Mit verwalteten E/A-Connectors kann Dataflow bestimmte E/A-Connectors verwalten, die in Apache Beam-Pipelines verwendet werden. Managed I/O vereinfacht die Verwaltung von Pipelines, die in unterstützte Quellen und Senken eingebunden sind.
Die verwaltete Ein-/Ausgabe besteht aus zwei Komponenten, die zusammenarbeiten:
Eine Apache Beam-Transformation, die eine gemeinsame API zum Erstellen von E/A-Connectors (Quellen und Senken) bereitstellt.
Ein Dataflow-Dienst, der diese E/A-Connectors in Ihrem Namen verwaltet, einschließlich der Möglichkeit, sie unabhängig von der Apache Beam-Version zu aktualisieren.
Die verwaltete Ein-/Ausgabe bietet unter anderem folgende Vorteile:
Automatische Upgrades: Dataflow aktualisiert die verwalteten E/A-Connectors in Ihrer Pipeline automatisch. Das bedeutet, dass Ihre Pipeline Sicherheitskorrekturen, Leistungsverbesserungen und Fehlerkorrekturen für diese Connectors erhält, ohne dass Codeänderungen erforderlich sind. Weitere Informationen finden Sie unter Automatische Upgrades.
Einheitliche API: Bisher hatten E/A-Connectors in Apache Beam unterschiedliche APIs und jeder Connector wurde auf andere Weise konfiguriert. Managed I/O bietet eine einzelne Konfigurations-API, die Schlüssel/Wert-Eigenschaften verwendet. Das führt zu einem einfacheren und konsistenteren Pipeline-Code. Weitere Informationen finden Sie unter Configuration API.
Voraussetzungen
Die folgenden SDKs unterstützen verwaltete E/A:
- Apache Beam SDK für Java Version 2.58.0 oder höher.
- Apache Beam SDK für Python Version 2.61.0 oder höher.
Für den Backend-Dienst ist Dataflow Runner v2 erforderlich. Wenn Runner v2 nicht aktiviert ist, wird Ihre Pipeline weiterhin ausgeführt, aber sie profitiert nicht von den Vorteilen des verwalteten I/O-Dienstes.
Automatische Upgrades
Dataflow-Pipelines mit verwalteten E/A-Connectors verwenden automatisch die neueste zuverlässige Version des Connectors:
Wenn Sie einen Job senden, verwendet Dataflow die neueste Version des Connectors, die getestet wurde und gut funktioniert.
Bei Streamingjobs sucht Dataflow immer dann nach Updates, wenn Sie einen Ersatzjob starten, und verwendet automatisch die letzte bekannte, funktionierende Version. Dataflow führt diese Prüfung auch dann durch, wenn Sie im Ersatzjob keinen Code ändern.
Sie müssen den Connector oder die Apache Beam-Version Ihrer Pipeline nicht manuell aktualisieren.
Das folgende Diagramm zeigt den Upgradevorgang. Der Nutzer erstellt eine Apache Beam-Pipeline mit SDK-Version X. Wenn der Nutzer den Job einreicht, prüft Dataflow die Version der verwalteten E/A und führt ein Upgrade auf Version Y durch.
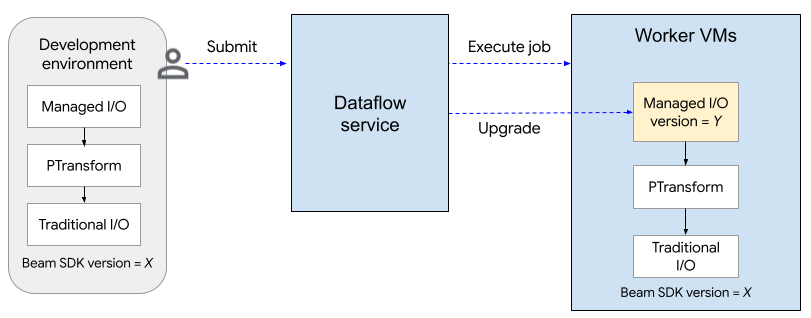
Durch den Upgrade-Prozess verlängert sich die Startzeit eines Jobs um etwa zwei Minuten. Wenn Sie den Status von verwalteten E/A-Vorgängen prüfen möchten, suchen Sie nach Logeinträgen, die den String „Managed Transform(s)“ enthalten.
Configuration API
Managed I/O ist eine sofort einsatzbereite Apache Beam-Transformation, die eine konsistente API zum Konfigurieren von Quellen und Senken bietet.
Java
Zum Erstellen einer von Managed I/O unterstützten Quelle oder Senke verwenden Sie die Klasse Managed. Geben Sie an, welche Quelle oder Senke instanziiert werden soll, und übergeben Sie eine Reihe von Konfigurationsparametern, ähnlich wie im folgenden Beispiel:
Map config = ImmutableMap.<String, Object>builder()
.put("config1", "abc")
.put("config2", 1);
pipeline.apply(Managed.read(/*Which source to read*/).withConfig(config))
.getSinglePCollection();
Sie können Konfigurationsparameter auch als YAML-Datei übergeben. Ein vollständiges Codebeispiel finden Sie unter Aus Apache Iceberg lesen.
Python
Importieren Sie das Modul apache_beam.transforms.managed und rufen Sie die Methode managed.Read oder managed.Write auf. Geben Sie an, welche Quelle oder Senke instanziiert werden soll, und übergeben Sie eine Reihe von Konfigurationsparametern, ähnlich wie im folgenden Beispiel:
pipeline
| beam.managed.Read(
beam.managed.SOURCE, # Example: beam.managed.KAFKA
config={
"config1": "abc",
"config2": 1
}
)
Sie können Konfigurationsparameter auch als YAML-Datei übergeben. Ein vollständiges Codebeispiel finden Sie unter Aus Apache Kafka lesen.
Dynamische Ziele
Bei einigen Senken kann der verwaltete E/A-Connector das Ziel dynamisch anhand von Feldwerten in den eingehenden Datensätzen auswählen.
Wenn Sie dynamische Ziele verwenden möchten, geben Sie einen Vorlagenstring für das Ziel an. Der Vorlagenstring kann Feldnamen in geschweiften Klammern enthalten, z. B. "tables.{field1}". Zur Laufzeit ersetzt der Connector den Wert des Felds für jeden eingehenden Datensatz, um das Ziel für diesen Datensatz zu bestimmen.
Angenommen, Ihre Daten enthalten ein Feld mit dem Namen airport. Sie können das Ziel auf "flights.{airport}" festlegen. Wenn airport=SFO ist, wird der Datensatz in flights.SFO geschrieben. Verwenden Sie für verschachtelte Felder die Punktnotation. Beispiel:
{top.middle.nested}.
Beispielcode für die Verwendung dynamischer Ziele finden Sie unter Mit dynamischen Zielen schreiben.
Filtern
Möglicherweise möchten Sie bestimmte Felder herausfiltern, bevor sie in die Zieltabelle geschrieben werden. Bei Senken, die dynamische Ziele unterstützen, können Sie dazu den Parameter drop, keep oder only verwenden. Mit diesen Parametern können Sie Zielmetadaten in die Eingabedatensätze einfügen, ohne die Metadaten in das Ziel zu schreiben.
Sie können für ein bestimmtes Ziel maximal einen dieser Parameter festlegen.
| Konfigurationsparameter | Datentyp | Beschreibung |
|---|---|---|
drop |
Liste mit Strings | Eine Liste der Feldnamen, die vor dem Schreiben in das Ziel gelöscht werden sollen. |
keep |
Liste mit Strings | Eine Liste der Feldnamen, die beim Schreiben in das Ziel beibehalten werden sollen. Andere Felder werden entfernt. |
only |
String | Der Name genau eines Felds, das als Datensatz der obersten Ebene verwendet werden soll, wenn Daten in das Ziel geschrieben werden. Alle anderen Felder werden entfernt. Dieses Feld muss vom Zeilentyp sein. |
Unterstützte Quellen und Senken
Verwaltete E/A unterstützt die folgenden Quellen und Senken.
Weitere Informationen finden Sie in der Apache Beam-Dokumentation unter Managed I/O Connectors.