Apache Beam SDK の組み込みロギング インフラストラクチャを使用して、パイプラインの実行時に情報をロギングできます。Google Cloud コンソールを使用して、パイプラインの実行中と実行後のロギング情報をモニタリングできます。
パイプラインにログメッセージを追加する
Java
Apache Beam SDK for Java では、オープンソースの Simple Logging Facade for Java(SLF4J)ライブラリを通じてワーカー メッセージをロギングすることをおすすめします。Apache Beam SDK for Java は必要なロギング インフラストラクチャを実装しているため、Java コードで必要なのは、SLF4J API をインポートすることだけです。次に、Logger をインスタンス化して、パイプライン コード内でメッセージ ロギングを有効にします。
既存のコードやライブラリについては、Apache Beam SDK for Java によって追加のロギング インフラストラクチャが設定されます。Java 用の次のロギング ライブラリによって生成されたログメッセージがキャプチャされます。
Python
Apache Beam SDK for Python には logging ライブラリ パッケージが用意されており、パイプラインのワーカーでコードを使用してログメッセージを出力できます。ライブラリ関数を使用するには、ライブラリをインポートする必要があります。
import logging
Go
Apache Beam SDK for Go には log ライブラリ パッケージが用意されており、パイプラインのワーカーでコードを使用してログメッセージを出力できます。ライブラリ関数を使用するには、ライブラリをインポートする必要があります。
import "github.com/apache/beam/sdks/v2/go/pkg/beam/log"
ワーカー ログ メッセージ コードの例
Java
次の例では、Dataflow ロギングに SLF4J を使用します。Dataflow ロギング用の SLF4J の構成の詳細については、Java のヒントの記事をご覧ください。
Apache Beam WordCount サンプルは、処理されたテキストの行に “love” という単語が見つかった場合にログ メッセージを出力するように変更できます。以下の例では、追加されるコードは太字で示されています(わかりやすくするために、前後のコードも含めています)。
package org.apache.beam.examples; // Import SLF4J packages. import org.slf4j.Logger; import org.slf4j.LoggerFactory; ... public class WordCount { ... static class ExtractWordsFn extends DoFn<String, String> { // Instantiate Logger. // Suggestion: As shown, specify the class name of the containing class // (WordCount). private static final Logger LOG = LoggerFactory.getLogger(WordCount.class); ... @ProcessElement public void processElement(ProcessContext c) { ... // Output each word encountered into the output PCollection. for (String word : words) { if (!word.isEmpty()) { c.output(word); } // Log INFO messages when the word "love" is found. if(word.toLowerCase().equals("love")) { LOG.info("Found " + word.toLowerCase()); } } } } ... // Remaining WordCount example code ...
Python
Apache Beam の wordcount.py サンプルは、処理されたテキストの行に “love” という単語が見つかった場合にログ メッセージを出力するように変更できます。
# import Python logging module. import logging class ExtractWordsFn(beam.DoFn): def process(self, element): words = re.findall(r'[A-Za-z\']+', element) for word in words: yield word if word.lower() == 'love': # Log using the root logger at info or higher levels logging.info('Found : %s', word.lower()) # Remaining WordCount example code ...
Go
Apache Beam の wordcount.go サンプルは、処理されたテキストの行に “love” という単語が見つかった場合にログ メッセージを出力するように変更できます。
func (f *extractFn) ProcessElement(ctx context.Context, line string, emit func(string)) { for _, word := range wordRE.FindAllString(line, -1) { // increment the counter for small words if length of words is // less than small_word_length if strings.ToLower(word) == "love" { log.Infof(ctx, "Found : %s", strings.ToLower(word)) } emit(word) } } // Remaining Wordcount example
Java
変更された WordCount パイプラインは、デフォルトの DirectRunner を使用してローカルで実行され、出力はローカル ファイル(--output=./local-wordcounts)に送信されます。コンソールの出力には、追加されたログメッセージが表示されます。
INFO: Executing pipeline using the DirectRunner. ... Feb 11, 2015 1:13:22 PM org.apache.beam.examples.WordCount$ExtractWordsFn processElement INFO: Found love Feb 11, 2015 1:13:22 PM org.apache.beam.examples.WordCount$ExtractWordsFn processElement INFO: Found love Feb 11, 2015 1:13:22 PM org.apache.beam.examples.WordCount$ExtractWordsFn processElement INFO: Found love ... INFO: Pipeline execution complete.
デフォルトでは、INFO 以上がマークされたログ行のみが Cloud Logging に送信されます。この動作を変更する場合は、パイプライン ワーカーのログレベルの設定をご覧ください。
Python
変更された WordCount パイプラインは、デフォルトの DirectRunner を使用してローカルで実行され、出力はローカル ファイル(--output=./local-wordcounts)に送信されます。コンソールの出力には、追加されたログメッセージが表示されます。
INFO:root:Found : love INFO:root:Found : love INFO:root:Found : love
デフォルトでは、INFO 以上がマークされたログ行のみが Cloud Logging に送信されます。
Go
変更された WordCount パイプラインは、デフォルトの DirectRunner を使用してローカルで実行され、出力はローカル ファイル(--output=./local-wordcounts)に送信されます。コンソールの出力には、追加されたログメッセージが表示されます。
2022/05/26 11:36:44 Found : love 2022/05/26 11:36:44 Found : love 2022/05/26 11:36:44 Found : love
デフォルトでは、INFO 以上がマークされたログ行のみが Cloud Logging に送信されます。
ログの量を制御する
また、パイプラインのログレベルを変更して、生成されるログの量を減らすこともできます。一部またはすべての Dataflow ログの取り込みを続行しない場合は、Logging の除外を追加して Dataflow ログを除外します。次に、BigQuery、Cloud Storage、Pub/Sub などの別の宛先にログをエクスポートします。詳細については、Dataflow ログ取り込みの制御をご覧ください。
ロギングの上限と抑制
ワーカー ログメッセージの上限は、ワーカーごとに 30 秒あたり 15,000 メッセージに制限されています。この上限に達すると、ロギングが抑制されたことを示す 1 つのワーカー ログメッセージが追加されます。
Throttling logger worker. It used up its 30s quota for logs in only 12.345s
ログの保存と保持
オペレーション ログは、_Default ログバケットに保存されます。Logging API サービス名は dataflow.googleapis.com です。Cloud Logging で使用される Google Cloud のモニタリング対象リソースタイプとサービスの詳細については、モニタリング対象リソースとサービスをご覧ください。
Logging でログエントリが保持される期間の詳細については、割り当てと上限: ログの保持期間で保持情報をご覧ください。
オペレーション ログの表示方法については、パイプライン ログをモニタリングおよび表示するをご覧ください。
パイプライン ログのモニタリングと表示
Dataflow サービスでパイプラインを実行すると、Dataflow モニタリング インターフェースを使用して、パイプラインによって出力されたログを表示できます。
Dataflow ワーカーログの例
変更された WordCount パイプラインは、次のオプションを使用してクラウドで実行できます。
Java
--project=WordCountExample --output=gs://<bucket-name>/counts --runner=DataflowRunner --tempLocation=gs://<bucket-name>/temp --stagingLocation=gs://<bucket-name>/binaries
Python
--project=WordCountExample --output=gs://<bucket-name>/counts --runner=DataflowRunner --staging_location=gs://<bucket-name>/binaries
Go
--project=WordCountExample --output=gs://<bucket-name>/counts --runner=DataflowRunner --staging_location=gs://<bucket-name>/binaries
ログの表示
WordCount クラウド パイプラインはブロック実行を使用するため、パイプラインの実行中にコンソール メッセージが出力されます。ジョブが開始すると、Google Cloud コンソール ページへのリンクがコンソールに出力され、続いてパイプラインのジョブ ID が出力されます。
INFO: To access the Dataflow monitoring console, please navigate to https://console.developers.google.com/dataflow/job/2017-04-13_13_58_10-6217777367720337669 Submitted job: 2017-04-13_13_58_10-6217777367720337669
コンソール URL は、送信されたジョブの概要ページがある Dataflow モニタリング インターフェースを表示します。左側には動的実行グラフが表示され、右側には概要情報が表示されます。下のパネルの keyboard_capslock をクリックしてログパネルを展開します。
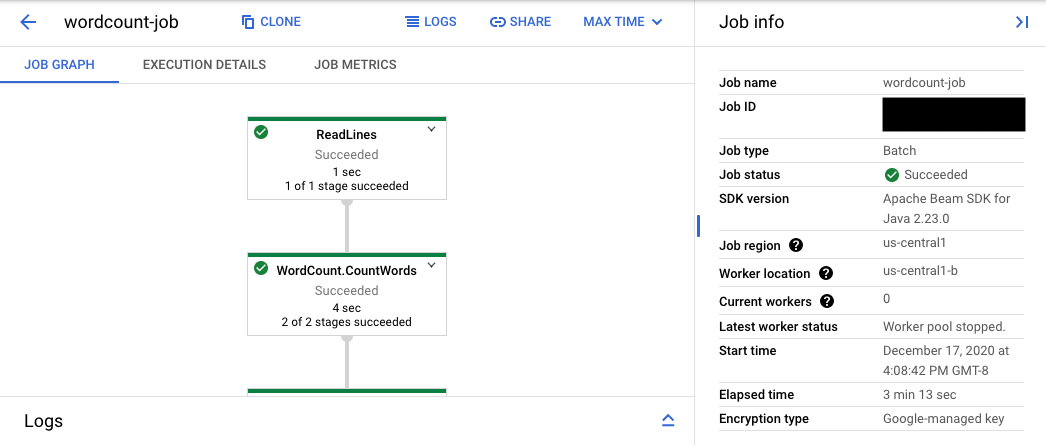
ログパネルにはデフォルトで、ジョブ全体のステータスを報告する [ジョブのログ] が表示されます。[情報] arrow_drop_down と filter_list [ログのフィルタ] をクリックすると、ログパネルに表示されるメッセージをフィルタできます。
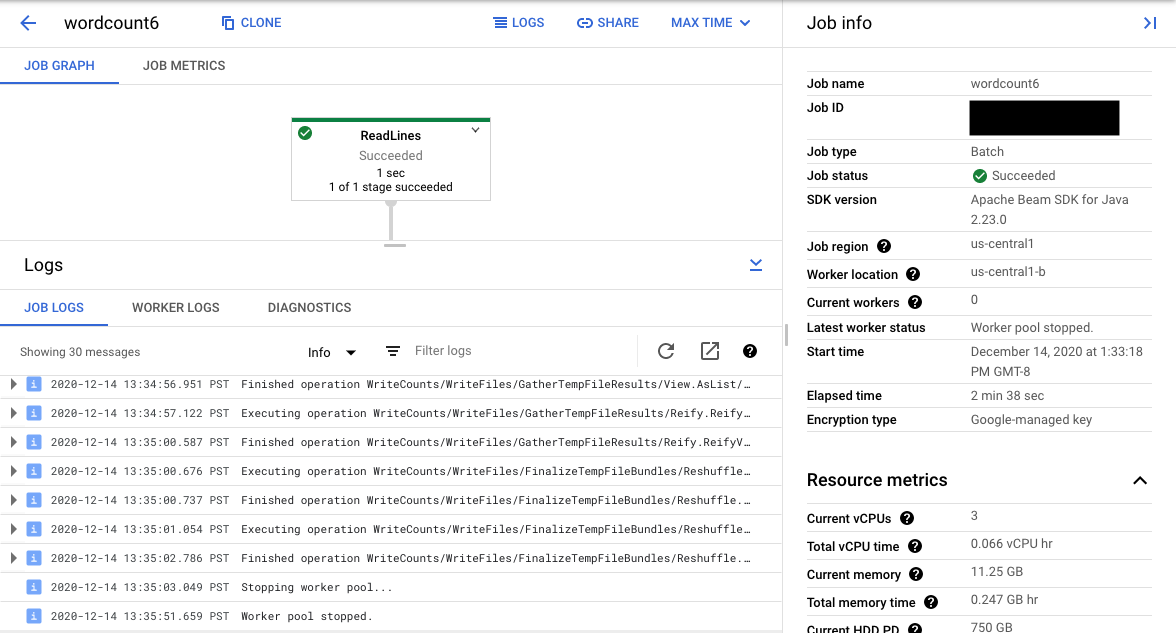
グラフのパイプライン ステップを選択すると、ビューは、コードによって生成された [ステップのログ] と、パイプライン ステップで実行中の生成されたコードに変更されます。
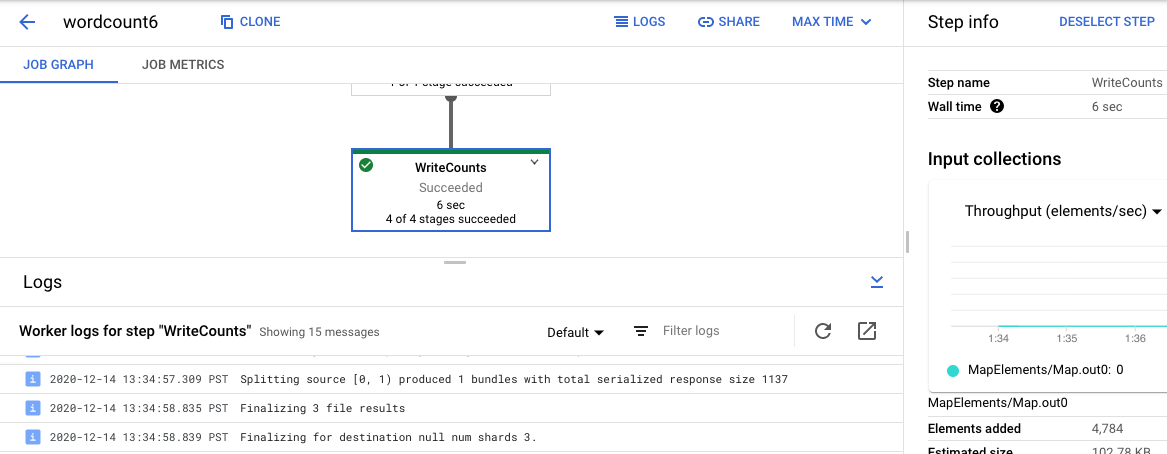
[ジョブのログ] に戻るには、グラフの外側をクリックするか右側のパネルの [ステップを選択解除] ボタンを使用して、ステップの選択を解除します。
ログ エクスプローラを開く
ログ エクスプローラを開いてさまざまなログタイプを選択するには、ログパネルで [ログ エクスプローラで表示](外部リンクボタン)をクリックします。
ログ エクスプローラでさまざまなログタイプを含むパネルを表示するには、[ログのフィールド] 切り替えボタンをクリックします。
[ログ エクスプローラ] ページでは、クエリでフィルタが適用されていて、ジョブステップまたはログタイプによってログがフィルタされている場合があります。フィルタを削除するには、[クエリを表示] をクリックしてクエリを編集します。
ジョブのすべてのログを表示する手順は次のとおりです。
[クエリ] フィールドに次のクエリを入力します。
resource.type="dataflow_step" resource.labels.job_id="JOB_ID"JOB_ID をジョブの ID に置き換えます。
[クエリを実行] をクリックします。
このクエリを使用してもジョブのログが表示されない場合は、[日時を編集する] をクリックします。
開始時間と終了時間を調整し、[適用] をクリックします。
ログタイプ
ログ エクスプローラには、パイプラインのインフラストラクチャ ログも含まれます。エラーログと警告ログを使用して、観察されたパイプラインの問題を診断します。パイプラインの問題と関連していないインフラストラクチャ ログのエラーや警告は、問題を示しているとは限りません。
ここでは、[ログ エクスプローラ] ページで表示できる、さまざまなログタイプの概要を示します。
- job-message ログには、Dataflow のさまざまなコンポーネントが生成するジョブレベルのメッセージが記録されます。たとえば、自動スケーリング構成、ワーカーの起動やシャットダウン、ジョブステップの進捗状況、ジョブエラーなどが記録されます。ユーザーコードのクラッシュに起因するワーカーレベルのエラーや、ワーカーログに記録されたエラーも job-message ログに記録されます。
- worker ログは Dataflow ワーカーによって生成されます。worker は、パイプライン処理の大部分(データへの
ParDoの適用など)を実行します。worker のログには、コードと Dataflow によって記録されたメッセージが含まれます。 - worker-startup ログは、ほとんどの Dataflow ジョブを表し、起動プロセスに関連するメッセージをキャプチャできます。起動プロセスでは、Cloud Storage からジョブの jar をダウンロードし、ワーカーを起動します。ワーカーの起動に問題がある場合は、ここを調べることをおすすめします。
- shuffler ログには、並列パイプライン オペレーションの結果を統合する、ワーカーからのメッセージが含まれます。
- system ログには、ワーカー VM のホスト オペレーティング システムからのメッセージが含まれます。シナリオによっては、プロセスのクラッシュや OOM(out-of-memory)イベントがキャプチャされることがあります。
- docker と kubelet のログには、Dataflow ワーカーで使用される、これらの一般公開されたテクノロジーに関連するメッセージが含まれます。
- nvidia-mps ログには、NVIDIA Multi-Process Service(MPS)オペレーションに関するメッセージが含まれます。
パイプラインのワーカーログ レベルを設定する
Java
Apache Beam SDK for Java によってワーカーに設定されるデフォルトの SLF4J ロギングレベルは INFO です。INFO 以上(INFO、WARN、ERROR)のすべてのログメッセージが出力されます。別のデフォルト ログレベルを設定して、より低い SLF4J ログレベル(TRACE または DEBUG)をサポートできます。また、コード内の異なるクラス パッケージに異なるログレベルを設定することもできます。
コマンドラインまたはプログラムでワーカーログ レベルを設定できるように、次のパイプライン オプションが用意されています。
--defaultSdkHarnessLogLevel=<level>: このオプションを使用して、指定したデフォルト レベルですべてのロガーを設定します。たとえば、次のコマンドライン オプションは、デフォルトの DataflowINFOログレベルをオーバーライドして、DEBUGに設定します。--defaultSdkHarnessLogLevel=DEBUG--sdkHarnessLogLevelOverrides={"<package or class>":"<level>"}: このオプションを使用して、指定したパッケージまたはクラスのログレベルを設定します。たとえば、org.apache.beam.runners.dataflowパッケージのデフォルトのパイプライン ログレベルをオーバーライドして、TRACEに設定するには、次のようにします。
--sdkHarnessLogLevelOverrides='{"org.apache.beam.runners.dataflow":"TRACE"}'
複数のオーバーライドを行うには、次のように JSON マップを指定します。
(--sdkHarnessLogLevelOverrides={"<package/class>":"<level>","<package/class>":"<level>",...})defaultSdkHarnessLogLevelとsdkHarnessLogLevelOverridesのパイプライン オプションは、Runner v2 を使用しない Apache Beam SDK バージョン 2.50.0 以前を使用するパイプラインではサポートされていません。 その場合、--defaultWorkerLogLevel=<level>と--workerLogLevelOverrides={"<package or class>":"<level>"}のパイプライン オプションを使用します。複数のオーバーライドを行うには、次のように JSON マップを指定します。
(--workerLogLevelOverrides={"<package/class>":"<level>","<package/class>":"<level>",...})
次のサンプル プログラムでは、パイプライン ログオプションに、コマンドラインからオーバーライドできるデフォルト値を設定します。
PipelineOptions options = ... SdkHarnessOptions loggingOptions = options.as(SdkHarnessOptions.class); // Overrides the default log level on the worker to emit logs at TRACE or higher. loggingOptions.setDefaultSdkHarnessLogLevel(LogLevel.TRACE); // Overrides the Foo class and "org.apache.beam.runners.dataflow" package to emit logs at WARN or higher. loggingOptions.getSdkHarnessLogLevelOverrides() .addOverrideForClass(Foo.class, LogLevel.WARN) .addOverrideForPackage(Package.getPackage("org.apache.beam.runners.dataflow"), LogLevel.WARN);
Python
Apache Beam SDK for Python によってワーカーに設定されるデフォルトのロギングレベルは INFO です。INFO 以上(INFO、WARNING、ERROR、CRITICAL)のすべてのログメッセージが出力されます。別のデフォルトのログレベルを設定して、より低いロギングレベル(DEBUG)をサポートできます。また、コード内のモジュールごとに異なるログレベルを設定することもできます。
コマンドラインまたはプログラムでワーカーログ レベルを設定できるように、2 つのパイプライン オプションが用意されています。
--default_sdk_harness_log_level=<level>: このオプションを使用して、指定したデフォルト レベルですべてのロガーを設定します。たとえば、次のコマンドライン オプションは、デフォルトの DataflowINFOログレベルをオーバーライドして、DEBUGに設定します。--default_sdk_harness_log_level=DEBUG--sdk_harness_log_level_overrides={\"<module>\":\"<level>\"}: このオプションを使用して、指定したモジュールのロギングレベルを設定します。たとえば、apache_beam.runners.dataflowモジュールのデフォルトのパイプライン ログレベルをオーバーライドして、DEBUGに設定するには、次のようにします。
--sdk_harness_log_level_overrides={\"apache_beam.runners.dataflow\":\"DEBUG\"}
複数のオーバーライドを行うには、次のように JSON マップを指定します。
(--sdk_harness_log_level_overrides={\"<module>\":\"<level>\",\"<module>\":\"<level>\",...})
次の例では、WorkerOptions クラスを使用して、コマンドラインからオーバーライドできるパイプライン ロギング オプションをプログラムで設定しています。
from apache_beam.options.pipeline_options import PipelineOptions, WorkerOptions pipeline_args = [ '--project=PROJECT_NAME', '--job_name=JOB_NAME', '--staging_location=gs://STORAGE_BUCKET/staging/', '--temp_location=gs://STORAGE_BUCKET/tmp/', '--region=DATAFLOW_REGION', '--runner=DataflowRunner' ] pipeline_options = PipelineOptions(pipeline_args) worker_options = pipeline_options.view_as(WorkerOptions) worker_options.default_sdk_harness_log_level = 'WARNING' # Note: In Apache Beam SDK 2.42.0 and earlier versions, use ['{"apache_beam.runners.dataflow":"WARNING"}'] worker_options.sdk_harness_log_level_overrides = {"apache_beam.runners.dataflow":"WARNING"} # Pass in pipeline options during pipeline creation. with beam.Pipeline(options=pipeline_options) as pipeline:
次のように置き換えます。
PROJECT_NAME: プロジェクトの名前JOB_NAME: ジョブの名前STORAGE_BUCKET: Cloud Storage 名DATAFLOW_REGION: Dataflow ジョブをデプロイするリージョン--regionフラグは、メタデータ サーバー、ローカル クライアント、または環境変数に設定されているデフォルト リージョンをオーバーライドします。
Go
この機能は、Apache Beam SDK for Go では使用できません。
起動された BigQuery ジョブのログを表示する
Dataflow パイプラインで BigQuery を使用すると、BigQuery ジョブが起動し、ユーザーに代わってさまざまなアクションが実行されます。これらのアクションには、データの読み込み、エクスポートなどが含まれます。トラブルシューティングとモニタリングを行う場合、Dataflow モニタリング インターフェースには、これらの BigQuery ジョブに関する追加情報が [ログ] パネルに表示されます。
[ログ] パネルに表示される BigQuery ジョブの情報は BigQuery システム テーブルに保存され、そこから読み込まれます。基盤となる BigQuery テーブルに対してクエリが実行されると課金が発生します。
BigQuery ジョブの詳細を表示する
BigQuery ジョブの情報を表示するには、パイプラインで Apache Beam 2.24.0 以降を使用する必要があります。
BigQuery ジョブを一覧表示するには、[BigQuery ジョブ] タブを開いて、BigQuery ジョブのロケーションを選択します。次に、[BigQuery ジョブの読み込み] をクリックしてダイアログを確定します。クエリが完了すると、ジョブリストが表示されます。
![BigQuery ジョブ情報テーブル内の [BigQuery ジョブの読み込み] ボタン](https://cloud.google.com/static/dataflow/images/bq-job-table-load-bq-jobs.png?authuser=00&hl=ja)
ジョブ ID、タイプ、期間など、各ジョブの基本情報が提供されます。
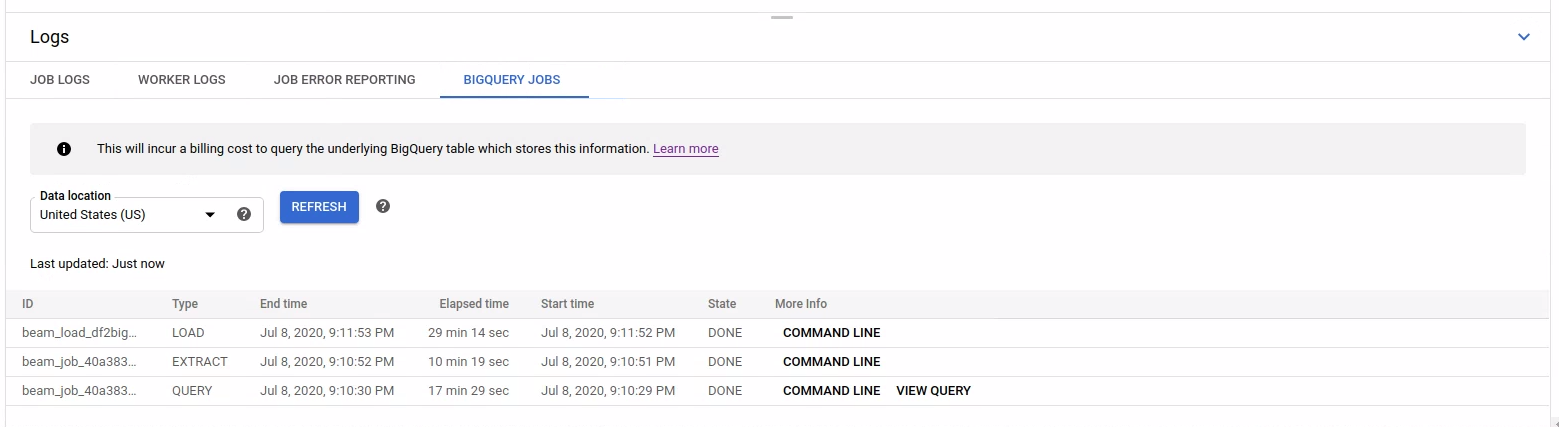
特定のジョブの詳細情報については、[詳細] 列の [コマンドライン] をクリックします。
コマンドラインのモーダル ウィンドウで bq jobs describe コマンドをコピーし、ローカルまたは Cloud Shell で実行します。
gcloud alpha bq jobs describe BIGQUERY_JOB_ID
bq jobs describe コマンドは、JobStatistics を出力します。これにより、低速または停滞している BigQuery ジョブの診断時に役立つ追加の詳細情報が提供されます。
別の方法としては、SQL クエリで BigQueryIO を使用すると、クエリジョブが発行されます。ジョブで使用される SQL クエリを表示するには、[詳細] 列で [クエリを表示] をクリックします。