-runtime-3.5_2.12-1.6.1.jar,gs://spark-lib/bigquery/iceberg-bigquery-catalog-1.6.1-1.0.1-beta.jar
- Propiedades: Haz clic en Agregar propiedad cinco veces para crear una lista de cinco campos de entrada
keyvaluey, luego, copia los siguientes pares de Clave y Valor para definir cinco propiedades.# Clave Valor 1. spark.sql.catalog.CATALOG_NAMEorg.apache.iceberg.spark.SparkCatalog2. spark.sql.catalog.CATALOG_NAME.catalog-implorg.apache.iceberg.gcp.bigquery.BigQueryMetastoreCatalog3. spark.sql.catalog.CATALOG_NAME.gcp_projectPROJECT_ID4. spark.sql.catalog.CATALOG_NAME.gcp_locationLOCATION5. spark.sql.catalog.CATALOG_NAME.warehousegs://BUCKET/WAREHOUSE_FOLDER
Notas:
- CATALOG_NAME: Es el nombre del catálogo de Iceberg.
- PROJECT_ID: El ID de tu proyecto de Google Cloud . Los IDs del proyecto se enumeran en la sección Información del proyecto del panel de la consola Google Cloud .región en la que se encuentra tu clúster.
- LOCATION: Una ubicación de BigQuery compatible. La ubicación predeterminada es "US".
- BUCKET y WAREHOUSE_FOLDER: Son el bucket y la carpeta de Cloud Storage que se usan para el almacén de Iceberg.
Haz clic en Enviar.
Para supervisar el progreso del trabajo y ver su resultado, ve a la página Trabajos de Dataproc en la consola de Google Cloud y, luego, haz clic en
Job IDpara abrir la página Detalles del trabajo.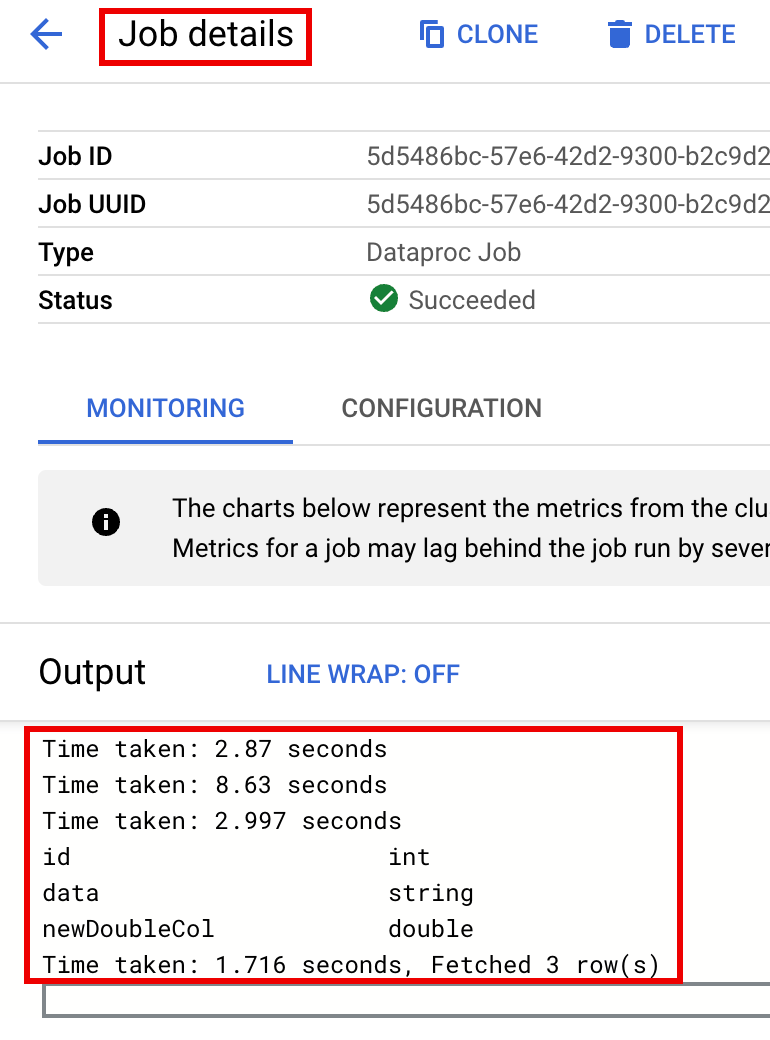
Cómo ver los metadatos de la tabla en BigQuery
En la consola de Google Cloud , ve a la página BigQuery.
Visualiza los metadatos de la tabla de Iceberg.
- PROJECT_ID: El ID de tu proyecto de Google Cloud . Los IDs del proyecto se enumeran en la sección Información del proyecto en el panel de la consola Google Cloud .
- CLUSTER_NAME: Es el nombre de tu clúster de Dataproc.
- REGION: La región de Compute Engine en la que se encuentra tu clúster.
- CATALOG_NAME: Es el nombre del catálogo de Iceberg.
- BUCKET y WAREHOUSE_FOLDER: Son el depósito y la carpeta de Cloud Storage que se usan para el almacén de Iceberg. LOCATION: Una ubicación de BigQuery compatible. La ubicación predeterminada es "US".
jarFileUris: Los archivos JAR enumerados son necesarios para crear metadatos de tablas en BigQuery Metastore.properties: Propiedades del catálogo.queryFileUri: Es el archivo de trabajoiceberg-table.sqlque copiaste en tu bucket de Cloud Storage.En la consola de Google Cloud , ve a la página BigQuery.
Visualiza los metadatos de la tabla de Iceberg.
Usa SSH para conectarte al nodo principal de tu clúster de Dataproc.
En la terminal de la sesión SSH, usa el editor de texto
vionanopara copiar los siguientes comandos en un archivoiceberg-table.sql.SET CATALOG_NAME = `CATALOG_NAME`; SET BUCKET = `BUCKET`; SET WAREHOUSE_FOLDER = `WAREHOUSE_FOLDER`; USE `${CATALOG_NAME}`; CREATE NAMESPACE IF NOT EXISTS `${CATALOG_NAME}`.example_namespace; DROP TABLE IF EXISTS `${CATALOG_NAME}`.example_namespace.example_table; CREATE TABLE `${CATALOG_NAME}`.example_namespace.example_table (id int, data string) USING ICEBERG LOCATION 'gs://${BUCKET}/${WAREHOUSE_FOLDER}'; INSERT INTO `${CATALOG_NAME}`.example_namespace.example_table VALUES (1, 'first row'); ALTER TABLE `${CATALOG_NAME}`.example_namespace.example_table ADD COLUMNS (newDoubleCol double); DESCRIBE TABLE `${CATALOG_NAME}`.example_namespace.example_table;Reemplaza lo siguiente:
- CATALOG_NAME: Es el nombre del catálogo de Iceberg.
- BUCKET y WAREHOUSE_FOLDER: Son el bucket y la carpeta de Cloud Storage que se usan para el almacén de Iceberg.
En la terminal de la sesión de SSH, ejecuta el siguiente comando
spark-sqlpara crear la tabla iceberg.spark-sql \ --packages org.apache.iceberg:iceberg-spark-runtime-3.5_2.12:1.6.1 \ --jars https://storage-download.googleapis.com/maven-central/maven2/org/apache/iceberg/iceberg-spark-runtime-3.5_2.12/1.6.1/iceberg-spark-runtime-3.5_2.12-1.6.1.jar,gs://spark-lib/bigquery/iceberg-bigquery-catalog-1.6.1-1.0.1-beta.jar \ --conf spark.sql.catalog.CATALOG_NAME=org.apache.iceberg.spark.SparkCatalog \ --conf spark.sql.catalog.CATALOG_NAME.catalog-impl=org.apache.iceberg.gcp.bigquery.BigQueryMetastoreCatalog \ --conf spark.sql.catalog.CATALOG_NAME.gcp_project=PROJECT_ID \ --conf spark.sql.catalog.CATALOG_NAME.gcp_location=LOCATION \ --conf spark.sql.catalog.CATALOG_NAME.warehouse=gs://BUCKET/WAREHOUSE_FOLDER \ -f iceberg-table.sql
Reemplaza lo siguiente:
- PROJECT_ID: El ID de tu proyecto de Google Cloud . Los IDs del proyecto se enumeran en la sección Información del proyecto del panel de la consola Google Cloud .
- LOCATION: Una ubicación de BigQuery compatible. La ubicación predeterminada es "US".
Cómo ver los metadatos de la tabla en BigQuery
En la consola de Google Cloud , ve a la página BigQuery.
Visualiza los metadatos de la tabla de Iceberg.
En la consola de Google Cloud , ve a la página Clústeres de Dataproc.
Selecciona el nombre del clúster para abrir la página Detalles del clúster.
Haz clic en la pestaña Interfaces web para ver una lista de los vínculos de Puerta de enlace de componentes a las interfaces web de los componentes predeterminados y opcionales instalados en el clúster.
Haz clic en el vínculo Zeppelin para abrir la interfaz web de Zeppelin.
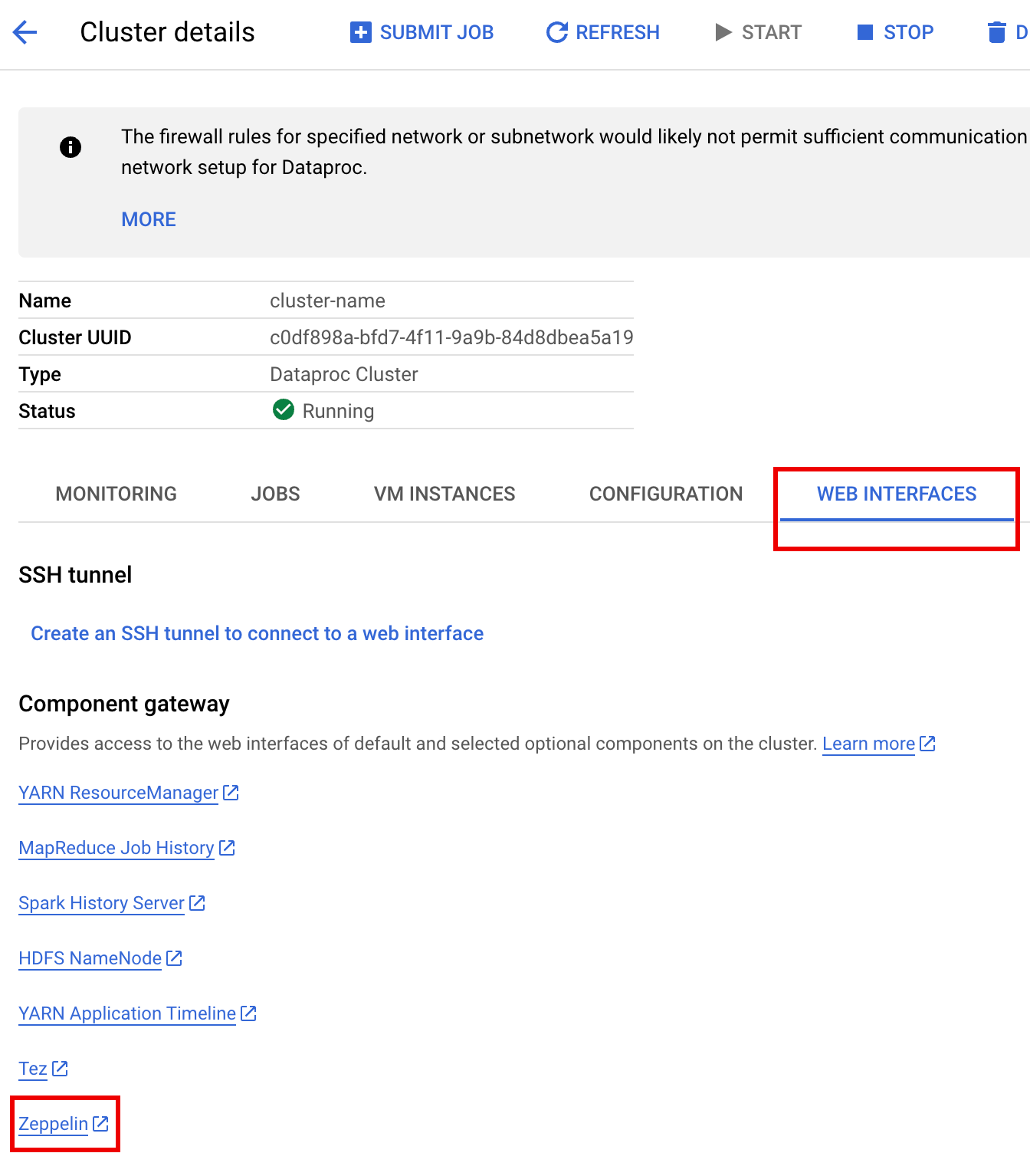
En la interfaz web de Zeppelin, haz clic en el menú anonymous y, luego, en Interpreter para abrir la página Interpreters.
Agrega dos archivos .jar al intérprete de Zeppelin Spark de la siguiente manera:
- Escribe "Spark" en el cuadro de
Search interpreterspara desplazarte a la sección del intérprete de Spark. - Haga clic en editar.
Pega lo siguiente en el campo spark.jars:
https://storage-download.googleapis.com/maven-central/maven2/org/apache/iceberg/iceberg-spark-runtime-3.5_2.12/1.6.1/iceberg-spark-runtime-3.5_2.12-1.6.1.jar,gs://spark-lib/bigquery/iceberg-bigquery-catalog-1.6.1-1.0.1-beta.jar

Haz clic en Guardar en la parte inferior de la sección del intérprete de Spark y, luego, haz clic en Aceptar para actualizar el intérprete y reiniciarlo con la nueva configuración.
- Escribe "Spark" en el cuadro de
En el menú del notebook de Zeppelin, haz clic en Create new note.
En el diálogo Crear una nota nueva, ingresa un nombre para el notebook y acepta el intérprete spark predeterminado. Haz clic en Crear para abrir el notebook.
Copia el siguiente código de PySpark en tu notebook de Zeppelin después de completar las variables.
%pyspark
from pyspark.sql import SparkSession
project_id = "PROJECT_ID" catalog = "CATALOG_NAME" namespace = "NAMESPACE" location = "LOCATION" warehouse_dir = "gs://BUCKET/WAREHOUSE_DIRECTORY"
spark = SparkSession.builder \ .appName("BigQuery Metastore Iceberg") \ .config(f"spark.sql.catalog.{catalog}", "org.apache.iceberg.spark.SparkCatalog") \ .config(f"spark.sql.catalog.{catalog}.catalog-impl", "org.apache.iceberg.gcp.bigquery.BigQueryMetastoreCatalog") \ .config(f"spark.sql.catalog.{catalog}.gcp_project", f"{project_id}") \ .config(f"spark.sql.catalog.{catalog}.gcp_location", f"{location}") \ .config(f"spark.sql.catalog.{catalog}.warehouse", f"{warehouse_dir}") \ .getOrCreate()
spark.sql(f"USE `{catalog}`;") spark.sql(f"CREATE NAMESPACE IF NOT EXISTS `{namespace}`;") spark.sql(f"USE `{namespace}`;")
\# Create table and display schema (without LOCATION) spark.sql("DROP TABLE IF EXISTS example_iceberg_table") spark.sql("CREATE TABLE example_iceberg_table (id int, data string) USING ICEBERG") spark.sql("DESCRIBE example_iceberg_table;")
\# Insert table data. spark.sql("INSERT INTO example_iceberg_table VALUES (1, 'first row');")
\# Alter table, then display schema. spark.sql("ALTER TABLE example_iceberg_table ADD COLUMNS (newDoubleCol double);")
\# Select and display the contents of the table. spark.sql("SELECT * FROM example_iceberg_table").show()Reemplaza lo siguiente:
- PROJECT_ID: El ID de tu proyecto de Google Cloud . Los IDs del proyecto se enumeran en la sección Información del proyecto del panel de la consola Google Cloud .
- CATALOG_NAME y NAMESPACE: El nombre y el espacio de nombres del catálogo de Iceberg se combinan para identificar la tabla de Iceberg (
catalog.namespace.table_name). - LOCATION: Una ubicación de BigQuery compatible. La ubicación predeterminada es "US".
- BUCKET y WAREHOUSE_DIRECTORY: Son el bucket y la carpeta de Cloud Storage que se usan como directorio del almacén de Iceberg.
Haz clic en el ícono de ejecución o presiona
Shift-Enterpara ejecutar el código. Cuando el trabajo se completa, el mensaje de estado muestra "Spark Job Finished" y el resultado muestra el contenido de la tabla:
Cómo ver los metadatos de la tabla en BigQuery
En la consola de Google Cloud , ve a la página BigQuery.
Visualiza los metadatos de la tabla de Iceberg.
Asignación de la base de datos de OSS al conjunto de datos de BigQuery
Ten en cuenta la siguiente asignación entre los términos de la base de datos de código abierto y los del conjunto de datos de BigQuery:
Base de datos de OSS Conjunto de datos de BigQuery Espacio de nombres y base de datos Conjunto de datos Tabla particionada o no particionada Tabla Ver Ver Crea una tabla de Iceberg
En esta sección, se muestra cómo crear una tabla de Iceberg con metadatos en BigLake Metastore. Para ello, envía un código de Spark SQL al servicio de Dataproc, a la CLI de Spark SQL y a la interfaz web del componente de Zeppelin, que se ejecutan en un clúster de Dataproc.
Trabajo de Dataproc
Puedes enviar un trabajo al servicio de Dataproc enviándolo a un clúster de Dataproc con la consola deGoogle Cloud o la CLI de Google Cloud, o bien a través de una solicitud REST HTTP o una llamada programática gRPC de las bibliotecas cliente de Cloud de Dataproc a la API de Dataproc Jobs.
En los ejemplos de esta sección,se muestra cómo enviar un trabajo de Spark SQL de Dataproc al servicio de Dataproc para crear una tabla de Iceberg con metadatos en BigQuery con gcloud CLI, la consola de Google Cloud o la API de REST de Dataproc.
Prepara archivos de trabajo
Sigue estos pasos para crear un archivo de trabajo de Spark SQL. El archivo contiene comandos de Spark SQL para crear y actualizar una tabla de Iceberg.
A continuación, descarga y copia el archivo JAR
iceberg-spark-runtime-3.5_2.12-1.6.1en Cloud Storage.Envía el trabajo de Spark SQL
Selecciona una pestaña para seguir las instrucciones y enviar el trabajo de Spark SQL al servicio de Dataproc con gcloud CLI deGoogle Cloud o la API de REST de Dataproc.
gcloud
Console
Sigue estos pasos para usar la consola de Google Cloud y enviar el trabajo de Spark SQL al servicio de Dataproc para crear una tabla de Iceberg con metadatos en BigLake Metastore.
REST
Puedes usar la API de jobs.submit de Dataproc para enviar el trabajo de Spark SQL al servicio de Dataproc y crear una tabla de Iceberg con metadatos en el metastore de BigLake.
Antes de usar cualquiera de los datos de solicitud a continuación, realiza los siguientes reemplazos:
Método HTTP y URL:
POST https://dataproc.googleapis.com/v1/projects/PROJECT_ID/regions/REGION/jobs:submit
Cuerpo JSON de la solicitud:
{ "projectId": "PROJECT_ID", "job": { "placement": { "clusterName": "CLUSTER_NAME" }, "statusHistory": [], "reference": { "jobId": "", "projectId": "PROJECT_ID" }, "sparkSqlJob": { "properties": { "spark.sql.catalog."CATALOG_NAME": "org.apache.iceberg.spark.SparkCatalog", "spark.sql.catalog."CATALOG_NAME".catalog-impl": "org.apache.iceberg.gcp.bigquery.BigQueryMetastoreCatalog", "spark.sql.catalog."CATALOG_NAME".gcp_project": "PROJECT_ID", "spark.sql.catalog."CATALOG_NAME".gcp_location": "LOCATION", "spark.sql.catalog."CATALOG_NAME".warehouse": "gs://BUCKET/WAREHOUSE_FOLDER" }, "jarFileUris": [ "gs://BUCKET/iceberg-spark-runtime-3.5_2.12-1.5.2.jar,gs://spark-lib/bigquery/iceberg-bigquery-catalog-1.5.2-1.0.1-beta.jar" ], "scriptVariables": {}, "queryFileUri": "gs://BUCKET/iceberg-table.sql" } } }Para enviar tu solicitud, expande una de estas opciones:
Deberías recibir una respuesta JSON similar a la que se muestra a continuación:
{ "reference": { "projectId": "PROJECT_ID", "jobId": "..." }, "placement": { "clusterName": "CLUSTER_NAME", "clusterUuid": "..." }, "status": { "state": "PENDING", "stateStartTime": "..." }, "submittedBy": "USER", "sparkSqlJob": { "queryFileUri": "gs://BUCKET/iceberg-table.sql", "properties": { "spark.sql.catalog.USER_catalog": "org.apache.iceberg.spark.SparkCatalog", "spark.sql.catalog.USER_catalog.catalog-impl": "org.apache.iceberg.gcp.bigquery.BigQueryMetastoreCatalog", "spark.sql.catalog.USER_catalog.gcp_project": "PROJECT_ID", "spark.sql.catalog.USER_catalog.gcp_location": "LOCATION", "spark.sql.catalog.USER_catalog.warehouse": "gs://BUCKET/WAREHOUSE_FOLDER" }, "jarFileUris": [ "gs://BUCKET/iceberg-spark-runtime-3.5_2.12-1.5.2.jar", "gs://spark-lib/bigquery/iceberg-bigquery-catalog-1.5.2-1.0.1-beta.jar" ] }, "driverControlFilesUri": "gs://dataproc-...", "driverOutputResourceUri": "gs://dataproc-.../driveroutput", "jobUuid": "...", "region": "REGION" }Para supervisar el progreso del trabajo y ver su resultado, ve a la página Trabajos de Dataproc en la consola de Google Cloud y, luego, haz clic en
Job IDpara abrir la página Detalles del trabajo.
Cómo ver los metadatos de la tabla en BigQuery
CLI de Spark SQL
En los siguientes pasos, se muestra cómo crear una tabla de Iceberg con metadatos de la tabla almacenados en el metastore de BigLake con la CLI de Spark SQL que se ejecuta en el nodo principal de un clúster de Dataproc.
Interfaz web de Zeppelin
En los siguientes pasos, se muestra cómo crear una tabla de Iceberg con metadatos de tabla almacenados en BigLake Metastore a través de la interfaz web de Zeppelin que se ejecuta en el nodo principal de un clúster de Dataproc .