É possível ativar outros componentes, como o Flink, ao criar um cluster do Dataproc usando o recurso Componentes opcionais. Nesta página, mostramos como criar um cluster do Dataproc com o componente opcional Apache Flink ativado (um cluster do Flink) e executar jobs do Flink nele.
Você pode usar o cluster do Flink para:
Execute jobs do Flink usando o recurso
Jobsdo Dataproc no console Google Cloud , na CLI gcloud ou na API Dataproc.Execute jobs do Flink usando a CLI
flinkno nó mestre do cluster do Flink.Execute o Flink em um cluster do Kerberos
Criar um cluster do Dataproc Flink
Use o console Google Cloud , a CLI do Google Cloud ou a API Dataproc para criar um cluster do Dataproc com o componente Flink ativado.
Recomendação:use um cluster de VM padrão de um mestre com o componente Flink. Os clusters do modo de alta disponibilidade do Dataproc (com três VMs principais) não são compatíveis com o modo de alta disponibilidade do Flink.
Console
Para criar um cluster do Dataproc Flink usando o console Google Cloud , siga estas etapas:
Abra a página Criar um cluster do Dataproc no Compute Engine.
- O painel Configurar cluster está selecionado.
- Na seção Controle de versões, confirme ou altere o Tipo e a versão da imagem. A versão da imagem do cluster determina a versão do componente Flink instalado no cluster.
- A versão da imagem precisa ser 1.5 ou mais recente para ativar o componente Flink no cluster. Consulte Versões compatíveis do Dataproc para ver as listas das versões de componentes incluídas em cada versão de imagem do Dataproc.
- A versão da imagem precisa ser [TBD] ou mais recente para executar jobs do Flink pela API Jobs do Dataproc. Consulte Executar jobs do Flink no Dataproc.
- Na seção Componentes:
- Em Gateway de componentes, selecione Ativar gateway de componentes. É necessário ativar o Gateway de componentes para ativar o link do gateway de componentes à interface do servidor de histórico do Flink. Ao ativar o Component Gateway, você também ativa o acesso à interface da Web do Flink Job Manager em execução no cluster do Flink.
- Em Componentes opcionais, selecione Flink e outros componentes opcionais para ativar no cluster.
- Na seção Controle de versões, confirme ou altere o Tipo e a versão da imagem. A versão da imagem do cluster determina a versão do componente Flink instalado no cluster.
Clique no painel Personalizar cluster (opcional).
Na seção Propriedades do cluster, clique em Adicionar propriedades para cada propriedade do cluster opcional que você quer adicionar. É possível adicionar propriedades com prefixo
flinkpara configurar propriedades do Flink em/etc/flink/conf/flink-conf.yaml, que vão funcionar como padrões para aplicativos do Flink executados no cluster.Exemplos:
- Defina
flink:historyserver.archive.fs.dirpara especificar o local do Cloud Storage em que os arquivos de histórico de jobs do Flink serão gravados. Esse local será usado pelo servidor de histórico do Flink em execução no cluster do Flink. - Defina slots de tarefas do Flink com
flink:taskmanager.numberOfTaskSlots=n.
- Defina
Na seção Metadados personalizados do cluster, clique em Adicionar metadados para incluir metadados opcionais. Por exemplo, adicione
flink-start-yarn-sessiontruepara executar o daemon do Flink YARN (/usr/bin/flink-yarn-daemon) em segundo plano no nó mestre do cluster e iniciar uma sessão do Flink YARN. Consulte Modo de sessão do Flink.
Se você estiver usando a versão 2.0 ou anterior da imagem do Dataproc, clique no painel Gerenciar segurança (opcional) e, em Acesso ao projeto, selecione
Enables the cloud-platform scope for this cluster. O escopocloud-platformé ativado por padrão quando você cria um cluster que usa a versão 2.1 ou mais recente da imagem do Dataproc.
- O painel Configurar cluster está selecionado.
Clique em Criar para gerar o cluster.
gcloud
Para criar um cluster do Dataproc Flink usando a CLI gcloud, execute o seguinte comando gcloud dataproc clusters create localmente em uma janela de terminal ou no Cloud Shell:
gcloud dataproc clusters create CLUSTER_NAME \ --region=REGION \ --image-version=DATAPROC_IMAGE_VERSION \ --optional-components=FLINK \ --enable-component-gateway \ --properties=PROPERTIES ... other flags
Observações:
- CLUSTER_NAME: especifique o nome do cluster.
- REGION: especifique uma região do Compute Engine em que o cluster será localizado.
DATAPROC_IMAGE_VERSION: especifique opcionalmente a versão da imagem a ser usada no cluster. A versão da imagem do cluster determina a versão do componente Flink instalado no cluster.
A versão da imagem precisa ser 1.5 ou mais recente para ativar o componente Flink no cluster. Consulte Versões compatíveis do Dataproc para ver as listas das versões de componentes incluídas em cada versão de imagem do Dataproc.
A versão da imagem precisa ser [TBD] ou mais recente para executar jobs do Flink pela API Jobs do Dataproc. Consulte Executar jobs do Flink no Dataproc.
--optional-components: é necessário especificar o componenteFLINKpara executar jobs do Flink e o serviço da Web do Flink HistoryServer no cluster.--enable-component-gateway: é necessário ativar o gateway de componentes para ativar o link do gateway de componentes para a interface do servidor de histórico do Flink. Ao ativar o Component Gateway, você também ativa o acesso à interface da Web do Flink Job Manager em execução no cluster do Flink.PROPERTIES. Também é possível especificar uma ou mais propriedades do cluster.
Ao criar clusters do Dataproc com versões de imagem
2.0.67+ e2.1.15+, use a flag--propertiespara configurar propriedades do Flink em/etc/flink/conf/flink-conf.yaml, que vão atuar como padrões para aplicativos do Flink executados no cluster.É possível definir
flink:historyserver.archive.fs.dirpara especificar o local do Cloud Storage em que os arquivos de histórico de jobs do Flink serão gravados. Esse local será usado pelo servidor de histórico do Flink em execução no cluster do Flink.Exemplo de várias propriedades:
--properties=flink:historyserver.archive.fs.dir=gs://my-bucket/my-flink-cluster/completed-jobs,flink:taskmanager.numberOfTaskSlots=2Outras sinalizações:
- Você pode adicionar a flag opcional
--metadata flink-start-yarn-session=truepara executar o daemon do Flink YARN (/usr/bin/flink-yarn-daemon) em segundo plano no nó mestre do cluster e iniciar uma sessão do Flink YARN (consulte Modo de sessão do Flink).
- Você pode adicionar a flag opcional
Ao usar versões de imagem 2.0 ou anteriores, adicione a flag
--scopes=https://www.googleapis.com/auth/cloud-platformpara ativar o acesso às APIs Google Cloud pelo cluster (consulte Prática recomendada de escopos). O escopocloud-platformé ativado por padrão quando você cria um cluster que usa a versão 2.1 ou mais recente da imagem do Dataproc.
API
Para criar um cluster do Dataproc Flink usando a API Dataproc, envie uma solicitação clusters.create, da seguinte maneira:
Observações:
Defina o SoftwareConfig.Component como
FLINK.Se quiser, defina
SoftwareConfig.imageVersionpara especificar a versão da imagem a ser usada no cluster. A versão da imagem do cluster determina a versão do componente Flink instalado no cluster.A versão da imagem precisa ser 1.5 ou mais recente para ativar o componente Flink no cluster. Consulte Versões compatíveis do Dataproc para ver as listas das versões de componentes incluídas em cada versão de imagem do Dataproc.
A versão da imagem precisa ser [TBD] ou mais recente para executar jobs do Flink pela API Jobs do Dataproc. Consulte Executar jobs do Flink no Dataproc.
Defina EndpointConfig.enableHttpPortAccess como
truepara ativar o link do Gateway de componentes para a interface do servidor de histórico do Flink. Ao ativar o Component Gateway, você também ativa o acesso à interface da Web do Flink Job Manager em execução no cluster do Flink.Se quiser, defina
SoftwareConfig.propertiespara especificar uma ou mais propriedades do cluster.- É possível especificar propriedades do Flink que vão funcionar como padrões para aplicativos do Flink executados no cluster. Por exemplo, é possível definir
flink:historyserver.archive.fs.dirpara especificar o local do Cloud Storage em que os arquivos do histórico de jobs do Flink serão gravados. Esse local será usado pelo servidor de histórico do Flink em execução no cluster do Flink.
- É possível especificar propriedades do Flink que vão funcionar como padrões para aplicativos do Flink executados no cluster. Por exemplo, é possível definir
Você também pode definir:
GceClusterConfig.metadata. Por exemplo, para especificarflink-start-yarn-sessiontruee executar o daemon do Flink YARN (/usr/bin/flink-yarn-daemon) em segundo plano no nó mestre do cluster para iniciar uma sessão do Flink YARN (consulte Modo de sessão do Flink).- GceClusterConfig.serviceAccountScopes
para
https://www.googleapis.com/auth/cloud-platform(escopocloud-platform) ao usar versões de imagem 2.0 ou anteriores para permitir o acesso às APIs Google Cloud pelo cluster (consulte Prática recomendada de escopos). O escopocloud-platformé ativado por padrão quando você cria um cluster que usa a versão 2.1 ou mais recente da imagem do Dataproc.
Depois de criar um cluster do Flink
- Use o link
Flink History Serverno Gateway de componentes para ver o servidor de histórico do Flink em execução no cluster do Flink. - Use o
YARN ResourceManager linkno Gateway de componentes para conferir a interface da Web do Flink Job Manager em execução no cluster do Flink . - Crie um servidor de histórico permanente do Dataproc para visualizar arquivos de histórico de jobs do Flink gravados por clusters do Flink existentes e excluídos.
Executar jobs do Flink usando o recurso Jobs do Dataproc
É possível executar jobs do Flink usando o recurso Jobs do Dataproc no
consoleGoogle Cloud , na CLI gcloud ou na API Dataproc.
Console
Para enviar um job de exemplo de contagem de palavras do Flink no console:
Abra a página Enviar um job do Dataproc no Google Cloud console no navegador.
Preencha os campos na página Enviar um job:
- Selecione o nome do Cluster na lista de clusters.
- Defina o Tipo de job como
Flink. - Defina Classe principal ou jar como
org.apache.flink.examples.java.wordcount.WordCount. - Defina Arquivos Jar como
file:///usr/lib/flink/examples/batch/WordCount.jar.file:///indica um arquivo localizado no cluster. O Dataproc instalou oWordCount.jarao criar o cluster do Flink.- Esse campo também aceita um caminho do Cloud Storage (
gs://BUCKET/JARFILE) ou um caminho do sistema de arquivos distribuídos do Hadoop (HDFS, na sigla em inglês) (hdfs://PATH_TO_JAR).
Clique em Enviar.
- A saída do driver do job é exibida na página Detalhes do job.
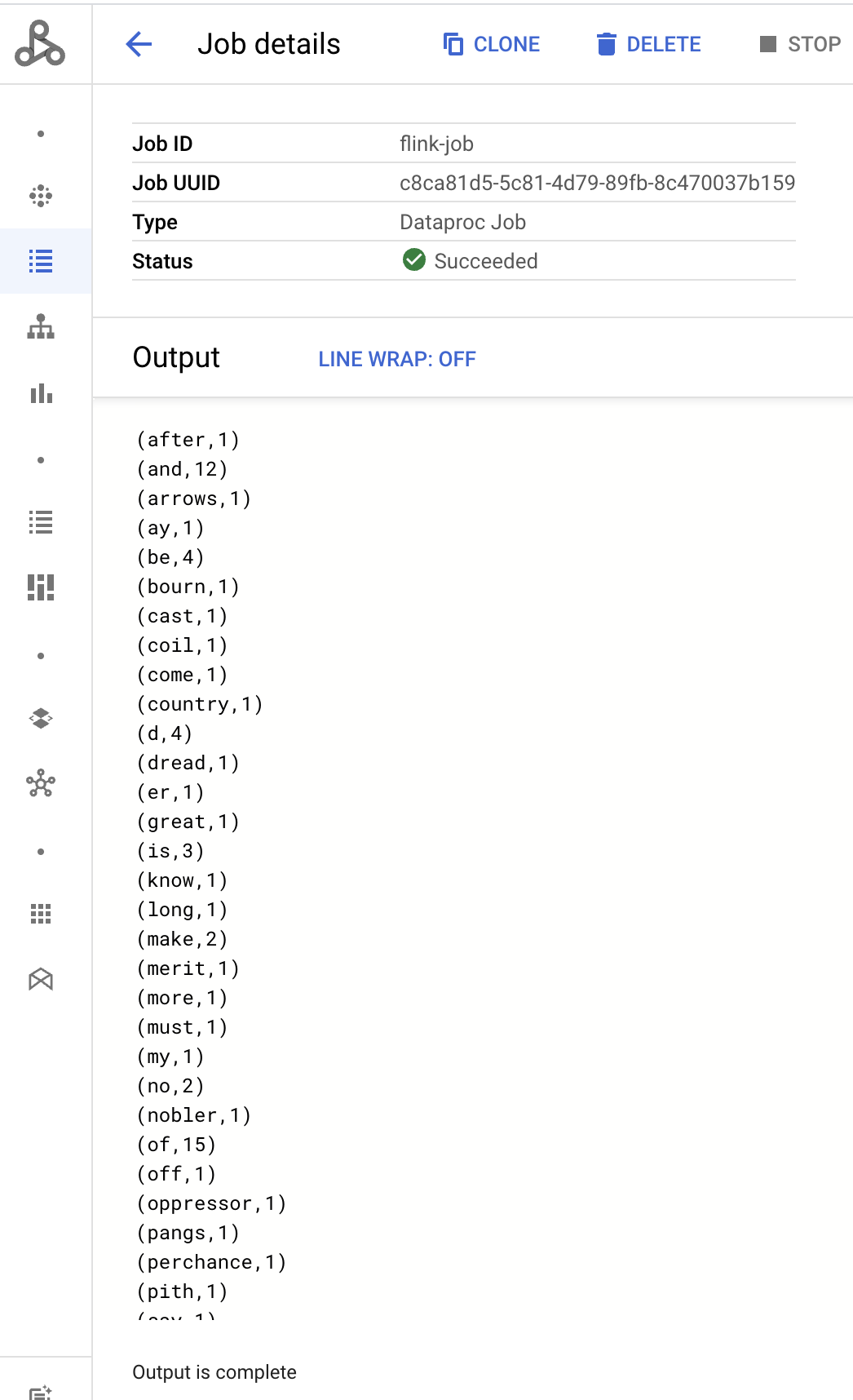
- Os jobs do Flink são listados na página Jobs do Dataproc no console Google Cloud .
- Clique em Parar ou Excluir na página Jobs ou Detalhes do job para interromper ou excluir um job.
gcloud
Para enviar um job do Flink a um cluster do Dataproc Flink, execute o comando da CLI gcloud gcloud dataproc jobs submit localmente em uma janela de terminal ou no Cloud Shell.
gcloud dataproc jobs submit flink \ --cluster=CLUSTER_NAME \ --region=REGION \ --class=MAIN_CLASS \ --jar=JAR_FILE \ -- JOB_ARGS
Observações:
- CLUSTER_NAME: especifique o nome do cluster do Dataproc Flink para enviar o job.
- REGION: especifique uma região do Compute Engine em que o cluster está localizado.
- MAIN_CLASS: especifique a classe
maindo seu aplicativo Flink, como:org.apache.flink.examples.java.wordcount.WordCount
- JAR_FILE: especifique o arquivo JAR do aplicativo Flink. Você pode especificar:
- Um arquivo jar instalado no cluster, usando o prefixo
file:///` :file:///usr/lib/flink/examples/streaming/TopSpeedWindowing.jarfile:///usr/lib/flink/examples/batch/WordCount.jar
- Um arquivo JAR no Cloud Storage:
gs://BUCKET/JARFILE - Um arquivo jar no HDFS:
hdfs://PATH_TO_JAR
- Um arquivo jar instalado no cluster, usando o prefixo
JOB_ARGS: opcionalmente, adicione argumentos de job após o traço duplo (
--).Depois de enviar o job, a saída do driver dele será exibida no terminal local ou do Cloud Shell.
Program execution finished Job with JobID 829d48df4ebef2817f4000dfba126e0f has finished. Job Runtime: 13610 ms ... (after,1) (and,12) (arrows,1) (ay,1) (be,4) (bourn,1) (cast,1) (coil,1) (come,1)
REST
Nesta seção, mostramos como enviar um job do Flink para um cluster do Flink no Dataproc usando a API jobs.submit do Dataproc.
Antes de usar os dados da solicitação abaixo, faça as substituições a seguir:
- PROJECT_ID: Google Cloud ID do projeto
- REGION: região do cluster
- CLUSTER_NAME: especifique o nome do cluster do Dataproc Flink para enviar o job.
Método HTTP e URL:
POST https://dataproc.googleapis.com/v1/projects/PROJECT_ID/regions/REGION/jobs:submit
Corpo JSON da solicitação:
{
"job": {
"placement": {
"clusterName": "CLUSTER_NAME"
},
"flinkJob": {
"mainClass": "org.apache.flink.examples.java.wordcount.WordCount",
"jarFileUris": [
"file:///usr/lib/flink/examples/batch/WordCount.jar"
]
}
}
}
Para enviar a solicitação, expanda uma destas opções:
Você receberá uma resposta JSON semelhante a esta:
{
"reference": {
"projectId": "PROJECT_ID",
"jobId": "JOB_ID"
},
"placement": {
"clusterName": "CLUSTER_NAME",
"clusterUuid": "CLUSTER_UUID"
},
"flinkJob": {
"mainClass": "org.apache.flink.examples.java.wordcount.WordCount",
"args": [
"1000"
],
"jarFileUris": [
"file:///usr/lib/flink/examples/batch/WordCount.jar"
]
},
"status": {
"state": "PENDING",
"stateStartTime": "2020-10-07T20:16:21.759Z"
},
"jobUuid": "JOB_UUID"
}
- Os jobs do Flink são listados na página Jobs do Dataproc no console Google Cloud .
- Clique em Parar ou Excluir na página Jobs ou Detalhes do job no console do Google Cloud para interromper ou excluir um job.
Executar jobs do Flink usando a CLI flink
Em vez de
executar jobs do Flink usando o recurso Jobs do Dataproc,
é possível executar jobs do Flink no nó mestre do cluster do Flink usando a CLI flink.
As seções a seguir descrevem diferentes maneiras de executar um job da CLI flink no
cluster do Dataproc Flink.
Use SSH para acessar o nó mestre:use o utilitário SSH para abrir uma janela de terminal na VM mestre do cluster.
Defina o classpath:inicialize o classpath do Hadoop na janela do terminal SSH da VM mestre do cluster do Flink:
export HADOOP_CLASSPATH=$(hadoop classpath)Executar jobs do Flink:é possível executar jobs do Flink em diferentes modos de implantação no YARN: aplicativo, por job e modo de sessão.
Modo de aplicativo:o modo de aplicativo do Flink é compatível com a versão 2.0 e mais recentes da imagem do Dataproc. Esse modo executa o método
main()do job no gerenciador de jobs do YARN. O cluster é desligado após a conclusão do job.Exemplo de envio de job:
flink run-application \ -t yarn-application \ -Djobmanager.memory.process.size=1024m \ -Dtaskmanager.memory.process.size=2048m \ -Djobmanager.heap.mb=820 \ -Dtaskmanager.heap.mb=1640 \ -Dtaskmanager.numberOfTaskSlots=2 \ -Dparallelism.default=4 \ /usr/lib/flink/examples/batch/WordCount.jarListar jobs em execução:
./bin/flink list -t yarn-application -Dyarn.application.id=application_XXXX_YYCancele um job em execução:
./bin/flink cancel -t yarn-application -Dyarn.application.id=application_XXXX_YY <jobId>Modo por job:esse modo do Flink executa o método
main()do job no lado do cliente.Exemplo de envio de job:
flink run \ -m yarn-cluster \ -p 4 \ -ys 2 \ -yjm 1024m \ -ytm 2048m \ /usr/lib/flink/examples/batch/WordCount.jarModo de sessão:inicie uma sessão do Flink YARN de longa duração e envie um ou mais jobs para ela.
Iniciar uma sessão:você pode iniciar uma sessão do Flink de uma das seguintes maneiras:
Crie um cluster do Flink, adicionando a flag
--metadata flink-start-yarn-session=trueao comandogcloud dataproc clusters create. Consulte Criar um cluster do Flink no Dataproc. Com essa flag ativada, depois que o cluster é criado, o Dataproc executa/usr/bin/flink-yarn-daemonpara iniciar uma sessão do Flink no cluster.O ID do aplicativo YARN da sessão é salvo em
/tmp/.yarn-properties-${USER}. É possível listar o ID com o comandoyarn application -list.Execute o script do Flink
yarn-session.shpré-instalado na VM mestre do cluster com configurações personalizadas:Exemplo com configurações personalizadas:
/usr/lib/flink/bin/yarn-session.sh \ -s 1 \ -jm 1024m \ -tm 2048m \ -nm flink-dataproc \ --detachedExecute o script wrapper do Flink
/usr/bin/flink-yarn-daemoncom as configurações padrão:. /usr/bin/flink-yarn-daemon
Enviar um job para uma sessão:execute o comando a seguir para enviar um job do Flink à sessão.
flink run -m <var>FLINK_MASTER_URL</var>/usr/lib/flink/examples/batch/WordCount.jar- FLINK_MASTER_URL: o URL, incluindo host
e porta, da VM principal do Flink em que os jobs são executados.
Remova o
http:// prefixdo URL. Esse URL é listado na saída do comando quando você inicia uma sessão do Flink. Execute o comando a seguir para listar esse URL no campoTracking-URL:
yarn application -list -appId=<yarn-app-id> | sed 's#http://##' ```- FLINK_MASTER_URL: o URL, incluindo host
e porta, da VM principal do Flink em que os jobs são executados.
Remova o
Listar jobs em uma sessão:para listar jobs do Flink em uma sessão, faça uma das seguintes ações:
Execute
flink listsem argumentos. O comando procura o ID do aplicativo YARN da sessão em/tmp/.yarn-properties-${USER}.Extraia o ID do aplicativo YARN da sessão em
/tmp/.yarn-properties-${USER}ou na saída deyarn application -list, e execute<code>flink list -yid YARN_APPLICATION_ID.Execute
flink list -m FLINK_MASTER_URL.
Interromper uma sessão:para interromper a sessão, receba o ID do aplicativo YARN da sessão em
/tmp/.yarn-properties-${USER}ou na saída deyarn application -liste execute um dos seguintes comandos:echo "stop" | /usr/lib/flink/bin/yarn-session.sh -id YARN_APPLICATION_IDyarn application -kill YARN_APPLICATION_ID
Executar jobs do Apache Beam no Flink
É possível executar jobs do Apache Beam no Dataproc usando o FlinkRunner.
É possível executar jobs do Beam no Flink das seguintes maneiras:
- Jobs do Beam em Java
- Jobs do Beam portáteis
Jobs do Beam em Java
Empacotar os jobs do Beam em um arquivo JAR. Forneça o arquivo JAR empacotado com as dependências necessárias para executar o job.
O exemplo a seguir executa um job do Java Beam a partir do nó mestre do cluster do Dataproc.
Crie um cluster do Dataproc com o componente Flink ativado.
gcloud dataproc clusters create CLUSTER_NAME \ --optional-components=FLINK \ --image-version=DATAPROC_IMAGE_VERSION \ --region=REGION \ --enable-component-gateway \ --scopes=https://www.googleapis.com/auth/cloud-platform--optional-components: Flink.--image-version: a versão de imagem do cluster, que determina a versão do Flink instalada no cluster. Por exemplo, consulte as versões do componente Flink do Apache listadas para a versão mais recente e quatro anteriores versões de lançamento de imagem 2.0.x.--region: uma região compatível do Dataproc.--enable-component-gateway: ativa o acesso à IU do Flink Job Manager.--scopes: ative o acesso às APIs Google Cloud pelo cluster (consulte Prática recomendada de escopos). O escopocloud-platformé ativado por padrão (não é necessário incluir essa configuração de flag) ao criar um cluster que usa a versão 2.1 ou mais recente da imagem do Dataproc.
Use o utilitário SSH para abrir uma janela de terminal no nó mestre do cluster do Flink.
Inicie uma sessão Flink YARN no nó mestre do cluster do Dataproc.
. /usr/bin/flink-yarn-daemonAnote a versão do Flink no cluster do Dataproc.
flink --versionNa máquina local, gere o exemplo de contagem de palavras canônica do Beam em Java.
Escolha uma versão do Beam compatível com a versão do Flink no cluster do Dataproc. Consulte a tabela de compatibilidade de versão do Flink (em inglês) que lista a compatibilidade da versão do Beam-Flink.
Abra o arquivo POM gerado. Verifique a versão do executor do Flink do Beam especificada pela tag
<flink.artifact.name>. Se o executor do Flink do Beam no nome do artefato do Flink não corresponder à versão do Flink no cluster, atualize o número da versão para corresponder.mvn archetype:generate \ -DarchetypeGroupId=org.apache.beam \ -DarchetypeArtifactId=beam-sdks-java-maven-archetypes-examples \ -DarchetypeVersion=BEAM_VERSION \ -DgroupId=org.example \ -DartifactId=word-count-beam \ -Dversion="0.1" \ -Dpackage=org.apache.beam.examples \ -DinteractiveMode=falseCrie um exemplo de contagem de palavras.
mvn package -Pflink-runnerFaça upload do arquivo JAR uber empacotado (
word-count-beam-bundled-0.1.jar, cerca de 135 MB) no nó mestre do cluster do Dataproc. É possível usargcloud storage cppara transferências de arquivos mais rápidas para o cluster do Dataproc do Cloud Storage.No terminal local, crie um bucket do Cloud Storage e faça o upload do JAR uber.
gcloud storage buckets create BUCKET_NAMEgcloud storage cp target/word-count-beam-bundled-0.1.jar gs://BUCKET_NAME/No nó mestre do Dataproc, faça o download do JAR uber.
gcloud storage cp gs://BUCKET_NAME/word-count-beam-bundled-0.1.jar .
Execute o job Java Beam no nó mestre do cluster do Dataproc.
flink run -c org.apache.beam.examples.WordCount word-count-beam-bundled-0.1.jar \ --runner=FlinkRunner \ --output=gs://BUCKET_NAME/java-wordcount-outVerifique se os resultados foram gravados no seu bucket do Cloud Storage.
gcloud storage cat gs://BUCKET_NAME/java-wordcount-out-SHARD_IDInterrompa a sessão YARN do Flink.
yarn application -listyarn application -kill YARN_APPLICATION_ID
Jobs do Beam portáteis
Para executar jobs do Beam escritos em Python, Go e outras linguagens compatíveis, use
o FlinkRunner ePortableRunner conforme descrito na página do
Flink Runner do Beam (consulte também Roteiro do Portability Framework).
No exemplo a seguir, um job portátil do Beam é executado no Python a partir do nó mestre do cluster do Dataproc.
Crie um cluster do Dataproc com os componentes Flink e Docker ativados.
gcloud dataproc clusters create CLUSTER_NAME \ --optional-components=FLINK,DOCKER \ --image-version=DATAPROC_IMAGE_VERSION \ --region=REGION \ --enable-component-gateway \ --scopes=https://www.googleapis.com/auth/cloud-platformObservações:
--optional-components: Flink e Docker.--image-version: a versão de imagem do cluster, que determina a versão do Flink instalada no cluster. Por exemplo, consulte as versões do componente Flink do Apache listadas para a versão mais recente e quatro anteriores versões de lançamento de imagem 2.0.x.--region: uma região disponível do Dataproc.--enable-component-gateway: ativa o acesso à interface do usuário do Flink Job Manager.--scopes: ative o acesso às APIs Google Cloud pelo cluster (consulte Prática recomendada de escopos). O escopocloud-platformé ativado por padrão (não é necessário incluir essa configuração de flag) ao criar um cluster que usa a versão 2.1 ou mais recente da imagem do Dataproc.
Use a CLI gcloud localmente ou no Cloud Shell para criar um bucket do Cloud Storage. Você vai especificar o BUCKET_NAME ao executar um programa de contagem de palavras de exemplo.
gcloud storage buckets create BUCKET_NAMEEm uma janela de terminal na VM do cluster, inicie uma sessão do Flink YARN. Anote o URL do mestre do Flink, o endereço do mestre do Flink em que os jobs são executados. Você vai especificar o FLINK_MASTER_URL ao executar um programa de contagem de palavras de exemplo.
. /usr/bin/flink-yarn-daemonMostre e anote a versão do Flink que está executando o cluster do Dataproc. Você vai especificar o FLINK_VERSION ao executar um programa de contagem de palavras de exemplo.
flink --versionInstale as bibliotecas do Python necessárias para o job no nó mestre do cluster.
Instale uma versão do Beam compatível com a versão do Flink no cluster.
python -m pip install apache-beam[gcp]==BEAM_VERSIONExecute o exemplo de contagem de palavras no nó mestre do cluster.
python -m apache_beam.examples.wordcount \ --runner=FlinkRunner \ --flink_version=FLINK_VERSION \ --flink_master=FLINK_MASTER_URL --flink_submit_uber_jar \ --output=gs://BUCKET_NAME/python-wordcount-outObservações:
--runner:FlinkRunner.--flink_version: FLINK_VERSION, conforme observado anteriormente.--flink_master: FLINK_MASTER_URL, conforme observado anteriormente.--flink_submit_uber_jar: use o JAR uber para executar o job do Beam.--output: BUCKET_NAME, criado anteriormente.
Verifique se os resultados foram gravados no bucket.
gcloud storage cat gs://BUCKET_NAME/python-wordcount-out-SHARD_IDInterrompa a sessão YARN do Flink.
- Consiga o ID do aplicativo.
yarn application -list1. Insert the <var>YARN_APPLICATION_ID</var>, then stop the session.yarn application -kill
Executar o Flink em um cluster do Kerberos
O componente Flink do Dataproc é compatível com clusters do Kerberos. Um tíquete do Kerberos válido é necessário para enviar e manter um job do Flink ou iniciar um cluster do Flink. Por padrão, um tíquete do Kerberos permanece válido por sete dias.
Acessar a interface do Flink Job Manager
A interface da Web do Flink Job Manager está disponível durante a execução de um job de Flink ou um cluster de sessão do Flink. Para usar a interface da Web:
- Crie um cluster do Dataproc Flink.
- Após a criação do cluster, clique no link do YARN ResourceManager do Gateway de componentes na guia "Interface da Web", na página Detalhes do cluster do Google Cloud console.
- Na IU do YARN Resource Manager, identifique a entrada do aplicativo de cluster
Flink. Dependendo do status de conclusão do job, um link do ApplicationMaster ou History será listado.
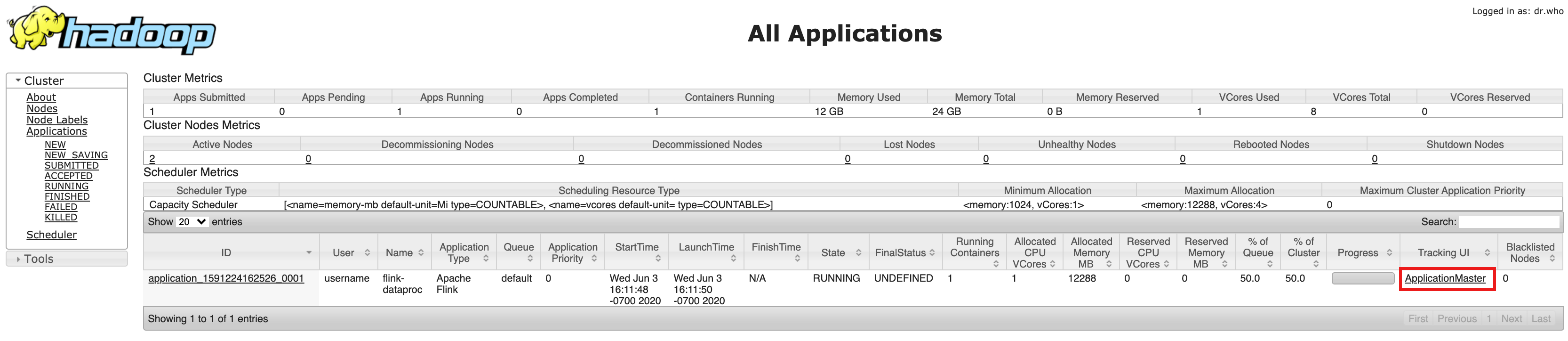
- Para um job de streaming de longa duração, clique no link ApplicationManager para abrir o painel do Flink. Para um job concluído, clique no link Histórico para visualizar os detalhes dele.
