자동 확장이란 무엇인가요?
워크로드에 '적절한' 클러스터 작업자(노드) 수를 예측하는 것은 어려우며 전체 파이프라인에 단일 클러스터 크기를 사용하는 것이 적합하지 않은 경우가 많습니다. 사용자가 시작하는 클러스터 확장으로 이 문제를 부분적으로 해결할 수 있지만 클러스터 사용률 및 수동 개입을 모니터링해야 합니다.
Dataproc AutoscalingPolicies API는 클러스터 리소스 관리를 자동화하는 메커니즘을 제공하고 클러스터 작업자 VM 자동 확장을 사용 설정합니다. Autoscaling Policy는 자동 확장 정책을 사용하는 클러스터 작업자가 확장되어야 하는 방식을 설명하는 재사용 가능한 구성입니다. 확장 경계, 빈도, 강도를 정의하여 클러스터의 수명 동안 클러스터 리소스에 대한 세분화된 제어를 제공합니다.
자동 확장을 사용해야 하는 경우
자동 확장 사용:
Cloud Storage 또는 BigQuery와 같이 데이터를 외부 서비스에 저장하는 클러스터
여러 작업을 처리하는 클러스터
단일 작업 클러스터 확장
Spark 일괄 작업에 향상된 유연성 모드 사용
다음을 대상으로 하거나 다음의 용도로 자동 확장을 사용하는 것은 권장되지 않습니다.
HDFS: 자동 확장은 온클러스터 HDFS를 확장하기 위한 용도가 아니며, 그 이유는 다음과 같습니다.
- HDFS 사용률은 자동 확장을 위한 신호가 아닙니다.
- HDFS 데이터는 기본 작업자에서만 호스팅됩니다. 기본 작업자 수는 모든 HDFS 데이터를 호스팅하기에 충분해야 합니다.
- HDFS DataNode를 사용 중단할 경우 작업자 삭제가 지연될 수 있습니다. 데이터 노드는 작업자가 삭제되기 전에 HDFS 블록을 다른 데이터 노드에 복사합니다. 데이터 크기 및 복제 인수에 따라 이 프로세스는 몇 시간이 걸릴 수 있습니다.
YARN Node Labels: 자동 확장은 YARN Node Labels를 지원하지 않으며 YARN-9088로 인해
dataproc:am.primary_only속성도 지원하지 않습니다. YARN은 노드 라벨을 사용할 때 클러스터 측정항목을 잘못 보고합니다.Spark Structured Streaming: 자동 확장은 Spark Structured Streaming을 지원하지 않습니다(자동 확장 및 Spark Structured Streaming 참조).
유휴 클러스터: 클러스터가 유휴 상태일 때 클러스터를 최소 크기로 축소하기 위한 용도로 자동 확장을 사용하는 것은 권장되지 않습니다. 새 클러스터 만들기와 클러스터 크기 조절은 비슷한 속도로 실행되기 때문에 유휴 클러스터를 삭제하고 대신 다시 만드는 것이 좋습니다. 다음 도구가 이러한 '임시' 모델을 지원합니다.
Dataproc 워크플로를 사용하여 전용 클러스터에서 일련의 작업을 예약하고, 작업이 완료되면 클러스터를 삭제합니다. 고급 조정의 경우 Apache Airflow 기반의 Cloud Composer를 사용합니다.
임시 쿼리 또는 외부에서 예약된 워크로드를 처리하는 클러스터의 경우, 클러스터 예약 삭제를 사용하여 지정된 유휴 기간 후에 또는 특정 시간에 클러스터를 삭제합니다.
크기가 다른 워크로드: 소규모 작업과 대규모 작업이 클러스터에서 실행되면 단계적 해제 축소가 대규모 작업이 완료될 때까지 기다립니다. 따라서 장기 실행 작업이 완료될 때까지 클러스터에서 실행 중인 소규모 작업에 대한 리소스 자동 확장이 지연됩니다. 이 결과를 방지하려면 클러스터에서 비슷한 크기의 작은 작업을 그룹화하고 별도의 클러스터에서 각 장기 작업을 격리하세요.
자동 확장 사용 설정
클러스터에서 자동 확장 정책을 사용 설정하려면 다음 안내를 따르세요.
다음 중 하나를 수행합니다.
자동 확장 정책 만들기
gcloud CLI
gcloud dataproc autoscaling-policies import 명령어를 사용하여 자동 확장 정책을 만들 수 있습니다. 자동 확장 정책을 정의하는 로컬 YAML 파일을 읽습니다. 파일의 형식 및 콘텐츠는 autoscalingPolicies REST API에서 정의한 구성 객체 및 필드와 일치해야 합니다.
다음 YAML 예시는 모든 필수 필드가 포함된 Dataproc 표준 클러스터의 정책을 정의합니다. 또한 기본 작업자의 minInstances 및 maxInstances 값과 보조(선점형) 작업자의 maxInstances 값을 제공하며 4분 cooldownPeriod(기본값은 2분)를 지정합니다. workerConfig는 기본 작업자를 구성합니다. 이 예시에서는 기본 작업자 확장을 방지하기 위해 minInstances 및 maxInstances가 동일한 값으로 설정됩니다.
workerConfig:
minInstances: 10
maxInstances: 10
secondaryWorkerConfig:
maxInstances: 50
basicAlgorithm:
cooldownPeriod: 4m
yarnConfig:
scaleUpFactor: 0.05
scaleDownFactor: 1.0
gracefulDecommissionTimeout: 1h
다음 YAML 예시는 모든 필수 필드 및 선택적 자동 확장 정책 필드가 포함된 Dataproc 표준 클러스터의 정책을 정의합니다.
clusterType: STANDARD
workerConfig:
minInstances: 10
maxInstances: 10
weight: 1
secondaryWorkerConfig:
minInstances: 0
maxInstances: 100
weight: 1
basicAlgorithm:
cooldownPeriod: 2m
yarnConfig:
scaleUpFactor: 0.05
scaleDownFactor: 1.0
scaleUpMinWorkerFraction: 0.0
scaleDownMinWorkerFraction: 0.0
gracefulDecommissionTimeout: 1h
다음 YAML 예시는 제로 스케일 클러스터의 정책을 정의합니다.
제로 스케일 클러스터에는workerConfig가 포함되지 않습니다.
clusterType: ZERO_SCALE
secondaryWorkerConfig:
minInstances: 0
maxInstances: 100
weight: 1
basicAlgorithm:
cooldownPeriod: 2m
yarnConfig:
scaleUpFactor: 0.05
scaleDownFactor: 1.0
scaleUpMinWorkerFraction: 0.0
scaleDownMinWorkerFraction: 0.0
gracefulDecommissionTimeout: 1h
로컬 터미널 또는 Cloud Shell에서 gcloud 명령어를 실행하여 자동 확장 정책을 만듭니다. 정책의 이름을 입력합니다. 이 이름이 id 정책이 되며, 나중에 gcloud 명령어에서 정책을 참조할 때 사용될 수 있습니다. --source 플래그를 사용하여 가져올 자동 확장 정책 YAML 파일의 로컬 경로와 파일 이름을 지정합니다.
gcloud dataproc autoscaling-policies import policy-name \ --source=filepath/filename.yaml \ --region=region
REST API
autoscalingPolicies.create 요청의 일부로 AutoscalingPolicy를 정의하여 자동 확장 정책을 만듭니다.
콘솔
자동 확장 정책을 만들려면 Google Cloud 콘솔의 Dataproc 자동 확장 정책 페이지에서 정책 만들기를 선택합니다. 정책 만들기 페이지에서 정책 권장사항 패널을 선택하여 특정 작업 유형 또는 확장 목표에 대한 자동 확장 정책 필드를 채울 수 있습니다.
자동 확장 클러스터 만들기
자동 확장 정책을 만들었으면 자동 확장 정책을 사용할 클러스터를 만듭니다. 클러스터는 자동 확장 정책과 동일한 리전에 있어야 합니다.
gcloud CLI
로컬 터미널 또는 Cloud Shell에서 gcloud 명령어를 실행하여 자동 확장 클러스터를 만듭니다. 클러스터 이름을 입력하고 --autoscaling-policy 플래그를 사용하여 policy ID(정책을 만들 때 지정한 정책 이름) 또는 정책 resource URI (resource name)를 지정합니다(AutoscalingPolicy id 및 name 필드 참조).
gcloud dataproc clusters create cluster-name \ --autoscaling-policy=policy id or resource URI \ --region=region
REST API
clusters.create 요청에 AutoscalingConfig를 포함하여 자동 확장 클러스터를 만듭니다.
콘솔
Google Cloud 콘솔의 Dataproc 클러스터 만들기 페이지에서 설정 클러스터 패널의 자동 확장 정책 섹션에서 새 클러스터에 적용할 기존 자동 확장 정책을 선택할 수 있습니다.
기존 클러스터에서 자동 확장 사용 설정
자동 확장 정책을 만들었으면 동일한 리전의 기존 클러스터에서 정책을 사용 설정할 수 있습니다.
gcloud CLI
로컬 터미널 또는 Cloud Shell에서 gcloud 명령어를 실행하여 기존 클러스터에서 자동 확장 정책을 사용 설정합니다. 클러스터 이름을 입력하고 --autoscaling-policy 플래그를 사용하여 policy ID(정책을 만들 때 지정한 정책 이름) 또는 정책 resource URI (resource name)를 지정합니다(AutoscalingPolicy id 및 name 필드 참조).
gcloud dataproc clusters update cluster-name \ --autoscaling-policy=policy id or resource URI \ --region=region
REST API
기존 클러스터에서 자동 확장 정책을 사용 설정하려면 clusters.patch 요청의 updateMask에서 정책의 AutoscalingConfig.policyUri를 설정합니다.
콘솔
Google Cloud 콘솔에서는 기존 클러스터에 자동 확장 정책 사용 설정이 지원되지 않습니다.
멀티 클러스터 정책 사용
자동 확장 정책은 여러 클러스터에 적용할 수 있는 확장 동작을 정의합니다. 자동 확장 정책은 비슷한 워크로드를 공유하거나 리소스 사용 패턴이 비슷한 작업을 실행하는 여러 클러스터에 적용하는 데 가장 적합합니다.
여러 클러스터에서 사용 중인 정책을 업데이트할 수 있습니다. 이 업데이트는 해당 정책을 사용하는 모든 클러스터의 자동 확장 동작에 즉시 영향을 미칩니다(autoscalingPolicies.update 참조). 정책을 사용 중인 클러스터에 정책 업데이트를 적용하지 않으려면 정책을 업데이트하기 전에 클러스터에서 자동 확장을 사용 중지합니다.
gcloud CLI
로컬 터미널 또는 Cloud Shell에서 gcloud 명령어를 실행하여 클러스터에서 자동 확장 정책을 사용 중지합니다.
gcloud dataproc clusters update cluster-name --disable-autoscaling \ --region=region
REST API
클러스터에서 자동 확장을 사용 중지하려면 AutoscalingConfig.policyUri를 빈 문자열로 설정하거나 clusters.patch 요청에 update_mask=config.autoscaling_config.policy_uri를 설정합니다.
콘솔
Google Cloud 콘솔에서는 클러스터에 자동 확장 사용 중지가 지원되지 않습니다.
- 1개 이상의 클러스터에서 사용 중인 정책은 삭제할 수 없습니다(autoscalingPolicies.delete 참조).
자동 확장 방식
자동 확장은 '대기' 기간마다 클러스터 Hadoop YARN 측정항목을 확인하여 클러스터를 확장할 것인지 그리고 확장할 경우 어느 정도 업데이트할 것인지를 결정합니다.
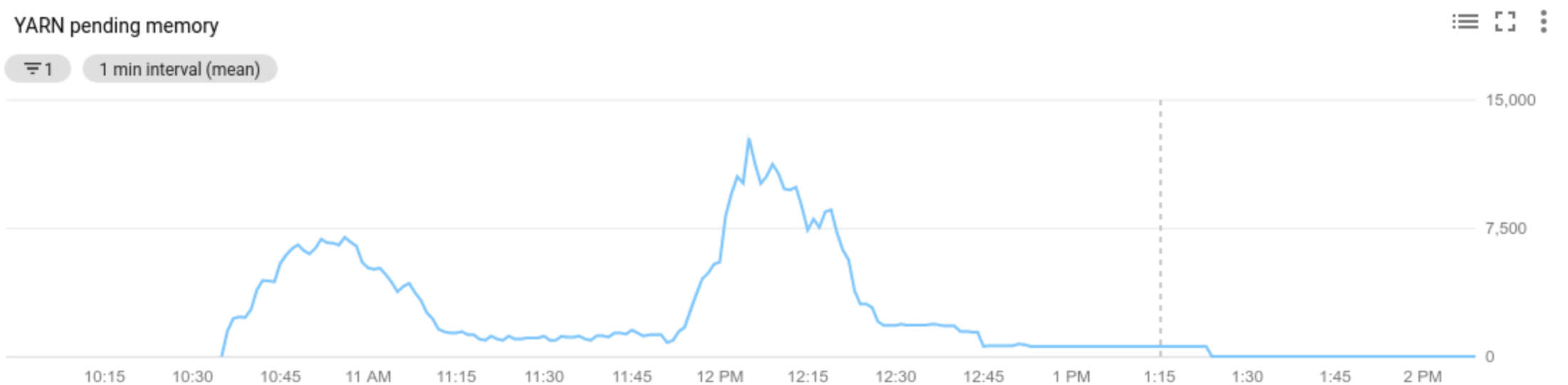
YARN 보류 리소스 측정항목(보류 메모리 또는 보류 코어) 값은 확장하거나 축소할지 여부를 결정합니다.
0보다 큰 값은 YARN 작업이 리소스를 기다리고 있고 수직 확장이 필요할 수 있음을 나타냅니다.0값은 YARN에 충분한 리소스가 있으므로 축소 또는 기타 변경이 필요하지 않을 수 있음을 나타냅니다.보류 리소스가 0보다 큰 경우:
$estimated\_worker\_count =$
\[ \Biggl \lceil AVERAGE\ during\ cooldown\ period\Big(\frac{Pending + Available + Allocated + Reserved}{Resource\ per\ worker}\Big)\Biggr \rceil \]
보류 리소스가 0인 경우:
$estimated\_worker\_count =$
\[ \Biggl \lceil AVERAGE\ during\ cooldown\ period\Big(\frac{Allocated + Reserved}{Resource\ per\ worker}\Big)\Biggr \rceil \]
Dataproc 이미지 2.2부터 기본적으로 자동 확장 처리기는 YARN 메모리와 YARN 코어를 모니터링하므로
estimated_worker_count가 메모리와 코어에 대해 별도로 평가되고 그 결과 더 큰 작업자 수가 선택됩니다. 이전 이미지 버전의 경우 코어 기반 자동 확장을 사용 설정하지 않으면 자동 확장 처리가 YARN 메모리만 모니터링합니다.$estimated\_worker\_count =$
\[ max(estimated\_worker\_count\_by\_memory,\ estimated\_worker\_count\_by\_cores) \]
\[ estimated\ \Delta worker = estimated\_worker\_count - current\_worker\_count \]
작업자 수를 얼마나 변경해야 하는지 파악한 후 자동 확장은
scaleUpFactor또는scaleDownFactor를 사용하여 실제 작업자 수의 변화를 계산합니다.if estimated Δworkers > 0: actual Δworkers = ROUND_UP(estimated Δworkers * scaleUpFactor) # examples: # ROUND_UP(estimated Δworkers=5 * scaleUpFactor=0.5) = 3 # ROUND_UP(estimated Δworkers=0.8 * scaleUpFactor=0.5) = 1 else: actual Δworkers = ROUND_DOWN(estimated Δworkers * scaleDownFactor) # examples: # ROUND_DOWN(estimated Δworkers=-5 * scaleDownFactor=0.5) = -2 # ROUND_DOWN(estimated Δworkers=-0.8 * scaleDownFactor=0.5) = 0 # ROUND_DOWN(estimated Δworkers=-1.5 * scaleDownFactor=0.5) = 0
1.0의 scaleUpFactor 또는 scaleDownFactor는 보류 또는 사용 가능한 리소스가 0(완전 사용)이 되도록 자동 확장이 이루어진다는 의미입니다.
작업자 수의 변경사항이 계산되면
scaleUpMinWorkerFraction및scaleDownMinWorkerFraction이 기준점 역할을 하여 자동 확장이 클러스터를 확장할지 결정합니다. 작은 비율은Δworkers가 작은 경우에도 자동 확장이 이루어진다는 의미입니다. 비율이 클 경우Δworkers가 클 경우에만 확장됩니다.IF (Δworkers > scaleUpMinWorkerFraction * current_worker_count) then scale up
IF (abs(Δworkers) > scaleDownMinWorkerFraction * current_worker_count), THEN scale down.
작업자 수가 확장이 필요할 만큼 클 경우, 자동 확장은
workerConfig및secondaryWorkerConfig의minInstancesmaxInstances경계와weight(기본 작업자와 보조 작업자의 비율)를 사용하여 기본 및 보조 작업자 인스턴스 그룹 간에 작업자 수를 분할할 방법을 결정합니다. 이 계산의 결과에 따라 자동 확장은 확장 기간 동안 클러스터를 최종적으로 변경합니다.다음과 같은 경우에는 2.0.57+, 2.1.5+ 및 이후 이미지 버전으로 생성된 클러스터에서 자동 확장 축소 요청이 취소됩니다.
- 0이 아닌 단계적 해제 제한 시간 값으로 축소가 진행 중입니다.
ACTIVE YARN 작업자 수('활성 작업자')와 자동 확장 처리가 권장하는 총 작업자 수의 변화(
Δworkers) 값은DECOMMISSIONINGYARN 작업자('사용 중단 작업자')보다 크거나 같습니다. 다음 수식에서 확인할 수 있습니다.IF (active workers + Δworkers ≥ active workers + decommissioning workers) THEN cancel the scaledown operation
축소 취소 예시는 자동 확장은 언제 축소 작업을 취소하나요?를 참조하세요.
자동 확장 구성 권장사항
이 섹션에는 자동 확장을 구성하는 데 도움이 되는 권장사항이 포함되어 있습니다.
기본 작업자 확장 방지
기본 작업자는 HDFS Datanode를 실행하는 반면 보조 작업자는 컴퓨팅 전용입니다.
보조 작업자를 사용하면 스토리지를 프로비저닝할 필요 없이 컴퓨팅 리소스를 효율적으로 확장할 수 있으므로 확장 기능이 더 빨라집니다.
HDFS Namenode에는 영구적으로 해제가 반복되도록 HDFS가 손상된 상태로 전환되는 여러 경합 상태가 있습니다. 이 문제를 방지하려면 기본 작업자를 확장하지 않습니다. 예를 들면 다음과 같습니다.
none
workerConfig:
minInstances: 10
maxInstances: 10
secondaryWorkerConfig:
minInstances: 0
maxInstances: 100
클러스터 생성 명령어에 몇 가지 수정을 해야 합니다.
--num-workers=10을 자동 확장 정책의 기본 작업자 그룹 크기와 일치하도록 설정합니다.- 보조 작업자를 비선점형으로 구성하려면
--secondary-worker-type=non-preemptible을 설정합니다. (선점형 VM을 원하지 않는 경우). - 기본 작업자에서 보조 작업자로 하드웨어 구성을 복사합니다. 예를 들어
--worker-boot-disk-size=1000GB와--secondary-worker-boot-disk-size=1000GB가 일치하도록 설정합니다.
Spark 일괄 작업에 향상된 유연성 모드 사용
자동 확장과 함께 향상된 유연성 모드(EFM)를 사용하면 다음과 같은 이점이 있습니다.
작업이 실행되는 동안 클러스터의 더 빠른 축소를 사용 설정합니다.
클러스터 축소로 인해 작업 실행 중단을 방지합니다.
선점형 보조 작업자의 선점으로 인한 작업 실행 중단을 최소화합니다.
EFM을 사용 설정한 경우 자동 확장 정책의 단계적 해제 제한 시간을 0s로 설정해야 합니다. 자동 확장 정책은 보조 작업자만 자동 확장해야 합니다.
단계적 해제 제한 시간 선택
자동 확장은 클러스터에서 노드를 삭제할 때 YARN 단계적 해제를 지원합니다. 단계적 해제를 사용하면 애플리케이션이 단계 간의 데이터 셔플 처리를 완료하여 작업 진행을 다시 설정할 필요가 없습니다. 자동 확장 정책에서 제공되는 단계적 해제 제한 시간은 YARN이 노드를 삭제하기 전에 실행 중인 애플리케이션(사용 중단이 시작되었을 때 실행 중이었던 애플리케이션)을 기다리는 기간의 상한입니다.
프로세스가 지정된 단계적 해제 제한 시간 내에 완료되지 않으면 워커 노드가 강제로 종료되어 데이터 손실 또는 서비스 중단이 발생할 수 있습니다. 이러한 상황을 방지하려면 단계적 해제 제한 시간을 클러스터가 처리할 가장 긴 작업보다 큰 값으로 설정합니다. 예를 들어 가장 긴 작업이 1시간 동안 실행될 것으로 예상되는 경우 제한 시간을 최소 1시간(1h)으로 설정합니다.
단계적 해제 차단을 방지하려면 1시간 이상 걸리는 작업을 자체 임시 클러스터로 이전하는 것이 좋습니다.
scaleUpFactor 설정
scaleUpFactor는 자동 확장 처리가 클러스터를 확장하는 정도를 제어합니다.
0.0과 1.0 사이의 숫자를 지정하여 노드 추가를 유발하는 YARN 보류 리소스의 분수 값을 설정합니다.
예를 들어 각각 512MB를 요청하는 보류 중인 컨테이너가 100개 있으면 보류 중인 YARN 메모리는 50GB입니다. scaleUpFactor가 0.5이면 자동 확장 처리가 노드를 추가로 추가하여 25GB의 YARN 메모리를 추가합니다. 마찬가지로 0.1인 경우 자동 확장 처리가 5GB를 위한 충분한 노드를 추가합니다. 이 값은 YARN 메모리에 해당하며, VM에서 실제로 제공되는 총 메모리가 아닙니다.
동적 할당을 사용하는 맵리듀스 작업과 Spark 작업의 경우 0.05로 시작하는 것이 좋습니다. 고정 실행자 수 및 Tez 작업이 포함된 Spark 작업의 경우 1.0을 사용합니다. 1.0의 scaleUpFactor는 보류 또는 사용 가능한 리소스가 0(완전 사용)이 되도록 자동 확장이 이루어진다는 의미입니다.
scaleDownFactor 설정
scaleDownFactor는 자동 확장 처리가 클러스터를 축소하는 정도를 제어합니다. 0.0과 1.0 사이의 숫자를 지정하여 노드 삭제를 유발하는 YARN 사용 가능 리소스의 분수 값을 설정합니다.
대부분의 멀티 작업 클러스터에는 이 값을 자주 확장 및 축소하기보다는 1.0으로 둡니다. 단계적 해제로 인해 축소 작업은 확장 작업보다 훨씬 느립니다. scaleDownFactor=1.0을 설정하면 공격적인 축소 속도가 설정되므로 적절한 클러스터 크기를 얻기 위해 필요한 축소 작업 수가 최소화됩니다.
안정성이 더 필요한 클러스터의 경우 축소 속도 저하를 위해 scaleDownFactor를 낮게 설정하세요.
클러스터를 축소하지 않으려면 이 값을 0.0으로 설정합니다(예: 임시 또는 단일 작업 클러스터를 사용하는 경우).
scaleUpMinWorkerFraction 및 scaleDownMinWorkerFraction 설정
scaleUpMinWorkerFraction 및 scaleDownMinWorkerFraction은 scaleUpFactor 또는 scaleDownFactor와 함께 사용되며 기본값은 0.0입니다. 이는 자동 확장 처리가 클러스터를 확장하거나 축소하는 임곗값을 나타냅니다. 최소 분수 값은 확장 또는 축소 요청을 실행하는 데 필요한 클러스터 크기를 늘리거나 줄입니다.
예를 들어 scaleUpMinWorkerFraction이 0.05(5%) 이하여야 자동 확장 처리가 100개 노드 클러스터에 작업자 5명을 추가하는 업데이트 요청을 실행합니다. 0.1로 설정하면 자동 확장 처리가 클러스터의 수직 확장을 요청하지 않습니다.
마찬가지로 scaleDownMinWorkerFraction이 0.05이면 자동 확장 처리는 5개 이상의 노드가 삭제되어야 합니다.
0.0의 기본값은 임곗값이 없음을 의미합니다.
큰 클러스터(노드 100개 이상)에 더 높은 scaleDownMinWorkerFractionthresholds을 설정하여 사소하고 불필요한 확장 작업을 방지하기 위해 적극 권장합니다.
대기 기간 선택
cooldownPeriod는 자동 확장 처리가 클러스터 크기 변경 요청을 실행하지 않는 기간을 설정합니다. 이를 사용하여 자동 확장 처리가 클러스터 크기를 변경하는 빈도를 제한할 수 있습니다.
cooldownPeriod의 최솟값 및 기본값은 모두 2분입니다. 정책에서 더 짧은 cooldownPeriod를 설정하면 워크로드 변경 사항이 클러스터 크기에 더 빨리 영향을 미치지만 불필요하게 클러스터가 확장 및 축소될 수 있습니다. 더 짧은 cooldownPeriod를 사용할 때는 정책의 scaleUpMinWorkerFraction, scaleDownMinWorkerFraction을 모두 0이 아닌 값으로 설정하는 것이 좋습니다. 이렇게 하면 리소스 사용률의 변화가 클러스터 업데이트를 보증하기에 충분할 때만 클러스터가 확장 및 축소됩니다.
워크로드가 클러스터 크기 변경에 민감한 경우 대기 기간을 늘릴 수 있습니다. 예를 들어 일괄 처리 작업을 실행 중인 경우 대기 기간을 10분 이상으로 설정할 수 있습니다. 다양한 대기 기간을 실험하여 워크로드에 가장 적합한 값을 찾습니다.
작업자 수 경계 및 그룹 가중치
각 작업자 그룹에는 각 그룹의 크기에 대한 엄격한 제한을 구성하는 minInstances 및 maxInstances가 있습니다.
또한 각 그룹에는 두 그룹 간 목표 잔액을 구성하는 weight라는 매개변수가 있습니다. 이 매개변수는 힌트로만 제공되며, 그룹이 최소 또는 최대 크기에 도달하면 노드가 다른 그룹에서만 추가되거나 삭제됩니다. 따라서 weight는 거의 항상 기본 1에서 남겨둘 수 있습니다.
코어 기반 자동 확장 사용
CPU 집약적인 애플리케이션의 경우 리소스 할당에 기본 리소스 계산기를 사용하는 것이 좋습니다. 이는 Dataproc 이미지 버전 2.2부터의 기본 YARN 구성입니다. 이전 이미지 버전에서는 클러스터를 만들 때 다음 속성을 설정하여 기본 리소스 계산기를 사용하도록 YARN을 구성하지 않는 한 Dataproc에서 리소스 할당을 위해 메모리 측정항목을 사용하도록 YARN을 구성합니다.
capacity-scheduler:yarn.scheduler.capacity.resource-calculator=org.apache.hadoop.yarn.util.resource.DominantResourceCalculator
자동 확장 측정항목 및 로그
다음 리소스 및 도구는 자동 확장 작업과 클러스터 및 작업에 미치는 영향을 모니터링하는 데 도움을 줄 수 있습니다.
Cloud Monitoring
다음과 같은 용도로 Cloud Monitoring을 사용합니다.
- 자동 확장에서 사용하는 측정항목을 봅니다.
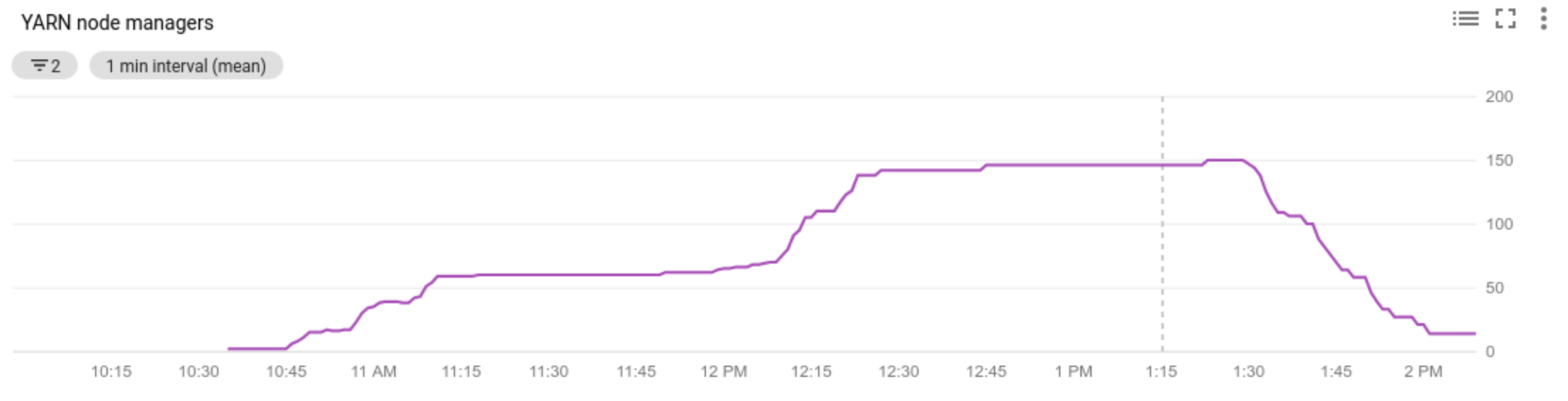
- 클러스터에 있는 노드 관리자 수를 봅니다.
- 자동 확장이 클러스터를 확장하거나 확장하지 않은 이유를 이해합니다.
Cloud Logging
Cloud Logging을 사용하여 Dataproc 자동 확장 처리의 로그를 확인하세요.
1) 클러스터의 로그를 찾습니다.
2) dataproc.googleapis.com/autoscaler를 선택합니다.
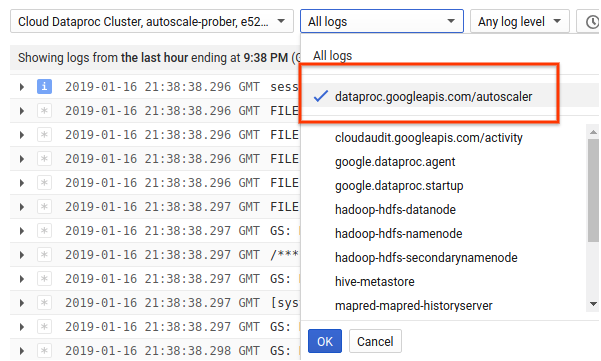
3) 로그 메시지를 펼쳐서 status 필드를 확인합니다. 로그는 머신이 읽을 수 있는 JSON 형식입니다.
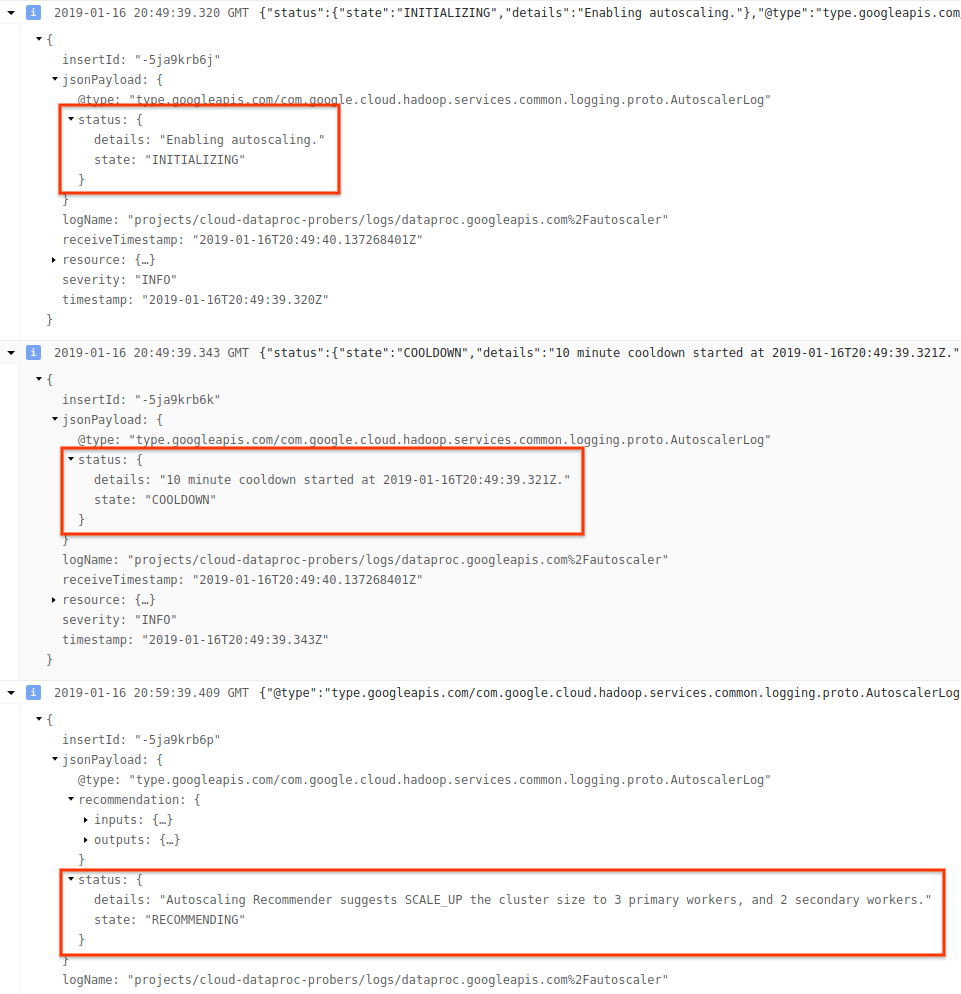
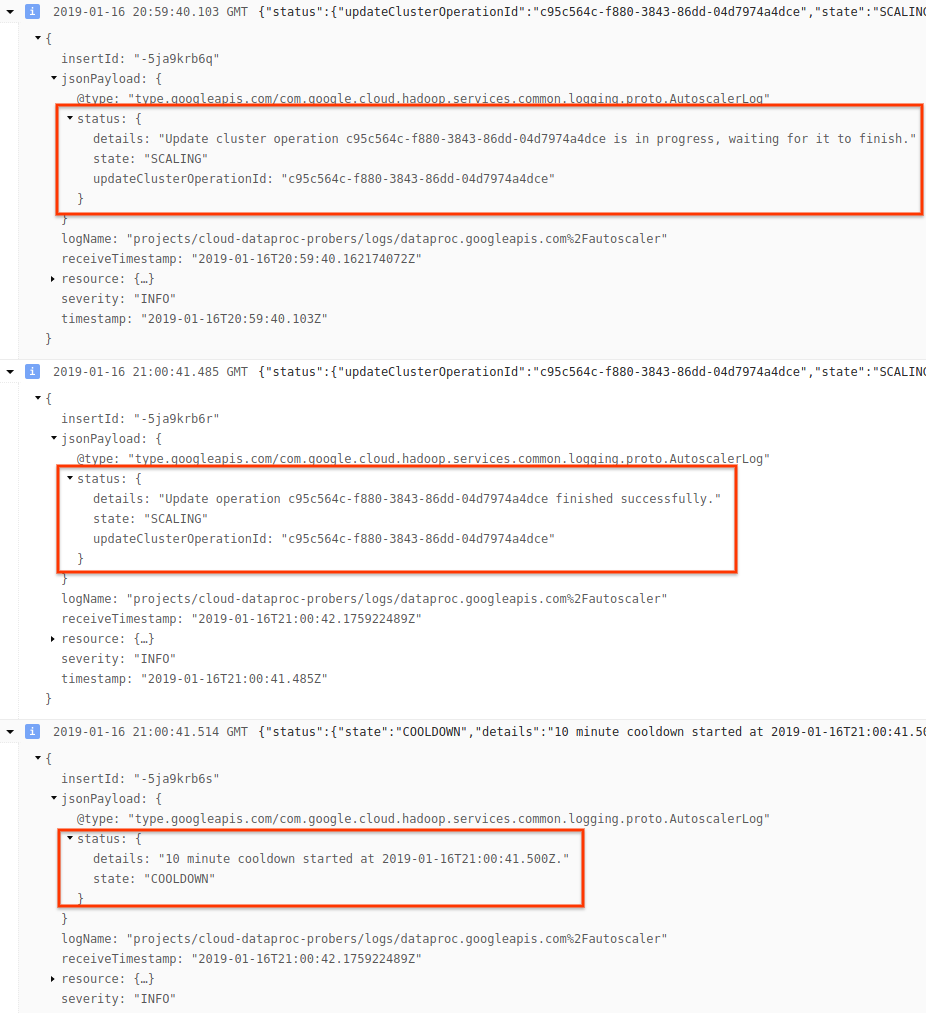
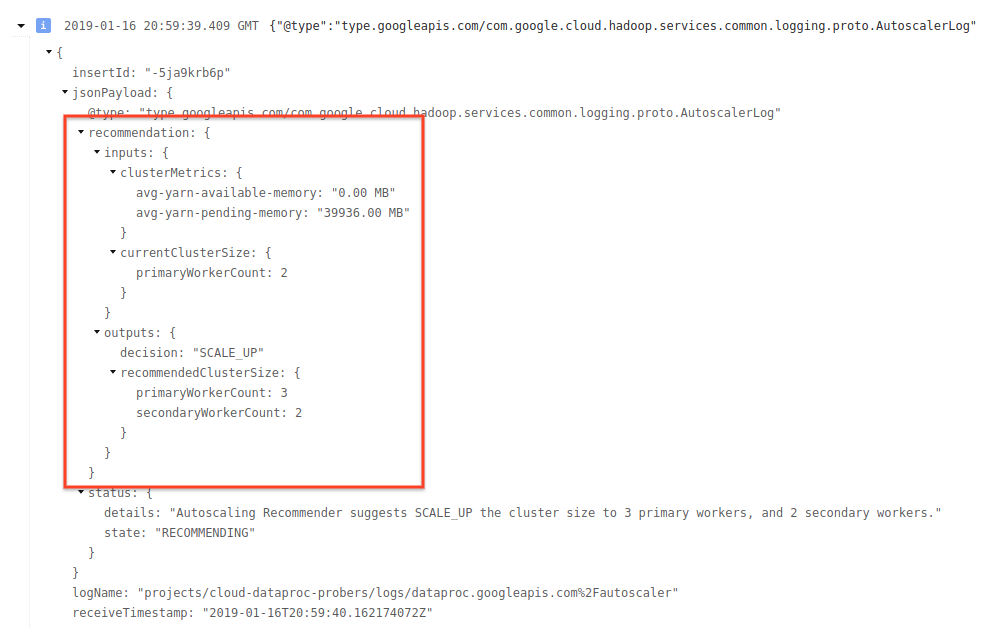
4) 로그 메시지를 펼쳐서 확장 권장사항, 확장 결정에 사용되는 측정항목, 원래 클러스터 크기, 새 대상 클러스터 크기를 확인합니다.
백그라운드: Apache Hadoop 및 Apache Spark로 자동 확장
다음 섹션에서는 자동 확장이 어떻게 Hadoop YARN 및 Hadoop 맵리듀스, Apache Spark, Spark Streaming, Spark Structured Streaming과 상호작용하는지(혹은 하지 않는지) 설명합니다.
Hadoop YARN 측정항목
자동 확장은 다음의 Hadoop YARN 측정항목을 중심으로 이루어집니다.
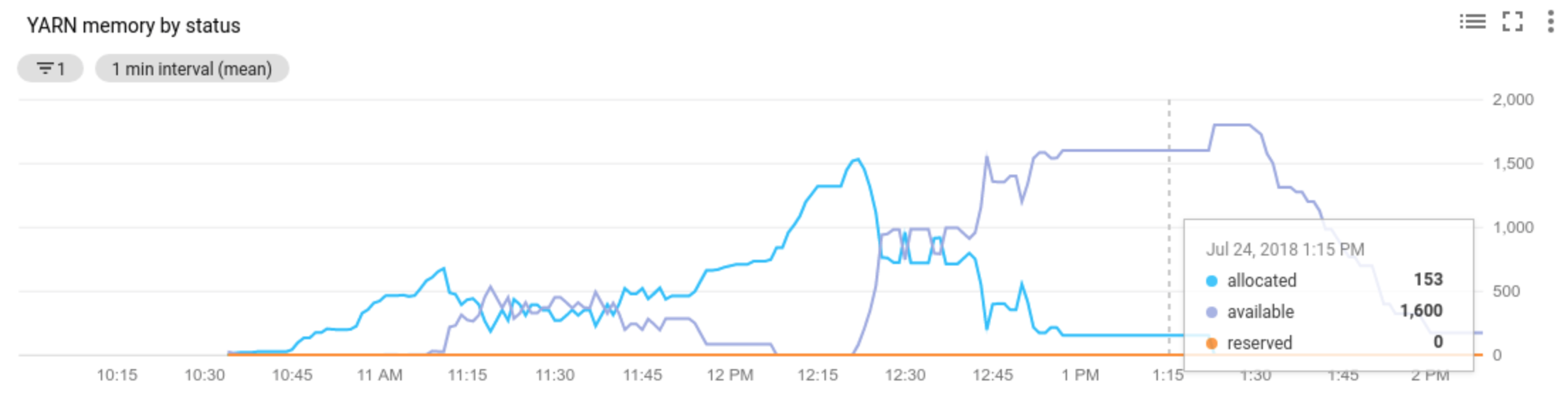
Allocated resource는 전체 클러스터에서 컨테이너를 실행함으로써 소비되는 총 YARN 리소스를 나타냅니다. 최대 1개의 리소스 단위를 사용할 수 있는 컨테이너가 6개 있는 경우에는 할당된 리소스가 6개인 것입니다.Available resource는 클러스터에서 할당된 컨테이너가 사용하지 않는 YARN 리소스입니다. 모든 노드 관리자에 10개의 리소스 단위가 있고 그중 6개가 할당된 경우에는 사용 가능한 리소스가 4개인 것입니다. 클러스터에 사용 가능(미사용) 리소스가 있는 경우, 자동 확장은 클러스터에서 작업자를 삭제할 수 있습니다.Pending resource는 보류 컨테이너를 위한 YARN 리소스 요청 합계입니다. 보류 컨테이너는 공간이 YARN으로 돌아오기를 기다리고 있습니다. 보류 리소스는 사용 가능한 리소스가 0이거나 너무 적어서 다음 컨테이너에 할당할 수 없는 경우에만 0이 아닙니다. 보류 컨테이너가 있으면 자동 확장이 작업자를 클러스터에 추가할 수 있습니다.
Cloud Monitoring에서 이러한 측정항목을 볼 수 있습니다. 기본적으로 YARN 메모리는 클러스터의 총 메모리에 0.8을 곱한 것입니다. 남은 메모리는 페이지 캐시와 같이 다른 데몬 및 운영체제가 사용할 수 있도록 예약됩니다. 기본값을 'yarn.nodemanager.resource.memory-mb 'YARN 구성 설정으로 재정의할 수 있습니다(Apache Hadoop YARN, HDFS, Spark, 관련 속성 참조).
자동 확장 및 Hadoop 맵리듀스
맵리듀스는 각각의 매핑 및 감소 작업을 별도의 YARN 컨테이너로 실행합니다. 작업이 시작될 때 맵리듀스는 각 매핑 작업에 컨테이너 요청을 제출하기 때문에 보류 YARN 메모리가 크게 증가하게 됩니다. 매핑 작업이 완료되면 보류 메모리가 줄어듭니다.
mapreduce.job.reduce.slowstart.completedmaps가 완료될 때(Dataproc에서 기본적으로 95%) 맵리듀스는 모든 감소기의 컨테이너 요청을 큐에 추가하기 때문에 또 다시 보류 메모리가 크게 증가합니다.
매핑 및 감소 작업이 몇 분 걸리는 경우를 제외하고는 자동 확장 scaleUpFactor에 높은 값을 설정하지 마세요. 작업자를 클러스터에 추가하는 데 적어도 1.5분이 걸리기 때문에 몇 분 동안 새 작업자를 활용하기에 충분한 보류 작업이 있는지 확인해야 합니다. 처음에는 scaleUpFactor를 보류 메모리의 0.05(5%) 또는 0.1(10%)로 설정하는 것이 좋습니다.
자동 확장 및 Spark
Spark는 YARN 위에 일정 예약 레이어를 하나 더 추가합니다. 특히 Spark Core의 동적 할당은 YARN에 컨테이너를 요청할 때 Spark 실행자를 실행한 후에 해당 실행자의 스레드에서 Spark 작업을 예약할 수 있게 해줍니다. Dataproc 클러스터는 기본적으로 동적 할당을 사용하기 때문에 필요할 때 실행자가 추가되고 삭제됩니다.
Spark는 항상 YARN에 컨테이너를 요청하지만 동적 할당 없이는 작업이 시작될 때만 컨테이너를 요청할 수 있습니다. 동적 할당을 사용하면 필요할 때 컨테이너를 삭제하고 새 컨테이너를 요청할 수 있습니다.
Spark는 소수의 실행자로 시작됩니다(자동 확장 클러스터에서는 2개). 그리고 백로깅된 작업이 있을 때 계속해서 실행자 수를 두 배로 늘립니다.
이로써 보류 메모리의 변동이 줄어듭니다(보류 메모리 급증 감소). Spark 작업의 경우 자동 확장 scaleUpFactor를 1.0(100%)과 같은 큰 숫자로 설정하는 것이 좋습니다.
Spark 동적 할당 중지
Spark 동적 할당을 활용하지 않는 별도의 Spark 작업을 실행 중인 경우에는 spark.dynamicAllocation.enabled=false 및 spark.executor.instances를 설정함으로써 Spark 동적 할당을 중지할 수 있습니다.
별도의 Spark 작업이 실행되는 동안에도 계속해서 자동 확장을 사용하여 클러스터를 확장하고 축소할 수 있습니다.
캐시된 데이터가 있는 Spark 작업
spark.dynamicAllocation.cachedExecutorIdleTimeout을 설정하거나 더 이상 필요 없는 데이터 세트를 캐시 해제합니다. 기본적으로 Spark는 캐시된 데이터가 있는 실행자를 삭제하지 않으며, 이로 인해 클러스터 축소가 방지됩니다.
자동 확장 및 Spark Streaming
Spark Streaming에는 스트리밍별 신호를 사용하여 실행자를 추가하고 삭제하는 자체적인 버전의 동적 할당이 있기 때문에
spark.streaming.dynamicAllocation.enabled=true를 설정하고,spark.dynamicAllocation.enabled=false를 설정하여 Spark Core의 동적 할당을 사용 중지합니다.Spark Streaming 작업을 통해 단계적 해제(
gracefulDecommissionTimeout자동 확장)를 사용하지 마세요. 대신 자동 확장을 사용하여 작업자를 안전하게 삭제할 수 있도록 내결함성을 위한 체크포인팅을 구성합니다.
또는 Spark Streaming을 자동 확장 없이 사용하려면 다음 단계를 따르세요.
- Spark Core의 동적 할당을 중지합니다(
spark.dynamicAllocation.enabled=false). - 작업에 맞는 실행자 수(
spark.executor.instances)를 설정합니다. 클러스터 속성을 참조하세요.
자동 확장 및 Spark Structured Streaming
Spark Structured Streaming은 동적 할당을 지원하지 않기 때문에(SPARK-24815: Structured Streaming은 동적 할당을 지원해야 함 참조) 자동 확장은 Spark Structured Streaming과 호환되지 않습니다.
파티션 나누기 및 동시 로드를 통해 자동 확장 제어
동시 로드는 일반적으로 클러스터 리소스에 의해 설정되거나 결정되지만(예: HDFS 블록 수에 따라 작업 수가 결정됨) 자동 확장을 사용할 때는 반대가 됩니다. 즉, 자동 확장이 작업 동시 로드에 맞춰 작업자 수를 설정합니다. 다음은 작업 동시 로드를 설정하는 데 도움이 되는 가이드라인입니다.
- Dataproc이 클러스터의 초기 클러스터 크기를 기준으로 맵리듀스 감소 작업의 기본 개수를 설정하지만, 사용자가 직접
mapreduce.job.reduces를 설정하여 감소 단계의 동시 로드 수를 늘릴 수 있습니다. - Spark SQL 및 Dataframe 동시 로드는
spark.sql.shuffle.partitions에 의해 결정됩니다(기본값은 200). - Spark의 RDD 함수는
spark.default.parallelism로 기본 설정되어 작업이 시작될 때 작업자 노드의 코어 수로 설정됩니다. 하지만 shuffle을 생성하는 모든 RDD 함수는 파티션 수로 매개변수를 사용하며, 이 매개변수가spark.default.parallelism을 재정의합니다.
데이터가 균등하게 분할되어야 합니다. 눈에 띌 정도의 데이터 편향이 있으면 하나 이상의 작업이 다른 작업보다 더 오래 걸려서 사용률이 낮아질 수 있습니다.
자동 확장 기본 Spark 및 Hadoop 속성 설정
자동 확장 클러스터에는 기본 작업자가 삭제되거나 보조 작업자가 선점될 때의 작업 오류를 방지하기 위한 기본 클러스터 속성 값이 있습니다. 자동 확장을 사용하여 클러스터를 만들 때 기본값을 재정의할 수 있습니다(클러스터 속성 참조).
작업, 애플리케이션 마스터, 스테이지의 재시도 최대 횟수를 늘리기 위한 기본값:
yarn:yarn.resourcemanager.am.max-attempts=10 mapred:mapreduce.map.maxattempts=10 mapred:mapreduce.reduce.maxattempts=10 spark:spark.task.maxFailures=10 spark:spark.stage.maxConsecutiveAttempts=10
재시도 카운터를 재설정하기 위한 기본값(장기 실행 Spark Streaming 작업에 유용):
spark:spark.yarn.am.attemptFailuresValidityInterval=1h spark:spark.yarn.executor.failuresValidityInterval=1h
Spark의 느린 시작 동적 할당 메커니즘이 작은 크기로 시작되도록 하기 위한 기본값:
spark:spark.executor.instances=2
자주 묻는 질문(FAQ)
이 섹션에는 일반적인 자동 확장 질문과 답변이 포함되어 있습니다.
고가용성 클러스터 및 단일 노드 클러스터에서 자동 확장을 사용할 수 있나요?
고가용성 클러스터에서는 자동 확장을 사용할 수 있지만 단일 노드 클러스터에서는 사용할 수 없습니다(단일 노드 클러스터는 크기 조정을 지원하지 않음).
자동 확장 클러스터의 크기를 수동으로 조절할 수 있나요?
예. 자동 확장 정책을 조정할 때는 임시방편으로 클러스터를 수동으로 조절할 수 있습니다. 하지만 이러한 변경은 일시적으로만 영향을 미치며 결국에는 자동 확장이 클러스터를 다시 조정합니다.
자동 확장 클러스터의 크기를 수동으로 조절하는 대신 다음을 고려해보세요.
자동 확장 정책을 업데이트합니다. 자동 확장 정책 변경 사항은 현재 정책을 사용 중인 모든 클러스터에 적용됩니다.(멀티 클러스터 정책 사용 참조).
정책을 분리하고 클러스터를 원하는 크기로 수동 확장합니다.
Dataproc은 Dataflow 자동 확장과 어떻게 다른가요?
Dataflow 수평 자동 확장 및 Dataflow Prime 수직 자동 확장을 참조하세요.
Dataproc 개발팀이 클러스터 상태를 ERROR에서 RUNNING으로 재설정할 수 있나요?
일반적으로는 불가능합니다. 이렇게 하려면 클러스터의 상태를 재설정하는 것이 안전한지 확인해야 하고 HDFS NameNode 재시작과 같은 다른 수동 단계 없이는 클러스터를 재설정할 수 없는 경우가 많습니다.
실패한 작업 이후 클러스터 상태를 확인할 수 없는 경우 Dataproc은 클러스터 상태를 ERROR로 설정합니다. ERROR의 클러스터는 자동 확장되지 않습니다. 일반적인 원인은 다음과 같습니다.
종종 Compute Engine 중단 중에 발생하는 Compute Engine API에서 반환된 오류
HDFS 해제의 버그로 인해 손상된 상태로 전환된 HDFS
'Task lease expired'와 같은 Dataproc Control API 오류
상태가 ERROR인 클러스터를 삭제하고 다시 만듭니다.
자동 확장은 언제 축소 작업을 취소하나요?
다음 그래픽은 자동 확장에서 축소 작업이 취소되는 경우를 보여줍니다(자동 확장 작동 방식도 참조하세요).
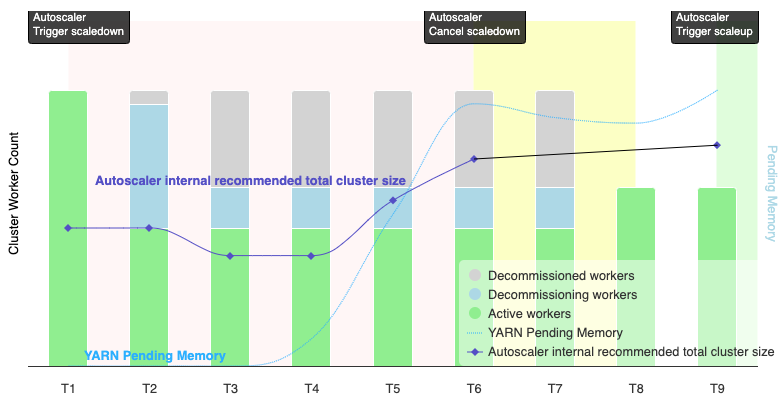
참고:
- 클러스터에 YARN 메모리 측정항목에 따라 자동 확장이 사용 설정되었습니다(기본값).
- T1-T9는 자동 확장 처리가 작업자 수를 평가할 때 대기 시간을 나타냅니다(이벤트 타이밍이 간소화됨).
- 누적 막대는 활성, 사용 중단, 사용 중단된 클러스터 YARN 작업자 수를 나타냅니다.
- 자동 확장 처리의 권장 작업자 수(검은 줄)는 YARN 메모리 측정항목, YARN 활성 작업자 수, 자동 확장 정책 설정을 기반으로 합니다 (자동 확장 작동 방법 참조).
- 빨간색 배경 영역은 축소 작업이 실행되는 기간을 나타냅니다.
- 노란색 배경 영역은 축소 작업이 취소되는 기간을 나타냅니다.
- 녹색 배경 영역은 확장 작업 기간을 나타냅니다.
다음 작업은 다음 시간에 수행됩니다.
T1: 자동 확장 처리가 단계적 해제 축소 작업을 시작하여 현재 클러스터 작업자의 약 절반을 축소합니다.
T2: 자동 확장 처리가 클러스터 측정항목을 계속 모니터링합니다. 축소 권장사항은 변경되지 않으며 축소 작업이 계속됩니다. 일부 작업자는 사용 중단되었고 다른 작업자는 사용 중단되는 중입니다(Dataproc은 사용 중단된 작업자를 삭제함).
T3: 자동 확장 처리는 추가 YARN 메모리를 사용할 수 있게 되어 작업자 수를 더 축소할 수 있다고 계산합니다. 하지만 활성 작업자 수와 권장 작업자 수 변화의 합계는 활성 작업자 수와 사용 중단 작업자 수를 합한 값보다 크거나 같지 않으므로 축소 취소 기준을 충족하지 않으며 자동 확장 처리가 축소 작업을 취소하지 않습니다.
T4: YARN이 보류 메모리 증가를 보고합니다. 하지만 자동 확장 처리는 작업자 수 권장사항을 변경하지 않습니다. T3와 마찬가지로 축소 취소 기준이 충족되지 않는 상태로 유지되며 자동 확장 처리가 축소 작업을 취소하지 않습니다.
T5: YARN 보류 메모리가 증가하고 자동 확장 처리에서 권장되는 작업자 수 변경이 늘어납니다. 하지만 활성 작업자 수와 권장 작업자 수 변화의 합계는 활성 작업자 수와 사용 중단 작업자 수를 합한 값보다 작으므로 여전히 축소 취소 기준을 충족하지 않으며 축소 작업은 취소되지 않습니다.
T6: YARN 대기 중인 메모리가 더 증가합니다. 활성 작업자 수와 자동 확장 처리에서 권장하는 작업자 수 변화의 합계는 이제 활성 작업자 수와 사용 중단 작업자 수를 합한 값보다 큽니다. 취소 기준이 충족되어 자동 확장 처리가 축소 작업을 취소합니다.
T7: 자동 확장 처리가 축소 작업 취소가 완료될 때까지 기다립니다. 자동 확장 처리는 이 간격 동안 작업자 수를 평가하고 변경을 권장하지 않는 것이 좋습니다.
T8: 축소 작업 취소가 완료됩니다. 사용 중단 작업자가 클러스터에 추가되고 활성 상태가 됩니다. 자동 확장 처리는 축소 작업 취소를 감지하고 다음 평가 기간(T9)까지 대기한 후 권장 작업자 수를 계산합니다.
T9: T9 시간에는 활성 작업이 없습니다. 자동 확장 처리는 자동 확장 정책 및 YARN 측정항목을 기반으로 확장 작업을 권장합니다.