Diese Seite bietet eine Übersicht über den Pipelinelebenszyklus – vom Pipelinecode zu einem Dataflow-Job.
Auf dieser Seite werden die folgenden Konzepte erläutert:
- Was eine Ausführungsgrafik ist und wie eine Apache Beam-Pipeline zu einem Dataflow-Job wird.
- So verarbeitet Dataflow Fehler.
- So parallelisiert und verteilt Dataflow die Verarbeitungslogik der Pipeline automatisch an die Worker, die Ihren Job ausführen.
- Joboptimierungen, die Dataflow vornehmen könnte
Ausführungsgrafik
Wenn Sie das Dataflow-Pipeline ausführen, erstellt Dataflow anhand des für das Pipeline-Objekt verwendeten Codes eine Ausführungsgrafik. Diese enthält alle Transformationen sowie die zugehörigen Verarbeitungsfunktionen, wie etwa DoFn-Objekte. Dies ist die Ausführungsgrafik der Pipeline. Die Phase wird als Grafikerstellungszeit bezeichnet.
Während die Grafik erstellt wird, führt Apache Beam den Code lokal vom Haupteinstiegspunkt des Pipelinecodes aus, stoppt bei den Aufrufen einer Quelle, einer Senke oder eines Transformationsschritts und wandelt diese Aufrufe in Knoten der Grafik um.
Folglich wird ein Stück Code, das sich im Einstiegspunkt einer Pipeline (Java- und Go-Methode main oder die oberste Ebene eines Python-Skripts) befindet, lokal auf dem Computer ausgeführt, auf dem die Pipeline ausgeführt wird. Derselbe Code, der in einer Methode eines DoFn-Objekts deklariert ist, wird in den Dataflow-Workern ausgeführt.
Das in den Apache Beam SDKs enthaltene WordCount enthält eine Reihe von Transformationen zum Lesen, Extrahieren, Zählen, Formatieren und Schreiben der einzelnen Wörter in einer Textsammlung. Außerdem wird zu jedem Wort angegeben, wie oft es vorkommt. Das folgende Diagramm zeigt, wie die Transformationen in der Pipeline von WordCount zu einer Ausführungsgrafik erweitert werden:
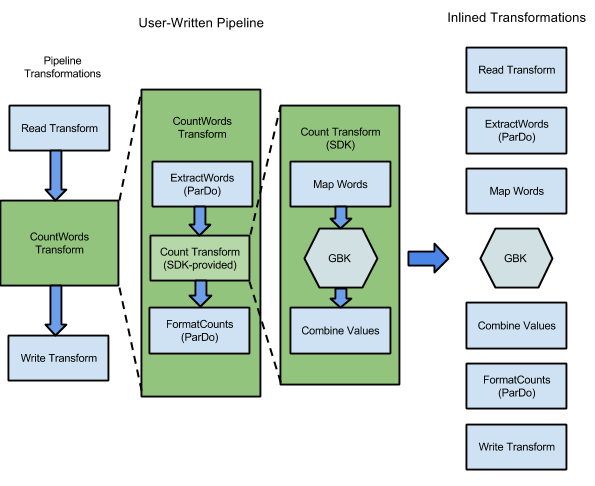
Abbildung 1: Ausführungsgrafik des Beispiels WordCount
Die Ausführungsgrafik weicht oft von der Reihenfolge ab, in der Sie die Transformationen beim Erstellen der Pipeline angegeben haben. Der Unterschied ist, dass der Dataflow-Dienst verschiedene Optimierungen und Zusammenlegungen in der Ausführungsgrafik vornimmt, bevor diese in verwalteten Cloudressourcen ausgeführt wird. Der Dataflow-Dienst berücksichtigt beim Ausführen der Pipeline Datenabhängigkeiten. Die Schritte ohne Datenabhängigkeiten zwischen ihnen können jedoch in beliebiger Reihenfolge ausgeführt werden.
Wenn Sie die von Dataflow für die Pipeline erstellte, nicht optimierte Ausführungsgrafik sehen möchten, wählen Sie den Job auf der Dataflow-Monitoring-Oberfläche aus. Weitere Informationen zum Aufrufen von Jobs finden Sie unter Dataflow-Monitoring-Oberfläche verwenden.
Apache Beam prüft während der Grafikerstellung, ob alle Ressourcen, auf die die Pipeline verweist (wie Cloud Storage-Buckets, BigQuery-Tabellen und Pub/Sub-Themen und -Abos), tatsächlich vorhanden und zugänglich sind. Die Prüfung erfolgt über Standard-API-Aufrufe der jeweiligen Dienste. Daher ist es wichtig, dass das zum Ausführen einer Pipeline verwendete Nutzerkonto eine funktionierende Verbindung zu den erforderlichen Diensten und die Berechtigung zum Aufrufen von deren APIs hat. Bevor die Pipeline an den Dataflow-Dienst gesendet wird, prüft Apache Beam auch, ob weitere Fehler vorliegen, und sorgt dafür, dass die Pipelinegrafik keine ungültigen Vorgänge enthält.
Die Ausführungsgrafik wird dann in das JSON-Format übersetzt und an den Dataflow-Dienstendpunkt übertragen.
Der Dataflow-Dienst validiert dann die JSON-Ausführungsgrafik. Durch die Validierung wird die Grafik zu einem Job im Dataflow-Dienst. Sie können den Job, die Ausführungsgrafik, den Status und die Loginformationen auf der Dataflow-Monitoring-Oberfläche aufrufen.
Java
Der Dataflow-Dienst sendet eine Antwort an den Computer, auf dem Sie das Dataflow-Programm ausführen. Diese Antwort wird im Objekt DataflowPipelineJob gekapselt, das den jobId Ihres Dataflow-Jobs enthält.
Verwenden Sie jobId für Monitoring, Verfolgung und Fehlerbehebung Ihres Jobs mithilfe der Dataflow-Monitoring-Oberfläche und der Dataflow-Befehlszeile.
Weitere Informationen finden Sie in der API-Referenz zu "DataflowPipelineJob".
Python
Der Dataflow-Dienst sendet eine Antwort an den Computer, auf dem Sie das Dataflow-Programm ausführen. Diese Antwort wird im Objekt DataflowPipelineResult gekapselt, das den job_id Ihres Dataflow-Jobs enthält.
Verwenden Sie job_id für Monitoring, Verfolgung und Fehlerbehebung Ihres Jobs mithilfe der Dataflow-Monitoring-Oberfläche und der Dataflow-Befehlszeile.
Go
Der Dataflow-Dienst sendet eine Antwort an den Computer, auf dem Sie das Dataflow-Programm ausführen. Diese Antwort wird im Objekt dataflowPipelineResult gekapselt, das den jobID Ihres Dataflow-Jobs enthält.
Verwenden Sie jobID für Monitoring, Verfolgung und Fehlerbehebung Ihres Jobs mithilfe der Dataflow-Monitoring-Oberfläche und der Dataflow-Befehlszeile.
Die Grafik wird auch erstellt, wenn Sie die Pipeline lokal ausführen. Es erfolgt jedoch keine Übersetzung in das JSON-Format und keine Übertragung an den Dienst. Die Grafik wird stattdessen lokal auf demselben Computer ausgeführt, auf dem Sie Dataflow gestartet haben. Weitere Informationen finden Sie unter PipelineOptions für die lokale Ausführung konfigurieren.
Verarbeitung von Fehlern und Ausnahmen
Die Pipeline kann während der Datenverarbeitung Ausnahmen ausgeben. Einige dieser Fehler sind temporär, wie etwa vorübergehende Probleme beim Zugriff auf einen externen Dienst. Andere Fehler sind permanent, z. B. Fehler, die durch beschädigte oder nicht parsingfähige Eingabedaten verursacht werden, oder Nullzeiger während der Berechnung.
Dataflow verarbeitet Elemente in beliebigen Gruppierungen. Sollte für eines der Elemente in der Gruppierung ein Fehler ausgegeben werden, wird die gesamte Gruppierung noch einmal verarbeitet. Im Batchmodus wird die Verarbeitung von Gruppierungen mit einem fehlerhaften Element viermal wiederholt. Wenn eine Gruppierung viermal fehlgeschlagen ist, fällt die gesamte Pipeline aus. Im Streamingmodus wird die Verarbeitung einer Gruppierung mit einem fehlerhaften Element unendlich oft wiederholt. Dies kann zur permanenten Blockierung der Pipeline führen.
Bei der Verarbeitung im Batchmodus tritt möglicherweise erst eine größere Anzahl einzelner Fehler auf, bevor ein kompletter Pipelinejob fehlschlägt. Dies ist der Fall, wenn eine gegebene Gruppierung nach vier Wiederholversuchen fehlschlägt. Wenn die Pipeline beispielsweise versucht, 100 Gruppierungen zu verarbeiten, kann Dataflow mehrere Hundert einzelne Fehler generieren, bevor eine Gruppierung viermal ausfällt und die Verarbeitung beendet wird.
Fehler bei Start-Workern, z. B. die Nichtinstallation von Paketen auf den Workern, sind temporär. Dieses Szenario führt zu unbeschränkten Wiederholungen und kann zur permanenten Blockierung der Pipeline führen.
Parallelisierung und Verteilung
Der Dataflow-Dienst parallelisiert und verteilt die Verarbeitungslogik der Pipeline automatisch an die Worker, die Sie der Ausführung des Jobs zuweisen. Dataflow verwendet die Abstraktionen im Programmiermodell, um Funktionen zur parallelen Verarbeitung darzustellen. Beispiel: Die ParDo-Transformationen in einer Pipeline führen Dataflow dazu, den Verarbeitungscode, der durch DoFn-Objekte dargestellt wird, automatisch auf mehrere Worker zu verteilen, die parallel ausgeführt werden sollen.
Es gibt zwei Arten von Job-Parallelität:
Horizontale Parallelität tritt auf, wenn Pipelinedaten gleichzeitig auf mehrere Worker aufgeteilt und verarbeitet werden. Die Dataflow-Laufzeitumgebung wird von einem Pool verteilter Worker bereitgestellt. Eine Pipeline hat eine höhere potenzielle Parallelität, wenn der Pool mehr Worker enthält, diese Konfiguration jedoch auch höhere Kosten verursacht. Theoretisch hat die horizontale Parallelität keine Obergrenze. Dataflow beschränkt den Worker-Pool jedoch auf 4.000 Worker, um die flottenweite Ressourcennutzung zu optimieren.
Vertikale Parallelität tritt auf, wenn Pipelinedaten von mehreren CPU-Kernen auf demselben Worker aufgeteilt und verarbeitet werden. Jeder Worker wird von einer Compute Engine-VM betrieben. Eine VM kann mehrere Prozesse ausführen, um alle ihre CPU-Kerne zu belegen. Eine VM mit mehr Kernen hat eine höhere potenzielle vertikale Parallelität, aber diese Konfiguration führt zu höheren Kosten. Eine höhere Anzahl von Kernen führt häufig zu einer höheren Speichernutzung, sodass die Anzahl der Kerne in der Regel zusammen mit der Speichergröße skaliert wird. Angesichts des physischen Grenzwerts von Computerarchitekturen ist die Obergrenze der vertikalen Parallelität viel niedriger als die obere Grenze der horizontalen Parallelität.
Verwaltete Parallelität
Standardmäßig verwaltet Dataflow automatisch die Jobparallelität. Dataflow überwacht die Laufzeitstatistiken für den Job, z. B. die CPU- und Speichernutzung, um zu bestimmen, wie der Job skaliert werden soll. Abhängig von Ihren Jobeinstellungen kann Dataflow Jobs horizontal skalieren, die alsHorizontales Autoscaling oder vertikal bezeichnet.Vertikale Skalierung. Durch die automatische Skalierung für die Parallelität werden die Jobkosten und die Jobleistung optimiert.
Zur Verbesserung der Jobleistung optimiert Dataflow auch Pipelines intern. Typische Optimierungen sind die Zusammenführungsoptimierung und die Kombinationsoptimierung. Durch das Zusammenführen von Pipelineschritten beseitigt Dataflow unnötige Kosten für die Koordinierung der Schritte in einem verteilten System und die separate Ausführung jedes einzelnen Schritts.
Faktoren, die sich auf die Parallelität auswirken
Folgende Faktoren wirken sich darauf aus, wie gut die Parallelität in Dataflow-Jobs funktioniert.
Eingabequelle
Wenn eine Eingabequelle keine Parallelität zulässt, kann der Schritt zur Aufnahme der Eingabequelle zu einem Engpass in einem Dataflow-Job werden. Wenn Sie beispielsweise Daten aus einer einzelnen komprimierten Textdatei aufnehmen, kann Dataflow die Eingabedaten nicht parallelisieren. Da die meisten Komprimierungsformate während der Aufnahme nicht willkürlich in Fragmente aufgeteilt werden können, muss Dataflow die Daten vom Anfang der Datei sequenziell lesen. Der Gesamtdurchsatz der Pipeline wird durch den nicht parallelen Teil der Pipeline verlangsamt. Die Lösung für dieses Problem besteht darin, eine skalierbarere Eingabequelle zu verwenden.
In einigen Fällen reduziert die Schrittfusion auch die Parallelität. Wenn die Eingabequelle keine Parallelität zulässt, wenn Dataflow den Datenaufnahmeschritt mit nachfolgenden Schritten zusammenführt und diesen zusammengeführten Schritt einem einzelnen Thread zuweist, wird die gesamte Pipeline möglicherweise langsamer ausgeführt.
Fügen Sie nach dem Schritt zur Aufnahme der Eingabequelle einen Reshuffle-Schritt ein, um dieses Szenario zu vermeiden. Weitere Informationen finden Sie im Abschnitt Zusammenführung verhindern dieses Dokuments.
Standard-Fanout und Datenform
Das Standard-Fanout eines einzelnen Transformationsschritts kann zu einem Engpass führen und die Parallelität begrenzen. Die ParDo-Transformation "High Fan-Out" kann beispielsweise zu einer Zusammenführung führen, um die Fähigkeit von Dataflow einzuschränken, die Worker-Nutzung zu optimieren. Bei einem solchen Vorgang kann die Eingabesammlung relativ wenig Elemente enthalten, der ParDo jedoch eine Ausgabe mit hundert- oder tausendmal so vielen Elementen erzeugen, gefolgt von einem anderen ParDo. Wenn der Dataflow-Dienst diese ParDo-Vorgänge zusammenführt, ist die Parallelität in diesem Schritt auf maximal die Anzahl der Elemente in der Eingabesammlung beschränkt, obwohl die dazwischenliegende PCollection viel mehr Elemente enthält.
Mögliche Lösungen finden Sie im Abschnitt Zusammenführung verhindern dieses Dokuments.
Datenform
Die Form der Daten, unabhängig davon, ob es sich um Eingabe- oder Zwischendaten handelt, kann die Parallelität einschränken.
Wenn beispielsweise auf einen GroupByKey-Schritt für einen natürlichen Schlüssel wie eine Stadt ein map- oder Combine-Schritt folgt, fasst Dataflow die beiden Schritte zusammen. Wenn der Schlüsselbereich klein ist, z. B. fünf Städte und ein Schlüssel sehr heiß ist, z. B. eine große Stadt, werden die meisten Elemente in der Ausgabe des Schritts GroupByKey auf einen Prozess verteilt. Dieser Prozess wird zu einem Engpass und verlangsamt den Job.
In diesem Beispiel können Sie die Schrittergebnisse GroupByKey in einen größeren künstlichen Schlüsselbereich verteilen, anstatt die natürlichen Schlüssel zu verwenden. Fügen Sie einen Reshuffle-Schritt zwischen dem Schritt GroupByKey und dem Schritt map oder Combine ein.
Erstellen Sie im Schritt Reshuffle den künstlichen Schlüsselbereich, z. B. mit einer hash-Funktion, um die durch die Datenform verursachte begrenzte Parallelität zu überwinden.
Weitere Informationen finden Sie im Abschnitt Zusammenführung verhindern dieses Dokuments.
Ausgabesenke
Eine Senke ist eine Transformation, die in ein externes Datenspeichersystem schreibt, z. B. eine Datei oder eine Datenbank. In der Praxis werden Senken als Standard-DoFn-Objekte modelliert und implementiert und sie werden verwendet, um eine PCollection für externe Systeme zu erfassen.
In diesem Fall enthält die PCollection die endgültigen Pipelineergebnisse. Threads, die Senken-APIs aufrufen, können parallel ausgeführt werden, um Daten in die externen Systeme zu schreiben. Standardmäßig erfolgt keine Koordination zwischen den Threads. Ohne eine Zwischenebene zum Zwischenspeichern der Schreibanfragen und zum Steuern des Ablaufs kann das externe System überlastet werden und den Schreibdurchsatz reduzieren. Wenn Sie Ressourcen durch Hinzufügen weiterer Parallelität hochskalieren, kann die Pipeline noch weiter verlangsamt werden.
Die Lösung für dieses Problem besteht darin, die Parallelität im Schreibschritt zu reduzieren.
Sie können direkt vor dem Schreibschritt einen GroupByKey-Schritt hinzufügen. Der Schritt GroupByKey gruppiert Ausgabedaten in einem kleineren Satz von Batches, um die Gesamtzahl der RPC-Aufrufe und Verbindungen zu externen Systemen zu reduzieren. Verwenden Sie beispielsweise GroupByKey, um einen Hashbereich mit 50 von 1 Million Datenpunkten zu erstellen.
Der Nachteil dieses Ansatzes ist, dass damit eine hartcodierte Begrenzung der Parallelität entsteht. Eine weitere Option besteht darin, beim Schreiben von Daten einen exponentiellen Backoff in der Senke zu implementieren. Diese Option kann nur minimale Client-Drosselung bieten.
Parallelität überwachen
Zum Überwachen der Parallelität können Sie mit der Google Cloud Console alle erkannten Nachzügler aufrufen. Weitere Informationen finden Sie unter Fehlerbehebung bei Nachzüglern in Batchjobs und Fehlerbehebung bei Nachzüglern in Streamingjobs.
Zusammenführung optimieren
Nachdem die JSON-Form der Ausführungsgrafik der Pipeline validiert wurde, ändert der Dataflow-Dienst die Grafik möglicherweise, um Optimierungen vorzunehmen.
Eine Optimierung kann das Zusammenführen mehrerer Schritte oder Transformationen in der Pipeline-Ausführungsgrafik zu einem Schritt beinhalten. Durch das Zusammenführen von Schritten muss der Dataflow-Dienst nicht jede dazwischenliegende PCollection in der Pipeline erfassen, was im Hinblick auf den Speicher- und Verarbeitungsaufwand kostspielig werden kann.
Obwohl alle beim Erstellen der Pipeline angegebenen Transformationen für den Dienst ausgeführt werden, sollten die Transformationen möglicherweise in einer anderen Reihenfolge oder als Teil einer größeren Transformation ausgeführt werden, um eine möglichst effektive Ausführung Ihrer Pipeline zu gewährleisten. zusammengeführte Transformation. Dabei berücksichtigt der Dataflow-Dienst Datenabhängigkeiten zwischen den Schritten in der Ausführungsgrafik. Ansonsten können die Schritte jedoch in beliebiger Reihenfolge ausgeführt werden.
Beispiel einer Zusammenführung
Das folgende Diagramm zeigt, wie der Dataflow-Dienst die Ausführungsgrafik des WordCount aus dem Apache Beam SDK for Java optimieren und zusammenführen kann, um die Ausführung effizienter zu gestalten:
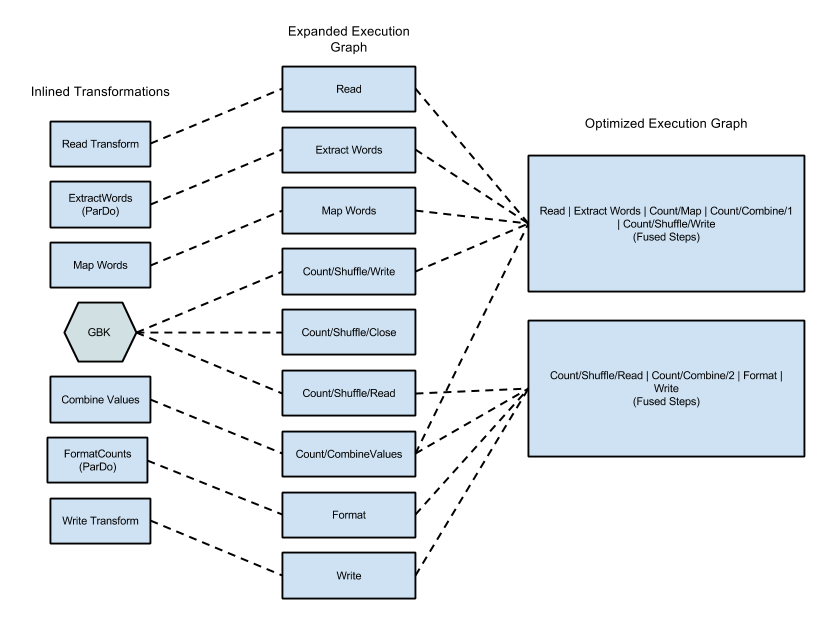
Abbildung 2: Für das WordCount-Beispiel optimierte Ausführungsgrafik
Zusammenführung vermeiden
In einigen Fällen kann Dataflow eine falsche optimale Zusammenführung von Vorgängen in der Pipeline erraten. Dies kann die Fähigkeit von Dataflow einschränken, alle verfügbaren Worker zu verwenden. In solchen Fällen können Sie verhindern, dass Dataflow optimierte Zusammenführungen durchführt.
Zur Verhinderung einer Zusammenführung dieses Schrittes können Sie der Pipeline einen Vorgang hinzufügen, der den Dataflow-Dienst zwingt, die dazwischenliegende PCollection zu erfassen. Führen Sie gegebenenfalls einen der folgenden Vorgänge aus:
- Fügen Sie einen
GroupByKeyein und heben Sie die Gruppierung nach dem erstenParDoauf. Der Dataflow-Dienst führt keineParDo-Vorgänge über eine Zusammenfassung hinweg aus. - Übergeben Sie die dazwischenliegende
PCollectionals Nebeneingabe für ein anderesParDo. Nebeneingaben werden vom Dataflow-Dienst immer erfasst. - Fügen Sie einen
Reshuffle-Schritt ein.Reshuffleverhindert eine Zusammenführung, erstellt Prüfpunkte für die Daten und führt eine Deduplizierung von Datensätzen durch. Dataflow unterstützt Reshuffle, obwohl es in der Apache Beam-Dokumentation als verworfen gekennzeichnet ist.
Zusammenführung überwachen
Sie können über die gcloud CLI oder die API in der Google Cloud Console auf die optimierten Graphen und die zusammengeführten Phasen zugreifen.
Console
Öffnen Sie auf dem Tab Ausführungsdetails des Dataflow-Jobs den Phasenworkflow in der Diagrammansicht, um die zusammengeführten Phasen und Schritte in der Console aufzurufen.
Klicken Sie im Diagramm auf die zusammengeführte Phase, um die Komponentenschritte zu sehen, die für eine Phase zusammengeführt wurden. Im Bereich Phaseninformationen werden in der Zeile Komponentenschritte die zusammengeführten Phasen angezeigt. Manchmal werden Teile einer einzelnen zusammengesetzten Transformation in mehrere Phasen zusammengeführt.
gcloud
Wenn Sie mit der gcloud CLI auf die optimierte Grafik und die zusammengeführten Phasen zugreifen möchten, führen Sie den folgenden gcloud-Befehl aus:
gcloud dataflow jobs describe --full JOB_ID --format json
Ersetzen Sie JOB_ID durch die ID Ihres Dataflow-Jobs.
Um die relevanten Bits zu extrahieren, leiten Sie die Ausgabe des Befehls gcloud an jq weiter:
gcloud dataflow jobs describe --full JOB_ID --format json | jq '.pipelineDescription.executionPipelineStage\[\] | {"stage_id": .id, "stage_name": .name, "fused_steps": .componentTransform }'
Um die Beschreibung der zusammengeführten Phasen in der Ausgabeantwortdatei anzusehen, rufen Sie im ComponentTransform-Array dasExecutionStageSummary-Objekt auf.
API
Rufen Sie project.locations.jobs.get auf, um mithilfe der API auf die optimierte Grafik und die zusammengeführten Phasen zuzugreifen.
Um die Beschreibung der zusammengeführten Phasen in der Ausgabeantwortdatei anzusehen, rufen Sie im ComponentTransform-Array dasExecutionStageSummary-Objekt auf.
Optimierung kombinieren
Zusammenführungen stellen bei umfangreichen Datenverarbeitungen ein wichtiges Konzept dar.
Dabei werden konzeptionell völlig unterschiedliche Daten vereint. Dies ist für Korrelationen extrem nützlich. Das Programmiermodell von Dataflow stellt die Aggregationsvorgänge in Form der Transformationen GroupByKey, CoGroupByKey und Combine dar.
Bei den Zusammenführungen durch Dataflow werden Daten des gesamten Datasets kombiniert, einschließlich Daten, die auf mehrere Worker verteilt sein können. Während der Zusammenführung ist es häufig am effizientesten, vor einer instanzübergreifenden Kombination so viele Daten wie möglich lokal zusammenzuführen. Wenn Sie eine Transformation vom Typ GroupByKey oder eine andere Aggregationstransformation anwenden, werden die Daten vom Dataflow-Dienst automatisch teilweise lokal kombiniert, bevor die Hauptgruppierung erfolgt.
Bei der Durchführung einer teilweisen oder mehrstufigen Kombination trifft der Dataflow-Dienst abhängig davon, ob die Pipeline mit Batch- oder Streamingdaten arbeitet, unterschiedliche Entscheidungen. Bei eingeschränkten Daten priorisiert der Dienst eine effiziente Vorgehensweise und kombiniert möglichst viel lokal. Bei uneingeschränkten Daten bevorzugt der Dienst eine geringere Latenz und führt möglicherweise keine teilweise Kombination durch, da dies die Latenz erhöhen kann.