O que é escalonamento automático
É difícil estimar o número "certo" de workers de cluster (nós) para uma carga de trabalho, e um único tamanho de cluster para um pipeline inteiro geralmente não é o ideal. O escalonamento de cluster iniciado pelo usuário aborda parcialmente esse desafio, mas requer o monitoramento da utilização de cluster e da intervenção manual.
A API ScalingPolicies do Dataproc
fornece um mecanismo para automatização do gerenciamento de recursos do cluster. Além disso, permite
o escalonamento automático da VM de worker do cluster. Um Autoscaling Policy é uma configuração reutilizável, que
descreve como os workers do cluster que usam a política de escalonamento automático precisam ser escalonados. Ele define
limites de escala, frequência e agressividade para fornecer controle
refinado sobre os recursos do cluster durante a vida útil do cluster.
Quando usar o escalonamento automático
Use o escalonamento automático:
em clusters que armazenam dados em serviços externos, como o Cloud Storage ou o BigQuery
em clusters que processam muitos jobs
para escalonar clusters de job único
com Modo de flexibilidade aprimorado para jobs em lote do Spark
O escalonamento automático não é recomendado com/para:
HDFS: o escalonamento automático não se destina ao escalonamento de HDFS no cluster porque:
- A utilização de HDFS não é um sinal para o escalonamento automático.
- Os dados do HDFS são hospedados apenas nos workers principais. O número de workers primários precisa ser suficiente para hospedar todos os dados do HDFS.
- A desativação dos DataNodes do HDFS pode atrasar a remoção de workers. Os DataNodes copiam blocos HDFS para outros DataNodes antes que um worker seja removido. Dependendo do tamanho dos dados e do fator de replicação, esse processo pode levar horas.
Rótulos de nó do YARN:o escalonamento automático não é compatível com rótulos de nó do YARN, nem com a propriedade
dataproc:am.primary_onlydevido a YARN-9088. O YARN relata incorretamente as métricas do cluster quando os rótulos dos nós são usados.Structured Streaming do Spark:o escalonamento automático não é compatível com o Structured Streaming do Spark. Consulte Escalonamento automático e Structured Streaming do Spark.
Clusters inativos: o escalonamento automático não é recomendado para escalonar um cluster até seu tamanho mínimo, quando ele estiver ocioso. O tempo necessário para a criação ou o redimensionamento de um cluster é o mesmo, por isso, pense em excluir clusters inativos e criar novos. As seguintes ferramentas são compatíveis com esse modelo efêmero:
Use os fluxos de trabalho do Dataproc para programar um conjunto de jobs em um cluster dedicado e exclua o cluster quando os jobs forem concluídos. Para uma orquestração mais avançada, use o Cloud Composer, baseado no Apache Airflow.
Para clusters que processam consultas ad hoc ou cargas de trabalho agendadas externamente, use a Exclusão agendada de cluster para excluir o cluster após um determinado período de ociosidade ou em um horário específico.
Cargas de trabalho de tamanhos diferentes:quando jobs pequenos e grandes são executados em um cluster, o escalonamento reduzido de desativação normal aguarda a conclusão dos jobs grandes. Como resultado, um job de longa duração vai atrasar o escalonamento automático de recursos para jobs menores em execução no cluster até que o job de longa duração seja concluído. Para evitar esse resultado, agrupe jobs menores de tamanho semelhante em um cluster e isole cada job de longa duração em um cluster separado.
Ativar o escalonamento automático
Para ativar o escalonamento automático em um cluster:
Siga uma destas instruções:
Criar uma política de escalonamento automático
CLI da gcloud
Você pode usar o comando
gcloud dataproc autoscaling-policies import
para criar uma política de escalonamento automático. Ele lê um arquivo
YAML
local que define uma política de escalonamento automático. O formato e o conteúdo do arquivo
precisam corresponder aos objetos de config e aos campos definidos pela
API REST
autoscalingPolicies.
O exemplo YAML a seguir define uma política para clusters padrão do Dataproc, com todos os campos obrigatórios. Ele também fornece os valores de
minInstances e maxInstances para os
workers principais, o valor de maxInstances para os workers secundários
(preemptivos) e especifica um cooldownPeriod de quatro minutos
(o padrão é dois minutos). O workerConfig configura os workers principais. Neste exemplo, minInstances e
maxInstances estão definidos com o mesmo valor
para evitar o escalonamento dos workers principais.
workerConfig:
minInstances: 10
maxInstances: 10
secondaryWorkerConfig:
maxInstances: 50
basicAlgorithm:
cooldownPeriod: 4m
yarnConfig:
scaleUpFactor: 0.05
scaleDownFactor: 1.0
gracefulDecommissionTimeout: 1h
O exemplo de YAML a seguir define uma política para clusters padrão do Dataproc, com todos os campos obrigatórios e opcionais da política de escalonamento automático.
clusterType: STANDARD
workerConfig:
minInstances: 10
maxInstances: 10
weight: 1
secondaryWorkerConfig:
minInstances: 0
maxInstances: 100
weight: 1
basicAlgorithm:
cooldownPeriod: 2m
yarnConfig:
scaleUpFactor: 0.05
scaleDownFactor: 1.0
scaleUpMinWorkerFraction: 0.0
scaleDownMinWorkerFraction: 0.0
gracefulDecommissionTimeout: 1h
O exemplo YAML a seguir define uma política para clusters de escalonamento para zero.
Para clusters de escala zero, não incluaworkerConfig.
clusterType: ZERO_SCALE
secondaryWorkerConfig:
minInstances: 0
maxInstances: 100
weight: 1
basicAlgorithm:
cooldownPeriod: 2m
yarnConfig:
scaleUpFactor: 0.05
scaleDownFactor: 1.0
scaleUpMinWorkerFraction: 0.0
scaleDownMinWorkerFraction: 0.0
gracefulDecommissionTimeout: 1h
Execute o comando gcloud a seguir em um terminal local ou no
Cloud Shell para criar a
política de escalonamento automático. Forneça um nome para a política. Esse nome se tornará
a política id, que poderá ser usada em comandos gcloud
posteriores para fazer referência à política. Use a flag --source para especificar
o caminho local e o nome do arquivo YAML da política de escalonamento automático a ser importado.
gcloud dataproc autoscaling-policies import policy-name \ --source=filepath/filename.yaml \ --region=region
API REST
Crie uma política de escalonamento automático definindo uma AutoscalingPolicy como parte de uma solicitação autoscalingPolicies.create.
Console
Para criar uma política de escalonamento automático, selecione "CRIAR POLÍTICA" na página Políticas de escalonamento automático do Dataproc usando o Google Cloud console. Na página Criar política, selecione um painel de recomendações de política para preencher os campos de política de escalonamento automático de um tipo de job ou objetivo de escalonamento específico.
Criar um cluster de escalonamento automático
Depois de criar uma política de escalonamento automático, crie um cluster que use a política de escalonamento automático. O cluster precisa estar na mesma região da política de escalonamento automático.
CLI da gcloud
Execute o seguinte comando gcloud em um terminal local ou no
Cloud Shell para criar um
cluster de escalonamento automático. Forneça um nome para o cluster e use
a sinalização --autoscaling-policy para especificar o policy ID
(o nome da política especificada quando você
criou a política)
ou a política
resource URI (resource name)
(consulte os
campos AutoscalingPolicy id e name).
gcloud dataproc clusters create cluster-name \ --autoscaling-policy=policy id or resource URI \ --region=region
API REST
Crie um cluster de escalonamento automático incluindo um AutoscalingConfig como parte de uma solicitação clusters.create.
Console
É possível selecionar uma política de escalonamento automático existente para aplicar a um novo cluster. Basta acessar a seção "Política de escalonamento automático" no painel "Configurar cluster" na página Criar um cluster do Dataproc no console Google Cloud .
Ativar o escalonamento automático em um cluster atual
Depois de criar uma política de escalonamento automático, é possível ativar a política em um cluster atual na mesma região.
CLI da gcloud
Execute o seguinte comando gcloud em um terminal local ou no
Cloud Shell para ativar uma
política de escalonamento automático em um cluster atual. Forneça o nome do cluster e use a sinalização
--autoscaling-policy para especificar o policy ID
(o nome da política especificada ao
criar a política).
ou a política
resource URI (resource name)
(consulte os campos
AutoscalingPolicy id e name).
gcloud dataproc clusters update cluster-name \ --autoscaling-policy=policy id or resource URI \ --region=region
API REST
Para ativar uma política de escalonamento automático em um cluster atual, defina o
AutoscalingConfig.policyUri
da política no updateMask de uma
solicitação
clusters.patch.
Console
Não é possível ativar uma política de escalonamento automático em um cluster atual no console Google Cloud .
Uso da política de vários clusters
Uma política de escalonamento automático define o comportamento de escalonamento que pode ser aplicado a vários clusters. Uma política de escalonamento automático é melhor aplicada em vários clusters quando eles compartilham cargas de trabalho semelhantes ou executam jobs com padrões de uso de recursos semelhantes.
É possível atualizar uma política que está sendo usada por vários clusters. As atualizações afetam imediatamente o comportamento de escalonamento automático de todos os clusters que usam a política. Consulte autoscalingPolicies.update. Se você não quiser que uma atualização de política seja aplicada a um cluster que esteja usando a política, desative o escalonamento automático no cluster antes de atualizá-la.
CLI da gcloud
Execute o comando gcloud a seguir em um terminal local ou no
Cloud Shell para
desativar o escalonamento automático em um cluster.
gcloud dataproc clusters update cluster-name --disable-autoscaling \ --region=region
API REST
Para desativar o escalonamento automático em um cluster, defina
AutoscalingConfig.policyUri
para a string vazia e defina
update_mask=config.autoscaling_config.policy_uri em uma
solicitação
clusters.patch.
Console
Não é possível desativar o escalonamento automático em um cluster no console Google Cloud .
- Uma política em uso por um ou mais clusters não pode ser excluída. Consulte autoscalingPolicies.delete.
Como o escalonamento automático funciona
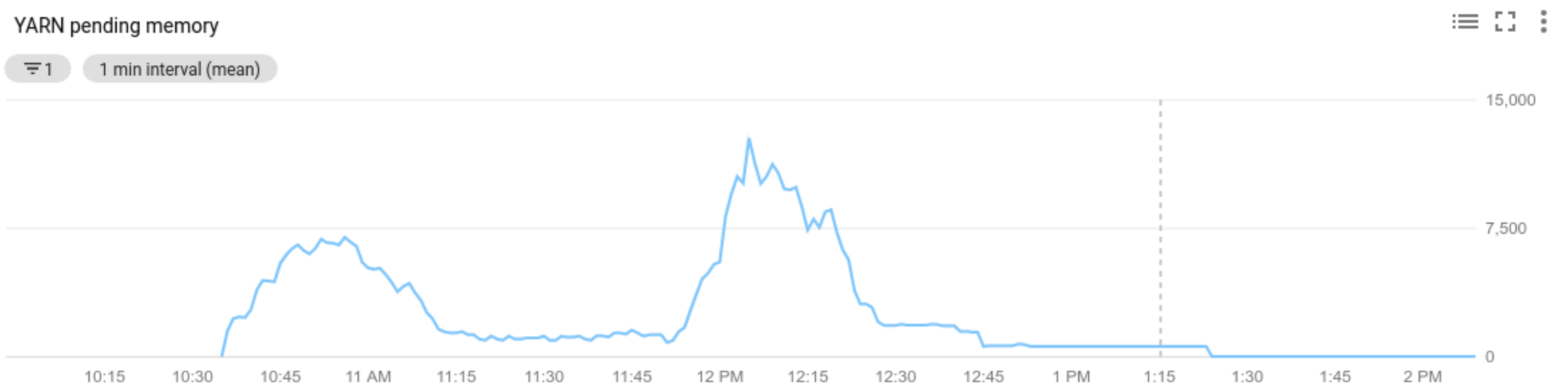
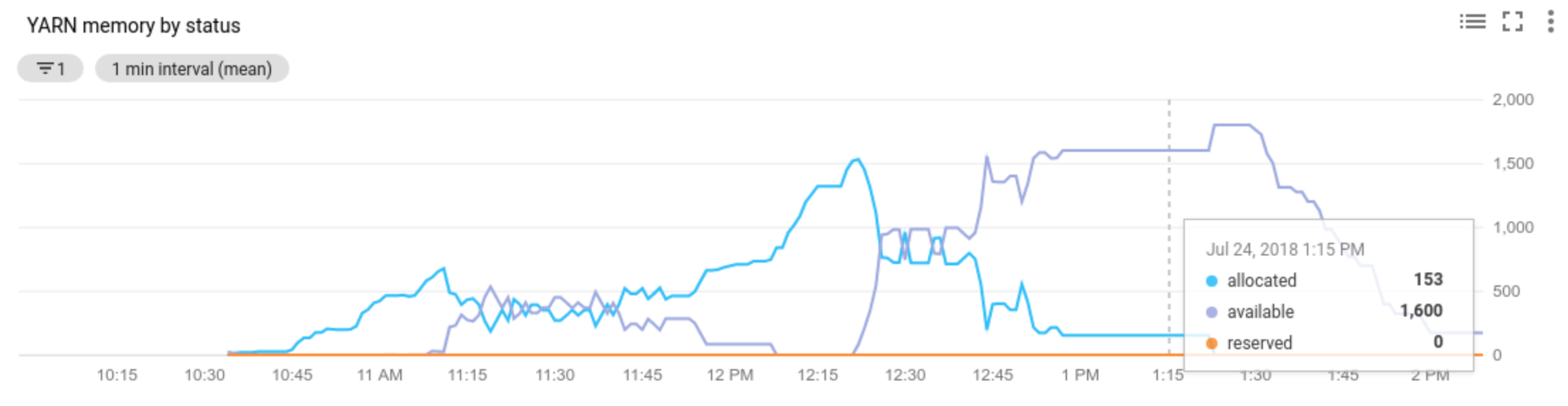
As métricas da YARN do Hadoop do cluster são verificadas pelo escalonamento automático, no decorrer de cada período de "resfriamento", para definir se o cluster precisa ser escalonado e qual a magnitude da atualização.
O valor da métrica de recurso pendente do YARN (memória pendente ou núcleos pendentes) determina se é necessário escalonar verticalmente ou reduzir a escala. Um valor maior que
0indica que os jobs do YARN estão aguardando recursos e que pode ser necessário fazer escalonamento vertical. Um valor0indica que o YARN tem recursos suficientes para que uma redução ou outras mudanças não sejam necessárias.Se o recurso pendente for > 0:
$estimated\_worker\_count =$
\[ \Biggl \lceil AVERAGE\ during\ cooldown\ period\Big(\frac{Pending + Available + Allocated + Reserved}{Resource\ per\ worker}\Big)\Biggr \rceil \]
Se o recurso pendente for 0:
$estimated\_worker\_count =$
\[ \Biggl \lceil AVERAGE\ during\ cooldown\ period\Big(\frac{Allocated + Reserved}{Resource\ per\ worker}\Big)\Biggr \rceil \]
Por padrão, o escalonador automático monitora o recurso de memória do YARN. Se você ativar o escalonamento automático baseado em núcleos, a memória e os núcleos do YARN serão monitorados:
estimated_worker_countserá avaliado separadamente para memória e núcleos, e a contagem de workers resultante será selecionada.$estimated\_worker\_count =$
\[ max(estimated\_worker\_count\_by\_memory,\ estimated\_worker\_count\_by\_cores) \]
\[ estimated\ \Delta worker = estimated\_worker\_count - current\_worker\_count \]
Dada a mudança estimada necessária para o número de workers, o escalonamento automático usa um
scaleUpFactorouscaleDownFactorpara calcular a mudança real no número de workers:if estimated Δworkers > 0: actual Δworkers = ROUND_UP(estimated Δworkers * scaleUpFactor) # examples: # ROUND_UP(estimated Δworkers=5 * scaleUpFactor=0.5) = 3 # ROUND_UP(estimated Δworkers=0.8 * scaleUpFactor=0.5) = 1 else: actual Δworkers = ROUND_DOWN(estimated Δworkers * scaleDownFactor) # examples: # ROUND_DOWN(estimated Δworkers=-5 * scaleDownFactor=0.5) = -2 # ROUND_DOWN(estimated Δworkers=-0.8 * scaleDownFactor=0.5) = 0 # ROUND_DOWN(estimated Δworkers=-1.5 * scaleDownFactor=0.5) = 0
Um scaleUpFactor ou scaleDownFactor de 1.0 significa que o escalonamento automático será dimensionado para que o recurso pendente ou disponível seja zero (utilização perfeita).
Quando a alteração no número de workers for calculada,
scaleUpMinWorkerFractionescaleDownMinWorkerFractionage como um limite para determinar se o cluster será escalonado pelo escalonamento automático. Uma pequena fração significa que o escalonamento automático precisa ser escalonado mesmo que oΔworkersseja pequeno. Uma fração maior significa que o escalonamento só pode ocorrer quando oΔworkersé grande.IF (Δworkers > scaleUpMinWorkerFraction * current_worker_count) then scale up
IF (abs(Δworkers) > scaleDownMinWorkerFraction * current_worker_count), THEN scale down.
Se o número de workers a escalonar for grande o suficiente para acionar o escalonamento, o escalonamento automático usará os limites
minInstancesmaxInstancesdeworkerConfigesecondaryWorkerConfigeweight(proporção de workers primários e secundários) para determinar como dividir o número de workers entre os grupos de instâncias de worker primário e secundário. O resultado desses cálculos é a alteração final de escalonamento automático no cluster para o período de escalonamento.As solicitações de redução de escalonamento automático serão canceladas em clusters criados com versões de imagem 2.0.57+, 2.1.5+ e versões de imagem mais recentes se:
- um redução está em andamento com um valor de tempo limite de desativação otimizada diferente de zero e
o número de workers YARN ATIVOS ("workers ativos") mais a mudança no número total de workers recomendada pelo escalonador automático (
Δworkers) é igual ou maior queDECOMMISSIONINGworkers YARN ("workers de desativação"), conforme mostrado na fórmula a seguir:IF (active workers + Δworkers ≥ active workers + decommissioning workers) THEN cancel the scaledown operation
Para um exemplo de cancelamento de redução de escala, consulte Quando o escalonamento automático cancela uma operação de redução de escala?.
Recomendações de configuração de escalonamento automático
Esta seção contém recomendações para ajudar você a configurar o escalonamento automático.
Evite escalonar os workers principais
Os workers principais executam HDFS Datanodes, enquanto os secundários são somente para computação.
O uso de workers secundários permite escalonar recursos de computação de maneira eficiente sem
a necessidade de provisionar armazenamento, resultando em recursos de escalonamento mais rápidos.
Os Namenodes do HDFS podem ter várias disputas que fazem com que o HDFS
seja corrompido, de modo que a desativação fique travada indefinidamente. Para
evitar esse problema, não dimensione os workers principais. Por exemplo:
none
workerConfig:
minInstances: 10
maxInstances: 10
secondaryWorkerConfig:
minInstances: 0
maxInstances: 100
Algumas modificações precisam ser feitas no comando de criação do cluster:
- Defina
--num-workers=10para corresponder ao tamanho do grupo de workers principais da política de escalonamento automático. - Defina
--secondary-worker-type=non-preemptiblepara configurar workers secundários como não preemptivos. (a menos que as VMs preemptivas sejam necessárias). - Copie a configuração de hardware de workers principais para workers secundários. Por
exemplo, defina
--secondary-worker-boot-disk-size=1000GBpara corresponder a--worker-boot-disk-size=1000GB.
Use o modo de flexibilidade aprimorado para jobs em lote do Spark
Use o modo de flexibilidade aprimorado (EFM) com escalonamento automático para:
permite um escalonamento reduzido mais rápido do cluster enquanto os jobs estão em execução
evitar interrupções nos jobs em execução devido à redução do cluster
minimizar a interrupção dos jobs em execução devido à remoção de workers secundários preemptivos
Com o EFM ativado, o tempo limite de desativação otimizada
de uma política de escalonamento automático precisa ser definido como 0s. A política de escalonamento automático só
precisa escalonar os workers secundários automaticamente.
Escolher um tempo limite de desativação otimizada
O escalonamento automático é compatível com a desativação otimizada do YARN ao remover nós de um cluster. A desativação otimizada permite que os aplicativos concluam a reprodução aleatória de dados entre cenários para evitar a definição do andamento do job. O tempo limite de desativação otimizada fornecido em uma política de escalonamento automático é o limite máximo da duração que o YARN aguardará pela execução dos aplicativos (o aplicativo que estava em execução durante a desativação) antes de remover nós.
Quando um processo não é concluído dentro do período de tempo limite de desativação sem falhas especificado, o nó de
trabalho é encerrado de modo forçado, o que pode causar perda de dados ou
interrupção do serviço. Para evitar essa possibilidade, defina o tempo limite de desativação otimizada com um valor maior que o
job mais longo que o cluster vai processar. Por exemplo, se você espera que seu trabalho mais longo seja executado por uma hora, defina o tempo limite para pelo menos uma hora (1h).
Pense na migração de jobs que levam mais de uma hora para os próprios clusters efêmeros para evitar o bloqueio da desativação otimizada.
Como definir scaleUpFactor
scaleUpFactor controla a intensidade com que o escalonador automático aumenta um cluster.
Especifique um número entre 0.0 e 1.0 para definir o valor fracionário
do recurso pendente do YARN que causa a adição de nós.
Por exemplo, se houver 100 contêineres pendentes solicitando 512 MB cada,
haverá 50 GB de memória pendente do YARN. Se scaleUpFactor for 0.5, o escalonador
automático adicionará nós suficientes para adicionar 25 GB de memória do YARN. Da mesma forma, se for
0.1, o escalonador automático adicionará nós suficientes para 5 GB. Observe que esses valores
correspondem à memória do YARN, não à memória total disponível fisicamente em uma VM.
Um bom ponto de partida é 0.05 para jobs do MapReduce e jobs do Spark com a alocação
dinâmica ativada. Para os jobs do Spark com uma contagem de executores fixos e jobs do Tez, use
1.0. Um scaleUpFactor de 1.0 significa que o escalonamento automático será dimensionado para que o
recurso pendente ou disponível seja 0 (utilização perfeita).
Como definir scaleDownFactor
scaleDownFactor controla a intensidade com que o escalonador automático reduz o
escalonamento de um cluster. Especifique um número entre 0.0 e 1.0 para definir o valor fracionário
do recurso disponível do YARN que causa a remoção do nó.
Deixe esse valor em 1.0 para a maioria dos clusters de vários jobs que precisam ser escalonar verticalmente com frequência. Como resultado da desativação otimizada, as operações de redução de escalonamento são
significativamente mais lentas do que as de aumento de escalonamento. A definição de scaleDownFactor=1.0 define
uma taxa de redução de escalonamento agressiva, o que minimiza o número de operações de redução de escalonamento
necessárias para atingir o tamanho de cluster adequado.
Para clusters que precisam de mais estabilidade, defina um scaleDownFactor menor para uma taxa de redução vertical mais lenta.
Defina esse valor como 0.0 para evitar a redução de escalonamento do cluster, por exemplo, ao usar clusters efêmeros ou de job único.
Definindo scaleUpMinWorkerFraction e scaleDownMinWorkerFraction
scaleUpMinWorkerFraction e scaleDownMinWorkerFraction são usados
com scaleUpFactor ou scaleDownFactor e têm valores
padrão de 0.0. Eles representam os limites em que o escalonador automático vai escalonar verticalmente ou reduzir escala vertical o cluster: o aumento ou diminuição fracionário mínimo no tamanho do cluster necessário para emitir solicitações de escalonamento vertical ou redução vertical.
Exemplos: o escalonador automático não vai emitir uma solicitação de atualização para adicionar 5 workers a um cluster de 100 nós, a menos que scaleUpMinWorkerFraction seja menor ou igual a 0.05 (5%). Se definido como 0.1, o escalonador automático não vai emitir a solicitação para escalonar verticalmente o cluster.
Da mesma forma, se scaleDownMinWorkerFraction for 0.05, o escalonador automático não
removerá pelo menos cinco nós.
O valor padrão de 0.0 significa que não há limite.
Definir um valor de scaleDownMinWorkerFractionthresholds mais alto em clusters grandes (mais de 100 nós) para evitar operações de escalonamento pequenas e desnecessárias é altamente recomendável.
Escolher um período de espera
O cooldownPeriod define um período em que o escalonador automático
não vai emitir solicitações para mudar o tamanho do cluster. É possível usar esse parâmetro
para limitar a frequência das mudanças do escalonador automático no tamanho do cluster.
O cooldownPeriod mínimo e padrão
é de dois minutos. Se um cooldownPeriod mais curto for definido em uma política, as alterações de carga de trabalho
afetarão mais rapidamente o tamanho do cluster, mas os clusters podem
aumentar e diminuir o escalonamento
desnecessariamente. A prática recomendada é definir
scaleUpMinWorkerFraction e scaleDownMinWorkerFraction
da política como um valor diferente de zero ao usar um cooldownPeriod mais curto. Isso garante que
o cluster só aumente ou diminua quando a mudança na utilização de recursos for
suficiente para justificar uma atualização do cluster.
Se a carga de trabalho for sensível a mudanças no tamanho do cluster, aumente o período de espera. Por exemplo, se você estiver executando um job de processamento em lote, poderá definir o período de espera como 10 minutos ou mais. Teste diferentes períodos de espera para encontrar o valor que funciona melhor para sua carga de trabalho.
Limites de contagem de workers e pesos de grupo
Cada grupo de workers tem minInstances e maxInstances que configuram um limite absoluto
no tamanho de cada grupo.
Cada grupo também tem um parâmetro chamado weight que configura o equilíbrio
de destino entre os dois grupos. Observe que esse parâmetro é apenas uma dica e,
se um grupo atingir o tamanho mínimo ou máximo, os nós só serão adicionados ou
removidos do outro grupo. Assim, weight quase sempre pode ser deixado no 1 padrão.
Ativar o escalonamento automático baseado em núcleos
Por padrão, o YARN usa métricas de memória para alocação de recursos. Para aplicativos que exigem muito da CPU, a prática recomendada é configurar o YARN para usar a Calculadora de recursos dominantes. Para fazer isso, defina a seguinte propriedade ao criar um cluster:
capacity-scheduler:yarn.scheduler.capacity.resource-calculator=org.apache.hadoop.yarn.util.resource.DominantResourceCalculator
Métricas e registros de escalonamento automático
Os recursos e ferramentas a seguir podem ajudá-lo a monitorar operações de escalonamento automático e respectivos efeitos no seu cluster e nos seus jobs.
Cloud Monitoring
Use o Cloud Monitoring para:
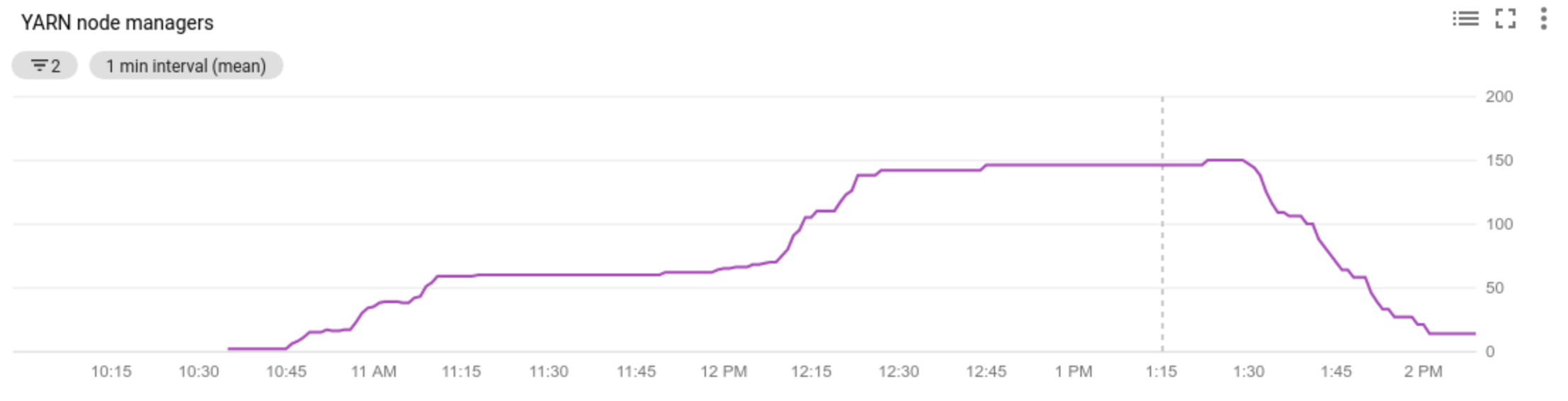
- ver as métricas usadas pelo escalonamento automático;
- ver o número de administradores de nodes no cluster;
- entender porque o escalonamento automático fez ou não o escalonamento do cluster.
Cloud Logging
Use o Cloud Logging para ver os registros do Dataproc Autoscaler.
1) Encontre registros para o cluster.
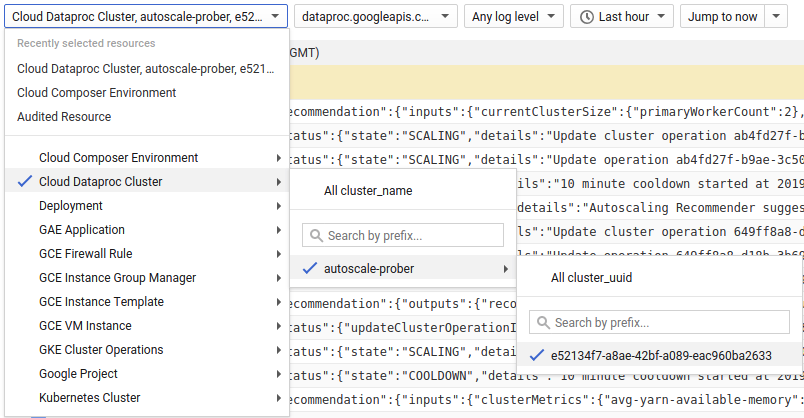
2) Selecione dataproc.googleapis.com/autoscaler.
3) Expanda as mensagens de registro para visualizar o campo status. Os registros estão em JSON, um
formato legível por máquina.
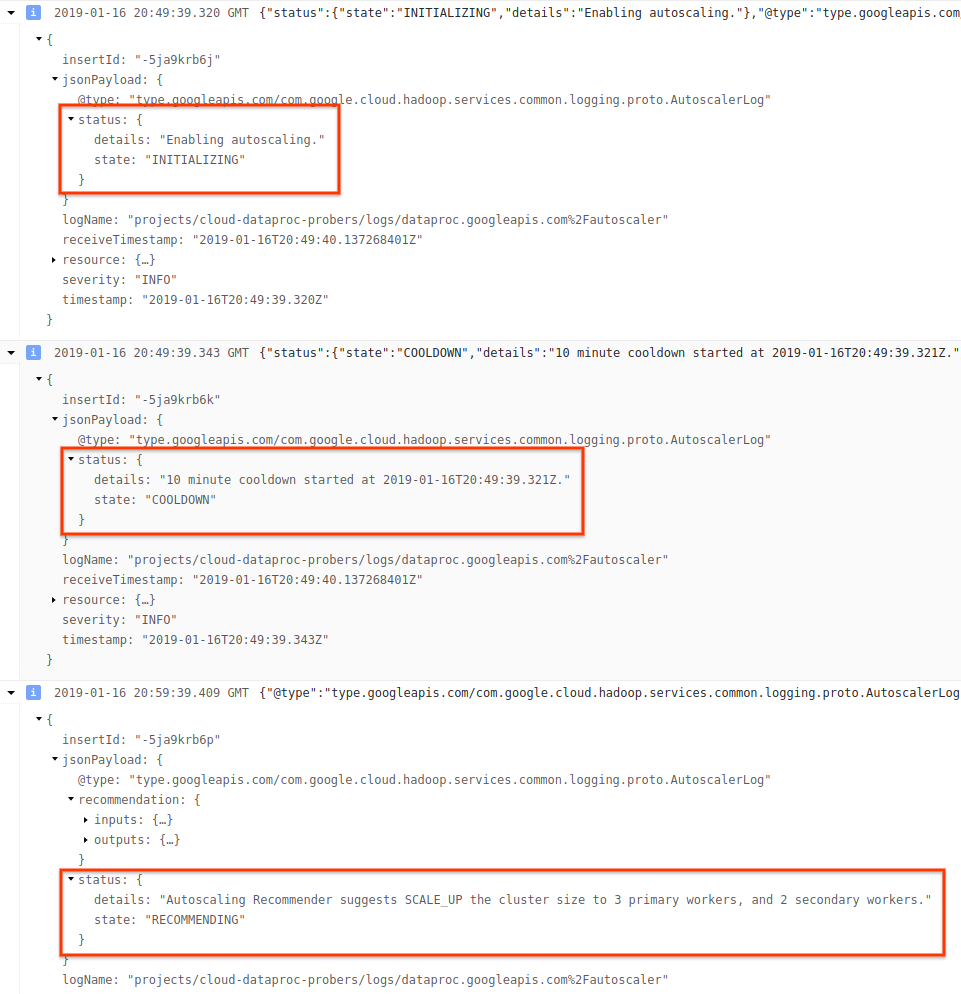
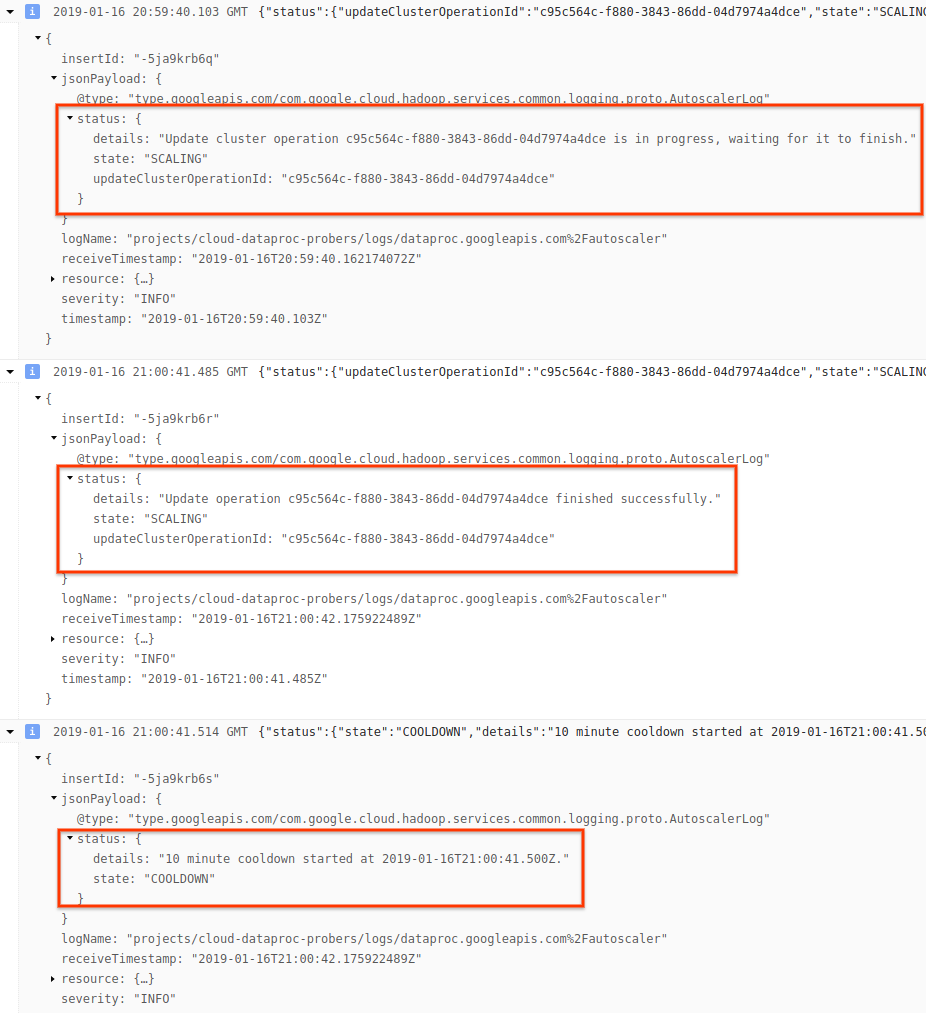
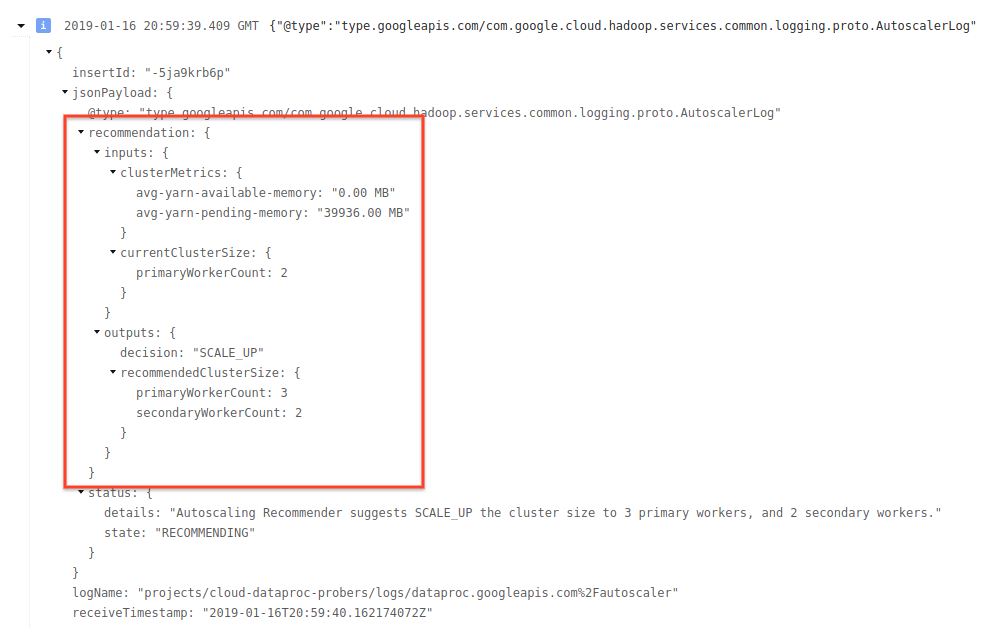
4) Expanda a mensagem de registro para ver recomendações de escalonamento, métricas usadas para decisões de escalonamento, o tamanho do cluster original e o novo tamanho do cluster de destino.
Segundo plano: como fazer o escalonamento automático com o Apache Hadoop e o Apache Spark
Nas seções a seguir, abordamos a maneira de interoperação do escalonamento automático com o YARN do Hadoop e o Hadoop Mapreduce e com o Apache Spark, o Spark Streaming e o Spark Structured Streaming.
Métricas do YARN do Hadoop
O escalonamento automático é centralizado nas seguintes métricas do YARN do Hadoop:
Allocated resourcerefere-se ao total de recursos YARN ocupados pela execução de contêineres em todo o cluster. Se houver 6 contêineres em execução que podem usar até 1 unidade de recurso, haverá 6 recursos alocados.Available resourceé o recurso YARN no cluster que não é usado pelos contêineres alocados. Se houver 10 unidades de recursos em todos os gerenciadores de nós e 6 delas estiverem alocadas, haverá 4 recursos disponíveis. Se houver recursos disponíveis (não utilizados) no cluster, com o escalonamento automático é possível remover workers do cluster.Pending resourceé a soma das solicitações de recursos do YARN para contêineres pendentes. Os contêineres pendentes aguardam espaço para serem executados no YARN. O recurso pendente só será diferente de zero se o recurso disponível for zero ou pequeno demais para ser alocado no próximo contêiner. Se houver contêineres pendentes, com o escalonamento automático será possível adicionar workers ao cluster.
É possível visualizar essas métricas no Cloud Monitoring. Por padrão, a memória YARN será de 0,8 * de memória total no cluster, com memória restante reservada para outros daemons e uso do sistema operacional, como o cache da página. É possível substituir o valor padrão pela configuração de configuração "yarn.nodemanager.resource.memory-mb" do YARN. Consulte Apache Hadoop YARN, HDFS, Spark e propriedades relacionadas.
Escalonamento automático e o Hadoop MapReduce
Com o MapReduce é executado cada mapa e reduzida a tarefa como um contêiner YARN separado. Quando um job começa, por meio do MapReduce são enviadas solicitações de contêiner para cada tarefa do mapa, resultando em grande aumento na memória pendente do YARN. À medida que as tarefas do mapa terminam, a memória pendente diminui.
Quando mapreduce.job.reduce.slowstart.completedmaps é concluído (95% por padrão
no Dataproc), o MapReduce enfileira solicitações de contêiner para todos
os redutores, resultando em outro pico na memória pendente.
A menos que as tarefas de mapa e redução demorem vários minutos ou mais, não
defina um valor alto para o escalonamento automático scaleUpFactor. Adicionar workers ao cluster demora pelo menos 1,5 minuto, portanto, verifique se há trabalho pendente suficiente para utilizar o novo worker por vários minutos. Um bom ponto de partida
é definir scaleUpFactor como 0,05 (5%) ou 0,1 (10%) da memória pendente.
Escalonamento automático e o Spark
Por meio do Spark, uma camada extra de agendamento é adicionada no topo do YARN. Especificamente, a alocação dinâmica do Spark Core faz solicitações ao YARN de contêineres para executar executores do Spark e, em seguida, programa tarefas do Spark em linhas de execução nesses executores. Com os clusters do Dataproc é feita a alocação dinâmica por padrão, portanto, os executores são adicionados e removidos conforme necessário.
No Spark, sempre é feita a solicitação de contêineres para o YARN, mas sem a alocação dinâmica, a solicitação só é feita no início do job. Com a alocação dinâmica, será feita a solicitação para a remoção de contêineres ou criação de novos, conforme a necessidade.
O Spark é iniciado com um número reduzido de executores - 2, em clusters de escalonamento automático - e
o número de executores é duplicado enquanto houver tarefas acumuladas.
Isso suaviza a memória pendente (menor número de picos de memória pendentes). É recomendado definir
scaleUpFactor de escalonamento automático como um número grande, como 1.0 (100%), para jobs do Spark.
Como desativar a alocação dinâmica do Spark
Se você estiver executando jobs separados do Spark que não se beneficiam da alocação
dinâmica do Spark, desative a alocação dinâmica do Spark definindo
spark.dynamicAllocation.enabled=false e spark.executor.instances.
É possível ainda usar o escalonamento automático para escalonar os clusters para mais ou para menos, enquanto os jobs separados
do Spark são executados.
Jobs do Spark com dados armazenados em cache
Defina spark.dynamicAllocation.cachedExecutorIdleTimeout ou remova os conjuntos de dados em cache quando
eles não forem mais necessários. Por padrão, o Spark não remove os executores que têm
dados armazenados em cache, o que evitaria a redução de escalonamento do cluster.
Escalonamento automático e o Spark Streaming
Como o Spark Streaming tem a própria versão de alocação dinâmica que usa sinais específicos de fluxo para adicionar e remover executores, defina
spark.streaming.dynamicAllocation.enabled=truee desative a alocação dinâmica do Spark Core definindospark.dynamicAllocation.enabled=false.Não use Desativação otimizada (escalonamento automático
gracefulDecommissionTimeout) com jobs do Spark Streaming. Em vez disso, para remover com segurança os workers com escalonamento automático, configure o checkpoint para tolerância a falhas.
Como alternativa, para usar o Spark Streaming sem o escalonamento automático:
- Desative a alocação dinâmica do Spark Core (
spark.dynamicAllocation.enabled=false) e - defina o número de executores (
spark.executor.instances) para o job. Veja Propriedades do cluster.
Escalonamento automático e o Spark Structured Streaming
O escalonamento automático não é compatível com o Spark Structured Streaming porque ele não oferece suporte à alocação dinâmica. Consulte SPARK-24815: o Structured Streaming é compatível com a alocação dinâmica.
Controlar o escalonamento automático com particionamento e paralelismo
Geralmente, o paralelismo é definido ou determinado pelos recursos do cluster. Por exemplo, o número de blocos do HDFS bloqueia o número de tarefas, com o escalonamento automático, a conversão se aplica: o escalonamento automático define o número de workers de acordo com o paralelismo do job. A seguir, as diretrizes para definir o paralelismo de jobs:
- Mesmo que o Dataproc defina o número padrão de tarefas
de redução do MapReduce com base no tamanho inicial do cluster, é possível definir
mapreduce.job.reducespara aumentar o paralelismo da fase de redução. - O paralelismo do Spark SQL e do DataFrame é determinado por
spark.sql.shuffle.partitions, que tem como padrão 200. - As funções RDD do Spark são padronizadas para
spark.default.parallelism, que é definido como o número de núcleos nos nós de trabalho quando o job é iniciado. No entanto, todas as funções RDD que criam embaralhamentos usam um parâmetro para o número de partições, que substituispark.default.parallelism.
É preciso garantir que os dados sejam particionados de maneira uniforme. Se houver uma distorção significativa de chave, uma ou mais tarefas podem demorar bem mais do que outras, resultando em baixa utilização.
Configurações de propriedades padrão de escalonamento automático do Spark e do Hadoop
Os clusters de escalonamento automático têm valores de propriedade de cluster padrão que ajudam a evitar a falha nos jobs, quando os workers principais são removidos ou quando os workers secundários são preteridos. É possível substituir esses valores padrão ao criar um cluster com escalonamento automático (consulte Propriedades do cluster).
Padrões para aumentar o número máximo de novas tentativas para tarefas, mestres de aplicativos e cenários:
yarn:yarn.resourcemanager.am.max-attempts=10 mapred:mapreduce.map.maxattempts=10 mapred:mapreduce.reduce.maxattempts=10 spark:spark.task.maxFailures=10 spark:spark.stage.maxConsecutiveAttempts=10
Padrões para redefinir os contadores de novas tentativas (útil para jobs de execução lenta do Spark Streaming):
spark:spark.yarn.am.attemptFailuresValidityInterval=1h spark:spark.yarn.executor.failuresValidityInterval=1h
Padrões para fazer com que o mecanismo de alocação dinâmica do Spark de inicialização lenta comece com um tamanho pequeno:
spark:spark.executor.instances=2
Perguntas frequentes
Esta seção contém perguntas e respostas comuns sobre o escalonamento automático.
O escalonamento automático pode ser ativado em clusters de alta disponibilidade e de nó único?
O escalonamento automático pode ser ativado em clusters de alta disponibilidade, mas não em clusters de nó único (eles não são compatíveis com redimensionamento).
É possível redimensionar manualmente um cluster de escalonamento automático?
Sim É possível redimensionar manualmente um cluster para interromper intervalos, ao ajustar uma política de escalonamento automático. No entanto, essas alterações terão apenas um efeito temporário, e o escalonamento automático acabará redimensionando novamente o cluster.
Em vez de redimensionar manualmente um cluster de escalonamento automático, considere:
Atualização da política de escalonamento automático. Todas as alterações feitas na política de escalonamento automático afetarão todos os clusters que atualmente usam a política (consulte Uso da política de vários clusters).
Desanexar a política e escalonar manualmente o cluster para o tamanho preferencial.
Como receber suporte do Dataproc.
Qual é a diferença entre o Dataproc e o escalonamento automático do Dataflow?
Consulte Escalonamento automático horizontal do Dataflow e Escalonamento automático vertical do Dataflow Prime.
A equipe de desenvolvimento do Dataproc pode redefinir o status de um cluster de ERROR para RUNNING?
Em geral, não. Isso requer esforço manual para verificar se é seguro redefinir o estado do cluster e, muitas vezes, não é possível redefini-lo sem outras etapas manuais, como reiniciar o NameNode do HDFS.
O Dataproc define o status de um cluster como ERROR quando
não consegue determinar o status de um cluster após uma operação com falha. Os clusters em
ERROR não têm escalonamento automático. Estas são as causas mais comuns:
Erros retornados da API Compute Engine, geralmente durante interrupções do Compute Engine.
O HDFS entra em um estado corrompido devido a bugs na desativação do HDFS.
Erros da API Dataproc Control, como "O lease de tarefas expirou".
Exclua e recrie clusters com status ERROR.
Quando o escalonamento automático cancela uma operação de redução?
O gráfico a seguir é uma ilustração que demonstra quando o escalonamento automático cancela uma operação de redução de escala. Consulte também Como o escalonamento automático funciona.
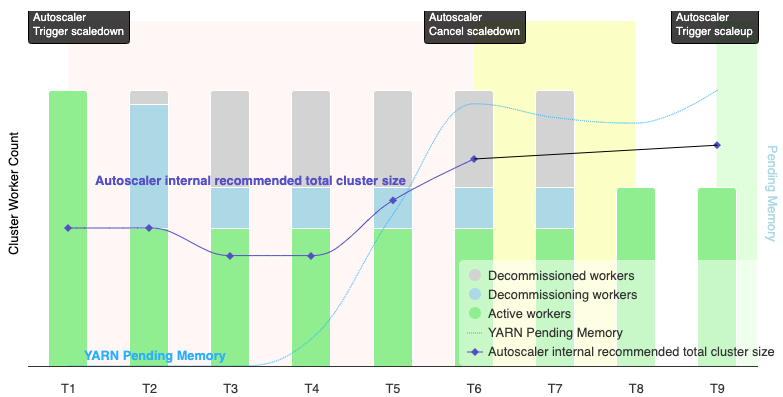
Observações:
- O cluster tem o escalonamento automático ativado com base apenas nas métricas de memória do YARN (o padrão).
- T1 a T9 representam intervalos de espera quando o escalonador automático avalia o número de workers (o tempo do evento foi simplificado).
- As barras empilhadas representam contagens de workers ativos, em desativação e desativados do YARN do cluster.
- O número recomendado de workers do escalonador automático (linha preta) se baseia nas métricas de memória do YARN, na contagem de workers ativos do YARN e nas configurações da política de escalonamento automático. Consulte Como funciona o escalonamento automático.
- A área vermelha indica o período em que a operação de redução está em execução.
- A área amarela indica o período em que a operação de redução está sendo cancelada.
- A área verde indica o período da operação de escalonamento.
As operações a seguir ocorrem nos seguintes horários:
T1: o escalonador automático inicia uma operação de redução de escala de desativação otimizada para reduzir escala vertical de aproximadamente metade dos workers do cluster atual.
T2: o escalonador automático continua monitorando as métricas do cluster. Ela não muda a recomendação de redução vertical, e a operação continua. Alguns workers foram desativados, e outros estão sendo desativados (o Dataproc exclui os workers desativados).
T3: o escalonador automático calcula que o número de workers pode reduzir escala vertical ainda mais, talvez devido à disponibilidade de mais memória do YARN. No entanto, como o número de workers ativos mais a mudança recomendada no número de workers não é igual ou maior que o número de workers ativos mais os em desativação, os critérios para cancelamento da redução não são atendidos, e o escalonador automático não cancela a operação de redução.
T4: o YARN informa um aumento na memória pendente. No entanto, o escalonador automático não muda a recomendação de contagem de workers. Como no T3, os critérios de cancelamento da redução ainda não foram atendidos, e o escalonador automático não cancela a operação de redução.
T5: a memória pendente do YARN aumenta, e a mudança no número de workers recomendada pelo escalonador automático aumenta. No entanto, como o número de workers ativos mais a mudança recomendada no número de workers é menor que o número de workers ativos mais os em desativação, os critérios de cancelamento não são atendidos, e a operação de redução não é cancelada.
T6: a memória YARN pendente aumenta ainda mais. O número de workers ativos mais a mudança no número de workers recomendada pelo escalonador automático agora é maior que o número de workers ativos mais os em desativação. Os critérios de cancelamento são atendidos, e o escalonador automático cancela a operação de redução.
T7: O escalonador automático está aguardando a conclusão do cancelamento da operação de redução. O escalonador automático não avalia nem recomenda uma mudança no número de workers durante esse intervalo.
T8: o cancelamento da operação de redução de escala é concluído. Os workers desativados são adicionados ao cluster e ficam ativos. O escalonador automático detecta a conclusão do cancelamento da operação de redução e aguarda o próximo período de avaliação (T9) para calcular o número recomendado de workers.
T9: não há operações ativas no horário da T9. Com base na política de escalonamento automático e nas métricas do YARN, o autoescalador recomenda uma operação de escalonamento vertical.