概要
Dataproc の永続履歴サーバー(PHS)では、アクティブまたは削除された Dataproc クラスタで実行されたジョブのジョブ履歴を表示するウェブ インターフェースを備えています。これは、Dataproc イメージ バージョン 1.5 以降で利用可能であり、単一ノードの Dataproc クラスタで実行されます。また、次のファイルとデータへのウェブ インターフェースを提供します。
MapReduce と Spark のジョブ履歴ファイル
Flink ジョブ履歴ファイル(Dataproc のオプションの Flink コンポーネントを参照して、Flink ジョブを実行する Dataproc クラスタを作成してください)
YARN Timeline Service v2 によって作成され、Bigtable インスタンスに保存されたアプリケーション タイムライン データファイル。
YARN 集計ログ
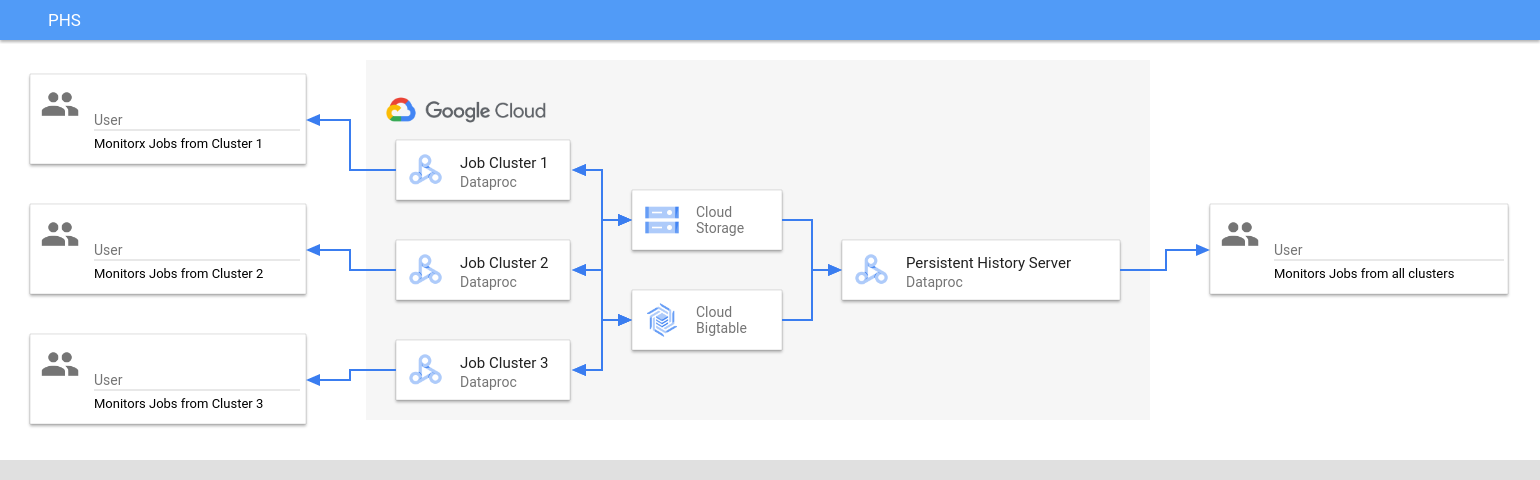
永続履歴サーバーは、Dataproc ジョブクラスタの存続期間中に Cloud Storage に書き込まれた Spark と MapReduce のジョブ履歴ファイル、Flink ジョブ履歴ファイル、YARN ログファイルにアクセスして表示します。
制限事項
PHS クラスタ イメージ バージョンと Dataproc ジョブクラスタ イメージ バージョンは一致する必要があります。たとえば、Dataproc 2.0 イメージ バージョンの PHS クラスタを使用して、PHS クラスタが配置されているプロジェクトにある Dataproc 2.0 イメージ バージョンのジョブクラスタで実行されていたジョブのジョブ履歴ファイルを表示できます。
Dataproc PHS クラスタを作成する
次の gcloud dataproc clusters create コマンドをローカル ターミナルまたは Cloud Shell 内で、次のフラグとクラスタ プロパティで実行して Dataproc 永続履歴サーバーの単一ノードクラスタを作成できます。
gcloud dataproc clusters create CLUSTER_NAME \ --project=PROJECT \ --region=REGION \ --single-node \ --enable-component-gateway \ --optional-components=COMPONENT \ --properties=PROPERTIES
- CLUSTER_NAME: PHS クラスタの名前を指定します。
- PROJECT: PHS クラスタに関連付けるプロジェクトを指定します。このプロジェクトは、ジョブを実行するクラスタに関連付けられているプロジェクトと同じである必要があります(Dataproc ジョブクラスタを作成するをご覧ください)。
- REGION: PHS クラスタが配置される Compute Engine リージョンを指定します。
--single-node: PHS クラスタは Dataproc の単一ノードクラスタです。--enable-component-gateway: このフラグは、PHS クラスタで コンポーネント ゲートウェイ ウェブ インターフェースを有効にします。- COMPONENT: このフラグを使用して、クラスタに 1 つ以上のオプション コンポーネントをインストールします。PHS クラスタで Flink HistoryServer ウェブサービスを実行して Flink ジョブ履歴ファイルを表示するには、
FLINKオプション コンポーネントを指定する必要があります。 - PROPERTIES。1 つ以上のクラスタ プロパティを指定します。
必要に応じて、--image-version フラグを追加して、PHS クラスタ イメージ バージョンを指定します。PHS イメージ バージョンは、Dataproc ジョブクラスタのイメージ バージョンと一致する必要があります。制限事項をご覧ください。
注:
- このセクションのプロパティ値の例では、ワイルドカード文字「*」を使用して、異なるジョブクラスタによって書き込まれた指定されたバケット内の複数のディレクトリを PHS が照合できるようにします(ただし、ワイルドカードの効率に関する考慮事項を参照してください)。
- 読みやすくするために、次の例では
--propertiesフラグを分けて示しています。gcloud dataproc clusters createを使用して Compute Engine クラスタ上で Dataproc を作成する際は、1 つの--propertiesフラグを使用して、カンマ区切りのプロパティのリストを指定することをおすすめします(クラスタ プロパティのフォーマット設定をご覧ください)。
プロパティ:
yarn:yarn.nodemanager.remote-app-log-dir=gs://bucket-name/*/yarn-logs: このプロパティを追加して、PHS がジョブクラスタによって書き込まれた YARN ログにアクセスする Cloud Storage のロケーションを指定します。spark:spark.history.fs.logDirectory=gs://bucket-name/*/spark-job-history: このプロパティを追加して永続 Spark ジョブ履歴を有効にします。このプロパティは、PHS がジョブクラスタによって書き込まれた Spark ジョブ履歴ログにアクセスするロケーションを指定します。Dataproc 2.0 以降のクラスタでは、PHS Spark の履歴ログを有効にするために、次のプロパティも設定する必要があります(Spark History Server の構成オプションを参照)。
spark.history.custom.executor.log.url値は、永続履歴サーバーによって設定される変数の {{PLACEHOLDERS}} を含むリテラル値です。これらの変数は、ユーザーによって設定されず、表示されるプロパティ値を渡します。--properties=spark:spark.history.custom.executor.log.url.applyIncompleteApplication=false
--properties=spark:spark.history.custom.executor.log.url={{YARN_LOG_SERVER_URL}}/{{NM_HOST}}:{{NM_PORT}}/{{CONTAINER_ID}}/{{CONTAINER_ID}}/{{USER}}/{{FILE_NAME}}mapred:mapreduce.jobhistory.read-only.dir-pattern=gs://bucket-name/*/mapreduce-job-history/done: このプロパティを追加して永続 MapReduce ジョブ履歴を有効にします。このプロパティは、PHS がジョブクラスタによって書き込まれた MapReduce ジョブ履歴ログにアクセスする Cloud Storage のロケーションを指定します。dataproc:yarn.atsv2.bigtable.instance=projects/project-id/instance_id/bigtable-instance-id: Yarn Timeline Service v2 を構成したあとで、このプロパティを追加して PHS クラスタを使用し、YARN アプリケーション タイムライン サービス V2および Tez ウェブ インターフェース(コンポーネント ゲートウェイのウェブ インターフェースを参照)上のタイムライン データを表示する。flink:historyserver.archive.fs.dir=gs://bucket-name/*/flink-job-history/completed-jobs: このプロパティを使用して、FlinkHistoryServerがカンマ区切りのディレクトリのリストをモニタリングするように構成します。
プロパティの例:
--properties=spark:spark.history.fs.logDirectory=gs://bucket-name/*/spark-job-history
--properties=mapred:mapreduce.jobhistory.read-only.dir-pattern=gs://bucket-name/*/mapreduce-job-history/done
--properties=flink:flink.historyserver.archive.fs.dir=gs://bucket-name/*/flink-job-history/completed-jobs
Dataproc ジョブクラスタを作成する
ジョブを実行してジョブ履歴ファイルを永続履歴サーバー(PHS)に書き込む Dataproc ジョブクラスタを作成するには、ローカル ターミナルまたは Cloud Shell で次のコマンドを実行します。
gcloud dataproc clusters create CLUSTER_NAME \ --project=PROJECT \ --region=REGION \ --optional-components=COMPONENT \ --enable-component-gateway \ --properties=PROPERTIES \ other args ...
- CLUSTER_NAME: ジョブクラスタの名前を指定します。
- PROJECT: ジョブクラスタに関連付けられているプロジェクトを指定します。
- REGION: ジョブクラスタが配置される Compute Engine リージョンを指定します。
--enable-component-gateway: このフラグは、ジョブクラスタで コンポーネント ゲートウェイ ウェブ インターフェースを有効にします。- COMPONENT: このフラグを使用して、クラスタに 1 つ以上のオプション コンポーネントをインストールします。クラスタで Flink ジョブを実行するには、
FLINKオプション コンポーネントを指定します。 PROPERTIES: 次の 1 つ以上のクラスタ プロパティを追加して、PHS 関連のデフォルト以外の Cloud Storage ロケーションと他のジョブクラスタ プロパティを設定します。
注:
- このセクションのプロパティ値の例では、ワイルドカード文字「*」を使用して、異なるジョブクラスタによって書き込まれた指定されたバケット内の複数のディレクトリを PHS が照合できるようにします(ただし、ワイルドカードの効率に関する考慮事項を参照してください)。
- 読みやすくするために、次の例では
--propertiesフラグを分けて示しています。gcloud dataproc clusters createを使用して Compute Engine クラスタ上で Dataproc を作成する際は、1 つの--propertiesフラグを使用して、カンマ区切りのプロパティのリストを指定することをおすすめします(クラスタ プロパティのフォーマット設定をご覧ください)。
プロパティ:
yarn:yarn.nodemanager.remote-app-log-dir: デフォルトでは、集約された YARN ログは Dataproc ジョブクラスタで有効になり、クラスタの一時バケットに書き込まれます。このプロパティを追加して、クラスタが永続履歴サーバーによるアクセスのために集約ログを書き込む異なる Cloud Storage の場所を指定します。--properties=yarn:yarn.nodemanager.remote-app-log-dir=gs://bucket-name/directory-name/yarn-logs
spark:spark.history.fs.logDirectoryとspark:spark.eventLog.dir: デフォルトでは、Spark のジョブ履歴ファイルが/spark-job-historyディレクトリのクラスタtemp bucketに保存されます。これらのプロパティを追加して、これらのファイルの異なる Cloud Storage の場所を指定できます。両方のプロパティを使用する場合は、同じバケット内のディレクトリを提示する必要があります。--properties=spark:spark.history.fs.logDirectory=gs://bucket-name/directory-name/spark-job-history
--properties=spark:spark.eventLog.dir=gs://bucket-name/directory-name/spark-job-history
mapred:mapreduce.jobhistory.done-dirとmapred:mapreduce.jobhistory.intermediate-done-dir: デフォルトでは、MapReduce のジョブ履歴ファイルが/mapreduce-job-history/doneと/mapreduce-job-history/intermediate-doneディレクトリのクラスタtemp bucketに保存されます。中間mapreduce.jobhistory.intermediate-done-dirロケーションは一時ストレージです。MapReduce ジョブが完了すると、中間ファイルはmapreduce.jobhistory.done-dirのロケーションに移動します。これらのプロパティを追加して、これらのファイルの異なる Cloud Storage の場所を指定できます。両方のプロパティを使用する場合は、同じバケット内のディレクトリを提示する必要があります。--properties=mapred:mapreduce.jobhistory.done-dir=gs://bucket-name/directory-name/mapreduce-job-history/done
--properties=mapred:mapreduce.jobhistory.intermediate-done-dir=gs://bucket-name/directory-name/mapreduce-job-history/intermediate-done
spark:spark.history.fs.gs.outputstream.type: このプロパティは、Cloud Storage コネクタ バージョン2.0.x(2.0と2.1のイメージ バージョン クラスタのデフォルトのコネクタ バージョン)を使用する2.0と2.1のイメージ バージョン クラスタに適用されます。Spark ジョブが Cloud Storage にデータを送信する方法を制御します。デフォルト設定はBASICです。この設定では、ジョブの完了後にデータが Cloud Storage に送信されます。FLUSHABLE_COMPOSITEに設定すると、spark:spark.history.fs.gs.outputstream.sync.min.interval.msで設定された間隔で、ジョブの実行中にデータが Cloud Storage にコピーされます。--properties=spark:spark.history.fs.gs.outputstream.type=FLUSHABLE_COMPOSITE
spark:spark.history.fs.gs.outputstream.sync.min.interval.ms: このプロパティは、Cloud Storage コネクタ バージョン2.0.x(2.0と2.1のイメージ バージョン クラスタのデフォルトのコネクタ バージョン)を使用する2.0と2.1のイメージ バージョン クラスタに適用されます。spark:spark.history.fs.gs.outputstream.typeがFLUSHABLE_COMPOSITEに設定されている場合に、データが Cloud Storage に転送される頻度(ミリ秒単位)を制御します。デフォルトの時間間隔は5000msです。ミリ秒単位の時間間隔値は、ms接尾辞の有無にかかわらず指定できます。--properties=spark:spark.history.fs.gs.outputstream.sync.min.interval.ms=INTERVALms
spark:spark.history.fs.gs.outputstream.sync.min.interval: このプロパティは、Cloud Storage コネクタ バージョン3.0.x(2.2イメージ バージョン クラスタのデフォルトのコネクタ バージョン)を使用する2.2以降のイメージ バージョン クラスタに適用されます。以前のspark:spark.history.fs.gs.outputstream.sync.min.interval.msプロパティに代わるもので、ms、s、mなどの時間接尾辞付きの値をサポートしています。spark:spark.history.fs.gs.outputstream.typeがFLUSHABLE_COMPOSITEに設定されている場合、Cloud Storage にデータが転送される頻度を制御します。--properties=spark:spark.history.fs.gs.outputstream.sync.min.interval=INTERVAL
dataproc:yarn.atsv2.bigtable.instance: Yarn Timeline Service v2 を構成した後、PHS クラスタ YARN アプリケーション タイムライン サービス V2 と Tez ウェブ インターフェースを表示するために、このプロパティを追加して、指定した Bigtable インスタンスに YARN タイムライン データを書き込みます。注: Bigtable インスタンスが存在しない場合、クラスタの作成は失敗します。--properties=dataproc:yarn.atsv2.bigtable.instance=projects/project-id/instance_id/bigtable-instance-id
flink:jobhistory.archive.fs.dir: Flink JobManager は、アーカイブされたジョブ情報をファイル システム ディレクトリにアップロードして、完了した Flink ジョブをアーカイブします。このプロパティを使用して、flink-conf.yamlにアーカイブ ディレクトリを設定します。--properties=flink:jobmanager.archive.fs.dir=gs://bucket-name/job-cluster-1/flink-job-history/completed-jobs
Spark バッチ ワークロードで PHS を使用する
Spark バッチ ワークロード用に Dataproc サーバーレスを用いて永続履歴サーバーを使用するには:
Spark バッチ ワークロードを送信するときに、PHS クラスタを選択または指定します。
Google Kubernetes Engine 上で Dataproc を用いて PHS を使用する
GKE 上で Dataproc を用いて永続履歴サーバーを使用するには:
GKE 仮想クラスタで Dataproc を作成するときに、PHS クラスタを選択または指定します。
コンポーネント ゲートウェイのウェブ インターフェース
Google Cloud コンソールで、Dataproc の [クラスタ] ページで、[PHS クラスタ名] をクリックし、[クラスタの詳細] ページを開きます。[ウェブ インターフェース] タブで、コンポーネント ゲートウェイ リンクを選択し、PHS クラスタで実行されているウェブ インターフェースを開きます。

Spark History Server のウェブ インターフェース
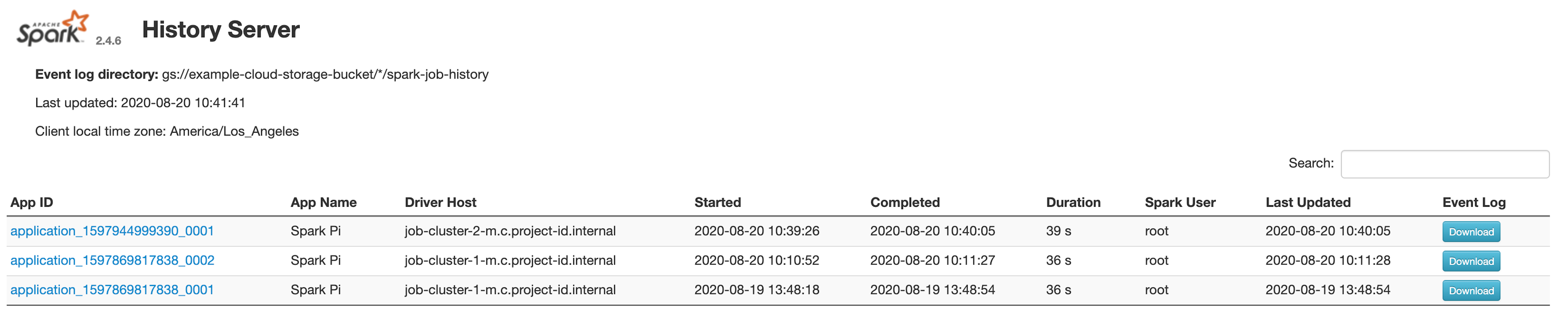
次のスクリーンショットは、ジョブクラスタの spark.history.fs.logDirectory と spark:spark.eventLog.dir を設定した後にジョブクラスタ-1 とジョブクラスタ-2 で実行される Spark ジョブへのリンクを表示する Spark History Server のウェブ インターフェースと PHS クラスタの spark.history.fs.logDirectory のロケーションを示しています。
| job-cluster-1 | gs://example-cloud-storage-bucket/job-cluster-1/spark-job-history |
| job-cluster-2 | gs://example-cloud-storage-bucket/job-cluster-2/spark-job-history |
| phs-cluster | gs://example-cloud-storage-bucket/*/spark-job-history |
アプリ名検索
Spark History Server のウェブ インターフェースでは、検索ボックスにアプリ名を入力して、アプリ名でジョブを一覧表示できます。アプリ名は次のいずれかの方法で設定できます(優先度順)。
- Spark コンテキストの作成時に、アプリケーション コード内に設定する
- ジョブの送信時に spark.app.name プロパティによって設定する
- Dataproc によってジョブ(
projects/project-id/regions/region/jobs/job-id)の完全な REST リソース名に設定する
ユーザーは、[検索] ボックスにアプリまたはリソース名の用語を入力して、ジョブを見つけて一覧表示できます。

イベントログ
Spark History Server のウェブ インターフェースには、[Event Log] ボタンが用意されており、クリックすると Spark イベントログをダウンロードできます。これらのログは、Spark アプリケーションのライフサイクルの調査に有用です。
Spark ジョブ
Spark アプリケーションは複数のジョブに分割され、それらはさらに複数のステージに分割されています。各ステージには複数のタスクがあり、それらはエグゼキューター ノード(ワーカー)で実行されます。
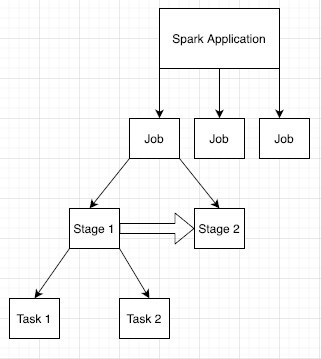
ウェブ インターフェースで Spark アプリ ID をクリックして [Spark Jobs] ページを開きます。このページには、アプリケーション内のジョブのイベント タイムラインと概要が表示されます。

ジョブをクリックして、有向非巡回グラフ(DAG)とジョブステージのサマリーがあるジョブの詳細ページを開きます。

ステージをクリックするか、[Stages] タブを使用して、ステージを選択し、[Stage Details] ページを開きます。

ステージの詳細には、DAG の可視化、イベント タイムライン、ステージ内のタスクの指標が含まれます。このページを使用すると、タスクの抑制、スケジューラの遅延、メモリ不足エラーに関連する問題のトラブルシューティングを行うことができます。DAG ビジュアライザはステージの派生元のコード行を示すため、問題を追跡して原因となっているコードを特定する際に活用できます。
Spark アプリケーションのドライバノードとエグゼキューター ノードに関する情報については、エグゼキュータのタブをクリックします。

このページの情報の重要部分には、各エグゼキュータで実行されたコア数とタスク数が含まれます。
Tez ウェブ インターフェース
Tez は、Dataproc の Hive と Pig のデフォルトの実行エンジンです。Dataproc ジョブクラスタで Hive ジョブを送信すると、Tez アプリケーションが起動します。
PHS と Dataproc のジョブクラスタの作成時に Yarn Timeline Service v2 を構成して dataproc:yarn.atsv2.bigtable.instance プロパティを設定した場合、PHS サーバーで実行されている Tez ウェブ インターフェースで検索および表示するために、YARN は生成された Hive と Pig のジョブのタイムライン データを指定された Bigtable インスタンスに書き込みます。

YARN Application Timeline V2 ウェブ インターフェース
PHS と Dataproc のジョブクラスタの作成時に Yarn Timeline Service v2 を構成して dataproc:yarn.atsv2.bigtable.instance プロパティを設定した場合、YARN は、PHS サーバーで実行されている YARN アプリケーション タイムライン サービス ウェブ インターフェースから取得と表示を行うために、生成されたジョブのタイムライン データを Bigtable インスタンスに書き込みます。Dataproc ジョブは、ウェブ インターフェースの [フロー アクティビティ] タブに表示されます。
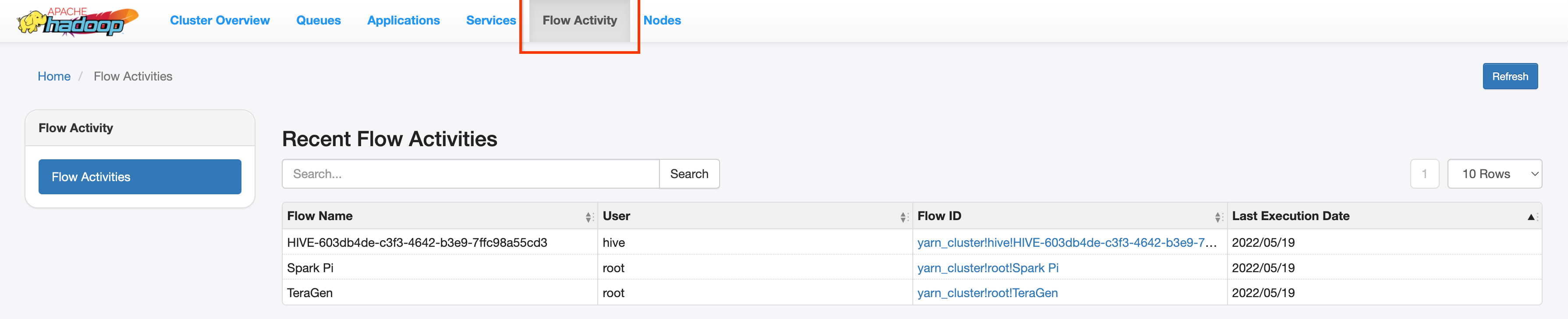
Yarn Timeline Service v2 を構成する
Yarn Timeline Service v2 を構成するには、Bigtable インスタンスを設定し、必要に応じて、次のとおりに、サービス アカウントのロールを確認します。
必要に応じて、サービス アカウントのロールを確認します。Dataproc クラスタ VM で使用されるデフォルトの VM サービス アカウントには、YARN Timeline Service 用の Bigtable インスタンスの作成と構成に必要な権限があります。カスタム VM サービス アカウントを使用してジョブまたは PHS クラスタを作成する場合、アカウントには Bigtable の
AdministratorまたはBigtable Userのロールのいずれかが必要です。
必要なテーブル スキーマ
YARN Timeline Service v2 用の Dataproc PHS サポートには、Bigtable インスタンスで作成された特定のスキーマが必要です。dataproc:yarn.atsv2.bigtable.instance プロパティが Bigtable インスタンスを指すようにジョブクラスタまたは PHS クラスタが作成されると、Dataproc によって必要なスキーマが作成されます。
必要な Bigtable インスタンス スキーマは次のとおりです。
| テーブル | 列ファミリー |
|---|---|
| prod.timelineservice.application | c,i,m |
| prod.timelineservice.app_flow | m |
| prod.timelineservice.entity | c,i,m |
| prod.timelineservice.flowactivity | i |
| prod.timelineservice.flowrun | i |
| prod.timelineservice.subapplication | c,i,m |
Bigtable ガベージ コレクション
ATSv2 テーブル用に経時 Bigtable ガベージ コレクションを構成できます。
cbt をインストールします(
.cbrtc fileの作成を含む)。ATSv2 経時ガベージ コレクション ポリシーを作成します。
export NUMBER_OF_DAYS = number \
cbt setgcpolicy prod.timelineservice.application c maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.application i maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.application m maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.app_flow m maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.entity c maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.entity i maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.entity m maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.flowactivity i maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.flowrun i maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.subapplication c maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.subapplication i maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.subapplication m maxage=${NUMBER_OF_DAYS}
注:
NUMBER_OF_DAYS: 最大日数は 30d です。