When you submit a Dataproc job, Dataproc automatically gathers the job output, and makes it available to you. This means you can quickly review job output without having to maintain a connection to the cluster while your jobs run or look through complicated log files.
Spark logs
There are two types of Spark logs: Spark driver logs and Spark executor logs.
Spark driver logs contain job output; Spark executor logs contain job executable
or launcher output, such as a spark-submit "Submitted application xxx" message, and
can be helpful for debugging job failures.
The Dataproc job driver, which is distinct from the Spark driver,
is a launcher for many job types. When launching Spark jobs, it runs as a
wrapper on the underlying spark-submit executable, which launches the Spark
driver. The Spark driver runs the job on the Dataproc cluster in Spark
client or cluster mode:
clientmode: the Spark driver runs the job in thespark-submitprocess, and Spark logs are sent to the Dataproc job driver.clustermode: the Spark driver runs the job in a YARN container. Spark driver logs are not available to the Dataproc job driver.
Dataproc and Spark job properties overview
| Property | Value | Default | Description |
|---|---|---|---|
dataproc:dataproc.logging.stackdriver.job.driver.enable |
true or false | false | Must be set at cluster creation time. When true,
job driver output is in Logging,
associated with the job resource; when false, job driver
output is not in Logging.Note: The following cluster property settings are also required to enable job driver logs in Logging, and are set by default when a cluster is created: dataproc:dataproc.logging.stackdriver.enable=true
and dataproc:jobs.file-backed-output.enable=true
|
dataproc:dataproc.logging.stackdriver.job.yarn.container.enable |
true or false | false | Must be set at cluster creation time.
When true, job YARN container logs are associated
with the job resource; when false, job YARN container logs
are associated with the cluster resource. |
spark:spark.submit.deployMode |
client or cluster | client | Controls Spark client or cluster mode. |
Spark jobs submitted using the Dataproc jobs API
The tables in this section list the effect of different property settings on the
destination of Dataproc job driver output when jobs are submitted
through the Dataproc jobs API, which includes job submission through the
Google Cloud console, gcloud CLI, and Cloud Client Libraries.
The listed Dataproc and Spark properties
can be set with the --properties flag when a cluster is created, and will apply
to all Spark jobs run on the cluster; Spark properties can also be set with the
--properties flag (without the "spark:" prefix) when a job is
submitted to the Dataproc jobs API, and will apply only to the job.
Dataproc job driver output
The following tables list the effect of different property settings on the destination of Dataproc job driver output.
dataproc: |
Output |
|---|---|
| false (default) |
|
| true |
|
Spark driver logs
The following tables list the effect of different property settings on the destination of Spark driver logs.
spark: |
dataproc: |
dataproc: |
Driver Output |
|---|---|---|---|
| client | false (default) | true or false |
|
| client | true | true or false |
|
| cluster | false (default) | false |
|
| cluster | true | true |
|
Spark executor logs
The following tables list the effect of different property settings on the destination of Spark executor logs.
dataproc: |
Executor log |
|---|---|
| false (default) | In Logging: yarn-userlogs under the cluster resource |
| true | In Logging dataproc.job.yarn.container under the job resource |
Spark jobs submitted without using the Dataproc jobs API
This section lists the effect of different property settings on the
destination of Spark job logs when jobs are submitted
without using the Dataproc jobs API, for example when submitting
a job directly on a cluster node using spark-submit or when using a Jupyter
or Zeppelin notebook. These jobs do not have Dataproc job IDs or drivers.
Spark driver logs
The following tables list the effect of different property settings on the
destination of Spark driver logs for jobs not submitted through the Dataproc jobs API.
spark: |
Driver Output |
|---|---|
| client |
|
| cluster |
|
Spark executor logs
When Spark jobs are not submitted through the Dataproc jobs API, executor
logs are in Logging yarn-userlogs under the cluster resource.
View job output
You can access Dataproc job output in the Google Cloud console, the gcloud CLI, Cloud Storage, or Logging.
Console
To view job output, go to your project's Dataproc Jobs section, then click on the Job ID to view job output.
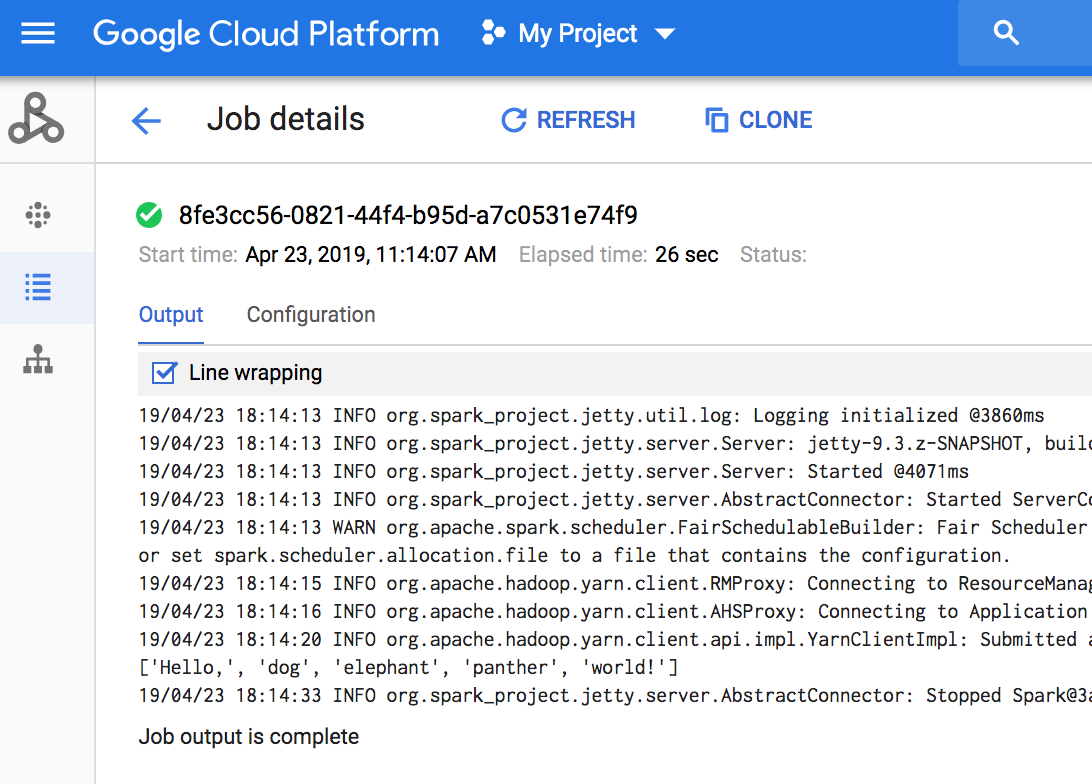
If the job is running, job output periodically refreshes with new content.
gcloud command
When you submit a job with the
gcloud dataproc jobs submit
command, job output is displayed on the console. You can "rejoin"
output at a later time, on a different computer, or in
a new window by passing your job's ID to the
gcloud dataproc jobs wait
command. The Job ID is a
GUID,
such as 5c1754a5-34f7-4553-b667-8a1199cb9cab. Here's an example.
gcloud dataproc jobs wait 5c1754a5-34f7-4553-b667-8a1199cb9cab \ --project my-project-id --region my-cluster-region
Waiting for job output... ... INFO gcs.GoogleHadoopFileSystemBase: GHFS version: 1.4.2-hadoop2 ... 16:47:45 INFO client.RMProxy: Connecting to ResourceManager at my-test-cluster-m/ ...
Cloud Storage
Job output is stored in Cloud Storage in either the staging bucket or the bucket you specified when you created your cluster. A link to job output in Cloud Storage is provided in the Job.driverOutputResourceUri field returned by:
- a jobs.get API request.
- a gcloud dataproc jobs describe job-id
command.
$ gcloud dataproc jobs describe spark-pi ... driverOutputResourceUri: gs://dataproc-nnn/jobs/spark-pi/driveroutput ...