Cuando envías un trabajo de Dataproc, Dataproc recopila automáticamente el resultado del trabajo y lo pone a tu disposición. Esto significa que puedes revisar con rapidez el resultado del trabajo sin tener que mantener una conexión con el clúster mientras se ejecutan tus trabajos o analizar archivos de registro complicados.
Registros de Spark
Existen dos tipos de registros de Spark: los registros del controlador de Spark y los registros del ejecutor de Spark.
Los registros del controlador de Spark contienen el resultado del trabajo, mientras que los registros del ejecutor de Spark contienen el resultado del ejecutable o del iniciador del trabajo, como un mensaje spark-submit "Submitted application xxx", y pueden ser útiles para depurar las fallas del trabajo.
El controlador de trabajos de Dataproc, que es distinto del controlador de Spark, es un iniciador para muchos tipos de trabajos. Cuando se inician trabajos de Spark, se ejecuta como un wrapper en el ejecutable spark-submit subyacente, que inicia el controlador de Spark. El controlador de Spark ejecuta el trabajo en el clúster de Dataproc en el modo client o cluster de Spark:
Modo
client: El controlador de Spark ejecuta el trabajo en el procesospark-submity los registros de Spark se envían al controlador del trabajo de Dataproc.Modo
cluster: El controlador de Spark ejecuta el trabajo en un contenedor de YARN. Los registros del controlador de Spark no están disponibles para el controlador del trabajo de Dataproc.
Descripción general de las propiedades de los trabajos de Dataproc y Spark
| Propiedad | Valor | Default | Descripción |
|---|---|---|---|
dataproc:dataproc.logging.stackdriver.job.driver.enable |
True o False | falso | Se debe configurar en el momento de la creación del clúster. Cuando es true, el resultado del controlador de trabajos se encuentra en Logging y está asociado con el recurso del trabajo. Cuando es false, el resultado del controlador de trabajos no se encuentra en Logging.Nota: Los siguientes parámetros de configuración de propiedades del clúster también son necesarios para habilitar los registros del controlador de trabajos en Logging y se establecen de forma predeterminada cuando se crea un clúster: dataproc:dataproc.logging.stackdriver.enable=true
y dataproc:jobs.file-backed-output.enable=true
|
dataproc:dataproc.logging.stackdriver.job.yarn.container.enable |
True o False | falso | Se debe configurar en el momento de la creación del clúster.
Cuando es true, los registros de contenedores de YARN del trabajo se asocian con el recurso del trabajo; cuando es false, los registros de contenedores de YARN del trabajo se asocian con el recurso del clúster. |
spark:spark.submit.deployMode |
cliente o clúster | cliente | Controla el modo client o cluster de Spark. |
Trabajos de Spark enviados con la API de jobs de Dataproc
En las tablas de esta sección, se indica el efecto de los diferentes parámetros de configuración de propiedades en el destino del resultado del controlador de trabajos de Dataproc cuando los trabajos se envían a través de la API de Dataproc jobs, lo que incluye el envío de trabajos a través de la consola deGoogle Cloud , gcloud CLI y las bibliotecas cliente de Cloud.
Las propiedades de Dataproc y Spark que se indican en la lista se pueden configurar con la marca --properties cuando se crea un clúster y se aplicarán a todos los trabajos de Spark que se ejecuten en el clúster. Las propiedades de Spark también se pueden configurar con la marca --properties (sin el prefijo "spark:") cuando se envía un trabajo a la API de Dataproc jobs y se aplicarán solo al trabajo.
Salida del controlador de trabajos de Dataproc
En las siguientes tablas, se indica el efecto de los diferentes parámetros de configuración de propiedades en el destino de la salida del controlador de trabajos de Dataproc.
dataproc: |
Salida |
|---|---|
| false (predeterminado) |
|
| verdadero |
|
Registros del controlador de Spark
En las siguientes tablas, se indica el efecto de los diferentes parámetros de configuración de propiedades en el destino de los registros del controlador de Spark.
spark: |
dataproc: |
dataproc: |
Salida del controlador |
|---|---|---|---|
| cliente | false (predeterminado) | True o False |
|
| cliente | verdadero | True o False |
|
| clúster | false (predeterminado) | falso |
|
| clúster | verdadero | verdadero |
|
Registros del ejecutor de Spark
En las siguientes tablas, se indica el efecto de los diferentes parámetros de configuración de propiedades en el destino de los registros del ejecutor de Spark.
dataproc: |
Registro del ejecutor |
|---|---|
| false (predeterminado) | En Logging: yarn-userlogs en el recurso del clúster |
| verdadero | En Logging dataproc.job.yarn.container en el recurso del trabajo |
Trabajos de Spark enviados sin usar la API de jobs de Dataproc
En esta sección, se indica el efecto de los diferentes parámetros de configuración de propiedades en el destino de los registros de trabajos de Spark cuando se envían trabajos sin usar la API de Dataproc jobs, por ejemplo, cuando se envía un trabajo directamente en un nodo del clúster con spark-submit o cuando se usa un notebook de Jupyter o Zeppelin. Estos trabajos no tienen IDs ni controladores de trabajos de Dataproc.
Registros del controlador de Spark
En las siguientes tablas, se indica el efecto de los diferentes parámetros de configuración de propiedades en el destino de los registros del controlador de Spark para los trabajos que no se envían a través de la API de Dataproc jobs.
spark: |
Salida del controlador |
|---|---|
| cliente |
|
| clúster |
|
Registros del ejecutor de Spark
Cuando los trabajos de Spark no se envían a través de la API de jobs de Dataproc, los registros del ejecutor se encuentran en Logging yarn-userlogs, en el recurso del clúster.
Cómo ver el resultado del trabajo
Puedes acceder al resultado del trabajo de Dataproc en la Google Cloud consola, gcloud CLI, Cloud Storage o Logging.
Console
Para ver el resultado del trabajo, ve a la sección Trabajos de tu proyecto de Dataproc y luego haz clic en el ID del trabajo para ver el resultado del trabajo.
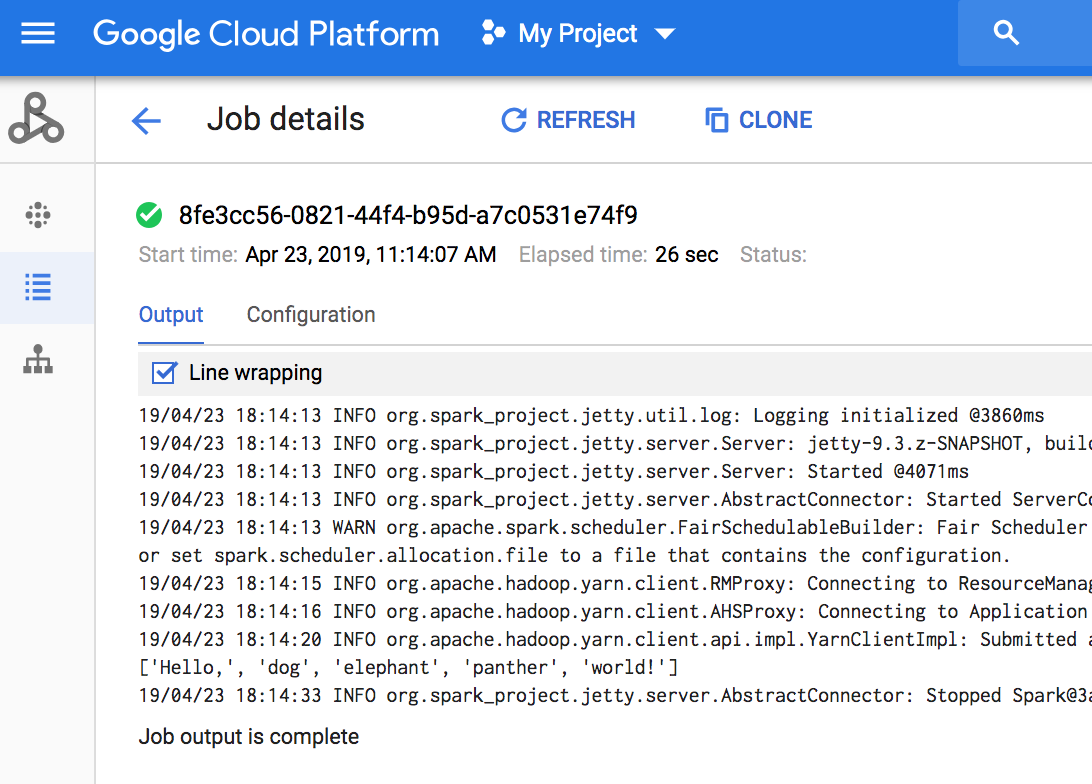
Si el trabajo se está ejecutando, el resultado del trabajo se actualiza de forma periódica con contenido nuevo.
Comando de gcloud
Cuando envías un trabajo con el comando gcloud dataproc jobs submit, el resultado del trabajo se muestra en la consola. Puedes “reunificar” el resultado más adelante, en una computadora diferente o en una nueva ventana si pasas el ID de tu trabajo al comando gcloud dataproc jobs wait. El ID del trabajo es un GUID, como 5c1754a5-34f7-4553-b667-8a1199cb9cab. A continuación, se muestra un ejemplo.
gcloud dataproc jobs wait 5c1754a5-34f7-4553-b667-8a1199cb9cab \ --project my-project-id --region my-cluster-region
Waiting for job output... ... INFO gcs.GoogleHadoopFileSystemBase: GHFS version: 1.4.2-hadoop2 ... 16:47:45 INFO client.RMProxy: Connecting to ResourceManager at my-test-cluster-m/ ...
Cloud Storage
El resultado del trabajo se almacena en Cloud Storage en el bucket de etapa de pruebas o en el bucket que especificaste cuando creaste tu clúster. Se proporciona un vínculo al resultado del trabajo en Cloud Storage en el campo Job.driverOutputResourceUri que muestran estas opciones:
- Una solicitud a la API de jobs.get
- Un comando gcloud dataproc jobs describe job-id
$ gcloud dataproc jobs describe spark-pi ... driverOutputResourceUri: gs://dataproc-nnn/jobs/spark-pi/driveroutput ...