Puedes crear una alerta de Monitoring que te notifique cuando un clúster de Dataproc o una métrica de trabajo supere un umbral especificado.
Crea una alerta
Abre la página Alertas en la consola de Google Cloud .
Haz clic en + Crear política para abrir la página Crear política de alertas.
- Haz clic en Seleccionar métrica.
- En el cuadro de entrada "Filtrar por nombre de recurso o métrica", escribe "dataproc" para enumerar las métricas de Dataproc. Navega por la jerarquía de métricas de Cloud Dataproc para seleccionar una métrica de clúster, trabajo, lote o sesión.
- Haz clic en Aplicar.
- Haz clic en Siguiente para abrir el panel Configurar activador de alertas.
- Establece un valor de límite para activar la alerta.
- Haz clic en Siguiente para abrir el panel Configurar notificaciones y finalizar la alerta.
- Configura los canales de notificación, la documentación y el nombre de la política de alertas.
- Haz clic en Siguiente para revisar la política de alertas.
- Haz clic en Crear política para crear la alerta.
Alertas de muestra
En esta sección, se describen ejemplos de alertas para un trabajo enviado al servicio de Dataproc y para un trabajo ejecutado como una aplicación de YARN.
Alerta de trabajo de Dataproc de larga duración
Dataproc emite la métrica dataproc.googleapis.com/job/state, que hace un seguimiento del tiempo que un trabajo estuvo en diferentes estados. Esta métrica se encuentra en el Explorador de métricas de la consola de Google Cloud en el recurso Trabajo de Cloud Dataproc (cloud_dataproc_job).
Puedes usar esta métrica para configurar una alerta que te notifique cuando el estado RUNNING del trabajo supere un umbral de duración.
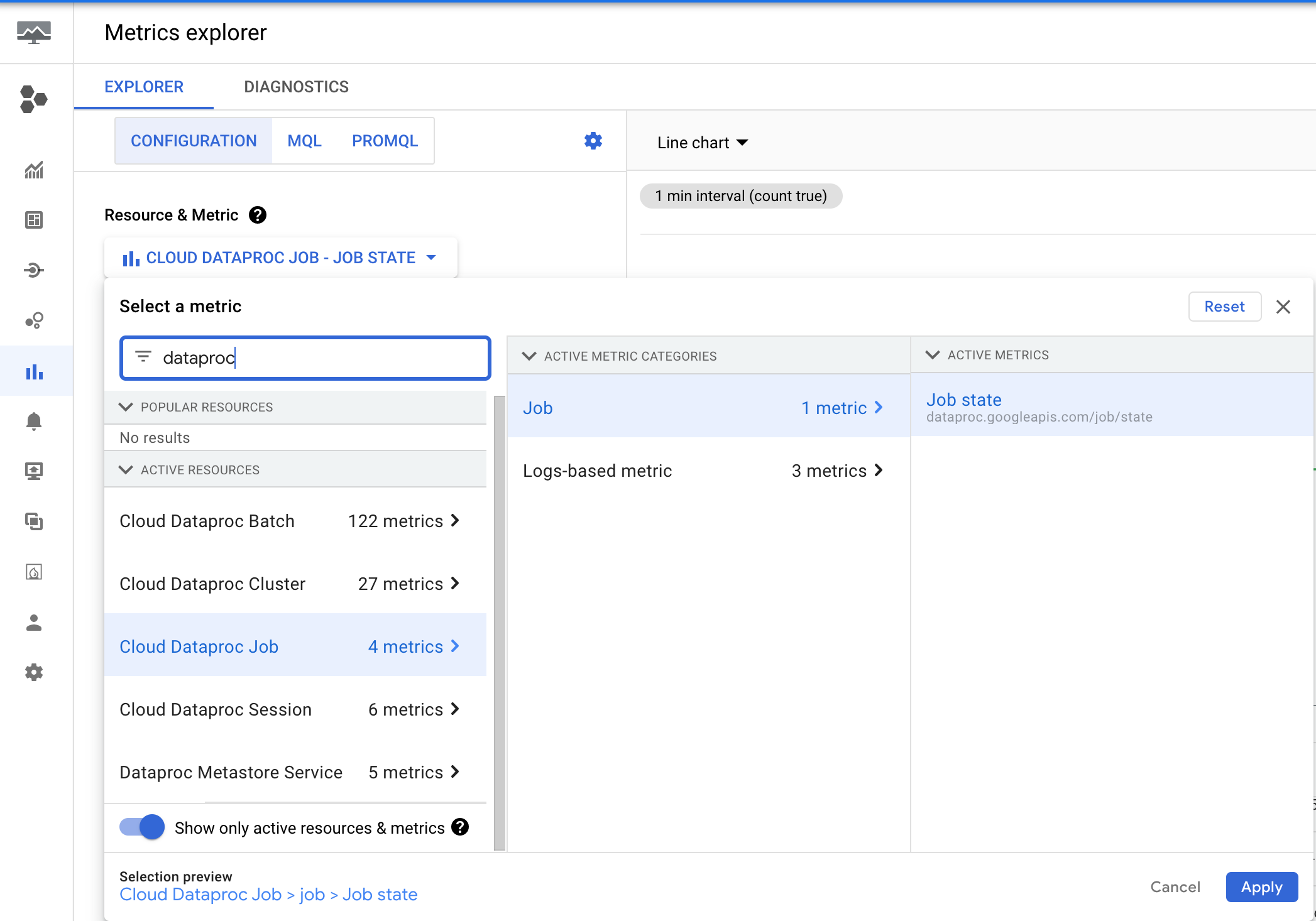
Configuración de alertas de duración del trabajo
En este ejemplo, se usa el lenguaje de consultas de Monitoring (MQL) para crear una política de alertas (consulta Crea políticas de alertas de MQL (consola)).
fetch cloud_dataproc_job
| metric 'dataproc.googleapis.com/job/state'
| filter metric.state == 'RUNNING'
| group_by [resource.job_id, metric.state], 1m
| condition val() == true()
En el siguiente ejemplo, la alerta se activa cuando un trabajo se ejecuta durante más de 30 minutos.
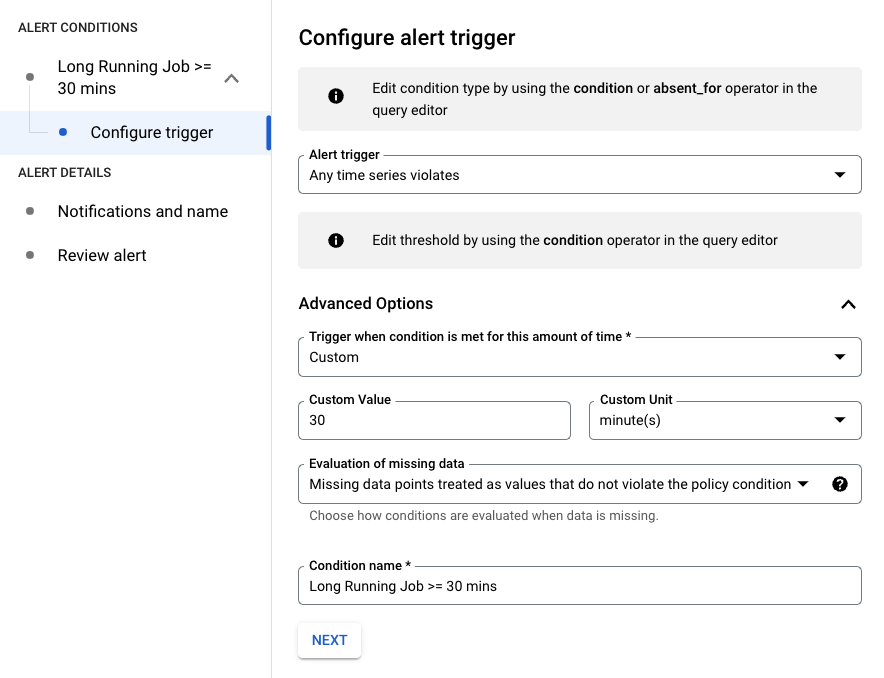
Puedes modificar la consulta filtrando por resource.job_id para aplicarla a un trabajo específico:
fetch cloud_dataproc_job
| metric 'dataproc.googleapis.com/job/state'
| filter (resource.job_id == '1234567890') && (metric.state == 'RUNNING')
| group_by [resource.job_id, metric.state], 1m
| condition val() == true()
Alerta de aplicación de YARN de larga duración
En el ejemplo anterior, se muestra una alerta que se activa cuando un trabajo de Dataproc se ejecuta durante más tiempo del especificado, pero solo se aplica a los trabajos enviados al servicio de Dataproc con la consola de Google Cloud , Google Cloud CLI o llamadas directas a la API dejobs de Dataproc. También puedes usar métricas de OSS para configurar alertas similares que supervisen el tiempo de ejecución de las aplicaciones de YARN.
Primero, veamos algunos antecedentes. YARN emite métricas de tiempo de ejecución en varios buckets.
De forma predeterminada, YARN mantiene 60, 300 y 1,440 minutos como umbrales de bucket y emite 4 métricas: running_0, running_60, running_300 y running_1440:
running_0registra la cantidad de trabajos con un tiempo de ejecución entre 0 y 60 minutos.running_60registra la cantidad de trabajos con un tiempo de ejecución de entre 60 y 300 minutos.running_300registra la cantidad de trabajos con un tiempo de ejecución entre 300 y 1,440 minutos.running_1440registra la cantidad de trabajos con un tiempo de ejecución superior a 1,440 minutos.
Por ejemplo, un trabajo que se ejecuta durante 72 minutos se registrará en running_60, pero no en running_0.
Estos umbrales predeterminados del bucket se pueden modificar pasando valores nuevos a la propiedad del clúster yarn:yarn.resourcemanager.metrics.runtime.buckets durante la creación del clúster de Dataproc. Cuando definas umbrales de buckets personalizados, también deberás definir anulaciones de métricas. Por ejemplo, para especificar umbrales de bucket de 30, 60 y 90 minutos, el comando gcloud dataproc clusters create debe incluir las siguientes marcas:
Umbrales del bucket:
‑‑properties=yarn:yarn.resourcemanager.metrics.runtime.buckets=30,60,90Anulaciones de métricas:
‑‑metric-overrides=yarn:ResourceManager:QueueMetrics:running_0, yarn:ResourceManager:QueueMetrics:running_30,yarn:ResourceManager:QueueMetrics:running_60, yarn:ResourceManager:QueueMetrics:running_90
Comando de muestra para crear un clúster
gcloud dataproc clusters create test-cluster \ --properties ^#^yarn:yarn.resourcemanager.metrics.runtime.buckets=30,60,90 \ --metric-sources=yarn \ --metric-overrides=yarn:ResourceManager:QueueMetrics:running_0,yarn:ResourceManager:QueueMetrics:running_30,yarn:ResourceManager:QueueMetrics:running_60,yarn:ResourceManager:QueueMetrics:running_90
Estas métricas se enumeran en el Explorador de métricas de la consola de Google Cloud en el recurso Instancia de VM (gce_instance).
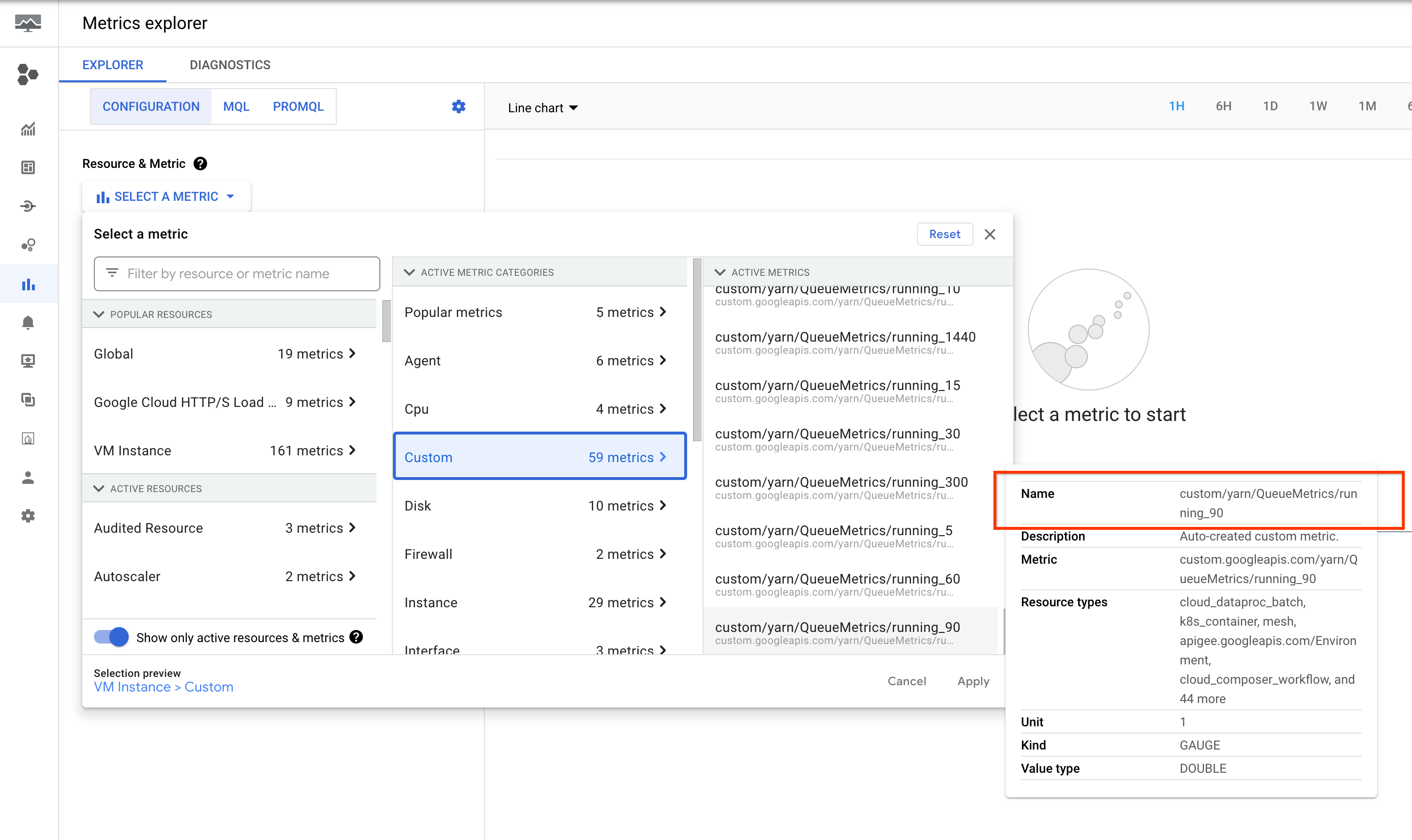
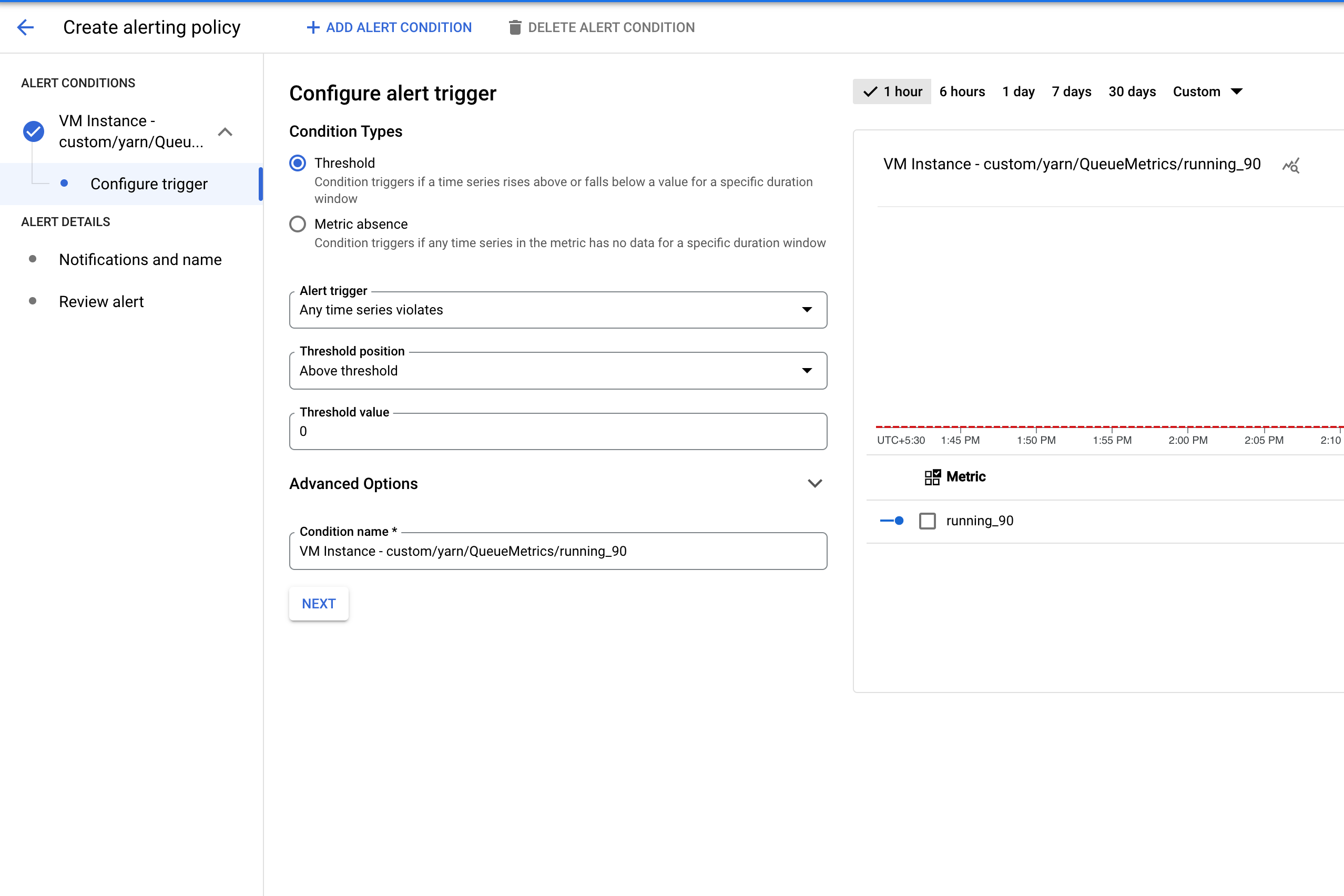
Configuración de alertas de aplicaciones de YARN
Crea un clúster con los buckets y las métricas requeridos habilitados .
Crea una política de alertas que se active cuando la cantidad de aplicaciones en un bucket de métricas de YARN supere un umbral especificado.
De manera opcional, agrega un filtro para generar alertas sobre los clústeres que coincidan con un patrón.
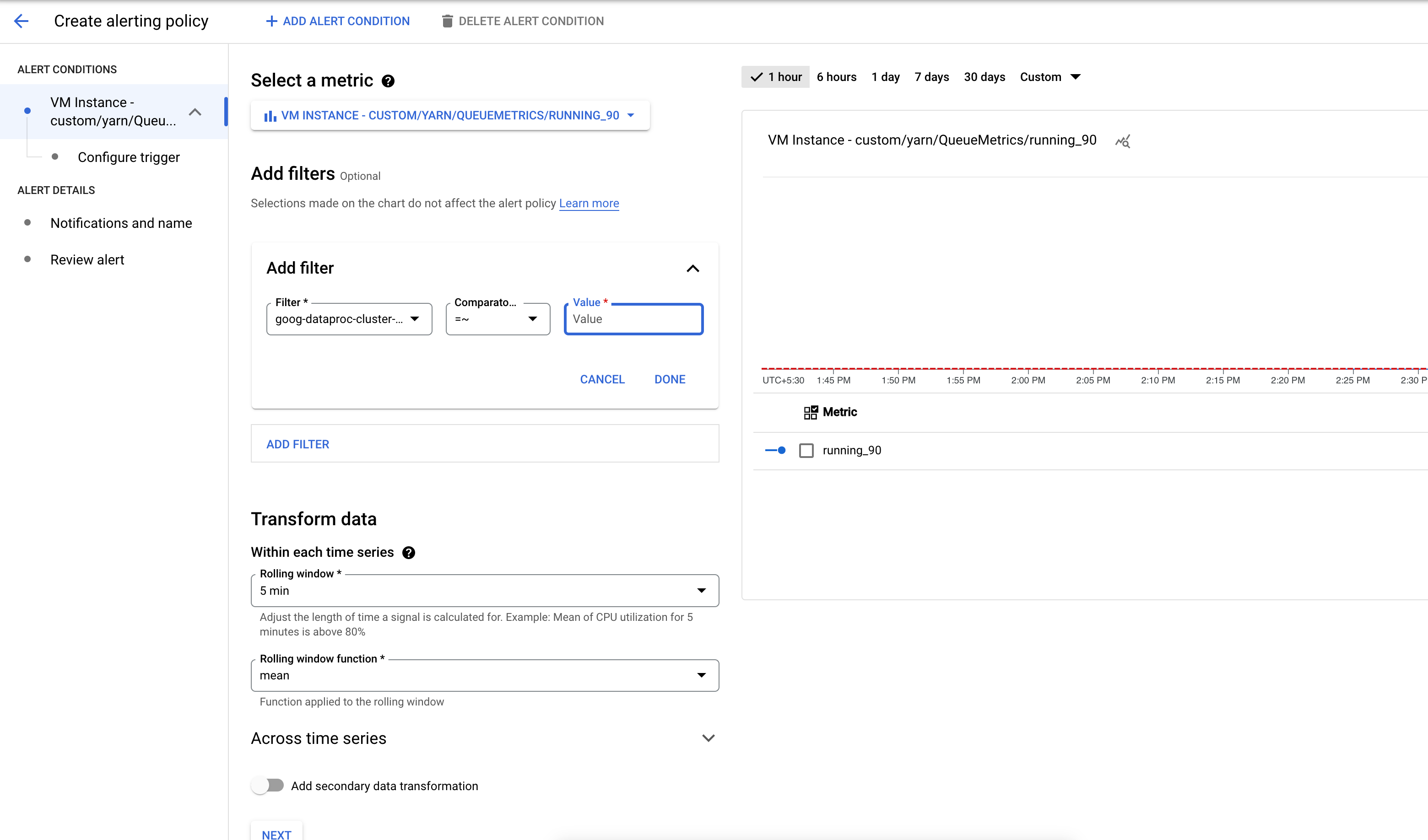
Configura el umbral para activar la alerta.
Alerta de trabajo de Dataproc con errores
También puedes usar la métrica dataproc.googleapis.com/job/state (consulta Alerta de trabajo de Dataproc de larga duración) para recibir alertas cuando falle un trabajo de Dataproc.
No se pudo configurar la alerta de trabajo
En este ejemplo, se usa el lenguaje de consultas de Monitoring (MQL) para crear una política de alertas (consulta Crea políticas de alertas de MQL (consola)).
Alerta de MQL
fetch cloud_dataproc_job
| metric 'dataproc.googleapis.com/job/state'
| filter metric.state == 'ERROR'
| group_by [resource.job_id, metric.state], 1m
| condition val() == true()
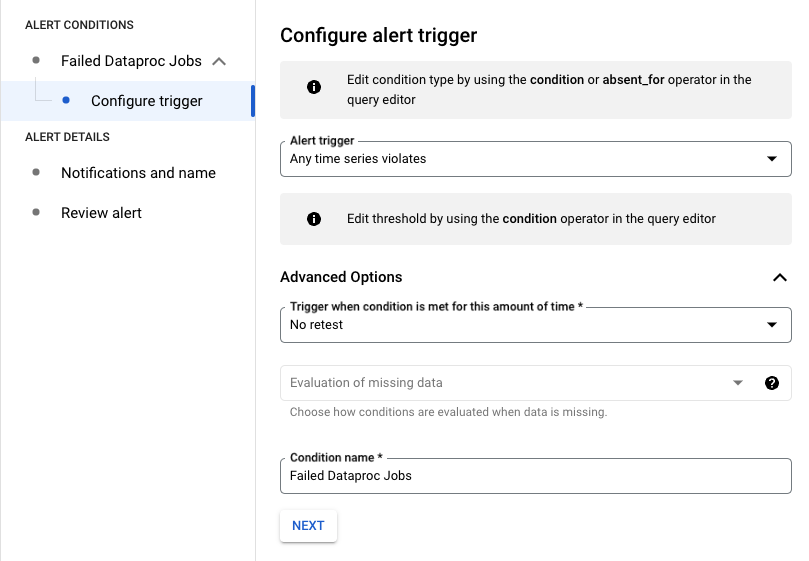
Configuración del activador de alertas
En el siguiente ejemplo, la alerta se activa cuando falla cualquier trabajo de Dataproc en tu proyecto.
Puedes modificar la consulta filtrando por resource.job_id para aplicarla a un trabajo específico:
fetch cloud_dataproc_job
| metric 'dataproc.googleapis.com/job/state'
| filter (resource.job_id == '1234567890') && (metric.state == 'ERROR')
| group_by [resource.job_id, metric.state], 1m
| condition val() == true()
Alerta de desviación de la capacidad del clúster
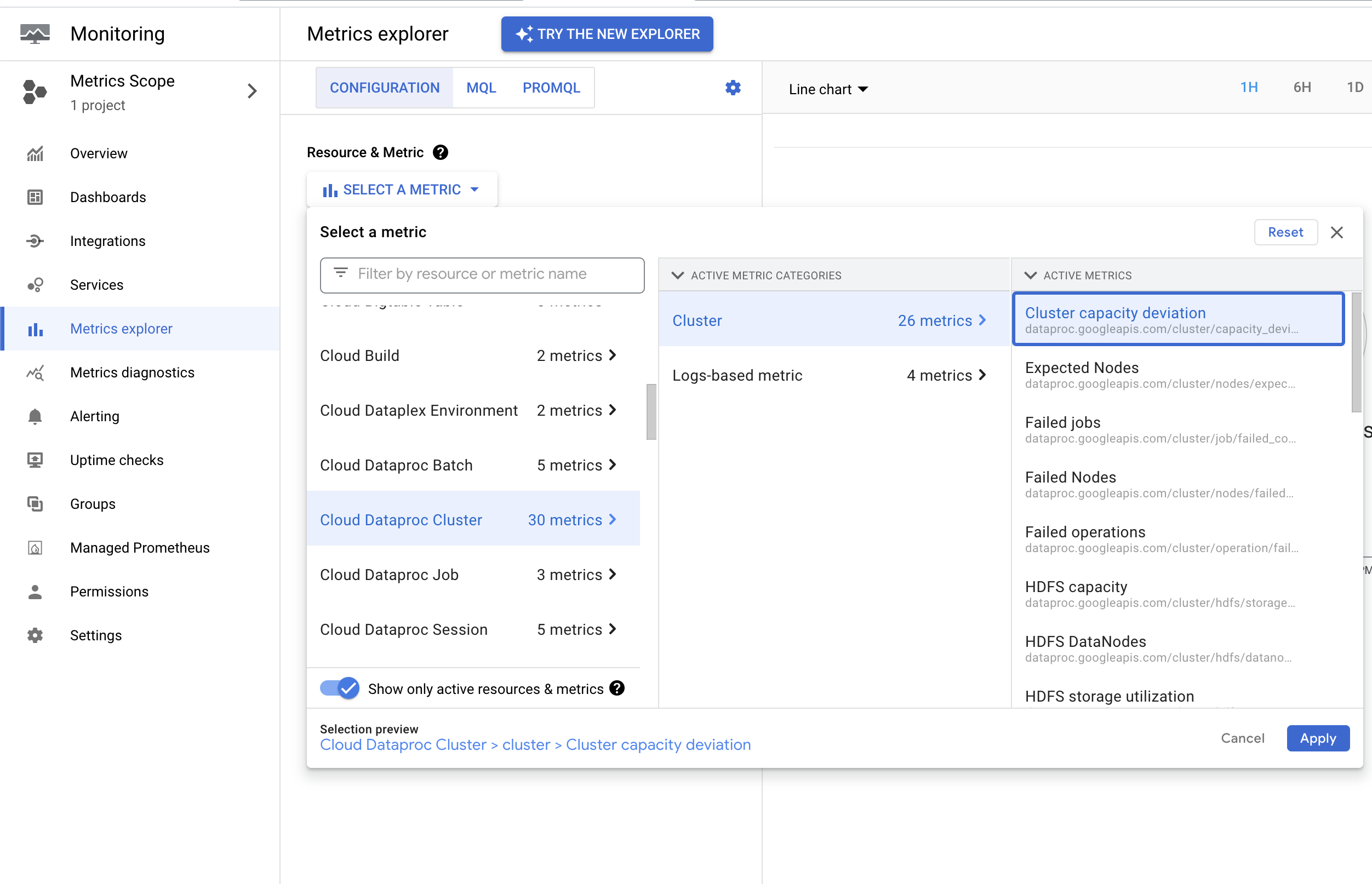
Dataproc emite la métrica dataproc.googleapis.com/cluster/capacity_deviation, que informa la diferencia entre el recuento de nodos esperado en el clúster y el recuento de nodos de YARN activos. Puedes encontrar esta métrica en el Explorador de métricas de la consolaGoogle Cloud en el recurso Clúster de Cloud Dataproc. Puedes usar esta métrica para crear una alerta que te notifique cuando la capacidad del clúster se desvíe de la capacidad esperada durante un período superior al umbral especificado.
Las siguientes operaciones pueden provocar un subregistro temporal de los nodos del clúster en la métrica capacity_deviation. Para evitar alertas de falsos positivos, establece el umbral de alerta de la métrica de modo que tenga en cuenta estas operaciones:
Creación y actualizaciones de clústeres: La métrica
capacity_deviationno se emite durante las operaciones de creación o actualización de clústeres.Acciones de inicialización del clúster: Las acciones de inicialización se realizan después de que se aprovisiona un nodo.
Actualizaciones de trabajadores secundarios: Los trabajadores secundarios se agregan de forma asíncrona, después de que se completa la operación de actualización.
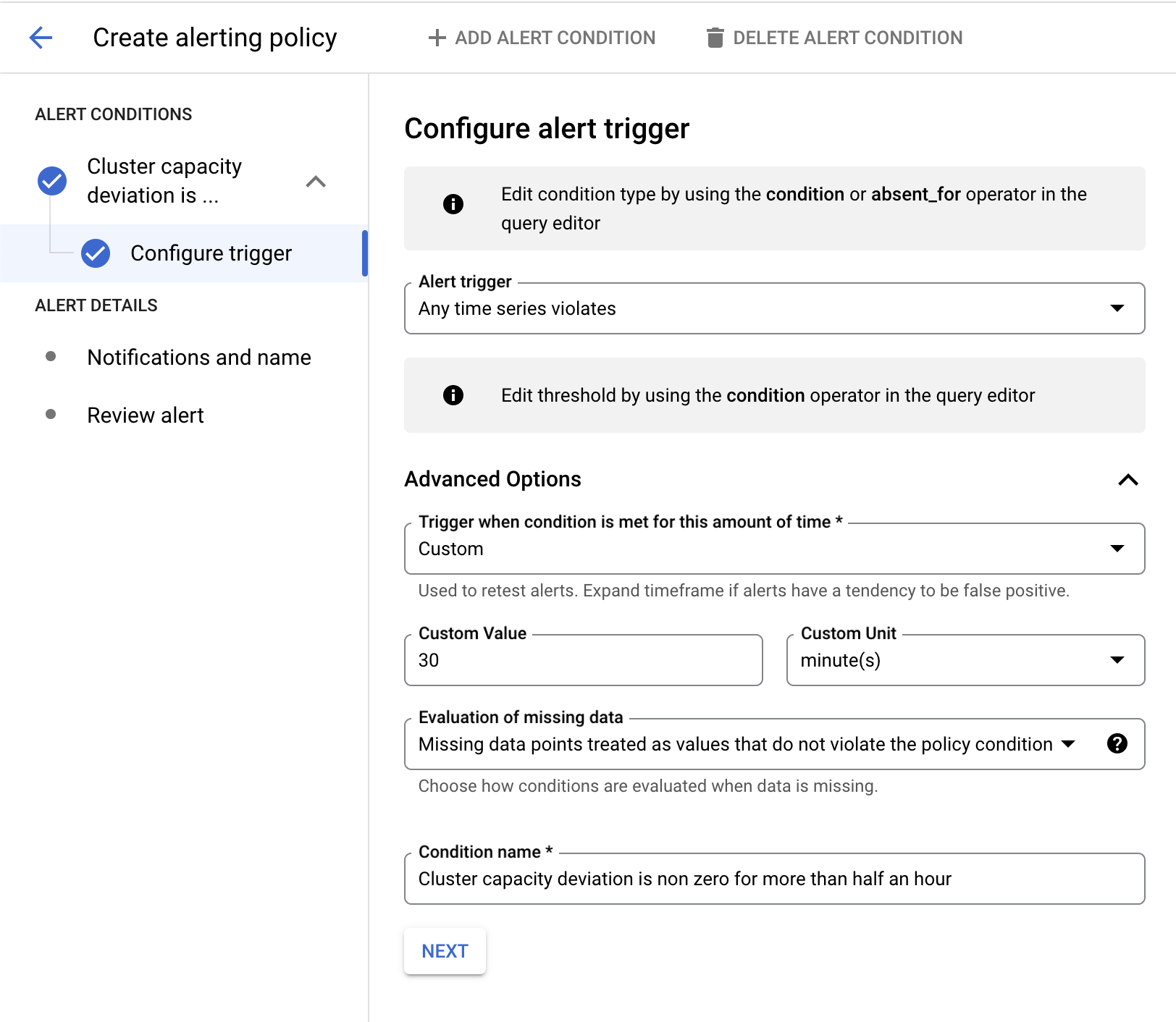
Configuración de alertas de desviación de capacidad
En este ejemplo, se usa el lenguaje de consulta de Monitoring (MQL) para crear una política de alertas.
fetch cloud_dataproc_cluster
| metric 'dataproc.googleapis.com/cluster/capacity_deviation'
| every 1m
| condition val() <> 0 '1'
En el siguiente ejemplo, la alerta se activa cuando la desviación de la capacidad del clúster es distinta de cero durante más de 30 minutos.
Ver alertas
Cuando una condición de límite de una métrica activa una alerta, Monitoring crea un incidente y un evento correspondiente. Puedes ver los incidentes desde la página de alertas de Monitoring en la consola de Google Cloud .
Si definiste un mecanismo de notificación en la política de alertas, como una notificación por correo electrónico o SMS, Monitoring envía una notificación del incidente.
¿Qué sigue?
- Consulta la Introducción a las alertas.