Wenn Sie den interaktiven Apache Beam-Runner mit JupyterLab-Notebooks verwenden, können Sie Pipelines iterativ entwickeln, Ihre Pipelinegrafik prüfen und einzelne PCollections in einem REPL-Workflow (Read-Eval-Print-Loop) analysieren. Ein Tutorial in dem gezeigt wird, wie Sie den interaktiven Apache Beam-Runner mit JupyterLab-Notebooks verwenden, finden Sie unter Mit Apache Beam-Notebooks entwickeln
Diese Seite enthält Details zu erweiterten Features, die Sie mit Ihrem Apache Beam-Notebook verwenden können.
Interaktiver FlinkRunner in mit dem Notebook verwalteten Clustern
Wenn Sie interaktiv mit Daten in Produktionsgröße vom Notebook aus arbeiten möchten, können Sie FlinkRunner mit einigen allgemeinen Pipelineoptionen verwenden, um der Notebooksitzung mitzuteilen, einen langlebigen Dataproc-Cluster zu verwalteten und Ihre Beam-Pipelines verteilt auszuführen.
Vorbereitung
So verwenden Sie dieses Feature:
- die Dataproc API aktivieren
- Weisen Sie dem Dienstkonto, mit dem die Notebookinstanz für Dataproc ausgeführt wird, eine Administrator- oder Bearbeiterrolle zu.
- Verwenden Sie einen Notebook-Kernel mit der Apache Beam SDK-Version 2.40.0 oder höher.
Konfiguration
Sie müssen mindestens die folgende Konfiguration haben:
# Set a Cloud Storage bucket to cache source recording and PCollections.
# By default, the cache is on the notebook instance itself, but that does not
# apply to the distributed execution scenario.
ib.options.cache_root = 'gs://<BUCKET_NAME>/flink'
# Define an InteractiveRunner that uses the FlinkRunner under the hood.
interactive_flink_runner = InteractiveRunner(underlying_runner=FlinkRunner())
options = PipelineOptions()
# Instruct the notebook that Google Cloud is used to run the FlinkRunner.
cloud_options = options.view_as(GoogleCloudOptions)
cloud_options.project = 'PROJECT_ID'
Explizite Bestimmung (optional)
Sie können die folgenden Optionen hinzufügen.
# Change this if the pipeline needs to run in a different region
# than the default, 'us-central1'. For example, to set it to 'us-west1':
cloud_options.region = 'us-west1'
# Explicitly provision the notebook-managed cluster.
worker_options = options.view_as(WorkerOptions)
# Provision 40 workers to run the pipeline.
worker_options.num_workers=40
# Use the default subnetwork.
worker_options.subnetwork='default'
# Choose the machine type for the workers.
worker_options.machine_type='n1-highmem-8'
# When working with non-official Apache Beam releases, such as Apache Beam built from source
# code, configure the environment to use a compatible released SDK container.
# If needed, build a custom container and use it. For more information, see:
# https://beam.apache.org/documentation/runtime/environments/
options.view_as(PortableOptions).environment_config = 'apache/beam_python3.7_sdk:2.41.0 or LOCATION.pkg.dev/PROJECT_ID/REPOSITORY/your_custom_container'
Nutzung
# The parallelism is applied to each step, so if your pipeline has 10 steps, you
# end up having 10 * 10 = 100 tasks scheduled, which can be run in parallel.
options.view_as(FlinkRunnerOptions).parallelism = 10
p_word_count = beam.Pipeline(interactive_flink_runner, options=options)
word_counts = (
p_word_count
| 'read' >> ReadWordsFromText('gs://apache-beam-samples/shakespeare/kinglear.txt')
| 'count' >> beam.combiners.Count.PerElement())
# The notebook session automatically starts and manages a cluster to run
# your pipelines with the FlinkRunner.
ib.show(word_counts)
# Interactively adjust the parallelism.
options.view_as(FlinkRunnerOptions).parallelism = 150
# The BigQuery read needs a Cloud Storage bucket as a temporary location.
options.view_as(GoogleCloudOptions).temp_location = ib.options.cache_root
p_bq = beam.Pipeline(runner=interactive_flink_runner, options=options)
delays_by_airline = (
p_bq
| 'Read Dataset from BigQuery' >> beam.io.ReadFromBigQuery(
project=project, use_standard_sql=True,
query=('SELECT airline, arrival_delay '
'FROM `bigquery-samples.airline_ontime_data.flights` '
'WHERE date >= "2010-01-01"'))
| 'Rebalance Data to TM Slots' >> beam.Reshuffle(num_buckets=1000)
| 'Extract Delay Info' >> beam.Map(
lambda e: (e['airline'], e['arrival_delay'] > 0))
| 'Filter Delayed' >> beam.Filter(lambda e: e[1])
| 'Count Delayed Flights Per Airline' >> beam.combiners.Count.PerKey())
# This step reuses the existing cluster.
ib.collect(delays_by_airline)
# Describe the cluster running the pipelines.
# You can access the Flink dashboard from the printed link.
ib.clusters.describe()
# Cleans up all long-lasting clusters managed by the notebook session.
ib.clusters.cleanup(force=True)
Mit dem Notebook verwaltete Cluster
- Wenn Sie keine Pipeline-Optionen angeben, verwendet Interactive Apache Beam standardmäßig immer den zuletzt verwendeten Cluster, um eine Pipeline mit
FlinkRunnerauszuführen.- Führen Sie
ib.clusters.set_default_cluster(None)aus, um dieses Verhalten zu vermeiden, z. B. wenn Sie eine andere Pipeline in derselben Notebook-Sitzung mit einem FlinkRunner ausführen möchten, der nicht vom Notebook gehostet wird.
- Führen Sie
- Beim Instanziieren einer neuen Pipeline, die ein Projekt, eine Region und eine Bereitstellungskonfiguration verwendet, die einem vorhandenen Dataproc-Cluster zugeordnet sind, verwendet Dataflow auch den Cluster wieder. Dies ist jedoch möglicherweise nicht der zuletzt verwendete Cluster.
- Wenn jedoch eine Änderung der Bereitstellung angegeben wird, z. B. beim Ändern der Größe eines Clusters, wird ein neuer Cluster erstellt, um die gewünschte Änderung zu übernehmen. Wenn Sie die Größe eines Clusters ändern möchten, um zu verhindern, dass die Cloud-Ressourcen erschöpft werden, bereinigen Sie überflüssige Cluster mithilfe von
ib.clusters.cleanup(pipeline). - Wenn eine Flink-
master_urlangegeben ist und zu einem Cluster gehört, der von der Notebooksitzung verwaltet wird, verwendet Dataflow den verwalteten Cluster wieder.- Wenn
master_urlin der Notebooksitzung unbekannt ist, bedeutet dies, dass ein vom Nutzer selbst gehosteterFlinkRunnergewünscht wird. Im Notebook wird nichts implizit ausgeführt.
- Wenn
Fehlerbehebung
Dieser Abschnitt enthält Informationen zur Fehlerbehebung beim interaktiven FlinkRunner in mit dem Notebook verwalteten Clustern.
Flink IOException: Unzureichende Anzahl von Netzwerkpuffern
Der Einfachheit halber wird die Zwischenspeicherkonfiguration des Flink-Netzwerks nicht für die Konfiguration bereitgestellt.
Wenn die Jobgrafik zu kompliziert oder die Parallelität zu hoch eingestellt ist, könnte die Kardinalität der Schritte multipliziert mit der Parallelität zu groß sein und dazu führen, dass zu viele Aufgaben parallel geplant werden und die Ausführung fehlschlägt.
Beachten Sie die folgenden Tipps, um die Geschwindigkeit interaktiver Ausführungen zu verbessern:
- Weisen Sie einer Variablen nur die
PCollectionzu, die Sie prüfen möchten. - Prüfen Sie
PCollectionseinzeln. - Verwenden Sie Reshuffle nach High-Fanout-Transformationen.
- Passen Sie die Parallelität an die Datengröße an (manchmal ist kleiner schneller).
Die Prüfung der Daten dauert zu lange
Prüfen Sie das Flink-Dashboard für den laufenden Job. Möglicherweise sehen Sie einen Schritt, bei dem Hunderte von Aufgaben abgeschlossen wurden und nur eine übrig ist, da sich In-Flight-Daten auf einer einzelnen Maschine befinden und nicht zufällig verteilt werden.
Verwenden Sie nach einer High-Fanout-Transformation immer die erneute Zufallswiedergabe, z. B. in folgenden Fällen:
- Zeilen aus einer Datei lesen
- Zeilen aus einer BigQuery-Tabelle lesen
Ohne Reshuffle werden Fanout-Daten immer auf demselben Worker ausgeführt und können die Vorteile der Parallelität nicht nutzen.
Wie viele Worker benötige ich?
Als Faustregel gilt, dass der Flink-Cluster etwa die Anzahl der vCPUs multipliziert mit der Anzahl der Worker-Slots hat. Wenn Sie beispielsweise 40 n1-highmem-8-Worker haben, hat der Flink-Cluster höchstens 320 Slots, also 8 multipliziert mit 40.
Im Idealfall kann der Worker einen Job verwalten, der mit Hunderten von Parallelitäten liest, zuordnet und kombiniert, wodurch Tausende von Aufgaben parallel geplant werden.
Funktioniert das auch beim Streaming?
Streamingpipelines sind derzeit nicht mit dem interaktiven Flink auf Notebook-verwalteten Cluster kompatibel.
Beam SQL und beam_sql-Magie
Mit Beam SQL können Sie begrenzte und unbegrenzte PCollections mit SQL-Anweisungen abfragen. Wenn Sie in einem Apache Beam-Notebook arbeiten, können Sie die benutzerdefinierte IPython-Magie
beam_sql verwenden, um die Pipelineentwicklung zu beschleunigen.
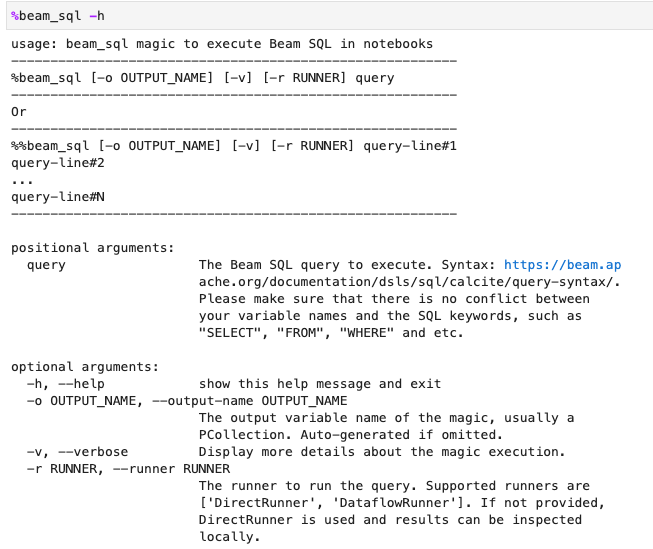
Sie können die Nutzung der Magie beam_sql mit der Option -h oder --help prüfen:
Sie können eine PCollection aus konstanten Werten erstellen:

Sie können mehrere PCollections zusammenführen:

Sie können einen Dataflow-Job mit der Option -r DataflowRunner oder --runner DataflowRunner starten:
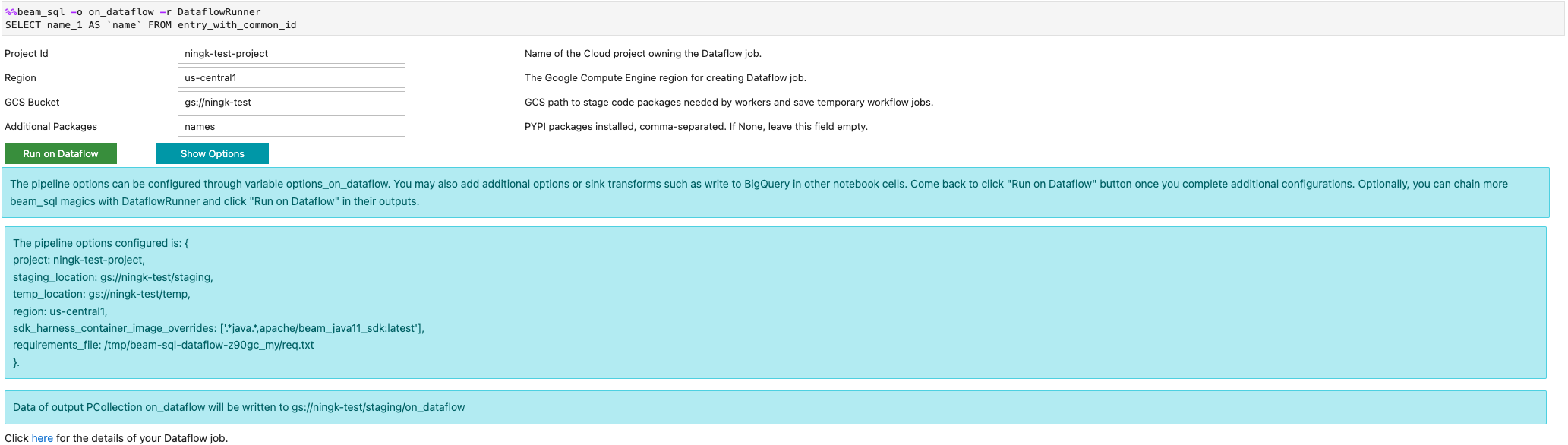
Weitere Informationen finden Sie im Beispiel-Notebook Apache Beam SQL in Notebooks.
Mit JIT-Compiler und GPU beschleunigen
Sie können Bibliotheken wie numba und GPUs verwenden, um Ihren Python-Code und Apache Beam-Pipelines zu beschleunigen. In der Apache Beam-Notebookinstanz, die mit
einer nvidia-tesla-t4-GPU erstellt wurde, kompilieren Sie zur Ausführung auf GPUs Ihren Python-Code mit
numba.cuda.jit, Optional, um die Ausführung auf CPUs zu beschleunigen, kompilieren Sie Ihren
Python-Code mit numba.jit oder numba.njit in Maschinencode.
Im folgenden Beispiel wird ein DoFn erstellt, das auf GPUs verarbeitet wird:
class Sampler(beam.DoFn):
def __init__(self, blocks=80, threads_per_block=64):
# Uses only 1 cuda grid with below config.
self.blocks = blocks
self.threads_per_block = threads_per_block
def setup(self):
import numpy as np
# An array on host as the prototype of arrays on GPU to
# hold accumulated sub count of points in the circle.
self.h_acc = np.zeros(
self.threads_per_block * self.blocks, dtype=np.float32)
def process(self, element: Tuple[int, int]):
from numba import cuda
from numba.cuda.random import create_xoroshiro128p_states
from numba.cuda.random import xoroshiro128p_uniform_float32
@cuda.jit
def gpu_monte_carlo_pi_sampler(rng_states, sub_sample_size, acc):
"""Uses GPU to sample random values and accumulates the sub count
of values within a circle of radius 1.
"""
pos = cuda.grid(1)
if pos < acc.shape[0]:
sub_acc = 0
for i in range(sub_sample_size):
x = xoroshiro128p_uniform_float32(rng_states, pos)
y = xoroshiro128p_uniform_float32(rng_states, pos)
if (x * x + y * y) <= 1.0:
sub_acc += 1
acc[pos] = sub_acc
rng_seed, sample_size = element
d_acc = cuda.to_device(self.h_acc)
sample_size_per_thread = sample_size // self.h_acc.shape[0]
rng_states = create_xoroshiro128p_states(self.h_acc.shape[0], seed=rng_seed)
gpu_monte_carlo_pi_sampler[self.blocks, self.threads_per_block](
rng_states, sample_size_per_thread, d_acc)
yield d_acc.copy_to_host()
Die folgende Abbildung zeigt das Notebook, das auf einer GPU ausgeführt wird:
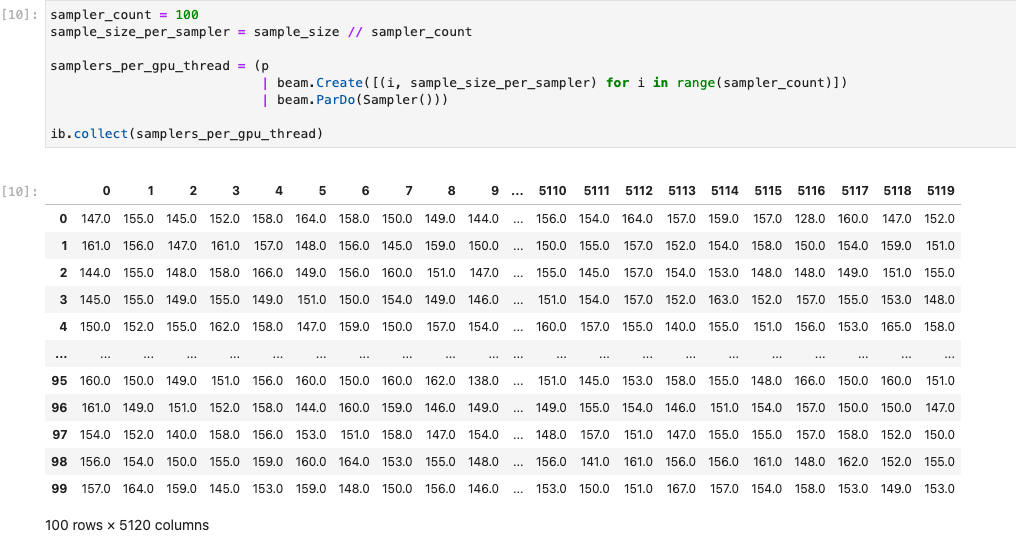
Weitere Details finden Sie im Beispiel-Notebook GPUs mit Apache Beam verwenden.
Einen benutzerdefinierten Container erstellen
Wenn Ihre Pipeline keine zusätzlichen Python-Abhängigkeiten oder ausführbaren Dateien benötigt, kann Apache Beam in den meisten Fällen automatisch seine offiziellen Container-Images verwenden, um Ihren benutzerdefinierten Code auszuführen. Diese Images enthalten viele gängige Python-Module, die weder erstellt noch explizit angegeben werden müssen.
In einigen Fällen haben Sie möglicherweise zusätzliche Python-Abhängigkeiten oder nicht von Python stammenden Abhängigkeiten. In diesen Szenarien können Sie einen benutzerdefinierten Container erstellen und zur Ausführung dem Flink-Cluster zur Verfügung stellen. Die folgende Liste bietet die Vorteile eines benutzerdefinierten Containers:
- Schnellere Einrichtung für aufeinanderfolgende und interaktive Ausführungen
- Stabile Konfigurationen und Abhängigkeiten
- Mehr Flexibilität: Sie können mehr als Python-Abhängigkeiten einrichten
Der Container-Build-Prozess kann mühsam sein, aber Sie können alles im Notebook mit dem folgenden Nutzungsmuster erledigen.
Lokalen Arbeitsbereich erstellen
Erstellen Sie zuerst ein lokales Arbeitsverzeichnis im Jupyter-Basisverzeichnis.
!mkdir -p /home/jupyter/.flink
Python-Abhängigkeiten vorbereiten
Installieren Sie als Nächstes alle zusätzlichen Python-Abhängigkeiten, die Sie verwenden können, und exportieren Sie sie in eine Anforderungsdatei.
%pip install dep_a
%pip install dep_b
...
Sie können mithilfe der Notebookmagie %%writefile eine Anforderungsdatei explizit erstellen.
%%writefile /home/jupyter/.flink/requirements.txt
dep_a
dep_b
...
Alternativ können Sie alle lokalen Abhängigkeiten in einer Anforderungsdatei fixieren. Diese Option kann zu unbeabsichtigten Abhängigkeiten führen.
%pip freeze > /home/jupyter/.flink/requirements.txt
Nicht-Python-Abhängigkeiten vorbereiten
Kopieren Sie alle Nicht-Python-Abhängigkeiten in den Arbeitsbereich. Wenn Sie keine Nicht-Python-Abhängigkeiten haben, überspringen Sie diesen Schritt.
!cp /path/to/your-dep /home/jupyter/.flink/your-dep
...
Dockerfile erstellen
Erstellen Sie ein Dockerfile mit der Notebook-Magie %%writefile. Beispiel:
%%writefile /home/jupyter/.flink/Dockerfile
FROM apache/beam_python3.7_sdk:2.40.0
COPY requirements.txt /tmp/requirements.txt
COPY your_dep /tmp/your_dep
...
RUN python -m pip install -r /tmp/requirements.txt
Im Beispielcontainer wird das Image des Apache Beam SDK Version 2.40.0
mit Python 3.7 als Basis verwendet,
eine your_dep-Datei hinzugefügt und die zusätzlichen Python-Abhängigkeiten installiert.
Verwenden Sie dieses Dockerfile als Vorlage und passen Sie es an Ihren Anwendungsfall an.
Wenn Sie in Ihren Apache Beam-Pipelines auf Abhängigkeiten verweisen, die nicht Python sind, verwenden Sie deren COPY-Ziele. Beispielsweise ist /tmp/your_dep der Dateipfad der Datei your_dep.
Mit Cloud Build ein Container-Image in Artifact Registry erstellen
Aktivieren Sie die Cloud Build- und Artifact Registry-Dienste, falls noch nicht geschehen.
!gcloud services enable cloudbuild.googleapis.com !gcloud services enable artifactregistry.googleapis.comErstellen Sie ein Artifact Registry-Repository, damit Sie Artefakte hochladen können. Jedes Repository kann Artefakte für ein einzelnes unterstütztes Format enthalten.
Alle Repository-Inhalte werden entweder mit Schlüsseln verschlüsselt, die Google gehören oder von Google verwaltet werden, oder mit vom Kunden verwaltete Verschlüsselungsschlüssel. Artifact Registry verwendet Schlüssel, die Google gehören und von Google verwaltet werden, sind standardmäßig und keine Konfiguration erforderlich für diese Option.
Sie müssen für das Repository mindestens Zugriff als Artifact Registry-Autor haben.
Führen Sie den folgenden Befehl aus, um ein neues Repository zu erstellen: Der Befehl verwendet das Flag
--asyncund kehrt sofort zurück, ohne auf den Abschluss des Vorgangs zu warten.gcloud artifacts repositories create REPOSITORY \ --repository-format=docker \ --location=LOCATION \ --asyncErsetzen Sie die folgenden Werte:
- REPOSITORY ist ein Name für Ihr Repository. Repository-Namen können für jeden Repository-Speicherort in einem Projekt nur einmal vorkommen.
- LOCATION: der Speicherort für Ihr Repository.
Um Images per Push oder Pull übertragen zu können, konfigurieren Sie Docker für die Authentifizierung von Anfragen für Artifact Registry. Führen Sie den folgenden Befehl aus, um die Authentifizierung bei Docker-Repositories einzurichten:
gcloud auth configure-docker LOCATION-docker.pkg.devMit dem Befehl wird die Docker-Konfiguration aktualisiert. Sie können jetzt eine Verbindung zu Artifact Registry in Ihrem Google Cloud-Projekt herstellen, um Images per Push zu übertragen.
Mit Cloud Build das Container-Image erstellen und in Artifact Registry speichern.
!cd /home/jupyter/.flink \ && gcloud builds submit \ --tag LOCATION.pkg.dev/PROJECT_ID/REPOSITORY/flink:latest \ --timeout=20mErsetzen Sie dabei
PROJECT_IDdurch die Projekt-ID Ihres Zielprojekts.
Benutzerdefinierte Container verwenden
Je nach Runner können Sie benutzerdefinierte Container für unterschiedliche Zwecke verwenden.
Informationen zur allgemeinen Nutzung von Apache Beam-Containern finden Sie unter:
Informationen zur Verwendung des Dataflow-Containers finden Sie unter:
Deaktivieren Sie externe IP-Adressen
Deaktivieren Sie beim Erstellen einer Apache Beam-Notebookinstanz zur Erhöhung der Sicherheit externe IP-Adressen. Da Notebook-Instanzen einige öffentliche Internetressourcen wie Artifact Registry herunterladen müssen, müssen Sie zuerst ein neues VPC-Netzwerk ohne externe IP-Adresse erstellen. Erstellen Sie dann ein Cloud NAT-Gateway für dieses VPC-Netzwerk. Weitere Informationen zu Cloud NAT finden Sie in der Cloud NAT-Dokumentation. Mit dem VPC-Netzwerk und dem Cloud NAT-Gateway auf das erforderliche öffentliche Internet zugreifen ohne externe IP-Adressen zu aktivieren.