Was ist Autoscaling?
Das Schätzen der "richtigen" Anzahl von Cluster-Workern (Knoten) für eine Arbeitslast ist schwierig und eine einzelne Clustergröße für eine gesamte Pipeline ist oft nicht ideal. Vom Nutzer initiierte Cluster-Skalierung wird diese Herausforderung teilweise gelöst, erfordert jedoch die Überwachung der Clusternutzung und ein manuelles Eingreifen.
Die Dataproc AutoscalingPolicies API bietet einen Mechanismus zur Automatisierung der Clusterressourcenverwaltung und ermöglicht das Autoscaling von Cluster-Worker-VMs. Eine Autoscaling Policy ist eine wiederverwendbare Konfiguration, die beschreibt, wie Cluster-Worker mit der Autoscaling-Richtlinie skalieren sollen. Sie definiert Skalierungsgrenzen, Häufigkeit und Aggressivität, um eine detaillierte Kontrolle über Clusterressourcen während der gesamten Clusterlebensdauer zu ermöglichen.
Einsatzmöglichkeiten für Autoscaling
Verwenden Sie Autoscaling:
bei Clustern, die Daten in externen Diensten speichern, wie z. B. Cloud Storage oder BigQuery
bei Clustern, die viele Jobs verarbeiten
um einzelne Jobcluster zu skalieren
mit dem Enhanced Flexibility Mode für Spark-Batch-Jobs
Autoscaling wird nicht empfohlen bei/für:
HDFS: Autoscaling ist nicht für die Skalierung von HDFS im Cluster vorgesehen, weil:
- Die HDFS-Nutzung ist kein Signal für das Autoscaling.
- HDFS-Daten werden nur auf primären Workern gehostet. Die Anzahl der primären Worker muss ausreichen, um alle HDFS-Daten zu hosten.
- Durch die Außerbetriebnahme von HDFS-DataNodes kann das Entfernen von Workern verzögert werden. Datenknoten kopieren HDFS-Blöcke in andere Datenknoten, bevor ein Worker entfernt wird. Je nach Datengröße und Replikationsfaktor kann dieser Vorgang Stunden dauern.
YARN-Knotenlabels:Autoscaling unterstützt keine YARN-Knotenlabels und das Attribut
dataproc:am.primary_onlyaufgrund von YARN-9088. YARN meldet Clustermesswerte nicht, wenn Knotenlabels verwendet werden.Spark Structured Streaming:Autoscaling unterstützt kein Spark Structured Streaming. Weitere Informationen finden Sie unter Autoscaling und Spark Structured Streaming.
Inaktive Cluster: Autoscaling eignet sich nicht zum Herunterskalieren eines Clusters auf die Mindestgröße, wenn der Cluster inaktiv ist. Da das Erstellen eines neuen Clusters genauso schnell geht wie das Ändern seiner Größe, ist es sinnvoller, inaktive Cluster stattdessen zu löschen und neu zu erstellen. Folgende Tools unterstützen dieses "ephemerische" Modell:
Verwenden Sie Dataproc-Workflows, um einen Satz von Jobs in einem dedizierten Cluster zu planen. Löschen Sie den Cluster, wenn die Jobs abgeschlossen sind. Verwenden Sie für eine bessere Orchestrierung Cloud Composer, einen Dienst, der auf Apache Airflow basiert.
Verwenden Sie für Cluster, die Ad-hoc-Abfragen oder extern geplante Arbeitslasten verarbeiten, Cluster Scheduled Deletion, um den Cluster nach einer bestimmten Dauer oder Zeit der Inaktivität bzw. zu einem bestimmten Zeitpunkt zu löschen.
Arbeitslasten unterschiedlicher Größe:Wenn kleine und große Jobs in einem Cluster ausgeführt werden, wird beim Herunterskalieren durch ordnungsgemäße Außerbetriebnahme gewartet, bis die großen Jobs abgeschlossen sind. Das Ergebnis ist, dass ein lang andauernder Job das Autoscaling von Ressourcen für kleinere Jobs, die im Cluster ausgeführt werden, verzögert, bis der lang andauernde Job abgeschlossen ist. Um dieses Ergebnis zu vermeiden, sollten Sie kleinere Jobs mit ähnlicher Größe in einem Cluster zusammenfassen und jeden Job mit langer Ausführungszeit in einem separaten Cluster isolieren.
Automatische Skalierung aktivieren
So aktivieren Sie Autoscaling in einem Cluster:
Entweder:
Autoscaling-Richtlinie erstellen
gcloud-CLI
Sie können eine Autoscaling-Richtlinie mit dem Befehl gcloud dataproc autoscaling-policies import erstellen. Sie liest eine lokale YAML-Datei, die eine Autoscaling-Richtlinie definiert. Das Format und der Inhalt der Datei müssen den Konfigurationsobjekten und Feldern entsprechen, die von der REST API autoscalingPolicies definiert sind.
Im folgenden YAML-Beispiel wird eine Richtlinie für Dataproc-Standardcluster mit allen erforderlichen Feldern definiert. Außerdem werden die Werte minInstances und maxInstances für die primären Worker und der Wert maxInstances für die sekundären (abrufbaren) Worker angegeben und eine 4-minütige cooldownPeriod festgelegt (der Standardwert ist 2 Minuten). workerConfig konfiguriert die primären Worker. In diesem Beispiel werden minInstances und maxInstances auf denselben Wert gesetzt, um die Skalierung der primären Worker zu vermeiden.
workerConfig:
minInstances: 10
maxInstances: 10
secondaryWorkerConfig:
maxInstances: 50
basicAlgorithm:
cooldownPeriod: 4m
yarnConfig:
scaleUpFactor: 0.05
scaleDownFactor: 1.0
gracefulDecommissionTimeout: 1h
Im folgenden YAML-Beispiel wird eine Richtlinie für Dataproc-Standardcluster mit allen erforderlichen und optionalen Feldern der Autoscaling-Richtlinie definiert.
clusterType: STANDARD
workerConfig:
minInstances: 10
maxInstances: 10
weight: 1
secondaryWorkerConfig:
minInstances: 0
maxInstances: 100
weight: 1
basicAlgorithm:
cooldownPeriod: 2m
yarnConfig:
scaleUpFactor: 0.05
scaleDownFactor: 1.0
scaleUpMinWorkerFraction: 0.0
scaleDownMinWorkerFraction: 0.0
gracefulDecommissionTimeout: 1h
Im folgenden YAML-Beispiel wird eine Richtlinie für Cluster mit null Instanzen definiert.
Bei Clustern ohne Skalierung geben SieworkerConfig nicht an.
clusterType: ZERO_SCALE
secondaryWorkerConfig:
minInstances: 0
maxInstances: 100
weight: 1
basicAlgorithm:
cooldownPeriod: 2m
yarnConfig:
scaleUpFactor: 0.05
scaleDownFactor: 1.0
scaleUpMinWorkerFraction: 0.0
scaleDownMinWorkerFraction: 0.0
gracefulDecommissionTimeout: 1h
Führen Sie zum Erstellen der Autoscaling-Richtlinie den folgenden gcloud-Befehl über ein lokales Terminal oder in Cloud Shell aus. Benennen Sie die Richtlinie. Dieser Name wird zur Richtlinie id, die Sie in späteren gcloud-Befehlen verwenden können, um auf die Richtlinie zu verweisen. Verwenden Sie das Flag --source, um den lokalen Pfad und den Dateinamen der YAML-Datei der Autoscaling-Richtlinie anzugeben, die importiert werden soll.
gcloud dataproc autoscaling-policies import policy-name \ --source=filepath/filename.yaml \ --region=region
REST API
Erstellen Sie eine Autoscaling-Richtlinie, indem Sie eine AutoscalingPolicy als Teil einer autoscalingPolicies.create-Anfrage definieren.
Console
Wählen Sie zum Erstellen einer Autoscaling-Richtlinie in der Google Cloud console auf der Dataproc-Seite Autoscaling-Richtlinien die Option CREATE POLICY aus. Auf der Seite Richtlinie erstellen können Sie ein Steuerfeld mit Richtlinienempfehlungen auswählen, um die Felder für die Autoscaling-Richtlinie für einen bestimmten Jobtyp oder ein Skalierungsziel auszufüllen.
Autoscaling-Cluster erstellen
Nachdem Sie eine Autoscaling-Richtlinie erstellt haben, erstellen Sie einen Cluster, der die Autoscaling-Richtlinie verwendet. Der Cluster muss sich in derselben Region wie die Autoscaling-Richtlinie befinden.
gcloud-CLI
Führen Sie den folgenden gcloud-Befehl über ein lokales Terminal oder in Cloud Shell aus, um einen Autoscaling-Cluster zu erstellen. Geben Sie einen Namen für den Cluster an und verwenden Sie das Flag --autoscaling-policy, um policy ID (den Namen der Richtlinie, den Sie beim Erstellen der Richtlinie angegeben haben) oder die Richtlinie resource URI (resource name) (siehe die Felder AutoscalingPolicy id und name) anzugeben.
gcloud dataproc clusters create cluster-name \ --autoscaling-policy=policy id or resource URI \ --region=region
REST API
Erstellen Sie einen Autoscaling-Cluster, indem Sie AutoscalingConfig als Teil einer clusters.create-Anfrage hinzufügen.
Console
Sie können eine vorhandene Autoscaling-Richtlinie für die Anwendung auf einen neuen Cluster aus dem Abschnitt „Autoscaling-Richtlinie“ im Bereich „Cluster einrichten“ auf der Seite Cluster erstellen auf der Seite „Dataproc“ der Google Cloud Console auswählen.
Autoscaling für einen vorhandenen Cluster aktivieren
Nach dem Erstellen einer Autoscaling-Richtlinie können Sie die Richtlinie für einen vorhandenen Cluster in derselben Region aktivieren.
gcloud-CLI
Führen Sie den folgenden gcloud-Befehl von einem lokalen Terminal oder in Cloud Shell aus, um eine Autoscaling-Richtlinie für einen vorhandenen Cluster zu aktivieren. Geben Sie einen Namen für den Cluster an und verwenden Sie das Flag --autoscaling-policy, um policy ID (den Namen der Richtlinie, den Sie beim Erstellen der Richtlinie angegeben haben) oder die Richtlinie resource URI (resource name) (siehe die AutoscalingPolicy-Felder id und name) anzugeben.
gcloud dataproc clusters update cluster-name \ --autoscaling-policy=policy id or resource URI \ --region=region
REST API
Um eine Autoscaling-Richtlinie für einen vorhandenen Cluster zu aktivieren, legen Sie den AutoscalingConfig.policyUri der Richtlinie in der updateMask einer clusters.patch-Anfrage fest.
Console
Das Aktivieren einer Autoscaling-Richtlinie für einen vorhandenen Cluster wird in der Google Cloud Konsole nicht unterstützt.
Multi-Cluster-Richtlinien verwenden
Eine Autoscaling-Richtlinie definiert das Skalierungsverhalten, das auf mehrere Cluster angewendet werden kann. Autoscaling-Richtlinien lassen sich am besten für mehrere Cluster anwenden, wenn die Cluster ähnliche Arbeitslasten gemeinsam verwenden oder Jobs mit ähnlichen Ressourcennutzungsmustern ausführen.
Sie können eine Richtlinie aktualisieren, die von mehreren Clustern verwendet wird. Die Aktualisierungen wirken sich sofort auf das Autoscaling-Verhalten aller Cluster aus, die die Richtlinie verwenden (siehe autoscalingPolicies.update). Wenn Sie nicht möchten, dass eine Richtlinienaktualisierung auf einen Cluster angewendet wird, der die Richtlinie verwendet, deaktivieren Sie das Autoscaling auf dem Cluster, bevor Sie die Richtlinie aktualisieren.
gcloud-CLI
Führen Sie den folgenden gcloud-Befehl in einem lokalen Terminal oder in Cloud Shell aus, um das Autoscaling in einem Cluster zu deaktivieren.
gcloud dataproc clusters update cluster-name --disable-autoscaling \ --region=region
REST API
Um Autoscaling auf einem Cluster zu deaktivieren, setzen Sie AutoscalingConfig.policyUri auf den leeren String und legen Sie update_mask=config.autoscaling_config.policy_uri in einer clusters.patch-Anfrage fest.
Console
Das Deaktivieren von Autoscaling in einem Cluster wird in der Google Cloud -Konsole nicht unterstützt.
- Eine Richtlinie, die von einem oder mehreren Clustern verwendet wird, kann nicht gelöscht werden (siehe autoscalingPolicies.delete).
Funktionsweise von Autoscaling
Beim Autoscaling werden die Hadoop-YARN-Messwerte des Clusters während jeder "Cooldown-Zeit" überprüft, um festzustellen, ob der Cluster skaliert werden soll und, wenn ja, in welchem Umfang.
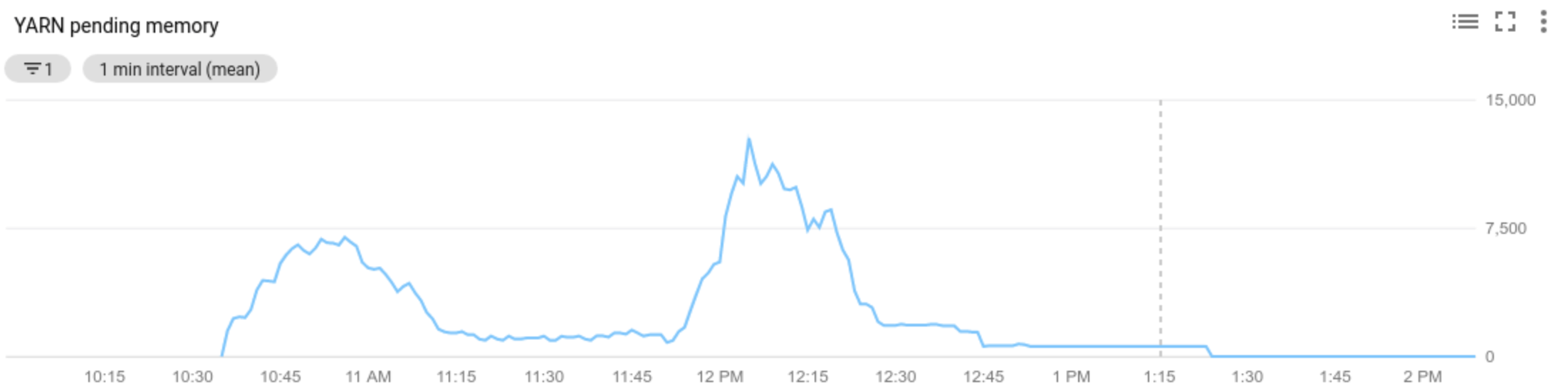
Der Wert des Messwerts für ausstehende YARN-Ressourcen („Pending Memory“ oder „Pending Cores“) bestimmt, ob skaliert wird. Ein Wert über
0gibt an, dass YARN-Jobs auf Ressourcen warten und möglicherweise eine Aufskalierung erforderlich ist. Ein0-Wert gibt an, dass YARN über genügend Ressourcen verfügt, sodass möglicherweise keine Skalierung oder andere Änderungen erforderlich sind.Wenn die ausstehende Ressource > 0 ist:
$estimated\_worker\_count =$
\[ \Biggl \lceil AVERAGE\ during\ cooldown\ period\Big(\frac{Pending + Available + Allocated + Reserved}{Resource\ per\ worker}\Big)\Biggr \rceil \]
Wenn die Anzahl der ausstehenden Ressourcen 0 ist:
$estimated\_worker\_count =$
\[ \Biggl \lceil AVERAGE\ during\ cooldown\ period\Big(\frac{Allocated + Reserved}{Resource\ per\ worker}\Big)\Biggr \rceil \]
Ab Dataproc-Image 2.2 überwacht der Autoscaler standardmäßig den YARN-Arbeitsspeicher und die YARN-Cores, sodass
estimated_worker_countseparat für Arbeitsspeicher und Cores ausgewertet wird und die resultierende höhere Anzahl von Workern ausgewählt wird. Bei früheren Image-Versionen überwacht der Autoscaler nur den YARN-Arbeitsspeicher, sofern Sie nicht kernbasiertes Autoscaling aktivieren.$estimated\_worker\_count =$
\[ max(estimated\_worker\_count\_by\_memory,\ estimated\_worker\_count\_by\_cores) \]
\[ estimated\ \Delta worker = estimated\_worker\_count - current\_worker\_count \]
Je nach geschätzter Änderung der Anzahl der Worker verwendet Autoscaling einen
scaleUpFactoroderscaleDownFactor, um die erforderliche Änderung an der Anzahl der Worker zu berechnen:if estimated Δworkers > 0: actual Δworkers = ROUND_UP(estimated Δworkers * scaleUpFactor) # examples: # ROUND_UP(estimated Δworkers=5 * scaleUpFactor=0.5) = 3 # ROUND_UP(estimated Δworkers=0.8 * scaleUpFactor=0.5) = 1 else: actual Δworkers = ROUND_DOWN(estimated Δworkers * scaleDownFactor) # examples: # ROUND_DOWN(estimated Δworkers=-5 * scaleDownFactor=0.5) = -2 # ROUND_DOWN(estimated Δworkers=-0.8 * scaleDownFactor=0.5) = 0 # ROUND_DOWN(estimated Δworkers=-1.5 * scaleDownFactor=0.5) = 0
Ein scaleUpFactor oder ein scaleDownFactor von 1,0 bedeutet, dass das Autoscaling so skaliert wird, dass die ausstehende oder verfügbare Ressource 0 ist (perfekte Auslastung).
Sobald die Änderung an der Anzahl der Worker berechnet wurde, fungiert entweder
scaleUpMinWorkerFractionundscaleDownMinWorkerFractionals Schwellenwert, um festzustellen, ob Autoscaling den Cluster skaliert. Ein niedriger Wert bedeutet, dass Autoscaling auch dann skalieren sollte, wennΔworkersklein ist. Ein größerer Wert bedeutet, dass nur skaliert werden soll, wennΔworkersgroß ist.IF (Δworkers > scaleUpMinWorkerFraction * current_worker_count) then scale up
IF (abs(Δworkers) > scaleDownMinWorkerFraction * current_worker_count), THEN scale down.
Wenn die Anzahl der zu skalierenden Worker groß genug ist, um eine Skalierung auszulösen, verwendet Autoscaling die
minInstances/maxInstances-Grenzen vonworkerConfigundsecondaryWorkerConfigundweight(Verhältnis von primären zu sekundären Workern), um zu bestimmen, wie die Anzahl der Worker auf die primären und sekundären Worker-Instanzgruppen aufgeteilt werden soll. Das Ergebnis dieser Berechnungen ist die endgültige Änderung des Clusters, die das Autoscaling in diesem Skalierungszeitraum vornimmt.Anfragen zum Herunterskalieren der Autoskalierung werden für Cluster, die mit den Image-Versionen 2.0.57+, 2.1.5+ und späteren Image-Versionen erstellt wurden, abgebrochen, wenn:
- eine Herunterskalierung mit einem Graceful-Decommissioning-Zeitlimitwert ungleich null läuft und
Die Anzahl der AKTIVEN YARN-Worker („aktive Worker“) plus die vom Autoscaler empfohlene Änderung der Gesamtzahl der Worker (
Δworkers) entspricht mindestensDECOMMISSIONINGYARN-Workern („Außerbetriebsetzung von Workern“), wie in der folgenden Formel dargestellt:IF (active workers + Δworkers ≥ active workers + decommissioning workers) THEN cancel the scaledown operation
Ein Beispiel für das Abbrechen einer Herunterskalierung finden Sie unter Wann wird eine Herunterskalierung durch Autoscaling abgebrochen?.
Empfehlungen für die Autoscaling-Konfiguration
Dieser Abschnitt enthält Empfehlungen zur Konfiguration von Autoscaling.
Primäre Worker nicht skalieren
HDFS-Datenknoten werden von primären Workern ausgeführt, sekundäre Worker dagegen nur Computing-Worker.
Durch die Verwendung sekundärer Worker können Sie Rechenressourcen effizient skalieren, ohne Speicher bereitstellen zu müssen. Das führt zu schnelleren Skalierungsfunktionen.
HDFS-NameNodes können mehrere Race-Bedingungen haben, die dazu führen, dass HDFS beschädigt wird und die Außerbetriebnahme auf unbestimmte Zeit hängen bleibt. Um dieses Problem zu vermeiden, sollten Sie keine primären Worker skalieren. Beispiel: none
workerConfig:
minInstances: 10
maxInstances: 10
secondaryWorkerConfig:
minInstances: 0
maxInstances: 100
Am Befehl zur Cluster-Erstellung müssen Sie einige Änderungen vornehmen:
- Legen Sie
--num-workers=10fest, um die Größe der primären Workergruppe der Autoscaling-Richtlinie anzupassen. - Legen Sie
--secondary-worker-type=non-preemptiblefest, um sekundäre Worker als nicht abrufbar zu konfigurieren. (Es sei denn, dass VMs auf Abruf erwünscht sind). - Kopieren Sie die Hardwarekonfiguration von primären Worker auf sekundäre Worker. Legen Sie beispielsweise
--secondary-worker-boot-disk-size=1000GBauf--worker-boot-disk-size=1000GBfest.
Verwenden Sie den Enhanced Flexibility Mode für Spark-Batchjobs
Mit dem Enhanced Flexibility Mode (EFM) und Autoscaling können Sie:
ermöglicht eine schnellere Herunterskalierung des Clusters während der Ausführung von Jobs.
Unterbrechungen laufender Jobs aufgrund des Herunterskalierens von Clustern verhindern
Unterbrechungen laufender Jobs aufgrund des Präemptierens von sekundären Workern auf Abruf minimieren
Wenn EFM aktiviert ist, muss das Zeitlimit für die ordnungsgemäße Außerbetriebnahme der Autoscaling-Richtlinie auf 0s gesetzt werden. Die Autoscaling-Richtlinie darf nur sekundäre Worker automatisch skalieren.
Zeitlimit für ordnungsgemäße Außerbetriebnahme auswählen
Autoscaling unterstützt die ordnungsgemäße Außerbetriebnahme von YARN, wenn Knoten aus einem Cluster entfernt werden. Die ordnungsgemäße Außerbetriebnahme ermöglicht es Anwendungen, nach dem Zufallsprinzip Teil der Daten zwischen den Phasen zu verschieben, um den Rückschrittfortschritt zu vermeiden. Das Zeitlimit für die ordnungsgemäße Außerbetriebnahme in einer Autoscaling-Richtlinie ist die Obergrenze des Zeitraums, den YARN auf das Ausführen von Anwendungen wartet (Anwendung, die beim Start der Außerbetriebnahme ausgeführt wurde), bevor Knoten entfernt werden.
Wenn ein Prozess nicht innerhalb des angegebenen Zeitlimits für die ordnungsgemäße Außerbetriebnahme abgeschlossen wird, wird der Worker-Knoten zwangsweise heruntergefahren, was möglicherweise zu Datenverlust oder Dienstunterbrechungen führt. Um diese Möglichkeit zu vermeiden, legen Sie das Zeitlimit für die ordnungsgemäße Außerbetriebnahme auf einen Wert fest, der länger ist als der längste Job, den der Cluster verarbeitet. Wenn Sie beispielsweise erwarten, dass Ihr längster Job eine Stunde lang ausgeführt wird, legen Sie das Zeitlimit auf mindestens eine Stunde (1h) fest.
Erwägen Sie Jobs, die länger als eine Stunde dauern, zu ihren eigenen sitzungsspezifischen Clustern zu migrieren und so eine ordnungsgemäße Außerbetriebnahme zu vermeiden.
scaleUpFactor festlegen
scaleUpFactor steuert, wie intensiv das Autoscaling einen Cluster hochskaliert.
Geben Sie eine Zahl zwischen 0.0 und 1.0 an, um den Bruchteilswert der ausstehenden YARN-Ressource festzulegen, der das Hinzufügen von Knoten verursacht.
Wenn es beispielsweise 100 ausstehende Container gibt, die jeweils 512 MB anfordern, gibt es 50 GB ausstehender YARN-Speicher. Wenn „scaleUpFactor” 0.5 ist, fügt das Autoscaling genügend Knoten hinzu, um 25 GB YARN-Speicher hinzuzufügen. Wenn 0.1 hingegen gleich ist, fügt das Autoscaling genügend Knoten für 5 GB hinzu. Beachten Sie, dass diese Werte dem YARN-Speicher entsprechen, nicht dem Gesamtspeicher, der für eine VM verfügbar ist.
Ein guter Ausgangspunkt ist 0.05 für MapReduce-Jobs und Spark-Jobs mit aktivierter dynamischer Zuweisung. Verwenden Sie für Spark-Jobs mit einer festen Executor-Anzahl und Tez-Jobs 1.0. Ein scaleUpFactor von 1.0 bedeutet, dass das Autoscaling so skaliert wird, dass die ausstehende oder verfügbare Ressource 0 ist (perfekte Auslastung).
Einstellen von scaleDownFactor
scaleDownFactor steuert, wie intensiv das Autoscaling einen Cluster herunterskaliert. Geben Sie eine Zahl zwischen 0.0 und 1.0 an, um den Bruchteilswert der verfügbaren YARN-Ressource festzulegen, der das Entfernen von Knoten verursacht.
Belassen Sie diesen Wert für die meisten Multi-Job-Cluster, die häufig hoch- und herunterskaliert werden müssen, auf 1.0. Aufgrund der ordnungsgemäßen Außerbetriebnahme sind die Vorgänge zum Herunterskalieren wesentlich langsamer als die Vorgänge zum Hochskalieren. Mit scaleDownFactor=1.0 wird eine aggressive Skalierungsrate nach unten festgelegt, wodurch die Anzahl der Skalierungsvorgänge reduziert wird, die erforderlich sind, um die richtige Clustergröße zu erzielen.
Für Cluster, die mehr Stabilität benötigen, legen Sie einen niedrigeren scaleDownFactor fest, um die Rate für das Herunterskalieren zu verlangsamen.
Setzen Sie diesen Wert auf 0.0, um die Herunterskalierung des Clusters zu verhindern, z. B. bei Verwendung von sitzungsspezifischen oder einzelnen Jobclustern.
scaleUpMinWorkerFraction und scaleDownMinWorkerFraction festlegen
scaleUpMinWorkerFraction und scaleDownMinWorkerFraction werden mit scaleUpFactor oder scaleDownFactor verwendet und haben Standardwerte von 0.0. Sie stellen die Schwellenwerte dar, mit denen Autoscaling den Cluster vertikal oder herunterskaliert: die minimale fraktionale Erhöhung oder Verringerung der Clustergröße, die zum Senden von Auf- oder Herunterskalierungsanfragen erforderlich ist.
Beispiele: Das Autoscaling gibt keine Aktualisierungsanfrage zum Hinzufügen von 5 Workern zu einem 100-Knoten-Cluster aus, es sei denn, scaleUpMinWorkerFraction ist kleiner oder gleich 0.05 (5%). Wenn der Wert auf 0.1 festgelegt ist, gibt Autoscaler die Anfrage zum Hochskalieren des Clusters nicht aus.
Wenn scaleDownMinWorkerFraction auf 0.05 gesetzt ist, führt das Autoscaling nur dann eine Aktualisierung durch, wenn mindestens fünf Knoten entfernt werden müssen.
Der Standardwert von 0.0 gibt keinen Grenzwert an.
Das Festlegen höherer scaleDownMinWorkerFractionthresholds für große Cluster (> 100 Knoten), um kleine, unnötige Skalierungsvorgänge zu vermeiden, wird dringend empfohlen.
Cooldown-Zeit auswählen
Mit cooldownPeriod wird ein Zeitraum festgelegt, in dem der Autoscaler keine Anfragen zum Ändern der Clustergröße stellt. Damit können Sie die Häufigkeit von Autoscaler-Änderungen an der Clustergröße begrenzen.
Der Mindest- und Standardwert für cooldownPeriod beträgt zwei Minuten. Wenn in einer Richtlinie eine kürzere cooldownPeriod festgelegt ist, wirken sich Änderungen der Arbeitslast schneller auf die Clustergröße aus, aber Cluster können unnötigerweise vertikal oder horizontal skaliert werden. Es wird empfohlen, scaleUpMinWorkerFraction und scaleDownMinWorkerFraction einer Richtlinie auf einen Wert ungleich Null zu setzen, wenn eine kürzere cooldownPeriod verwendet wird. Dadurch wird sichergestellt, dass der Cluster nur dann hoch- oder herunterskaliert wird, wenn die Änderung der Ressourcenauslastung für eine Clusteraktualisierung ausreicht.
Wenn Ihre Arbeitslast empfindlich auf Änderungen der Clustergröße reagiert, können Sie den Zeitraum für die Auskühlung verlängern. Wenn Sie beispielsweise einen Batchverarbeitungsjob ausführen, können Sie den Inaktivitätszeitraum auf 10 Minuten oder mehr festlegen. Experimentieren Sie mit verschiedenen Zeiträumen, um den Wert zu finden, der am besten für Ihre Arbeitslast geeignet ist.
Zählgrenzen und Gruppengewicht der Worker
Jede Worker-Gruppe hat minInstances und maxInstances, die ein festes Limit für die Größe jeder Gruppe konfigurieren.
Jede Gruppe hat außerdem einen Parameter namens weight, der das Zielsaldo zwischen den beiden Gruppen konfiguriert. Beachten Sie, dass dieser Parameter nur ein Hinweis ist. Wenn eine Gruppe die Mindest- oder Höchstgröße erreicht, werden Knoten nur der anderen Gruppe hinzugefügt oder daraus entfernt. Daher kann weight fast immer standardmäßig auf 1 bleiben.
Autoscaling auf Grundlage von Kernen verwenden
Für CPU-intensive Anwendungen empfiehlt es sich, den Dominant Resource Calculator für die Ressourcenzuweisung zu verwenden. Dies ist die standardmäßige YARN-Konfiguration ab Dataproc-Image-Version 2.2. Bei früheren Image-Versionen konfiguriert Dataproc YARN für die Verwendung von Arbeitsspeicher-Messwerten für die Ressourcenbereitstellung, sofern Sie beim Erstellen eines Clusters nicht das folgende Attribut festlegen, um YARN für die Verwendung des Dominant Resource Calculator zu konfigurieren:
capacity-scheduler:yarn.scheduler.capacity.resource-calculator=org.apache.hadoop.yarn.util.resource.DominantResourceCalculator
Autoscaling-Messwerte und -Logs
Mit den folgenden Ressourcen und Tools können Sie Autoscaling-Vorgänge und deren Auswirkungen auf einen Cluster und seine Jobs überwachen.
Cloud Monitoring
Mit Cloud Monitoring können Sie:
- Von Autoscaling verwendete Messwerte anzeigen lassen
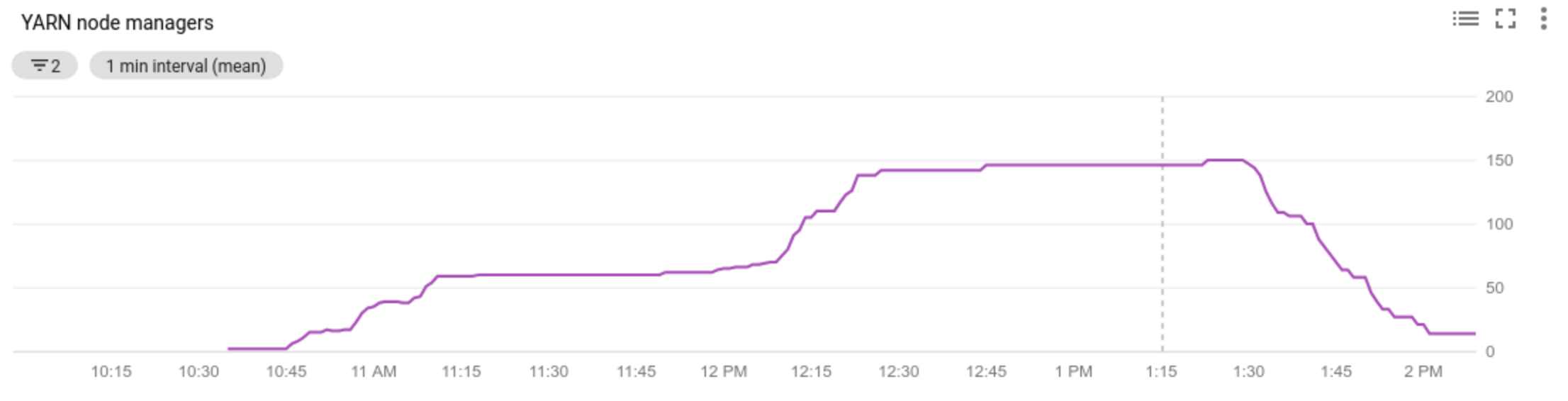
- Anzahl der Knotenmanager in einem Cluster anzeigen lassen
- Informationen dazu erhalten, warum Autoscaling einen Cluster skaliert oder nicht skaliert hat
Cloud Logging
Verwenden Sie Cloud Logging, um Logs von Dataproc Autoscaling aufzurufen.
1) Suchen Sie Logs für Ihren Cluster.
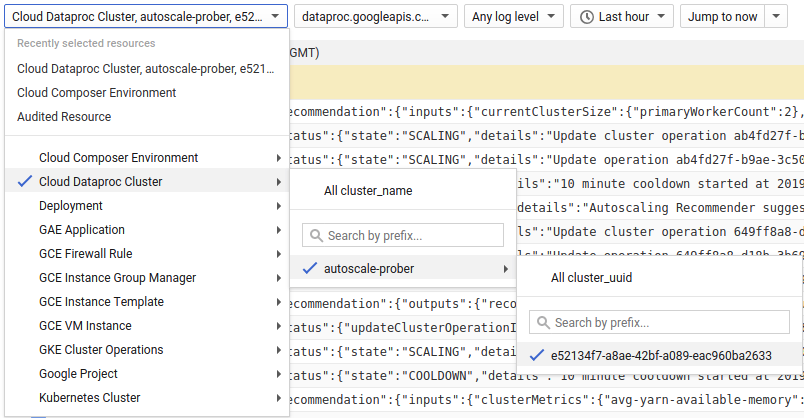
2) Wählen Sie dataproc.googleapis.com/autoscaler.
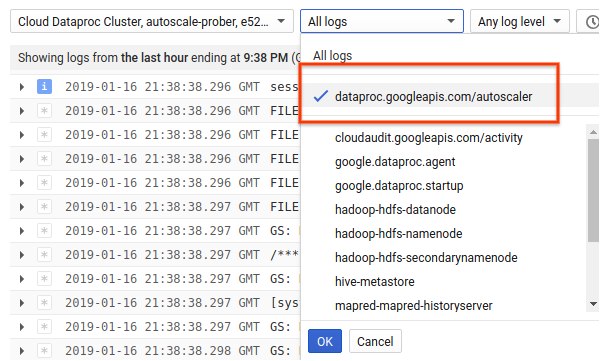
3) Maximieren Sie die Logeinträge, um das Feld status anzuzeigen. Die Logs sind im maschinenlesbaren Format JSON.
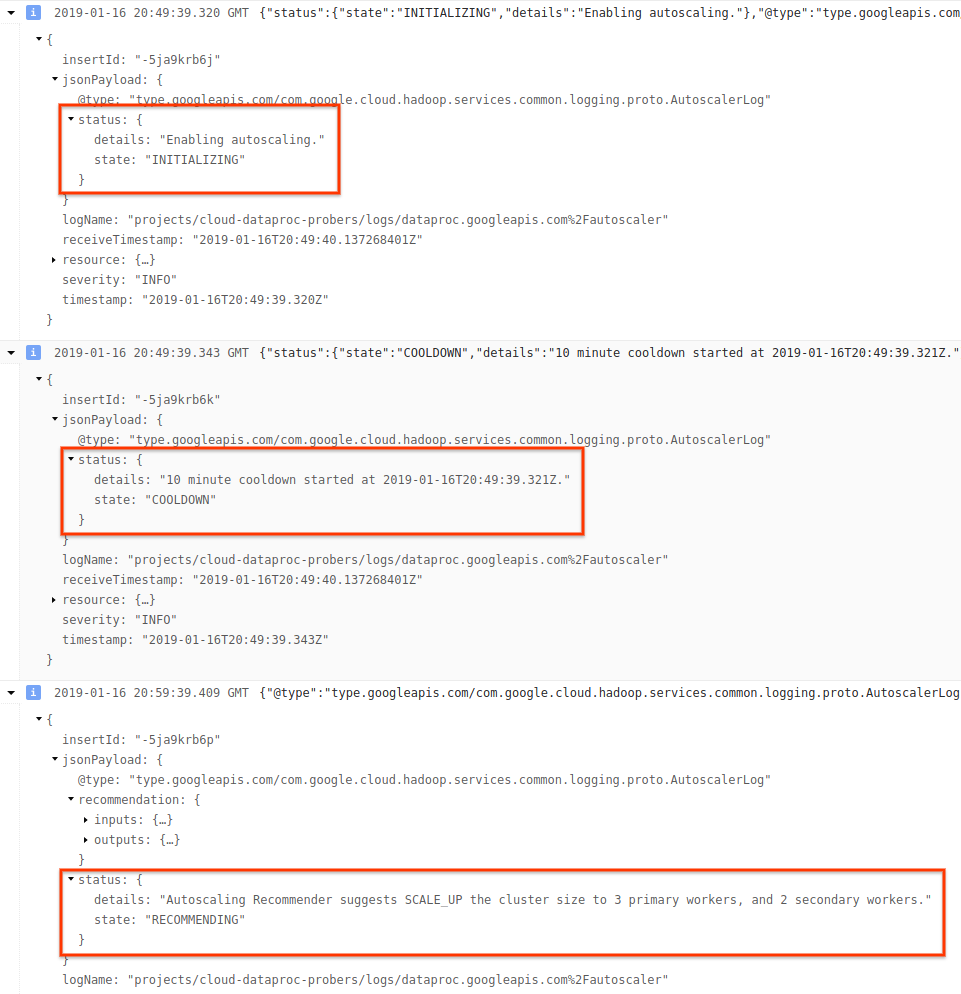
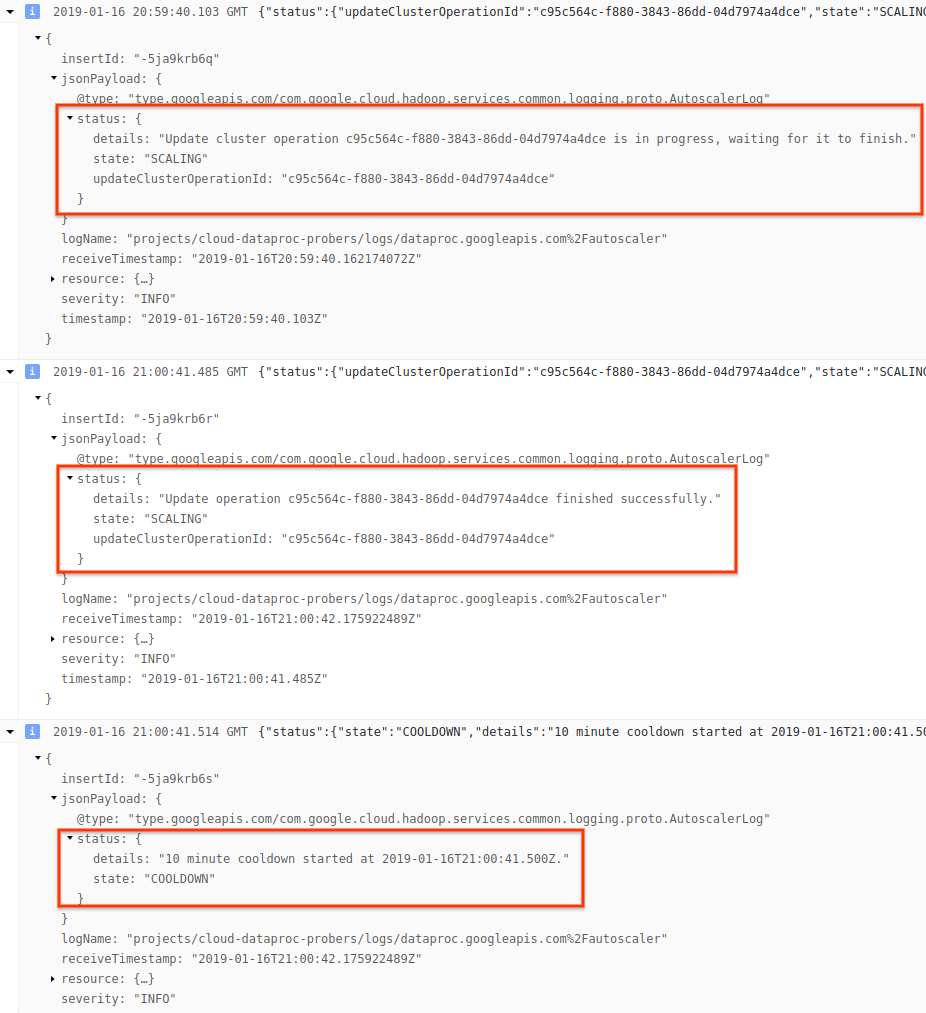
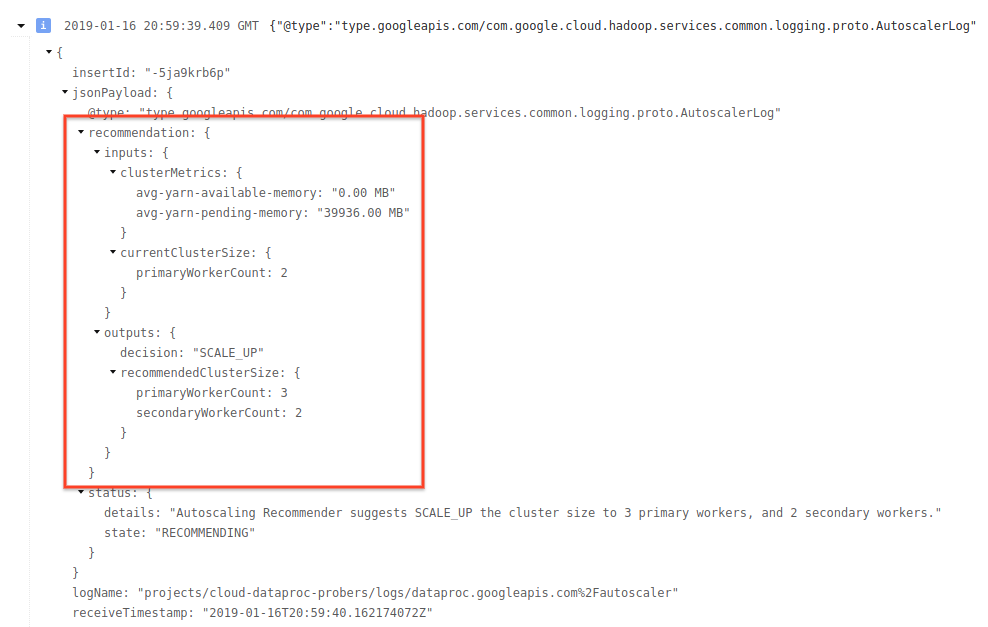
4) Erweitern Sie den Logeintrag, um Skalierungsempfehlungen, für Skalierungsentscheidungen verwendete Messwerte, die ursprüngliche Clustergröße und die neue Zielclustergröße zu sehen.
Hintergrund: Autoscaling mit Apache Hadoop und Apache Spark
In den folgenden Abschnitten wird erläutert, wie Autoscaling mit Hadoop YARN und Hadoop Mapreduce sowie mit Apache Spark, Spark Streaming und Spark Structured Streaming interagiert.
Hadoop YARN-Messwerte
Das Autoscaling basiert auf den folgenden Hadoop YARN-Messwerten:
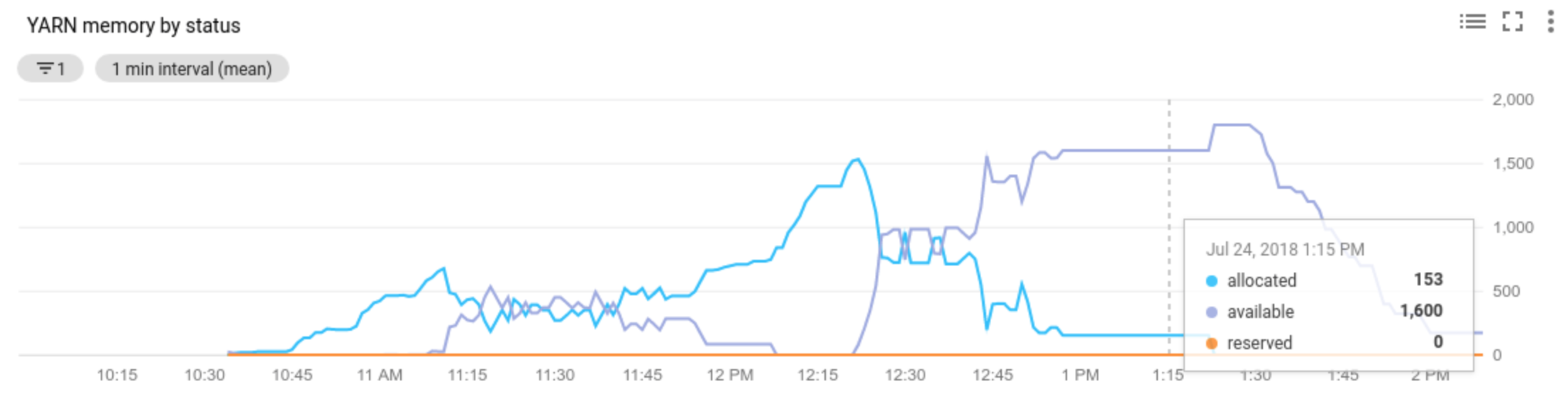
Allocated resourcebezieht sich auf die gesamten YARN-Ressourcen, die von den Containern belegt werden, die im gesamten Cluster ausgeführt werden. Wenn 6 Container ausgeführt werden, die bis zu 1 Ressourceneinheit verwenden können, sind 6 Ressourcen zugewiesen.Available resourceist die YARN-Ressource im Cluster, die nicht von zugewiesenen Containern verwendet wird. Wenn für alle Knotenmanager 10 Ressourceneinheiten zur Verfügung stehen und 6 davon zugeordnet wurden, sind 4 Ressourcen verfügbar. Wenn im Cluster freie (nicht verwendete) Ressourcen vorhanden sind, kann Autoscaling Worker aus dem Cluster entfernen.Pending resourceist die Summe der YARN-Ressourcenanforderungen für ausstehende Container. Ausstehende Container warten darauf, dass in YARN Speicherplatz frei wird. Die ausstehende Ressource ist nur dann ungleich null, wenn die verfügbare Ressource null oder zu klein ist, um dem nächsten Container zugewiesen zu werden. Wenn ausstehende Container vorhanden sind, fügt Autoscaling dem Cluster gegebenenfalls Worker hinzu.
Sie können diese Messwerte in Cloud Monitoring aufrufen. Standardmäßig beträgt der YARN-Speicher 0,8 * Gesamtspeicher auf dem Cluster. Der verbleibende Speicher ist für andere Daemons und die Betriebssystemnutzung reserviert, z. B. den Seitencache. Sie können den Standardwert mit der YARN-Konfigurationseinstellung "yarn.nodemanager.resource.memory-mb" überschreiben (siehe Apache Hadoop YARN, HDFS, Spark und zugehörige Attribute).
Autoscaling und Hadoop MapReduce
MapReduce führt alle MapReduce-Aufgaben als separaten YARN-Container aus. Wenn ein Job beginnt, sendet MapReduce eine Containeranfrage für jede Zuordnungsaufgabe, was zu einem starken Anstieg des ausstehenden YARN-Speichers führt. Wenn die Zuordnungsaufgaben abgeschlossen wurden, sinkt der Wert für den ausstehenden Speicher.
Wenn mapreduce.job.reduce.slowstart.completedmaps abgeschlossen wurde (ab einem Schwellwert von 95 % gilt dies in Dataproc als erfüllt), stellt MapReduce Containeranfragen für alle Reduzierungen in die Warteschlange, was zu einem weiteren Anstieg des ausstehenden Arbeitsspeichers führt.
Legen Sie keinen hohen Wert für den Autoscaling-scaleUpFactor fest, es sei denn, die Zuordnung und das Reduzieren von Aufgaben dauern mehrere Minuten oder länger. Das Hinzufügen von Workern zum Cluster dauert mindestens 1,5 Minuten. Achten Sie daher darauf, dass genügend ausstehende Arbeitslast vorhanden ist, um neue Worker für einige Minuten zu verwenden. Ein guter Ausgangspunkt ist, für scaleUpFactor einen Wert von 0,05 (5 %) oder 0,1 (10 %) des ausstehenden Speichers festzulegen.
Autoscaling und Spark
Spark fügt eine zusätzliche Ebene der Planung neben YARN hinzu. Genauer gesagt stellt die dynamische Zuordnung von Spark Core Anfragen an YARN nach Containern, die Spark-Executors ausführen, und plant dann Spark-Aufgaben für Threads auf diesen Executors. Dataproc-Cluster ermöglichen standardmäßig die dynamische Zuordnung, sodass Executors nach Bedarf hinzugefügt und entfernt werden können.
Spark fragt Container immer bei YARN an, aber ohne dynamische Zuordnung fragt es Container nur zu Beginn des Jobs an. Bei der dynamischen Zuordnung werden Container entfernt oder bei Bedarf neue Container angefragt.
Spark beginnt mit einer kleinen Anzahl von Executors – 2 in Autoscaling-Clustern – und verdoppelt die Anzahl der Executors, wenn Aufgaben im Rückstand sind.
Dadurch wird ein sprunghafter Anstieg bzw. Abfall bei ausstehendem Speicher seltener. Es wird empfohlen, den Autoscaling-scaleUpFactor für Spark-Jobs auf eine große Zahl zu setzen, z. B. 1,0 (100 %).
Dynamische Zuordnung von Spark deaktivieren
Wenn Sie separate Spark-Jobs ausführen, die nicht von der dynamischen Zuordnung von Spark profitieren, können Sie die dynamische Zuordnung von Spark deaktivieren, indem Sie spark.dynamicAllocation.enabled=false und spark.executor.instances angeben.
Sie können Autoscaling weiterhin verwenden, um Cluster hoch oder herunter zu skalieren, während die einzelnen Spark-Jobs ausgeführt werden.
Spark-Jobs mit im Cache gespeicherten Daten
Legen Sie spark.dynamicAllocation.cachedExecutorIdleTimeout fest oder löschen Sie den Cache von Datasets, wenn sie nicht mehr benötigt werden. Standardmäßig entfernt Spark keine Executors mit im Cache gespeicherten Daten, die das Herunterskalieren des Clusters verhindern würden.
Autoscaling und Spark-Streaming
Spark-Streaming hat eine eigene Version der dynamischen Zuordnung, die Streaming-spezifische Signale zum Hinzufügen und Entfernen von Executors verwendet. Um Spark-Streaming zu verwenden, geben Sie
spark.streaming.dynamicAllocation.enabled=truean und deaktivieren dann die dynamische Zuweisung von Spark Core mitspark.dynamicAllocation.enabled=false.Verwenden Sie die ordnungsgemäße Außerbetriebnahme (Autoscaling
gracefulDecommissionTimeout) nicht mit Spark Streaming-Jobs. Um Worker mit Autoscaling sicher zu entfernen, konfigurieren Sie stattdessen Checkpointing für Fehlertoleranz.
Alternativ können Sie Spark Streaming ohne Autoscaling verwenden:
- Deaktivieren Sie die Spark Core-dynamische Zuordnung (
spark.dynamicAllocation.enabled=false) und - Legen Sie die Anzahl der Executors (
spark.executor.instances) für Ihren Job fest. Informationen dazu finden Sie unter Clusterattribute:
Autoscaling und Spark Structured Streaming
Autoscaling ist nicht mit Spark Structured Streaming kompatibel, da Spark Structured Streaming keine dynamische Zuordnung unterstützt. Informationen dazu finden Sie unter SPARK-24815: Structured Streaming sollte die dynamische Zuordnung unterstützen.
Autoscaling durch Partitionierung und Parallelität steuern
Parallelität wird normalerweise durch Clusterressourcen festgelegt oder bestimmt, z. B. steuert die Anzahl der HDFS-Blöcke die Anzahl der Aufgaben. Beim Autoscaling ist jedoch das Gegenteil der Fall: Autoscaling legt die Clusterressourcen (Worker) anhand der Job-Parallelität fest. Diese Richtlinien können dabei helfen, die Job-Parallelität festzulegen:
- Während Dataproc die Standardanzahl der MapReduce-Reduce-Aufgaben basierend auf der anfänglichen Clustergröße Ihres Clusters festlegt, können Sie
mapreduce.job.reducesfestlegen, um die Parallelität der Reduce-Phase zu erhöhen. - Spark SQL und DataFrame-Parallelität werden durch
spark.sql.shuffle.partitionsbestimmt, die standardmäßig auf 200 gesetzt sind. - Die RDD-Funktionen von Spark sind standardmäßig auf
spark.default.parallelismgesetzt. Dieser Wert wird beim Start des Jobs auf die Anzahl der Kerne auf den Worker-Knoten festgelegt. Allerdings übernehmen alle RDD-Funktionen, die Shuffles erstellen, einen Parameter für die Anzahl der Partitionen, derspark.default.parallelismüberschreibt.
Achten Sie darauf, dass Ihre Daten gleichmäßig partitioniert sind. Wenn ein signifikanter Schlüsselversatz vorliegt, können eine oder mehrere Aufgaben erheblich länger dauern als andere Aufgaben, was zu einer geringen Auslastung führt.
Autoscaling-Standardeinstellungen für Spark- und Hadoop-Attribute
Autoscaling-Cluster haben Standardwerte für Clusterattribute, die dazu beitragen, Jobfehler zu vermeiden, wenn primäre Worker entfernt oder sekundäre Worker unterbrochen werden. Sie können diese Standardwerte überschreiben, wenn Sie einen Cluster mit Autoscaling erstellen. Informationen dazu finden Sie unter Clusterattribute.
Standardwerte für eine Erhöhung der maximalen Anzahl von Wiederholungen für Aufgaben, Application Master und Phasen:
yarn:yarn.resourcemanager.am.max-attempts=10 mapred:mapreduce.map.maxattempts=10 mapred:mapreduce.reduce.maxattempts=10 spark:spark.task.maxFailures=10 spark:spark.stage.maxConsecutiveAttempts=10
Standardwerte, um Wiederholungszähler zurückzusetzen. Dies kann bei lang andauernden Spark Streaming-Jobs hilfreich sein:
spark:spark.yarn.am.attemptFailuresValidityInterval=1h spark:spark.yarn.executor.failuresValidityInterval=1h
Standardwert, damit der Mechanismus der dynamischen Zuordnung für Slow-Start von Spark mit einer geringen Größe beginnt:
spark:spark.executor.instances=2
Häufig gestellte Fragen (FAQ)
In diesem Abschnitt finden Sie häufig gestellte Fragen und Antworten zum Autoscaling.
Kann Autoscaling in Hochverfügbarkeitsclustern und Single-Node-Clustern aktiviert werden?
Autoscaling kann in Hochverfügbarkeitsclustern aktiviert werden, nicht jedoch in Clustern mit einzelnem Knoten, da diese keine Skalierung unterstützen.
Kann man Größe eines Autoscaling-Clusters manuell ändern?
Ja. Möglicherweise entscheiden Sie sich dafür, die Größe eines Clusters während der Feinabstimmung einer Autoscaling-Richtlinie manuell als Stopp festzulegen. Diese Änderungen sind jedoch nur vorübergehend wirksam, das Autoscaling übernimmt die Clusterskalierung früher oder später wieder.
Statt den Cluster manuell zu skalieren, gibt es diese Möglichkeiten:
Aktualisieren der Autoscaling-Richtlinie Änderungen an der Autoscaling-Richtlinie wirken sich auf alle Cluster aus, die die Richtlinie derzeit verwenden (siehe Multi-Cluster-Richtlinienverwendung).
Richtlinie trennen und Cluster manuell auf die bevorzugte Größe skalieren.
Wie unterscheidet sich Dataproc vom Dataflow-Autoscaling?
Weitere Informationen finden Sie unter Horizontales Autoscaling in Dataflow und Vertikales Autoscaling in Dataflow Prime.
Kann das Dataproc-Entwicklungsteam den Clusterstatus von ERROR auf RUNNING zurücksetzen?
Im Allgemeinen nicht. Es erfordert manuelle Bemühungen, um zu testen, ob es sicher ist, den Status des Clusters zurückzusetzen. Außerdem kann ein Cluster nicht ohne andere manuelle Schritte zurückgesetzt werden, z. B. Neustart des HDFS-NameNode.
Dataproc setzt den Status eines Clusters auf ERROR, wenn er den Status eines Clusters nach einem fehlgeschlagenen Vorgang nicht ermitteln kann. Cluster in ERROR werden nicht automatisch skaliert. Das kann folgende Gründe haben:
Fehler, die von der Compute Engine API zurückgegeben werden, oft während eines Compute Engine-Ausfalls.
HDFS kann aufgrund von Programmfehlern bei der Außerbetriebnahme von HDFS beschädigt werden.
Fehler bei der Dataproc Control API, z. B. „Aufgabenfreigabe abgelaufen“.
Löschen und erstellen Sie Cluster mit dem Status ERROR neu.
Wann wird ein Herunterskalierungsvorgang durch Autoscaling abgebrochen?
Die folgende Abbildung zeigt, wann durch Autoscaling ein Herunterskalierungsvorgang abgebrochen wird (siehe auch So funktioniert Autoscaling).
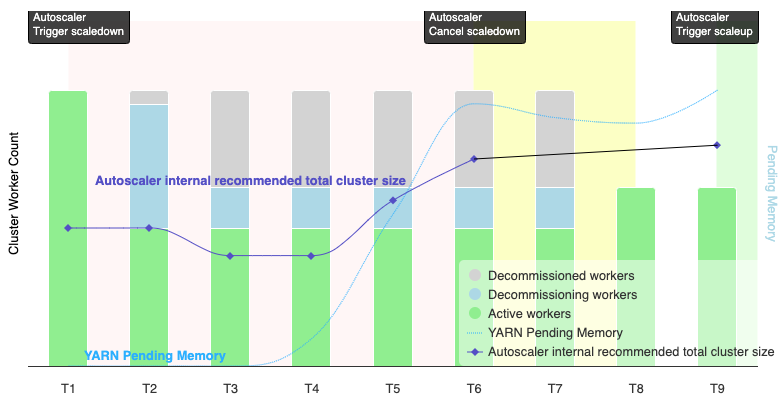
Hinweise:
- Für den Cluster ist Autoscaling nur basierend auf YARN-Speichermesswerten aktiviert (Standardeinstellung).
- T1–T9 stehen für Ruhephasen, in denen der Autoscaler die Anzahl der Worker auswertet (das Ereignis-Timing wurde vereinfacht).
- Gestapelte Balken stellen die Anzahl der aktiven, außer Betrieb gesetzten und außer Betrieb gesetzten YARN-Worker des Clusters dar.
- Die vom Autoscaler empfohlene Anzahl von Workern (schwarze Linie) basiert auf YARN-Speichermesswerten, der Anzahl der aktiven YARN-Worker und den Einstellungen der Autoscaling-Richtlinie (siehe Funktionsweise von Autoscaling).
- Der rote Hintergrundbereich gibt den Zeitraum an, in dem der Vorgang zum Herunterskalieren ausgeführt wird.
- Der gelbe Hintergrundbereich gibt den Zeitraum an, in dem der Vorgang zum Herunterskalieren abgebrochen wird.
- Der grüne Hintergrundbereich gibt den Zeitraum des Scale-up-Vorgangs an.
Die folgenden Vorgänge werden zu den angegebenen Zeiten ausgeführt:
T1: Der Autoscaler initiiert einen Vorgang zum Herunterskalieren durch ordnungsgemäße Außerbetriebnahme, um etwa die Hälfte der aktuellen Cluster-Worker herunterzuskalieren.
T2: Der Autoscaler überwacht weiterhin Clustermesswerte. Die Empfehlung zum Herunterskalieren wird nicht geändert und der Vorgang wird fortgesetzt. Einige Worker wurden außer Betrieb genommen und andere werden außer Betrieb genommen (Dataproc löscht außer Betrieb genommene Worker).
T3: Der Autoscaler berechnet, dass die Anzahl der Worker weiter reduziert werden kann, möglicherweise weil zusätzlicher YARN-Speicher verfügbar wird. Da die Anzahl der aktiven Worker plus die empfohlene Änderung der Anzahl der Worker jedoch nicht gleich oder größer als die Anzahl der aktiven Worker plus der Worker, die außer Betrieb genommen werden, ist, sind die Kriterien für die Aufhebung des Herunterskalierens nicht erfüllt und der Autoscaler bricht den Vorgang nicht ab.
T4: YARN meldet eine Zunahme des ausstehenden Speichers. Das Autoscaling ändert jedoch seine Empfehlung für die Anzahl der Worker nicht. Wie in T3 werden die Kriterien für die Abbruchskalierung nicht erfüllt und der Autoscaler bricht den Skalierungsvorgang nicht ab.
T5: Der ausstehende YARN-Arbeitsspeicher nimmt zu und die vom Autoscaler empfohlene Änderung der Anzahl der Worker nimmt zu. Da die Anzahl der aktiven Worker plus die empfohlene Änderung der Anzahl der Worker jedoch geringer ist als die Anzahl der aktiven Worker plus der Worker, die außer Betrieb genommen werden, sind die Kündigungskriterien weiterhin nicht erfüllt und der Vorgang zum Herunterskalieren wird nicht abgebrochen.
T6: Der ausstehende YARN-Speicher nimmt weiter zu. Die Anzahl der aktiven Worker plus die vom Autoscaler empfohlene Änderung der Anzahl der Worker ist jetzt größer als die Anzahl der aktiven und der außer Betrieb genommenen Worker. Die Kündigungskriterien sind erfüllt und der Autoscaler bricht den Vorgang zum Herunterskalieren ab.
T7: Das Autoscaling wartet auf den Abschluss des Vorgangs zum Herunterskalieren. Der Autoscaler bewertet und empfiehlt in diesem Zeitraum keine Änderung der Anzahl der Worker.
T8: Der Abbruch des Herunterskalierungsvorgangs wird abgeschlossen. Dem Cluster werden Worker hinzugefügt, die außer Betrieb genommen werden, und sie werden aktiv. Der Autoscaler erkennt den Abschluss des Vorgangs zum Abbrechen des Herunterskalierens und wartet auf den nächsten Auswertungszeitraum (T9), um die empfohlene Anzahl von Workern zu berechnen.
T9: Zum Zeitpunkt T9 sind keine aktiven Vorgänge vorhanden. Basierend auf der Autoscaler-Richtlinie und den YARN-Messwerten empfiehlt der Autoscaler eine Hochskalierung.