Puedes activar componentes adicionales, como Flink, cuando creas un clúster de Dataproc con la función de componentes opcionales. En esta página, se muestra cómo crear un clúster de Dataproc con el componente opcional Apache Flink activado (un clúster de Flink) y, luego, ejecutar trabajos de Flink en el clúster.
Puedes usar tu clúster de Flink para lo siguiente:
Ejecuta trabajos de Flink con el recurso
Jobsde Dataproc desde la consola, Google Cloud CLI o la API de Dataproc. Google CloudEjecuta trabajos de Flink con la CLI de
flinken el nodo instancia principal del clúster de Flink.
Crea un clúster de Dataproc Flink
Puedes usar la consola de Google Cloud , Google Cloud CLI o la API de Dataproc para crear un clúster de Dataproc que tenga el componente de Flink activado.
Recomendación: Usa un clúster de VM estándar de 1 principal con el componente de Flink. Los clústeres en modo de alta disponibilidad de Dataproc (con 3 VMs principales) no admiten el modo de alta disponibilidad de Flink.
Console
Para crear un clúster de Dataproc Flink con la Google Cloud consola, sigue estos pasos:
Abre la página Crea un clúster de Dataproc en Compute Engine.
- Se selecciona el panel Configura el clúster.
- En la sección Control de versiones, confirma o cambia el tipo y la versión de la imagen. La versión de la imagen del clúster determina la versión del componente de Flink instalado en el clúster.
- La versión de la imagen debe ser 1.5 o superior para activar el componente de Flink en el clúster (consulta las versiones compatibles de Dataproc para ver las listas de las versiones de los componentes incluidas en cada versión de la imagen de Dataproc).
- La versión de imagen debe ser [TBD] o posterior para ejecutar trabajos de Flink a través de la API de Dataproc Jobs (consulta Ejecuta trabajos de Flink en Dataproc).
- En la sección Componentes, haz lo siguiente:
- En Puerta de enlace de componentes, selecciona Habilitar puerta de enlace de componentes. Debes habilitar la puerta de enlace de componentes para activar el vínculo de la puerta de enlace de componentes a la IU del servidor de historial de Flink. Habilitar la puerta de enlace de componentes también permite el acceso a la interfaz web del administrador de trabajos de Flink que se ejecuta en el clúster de Flink.
- En Componentes opcionales, selecciona Flink y otros componentes opcionales para activar en tu clúster.
- En la sección Control de versiones, confirma o cambia el tipo y la versión de la imagen. La versión de la imagen del clúster determina la versión del componente de Flink instalado en el clúster.
Haz clic en el panel Personalizar clúster (opcional).
En la sección Propiedades del clúster, haz clic en Agregar propiedades para cada propiedad del clúster opcional que desees agregar a tu clúster. Puedes agregar propiedades con el prefijo
flinkpara configurar las propiedades de Flink en/etc/flink/conf/flink-conf.yaml, que actuarán como valores predeterminados para las aplicaciones de Flink que ejecutes en el clúster.Ejemplos:
- Establece
flink:historyserver.archive.fs.dirpara especificar la ubicación de Cloud Storage en la que se escribirán los archivos del historial de trabajos de Flink (el servidor del historial de Flink que se ejecuta en el clúster de Flink usará esta ubicación). - Establece las ranuras de tareas de Flink con
flink:taskmanager.numberOfTaskSlots=n.
- Establece
En la sección Metadatos personalizados del clúster, haz clic en Agregar metadatos para agregar metadatos opcionales. Por ejemplo, agrega
flink-start-yarn-sessiontruepara ejecutar el daemon de Flink en YARN (/usr/bin/flink-yarn-daemon) en segundo plano en el nodo instancia principal del clúster para iniciar una sesión de Flink en YARN (consulta Modo de sesión de Flink).
Si usas la versión 2.0 o una anterior de la imagen de Dataproc, haz clic en el panel Administrar seguridad (opcional) y, luego, en Acceso al proyecto, selecciona
Enables the cloud-platform scope for this cluster. El alcance decloud-platformestá habilitado de forma predeterminada cuando creas un clúster que usa la versión 2.1 o posterior de la imagen de Dataproc.
- Se selecciona el panel Configura el clúster.
Haz clic en Crear para generar el clúster.
gcloud
Para crear un clúster de Dataproc Flink con gcloud CLI, ejecuta el siguiente comando gcloud dataproc clusters create de forma local en una ventana de la terminal o en Cloud Shell:
gcloud dataproc clusters create CLUSTER_NAME \ --region=REGION \ --image-version=DATAPROC_IMAGE_VERSION \ --optional-components=FLINK \ --enable-component-gateway \ --properties=PROPERTIES ... other flags
Notas:
- CLUSTER_NAME: Especifica el nombre del clúster.
- REGION: Especifica una región de Compute Engine en la que se ubicará el clúster.
DATAPROC_IMAGE_VERSION: De manera opcional, especifica la versión de la imagen que se usará en el clúster. La versión de la imagen del clúster determina la versión del componente de Flink instalado en el clúster.
La versión de la imagen debe ser 1.5 o superior para activar el componente de Flink en el clúster (consulta las versiones compatibles de Dataproc para ver las listas de las versiones de los componentes incluidos en cada versión de la imagen de Dataproc).
La versión de la imagen debe ser [TBD] o posterior para ejecutar trabajos de Flink a través de la API de Dataproc Jobs (consulta Ejecuta trabajos de Flink en Dataproc).
--optional-components: Debes especificar el componenteFLINKpara ejecutar trabajos de Flink y el servicio web de Flink HistoryServer en el clúster.--enable-component-gateway: Debes habilitar la puerta de enlace de componentes para activar el vínculo de la puerta de enlace de componentes a la IU del servidor de historial de Flink. Habilitar la puerta de enlace de componentes también permite acceder a la interfaz web del administrador de trabajos de Flink que se ejecuta en el clúster de Flink.PROPERTIES. De manera opcional, especifica una o más propiedades del clúster.
Cuando creas clústeres de Dataproc con versiones de imagen
2.0.67+ y2.1.15+, puedes usar la marca--propertiespara configurar las propiedades de Flink en/etc/flink/conf/flink-conf.yamlque actuarán como valores predeterminados para las aplicaciones de Flink que ejecutes en el clúster.Puedes configurar
flink:historyserver.archive.fs.dirpara especificar la ubicación de Cloud Storage en la que se escribirán los archivos del historial de trabajos de Flink (el servidor de historial de Flink que se ejecuta en el clúster de Flink usará esta ubicación).Ejemplo de varias propiedades:
--properties=flink:historyserver.archive.fs.dir=gs://my-bucket/my-flink-cluster/completed-jobs,flink:taskmanager.numberOfTaskSlots=2Otras marcas:
- Puedes agregar la marca opcional
--metadata flink-start-yarn-session=truepara ejecutar el daemon de Flink en YARN (/usr/bin/flink-yarn-daemon) en segundo plano en el nodo instancia principal del clúster para iniciar una sesión de Flink en YARN (consulta Modo de sesión de Flink).
- Puedes agregar la marca opcional
Cuando usas versiones de imagen 2.0 o anteriores, puedes agregar la marca
--scopes=https://www.googleapis.com/auth/cloud-platformpara habilitar el acceso a las APIs de Google Cloud por parte de tu clúster (consulta Prácticas recomendadas para los permisos). El alcance decloud-platformestá habilitado de forma predeterminada cuando creas un clúster que usa la versión 2.1 o posterior de la imagen de Dataproc.
API
Para crear un clúster de Dataproc Flink con la API de Dataproc, envía una solicitud clusters.create de la siguiente manera:
Notas:
Establece SoftwareConfig.Component en
FLINK.De manera opcional, puedes establecer
SoftwareConfig.imageVersionpara especificar la versión de imagen que se usará en el clúster. La versión de la imagen del clúster determina la versión del componente de Flink instalado en el clúster.La versión de la imagen debe ser 1.5 o superior para activar el componente de Flink en el clúster (consulta las versiones compatibles de Dataproc para ver las listas de las versiones de los componentes incluidos en cada versión de la imagen de Dataproc).
La versión de la imagen debe ser [TBD] o posterior para ejecutar trabajos de Flink a través de la API de Dataproc Jobs (consulta Ejecuta trabajos de Flink en Dataproc).
Establece EndpointConfig.enableHttpPortAccess en
truepara habilitar el vínculo de Component Gateway a la IU del servidor de historial de Flink. Habilitar la puerta de enlace de componentes también permite acceder a la interfaz web del administrador de trabajos de Flink que se ejecuta en el clúster de Flink.De manera opcional, puedes establecer
SoftwareConfig.propertiespara especificar una o más propiedades del clúster.- Puedes especificar propiedades de Flink que actuarán como valores predeterminados para las aplicaciones de Flink que ejecutes en el clúster. Por ejemplo, puedes configurar
flink:historyserver.archive.fs.dirpara especificar la ubicación de Cloud Storage en la que se escribirán los archivos del historial de trabajos de Flink (el servidor de historial de Flink que se ejecuta en el clúster de Flink usará esta ubicación).
- Puedes especificar propiedades de Flink que actuarán como valores predeterminados para las aplicaciones de Flink que ejecutes en el clúster. Por ejemplo, puedes configurar
De forma opcional, puedes establecer lo siguiente:
GceClusterConfig.metadata. Por ejemplo, para especificarflink-start-yarn-sessiontruepara ejecutar el daemon de Flink en YARN (/usr/bin/flink-yarn-daemon) en segundo plano en el nodo instancia principal del clúster para iniciar una sesión de Flink en YARN (consulta Modo de sesión de Flink).- GceClusterConfig.serviceAccountScopes en
https://www.googleapis.com/auth/cloud-platform(permiso decloud-platform) cuando se usan versiones de imagen 2.0 o anteriores para habilitar el acceso a las APIs de Google Cloudpor parte de tu clúster (consulta la práctica recomendada sobre permisos). El alcance decloud-platformestá habilitado de forma predeterminada cuando creas un clúster que usa la versión 2.1 o posterior de la imagen de Dataproc.
Después de crear un clúster de Flink
- Usa el vínculo
Flink History Serveren la puerta de enlace de componentes para ver el servidor de historial de Flink que se ejecuta en el clúster de Flink. - Usa
YARN ResourceManager linken la puerta de enlace de componentes para ver la interfaz web del administrador de trabajos de Flink que se ejecuta en el clúster de Flink . - Crea un servidor de historial persistente de Dataproc para ver los archivos del historial de trabajos de Flink escritos por clústeres de Flink existentes y borrados.
Ejecuta trabajos de Flink con el recurso Jobs de Dataproc
Puedes ejecutar trabajos de Flink con el recurso Jobs de Dataproc desde laGoogle Cloud consola, Google Cloud CLI o la API de Dataproc.
Console
Para enviar un trabajo de conteo de palabras de Flink de muestra desde la consola, haz lo siguiente:
Abre la página de Dataproc Enviar un trabajo (Submit a job) en la consola deGoogle Cloud en tu navegador.
Completa los campos de la página Enviar un trabajo:
- En Clúster (Cluster), selecciona el nombre del clúster que quieres elegir de la lista.
- Establece Tipo de trabajo en
Flink. - Establece Clase principal o jar (Main class or jar) en
org.apache.flink.examples.java.wordcount.WordCount. - Establece Archivos JAR en
file:///usr/lib/flink/examples/batch/WordCount.jar.file:///denota un archivo ubicado en el clúster. Dataproc instalóWordCount.jarcuando creó el clúster de Flink.- Este campo también acepta una ruta de Cloud Storage (
gs://BUCKET/JARFILE) o una ruta del sistema de archivos distribuido de Hadoop (HDFS) (hdfs://PATH_TO_JAR).
Haz clic en Enviar.
- Los resultados del controlador de trabajos se muestran en la página Detalles del trabajo.

- Los trabajos de Flink se enumeran en la página Trabajos de Dataproc en la Google Cloud consola.
- Haz clic en Detener o Borrar en la página Trabajos o Detalles del trabajo para detener o borrar un trabajo.
gcloud
Para enviar un trabajo de Flink a un clúster de Dataproc Flink, ejecuta el comando gcloud dataproc jobs submit de gcloud CLI de forma local en una ventana de terminal o en Cloud Shell.
gcloud dataproc jobs submit flink \ --cluster=CLUSTER_NAME \ --region=REGION \ --class=MAIN_CLASS \ --jar=JAR_FILE \ -- JOB_ARGS
Notas:
- CLUSTER_NAME: Especifica el nombre del clúster de Dataproc Flink al que se enviará el trabajo.
- REGION: Especifica una región de Compute Engine en la que se ubica el clúster.
- MAIN_CLASS: Especifica la clase
mainde tu aplicación de Flink, como la siguiente:org.apache.flink.examples.java.wordcount.WordCount
- JAR_FILE: Especifica el archivo JAR de la aplicación de Flink. Puedes especificar lo siguiente:
- Un archivo JAR instalado en el clúster, con el prefijo
file:///` prefix:file:///usr/lib/flink/examples/streaming/TopSpeedWindowing.jarfile:///usr/lib/flink/examples/batch/WordCount.jar
- Un archivo .jar en Cloud Storage:
gs://BUCKET/JARFILE - Un archivo jar en HDFS:
hdfs://PATH_TO_JAR
- Un archivo JAR instalado en el clúster, con el prefijo
JOB_ARGS: De manera opcional, agrega argumentos de trabajo después del guion doble (
--).Después de enviar el trabajo, el resultado del controlador de trabajos se muestra en la terminal local o de Cloud Shell.
Program execution finished Job with JobID 829d48df4ebef2817f4000dfba126e0f has finished. Job Runtime: 13610 ms ... (after,1) (and,12) (arrows,1) (ay,1) (be,4) (bourn,1) (cast,1) (coil,1) (come,1)
REST
En esta sección, se muestra cómo enviar un trabajo de Flink a un clúster de Flink de Dataproc con la API de jobs.submit de Dataproc.
Antes de usar cualquiera de los datos de solicitud a continuación, realiza los siguientes reemplazos:
- PROJECT_ID: Google Cloud ID del proyecto
- REGION: región del clúster
- CLUSTER_NAME: Especifica el nombre del clúster de Dataproc Flink al que se enviará el trabajo.
Método HTTP y URL:
POST https://dataproc.googleapis.com/v1/projects/PROJECT_ID/regions/REGION/jobs:submit
Cuerpo JSON de la solicitud:
{
"job": {
"placement": {
"clusterName": "CLUSTER_NAME"
},
"flinkJob": {
"mainClass": "org.apache.flink.examples.java.wordcount.WordCount",
"jarFileUris": [
"file:///usr/lib/flink/examples/batch/WordCount.jar"
]
}
}
}
Para enviar tu solicitud, expande una de estas opciones:
Deberías recibir una respuesta JSON similar a la que se muestra a continuación:
{
"reference": {
"projectId": "PROJECT_ID",
"jobId": "JOB_ID"
},
"placement": {
"clusterName": "CLUSTER_NAME",
"clusterUuid": "CLUSTER_UUID"
},
"flinkJob": {
"mainClass": "org.apache.flink.examples.java.wordcount.WordCount",
"args": [
"1000"
],
"jarFileUris": [
"file:///usr/lib/flink/examples/batch/WordCount.jar"
]
},
"status": {
"state": "PENDING",
"stateStartTime": "2020-10-07T20:16:21.759Z"
},
"jobUuid": "JOB_UUID"
}
- Los trabajos de Flink se enumeran en la página Trabajos de Dataproc en la Google Cloud consola.
- Puedes hacer clic en Detener o Borrar en la página Trabajos o Detalles del trabajo de la consola de Google Cloud para detener o borrar un trabajo.
Ejecuta trabajos de Flink con la CLI de flink
En lugar de ejecutar trabajos de Flink con el recurso Jobs de Dataproc, puedes ejecutar trabajos de Flink en el nodo principal de tu clúster de Flink con la CLI de flink.
En las siguientes secciones, se describen diferentes formas de ejecutar un trabajo de la CLI de flink en tu clúster de Dataproc Flink.
Establece una conexión SSH con el nodo principal: Usa la utilidad SSH para abrir una ventana de terminal en la VM instancia principal del clúster.
Establece la ruta de acceso de clase: Inicializa la ruta de acceso de clase de Hadoop desde la ventana de la terminal SSH en la VM instancia principal del clúster de Flink:
export HADOOP_CLASSPATH=$(hadoop classpath)Ejecuta trabajos de Flink: Puedes ejecutar trabajos de Flink en diferentes modos de implementación en YARN: modo de aplicación, por trabajo y de sesión.
Modo de aplicación: El modo de aplicación de Flink es compatible con la versión 2.0 y posteriores de la imagen de Dataproc. En este modo, se ejecuta el método
main()del trabajo en el administrador de trabajos de YARN. El clúster se apaga después de que finaliza el trabajo.Ejemplo de envío de trabajo:
flink run-application \ -t yarn-application \ -Djobmanager.memory.process.size=1024m \ -Dtaskmanager.memory.process.size=2048m \ -Djobmanager.heap.mb=820 \ -Dtaskmanager.heap.mb=1640 \ -Dtaskmanager.numberOfTaskSlots=2 \ -Dparallelism.default=4 \ /usr/lib/flink/examples/batch/WordCount.jarEnumera los trabajos en ejecución:
./bin/flink list -t yarn-application -Dyarn.application.id=application_XXXX_YYPara cancelar un trabajo en ejecución, haz lo siguiente:
./bin/flink cancel -t yarn-application -Dyarn.application.id=application_XXXX_YY <jobId>Modo por trabajo: En este modo de Flink, se ejecuta el método
main()del trabajo en el cliente.Ejemplo de envío de trabajo:
flink run \ -m yarn-cluster \ -p 4 \ -ys 2 \ -yjm 1024m \ -ytm 2048m \ /usr/lib/flink/examples/batch/WordCount.jarModo de sesión: Inicia una sesión de Flink en YARN de larga duración y, luego, envía uno o más trabajos a la sesión.
Inicia una sesión: Puedes iniciar una sesión de Flink de una de las siguientes maneras:
Crea un clúster de Flink y agrega la marca
--metadata flink-start-yarn-session=trueal comandogcloud dataproc clusters create(consulta Crea un clúster de Dataproc Flink). Con esta marca habilitada, después de que se crea el clúster, Dataproc ejecuta/usr/bin/flink-yarn-daemonpara iniciar una sesión de Flink en el clúster.El ID de la aplicación de YARN de la sesión se guarda en
/tmp/.yarn-properties-${USER}. Puedes solicitar el ID con el comandoyarn application -list.Ejecuta la secuencia de comandos de Flink
yarn-session.sh, que está preinstalada en la VM instancia principal del clúster, con parámetros de configuración personalizados:Ejemplo con parámetros de configuración personalizados:
/usr/lib/flink/bin/yarn-session.sh \ -s 1 \ -jm 1024m \ -tm 2048m \ -nm flink-dataproc \ --detachedEjecuta la secuencia de comandos de wrapper de
/usr/bin/flink-yarn-daemonde Flink con la configuración predeterminada:. /usr/bin/flink-yarn-daemon
Envía un trabajo a una sesión: Ejecuta el siguiente comando para enviar un trabajo de Flink a la sesión.
flink run -m <var>FLINK_MASTER_URL</var>/usr/lib/flink/examples/batch/WordCount.jar- FLINK_MASTER_URL: Es la URL, incluidos el host y el puerto, de la VM principal de Flink en la que se ejecutan los trabajos.
Quita el
http:// prefixde la URL. Esta URL se muestra en el resultado del comando cuando inicias una sesión de Flink. Puedes ejecutar el siguiente comando para enumerar esta URL en el campoTracking-URL:
yarn application -list -appId=<yarn-app-id> | sed 's#http://##' ```- FLINK_MASTER_URL: Es la URL, incluidos el host y el puerto, de la VM principal de Flink en la que se ejecutan los trabajos.
Quita el
Enumera los trabajos en una sesión: Para enumerar los trabajos de Flink en una sesión, haz una de las siguientes acciones:
Ejecuta
flink listsin argumentos. El comando busca el ID de la aplicación de YARN de la sesión en/tmp/.yarn-properties-${USER}.Obtén el ID de la aplicación de YARN de la sesión desde
/tmp/.yarn-properties-${USER}o el resultado deyarn application -listy, luego, ejecuta<code>flink list -yid YARN_APPLICATION_ID.Ejecuta
flink list -m FLINK_MASTER_URL.
Detén una sesión: Para detener la sesión, obtén el ID de la aplicación de YARN de la sesión desde
/tmp/.yarn-properties-${USER}o el resultado deyarn application -listy, luego, ejecuta cualquiera de los siguientes comandos:echo "stop" | /usr/lib/flink/bin/yarn-session.sh -id YARN_APPLICATION_IDyarn application -kill YARN_APPLICATION_ID
Ejecuta trabajos de Apache Beam en Flink
Puedes ejecutar trabajos de Apache Beam en Dataproc mediante FlinkRunner.
Puedes ejecutar trabajos de Beam en Flink de las siguientes maneras:
- Trabajos de Java Beam
- Trabajos de Portable Beam
Trabajos de Java Beam
Empaqueta tus trabajos de Beam en un archivo JAR. Proporciona el archivo JAR empaquetado con las dependencias necesarias para ejecutar el trabajo.
En el siguiente ejemplo, se ejecuta un trabajo de Java Beam desde el nodo principal del clúster de Dataproc.
Crea un clúster de Dataproc con el componente Flink habilitado.
gcloud dataproc clusters create CLUSTER_NAME \ --optional-components=FLINK \ --image-version=DATAPROC_IMAGE_VERSION \ --region=REGION \ --enable-component-gateway \ --scopes=https://www.googleapis.com/auth/cloud-platform--optional-components: Flink.--image-version: Es la versión de la imagen del clúster, que determina la versión de Flink instalada en el clúster (por ejemplo, consulta las versiones de componente de Apache Flink enumeradas para las cuatro versiones 2.0.x más recientes y la cuatro anteriores).--region: Es una región de Dataproc compatible.--enable-component-gateway: Habilita el acceso a la IU del administrador de trabajo de Flink.--scopes: Habilita el acceso a las APIs de Google Cloud tu clúster (consulta la práctica recomendada sobre permisos). El alcance decloud-platformestá habilitado de forma predeterminada (no es necesario que incluyas este parámetro de configuración de la marca) cuando creas un clúster que usa la versión de imagen 2.1 de Dataproc o una posterior.
Usa la utilidad de SSH para abrir una ventana de terminal en el nodo instancia principal del clúster de Flink.
Inicia una sesión de Flink en YARN en el nodo instancia principal del clúster de Dataproc.
. /usr/bin/flink-yarn-daemonToma nota de la versión de Flink en tu clúster de Dataproc.
flink --versionEn tu máquina local, genera el ejemplo de recuento de palabras canónicos de Beam en Java.
Elige una versión de Beam compatible con la versión de Flink en tu clúster de Dataproc. Consulta la tabla Compatibilidad de versiones de Flink que enumera la compatibilidad de versiones de Beam-Flink.
Abre el archivo POM generado. Verifica la versión del ejecutor de Flink de Beam que especifica la etiqueta
<flink.artifact.name>. Si la versión del ejecutor de Flink de Beam en el nombre del artefacto de Flink no coincide con la versión de Flink en tu clúster, actualiza el número de versión para que coincida.mvn archetype:generate \ -DarchetypeGroupId=org.apache.beam \ -DarchetypeArtifactId=beam-sdks-java-maven-archetypes-examples \ -DarchetypeVersion=BEAM_VERSION \ -DgroupId=org.example \ -DartifactId=word-count-beam \ -Dversion="0.1" \ -Dpackage=org.apache.beam.examples \ -DinteractiveMode=falseEmpaqueta el ejemplo de conteo de palabras.
mvn package -Pflink-runnerSube el archivo uber JAR empaquetado,
word-count-beam-bundled-0.1.jar(~135 MB) al nodo principal del clúster de Dataproc. Puedes usargcloud storage cppara transferencias de archivos más rápidas a tu clúster de Dataproc desde Cloud Storage.En tu terminal local, crea un bucket de Cloud Storage y sube el archivo uber JAR.
gcloud storage buckets create BUCKET_NAMEgcloud storage cp target/word-count-beam-bundled-0.1.jar gs://BUCKET_NAME/En el nodo principal de Dataproc, descarga el archivo uber JAR.
gcloud storage cp gs://BUCKET_NAME/word-count-beam-bundled-0.1.jar .
Ejecutar el trabajo de Java Beam en el nodo principal del clúster de Dataproc
flink run -c org.apache.beam.examples.WordCount word-count-beam-bundled-0.1.jar \ --runner=FlinkRunner \ --output=gs://BUCKET_NAME/java-wordcount-outComprueba que los resultados se hayan escrito en tu bucket de Cloud Storage.
gcloud storage cat gs://BUCKET_NAME/java-wordcount-out-SHARD_IDDetén la sesión de Flink en YARN.
yarn application -listyarn application -kill YARN_APPLICATION_ID
Trabajos de Portable Beam
Para ejecutar trabajos de Beam escritos en Python, Go y otros lenguajes compatibles, puedes usar FlinkRunner y PortableRunner como se describe en la página del ejecutor de Flink de Beam (también consulta la hoja de ruta del marco de trabajo de portabilidad).
En el siguiente ejemplo, se ejecuta un trabajo portátil de Beam en Python desde el nodo principal del clúster de Dataproc.
Crea un clúster de Dataproc con los componentes Flink y Docker habilitados.
gcloud dataproc clusters create CLUSTER_NAME \ --optional-components=FLINK,DOCKER \ --image-version=DATAPROC_IMAGE_VERSION \ --region=REGION \ --enable-component-gateway \ --scopes=https://www.googleapis.com/auth/cloud-platformNotas:
--optional-components: Flink y Docker.--image-version: Es la versión de la imagen del clúster, que determina la versión de Flink instalada en el clúster (por ejemplo, consulta las versiones de componente de Apache Flink enumeradas para las cuatro versiones 2.0.x más recientes y las cuatro anteriores).--region: Es una región de Dataproc disponible.--enable-component-gateway: Habilita el acceso a la IU del administrador de trabajo de Flink.--scopes: Habilita el acceso a las APIs de tu clúster (consulta la práctica recomendada sobre permisos). Google Cloud El alcance decloud-platformestá habilitado de forma predeterminada (no es necesario que incluyas este parámetro de configuración de la marca) cuando creas un clúster que usa la versión de imagen 2.1 de Dataproc o una posterior.
Usa gcloud CLI de forma local o en Cloud Shell para crear un bucket de Cloud Storage. Especificarás BUCKET_NAME cuando ejecutes un programa de recuento de palabras de ejemplo.
gcloud storage buckets create BUCKET_NAMEEn una ventana de terminal de la VM del clúster, inicia una sesión de Flink en YARN. Anota la URL de la instancia principal de Flink, la dirección de la instancia principal de Flink en la que se ejecutan los trabajos. Especificarás FLINK_MASTER_URL cuando ejecutes un programa de recuento de palabras de muestra.
. /usr/bin/flink-yarn-daemonMuestra y toma nota de la versión de Flink que ejecuta el clúster de Dataproc. Especificarás FLINK_VERSION cuando ejecutes un programa de recuento de palabras de muestra.
flink --versionInstala las bibliotecas de Python necesarias para el trabajo en el nodo instancia principal del clúster.
Instala una versión de Beam que sea compatible con la versión de Flink en el clúster.
python -m pip install apache-beam[gcp]==BEAM_VERSIONEjecuta el ejemplo de recuento de palabras en el nodo instancia principal del clúster.
python -m apache_beam.examples.wordcount \ --runner=FlinkRunner \ --flink_version=FLINK_VERSION \ --flink_master=FLINK_MASTER_URL --flink_submit_uber_jar \ --output=gs://BUCKET_NAME/python-wordcount-outNotas:
--runner:FlinkRunner.--flink_version: FLINK_VERSION, que se mencionó anteriormente.--flink_master: FLINK_MASTER_URL, que se mencionó anteriormente.--flink_submit_uber_jar: Usa el uber JAR para ejecutar el trabajo de Beam.--output: BUCKET_NAME, que se creó anteriormente.
Verifica que los resultados se hayan escrito en tu bucket.
gcloud storage cat gs://BUCKET_NAME/python-wordcount-out-SHARD_IDDetén la sesión de Flink en YARN.
- Obtén el ID de la aplicación.
yarn application -list1. Insert the <var>YARN_APPLICATION_ID</var>, then stop the session.yarn application -kill
Ejecuta Flink en un clúster de Kerberized
El componente Flink de Dataproc admite clústeres con Kerberos. Se necesita un ticket Kerberos válido para enviar y continuar un trabajo de Flink o iniciar un clúster de Flink. De forma predeterminada, un ticket de Kerberos sigue siendo válido durante siete días.
Accede a la IU del administrador de trabajos de Flink
La interfaz web del administrador de trabajo de Flink está disponible mientras se ejecuta un clúster de Flink o un clúster de sesión de Flink. Para usar la interfaz web, haz lo siguiente:
- Crea un clúster de Dataproc Flink.
- Después de la creación del clúster, haz clic en el vínculo ResourceManager de YARN de la puerta de enlace de componentes en la pestaña de interfaz web en la página Detalles del clúster en la consola de Google Cloud .
- En la IU de Resource Manager de YARN, identifica la entrada de la aplicación del clúster de Flink. Según el estado de finalización de un trabajo, se mostrará el vínculo ApplicationMaster o History.
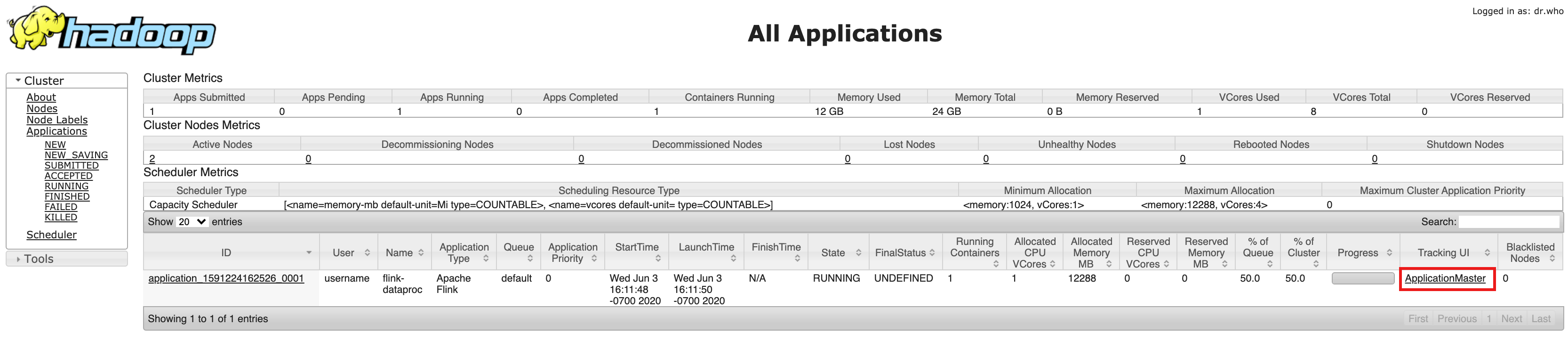
- En un trabajo de transmisión de larga duración, haz clic en el vínculo ApplicationManager para abrir el panel de Flink; para un trabajo completado, haz clic en el vínculo Historial para ver los detalles del trabajo.
