Dataflow はジョブの指標を収集します。これは、エラーのデバッグ、パフォーマンス問題のトラブルシューティング、パイプラインの最適化に役立ちます。Dataflow モニタリング インターフェースには、これらの指標を可視化したものが表示されます。Cloud Monitoring を使用してアラートを作成する、あるいは Metrics Explorer クエリをビルドすることもできます。
ジョブの指標にアクセスする
ジョブのジョブ指標を表示する手順は、次のとおりです。
Google Cloud コンソールで、[Dataflow] > [ジョブ] ページに移動します。
ジョブを選択します。
[ジョブの指標] タブをクリックします。
表示する指標を選択します。
ジョブ指標のグラフで追加情報にアクセスするには、 [データを探索] をクリックします。
各指標は、次のダッシュボードにまとめられています。
サポートと制限事項
Dataflow の指標を使用する場合は、次の点に注意してください。
ジョブデータが断続的に使用不能になる場合があります。データが欠落している場合、ジョブ モニタリング グラフにギャップが表示されます。
これらのグラフの一部は、ストリーミング パイプライン専用です。
指標データを書き込むには、ユーザー管理のサービス アカウントに IAM API 権限
monitoring.timeSeries.createが必要です。この権限は、Dataflow ワーカーのロールに含まれています。Dataflow サービスは、ジョブの完了後に予約済みの CPU 時間を報告します。制限なし(ストリーミング)ジョブの場合、予約された CPU 時間は、ジョブのキャンセルまたは失敗後にのみ報告されます。したがって、ジョブ指標にストリーミング ジョブ用に予約された CPU 時間は含まれません。
自動スケーリング指標
水平自動スケーリングを使用すると、Dataflow はジョブに適切な数のワーカー インスタンスを選択し、必要に応じてワーカーの追加または削除を行うことができます。
[ジョブの指標] タブの [自動スケーリング] セクションには、ワーカー数と目標ワーカー数が時間の経過とともに示されます。ジョブが Streaming Engine を使用している場合は、ワーカーの最小数と最大数も表示されます。
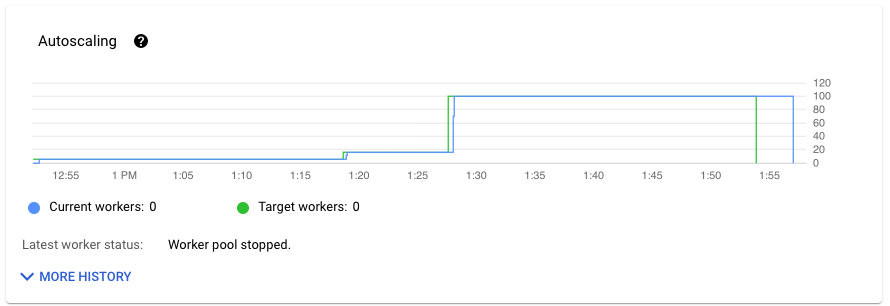
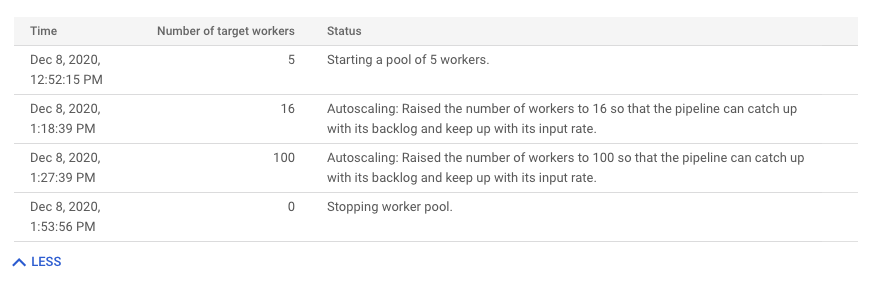
自動スケーリングの変更履歴を表示するには、[その他の履歴] をクリックします。パイプラインのワーカーの履歴情報を示すテーブル。
ストリーミング ジョブの自動スケーリングの詳細情報を表示するには、[自動スケーリング] タブをクリックします。詳細については、Dataflow 自動スケーリングのモニタリングをご覧ください。
全体的な指標
[概要指標] には次の指標が表示されます。
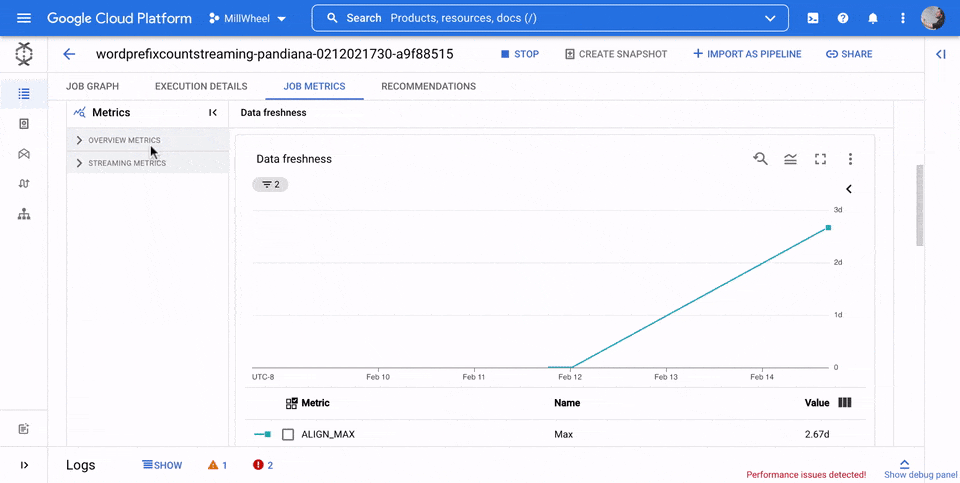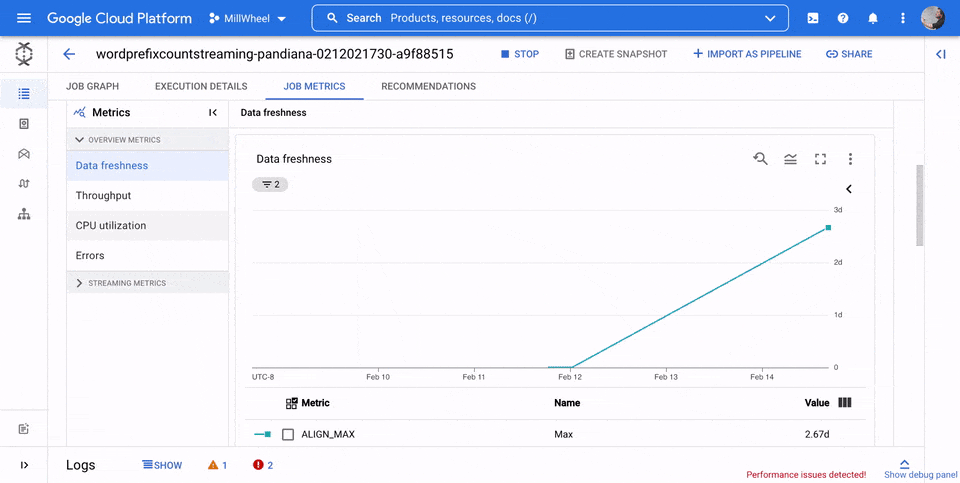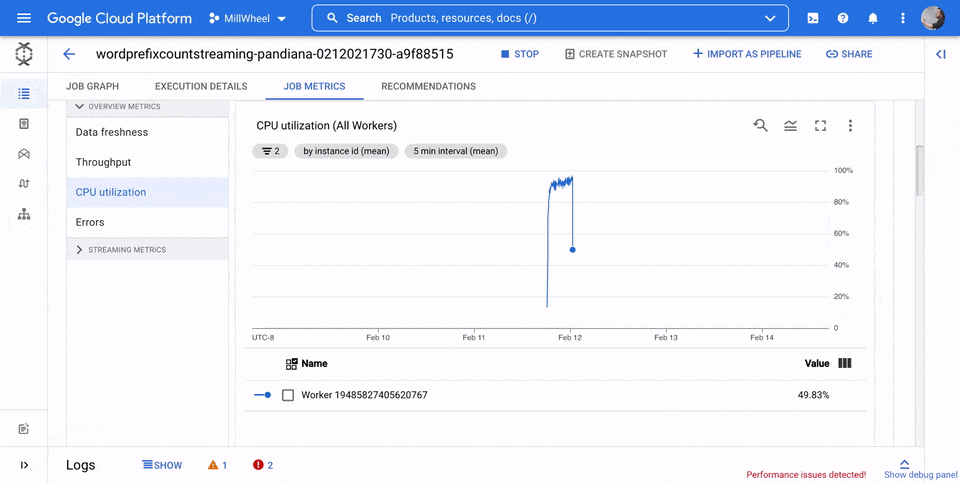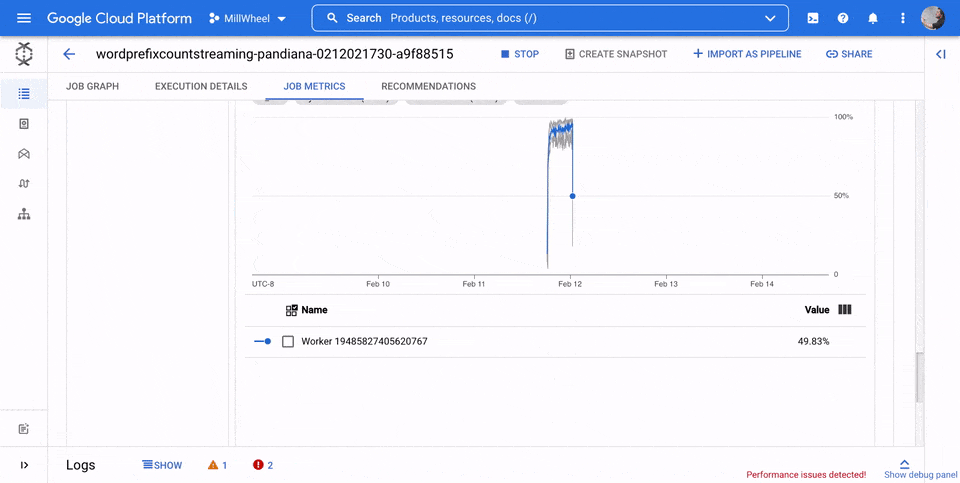
データの鮮度
この指標はストリーミング ジョブにのみ適用されます。
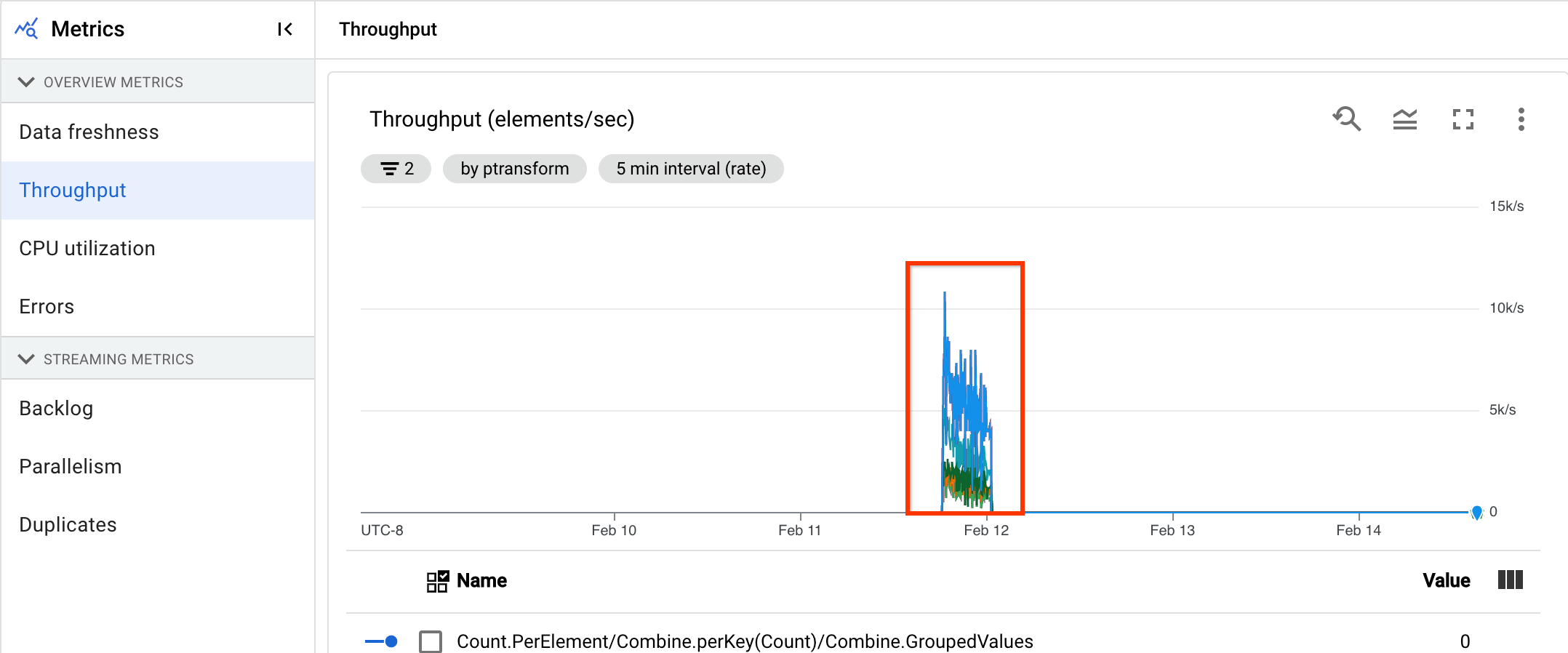
データの更新速度は、データ要素が処理された時間(処理時間)とデータ要素のタイムスタンプ(イベント時間)の差です。値が大きいほど、イベント時間と処理時間の間の遅延が大きかったことを意味します。
データの更新速度のグラフには、任意の時点でのデータの更新速度の最大値が表示されます。Dataflow は複数の要素を並行して処理するため、グラフにはイベント時間と比較して遅延が最も長い要素が反映されます。
一部の入力データがまだ処理されていない場合、出力ウォーターマークが遅延し、データの更新速度に影響する可能性があります。ウォーターマーク時間とイベント時間の間に大きな差がある場合は、オペレーションが遅いか、停止している可能性があります。詳細については、Apache Beam ドキュメントのウォーターマークと遅延データをご覧ください。
ダッシュボードには、次の 2 つのグラフが表示されます。
- ステージ別のデータの更新頻度
- データの鮮度
次の画像でハイライト表示された領域を見ると、イベント時間と出力ウォーターマーク時間に大きな差があります。これは、オペレーションが遅いことを示しています。
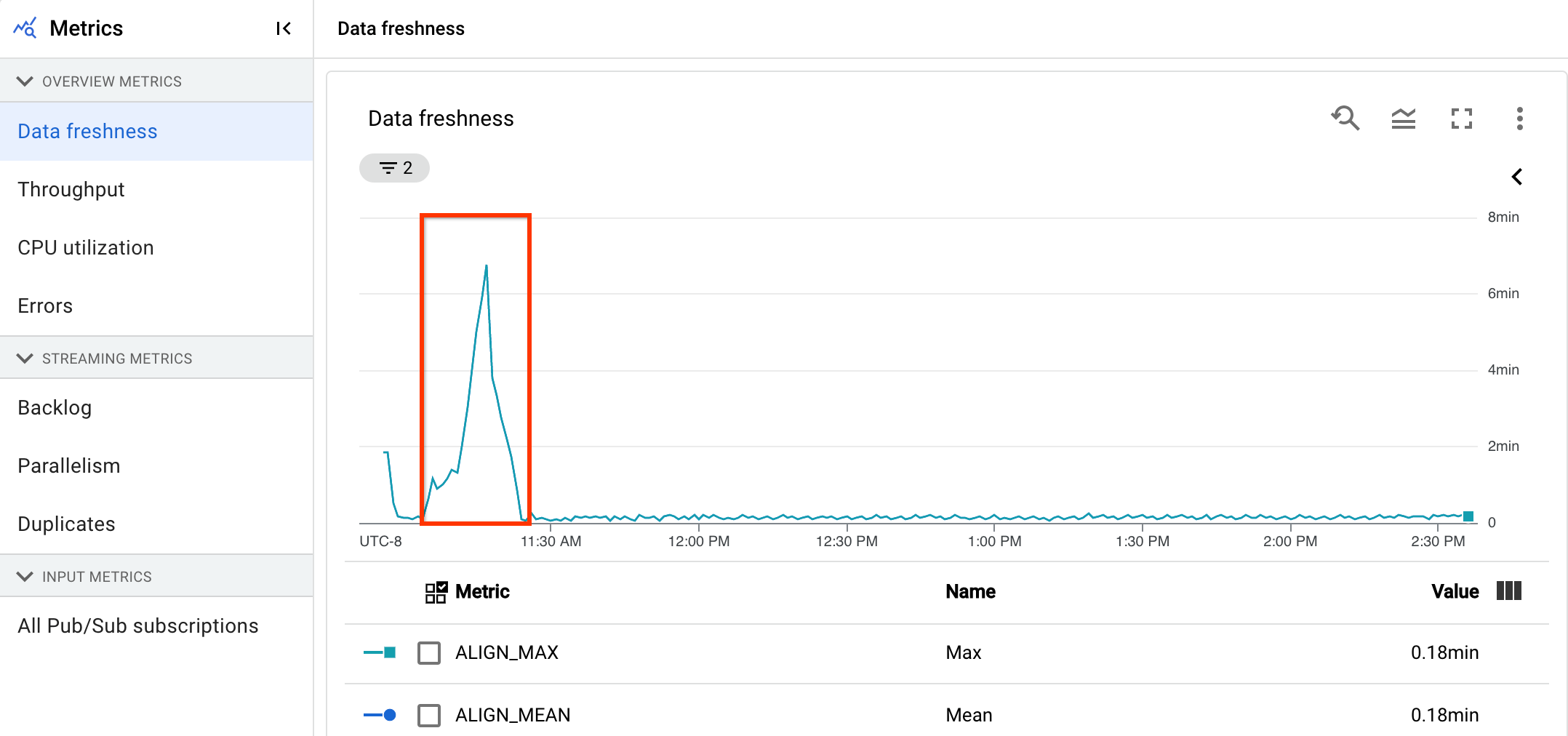
次の問題が原因で、この指標の値が高くなる可能性があります。
- パフォーマンスのボトルネック: パイプラインにシステム レイテンシが高いステージや、変換の停止を示すログがあるステージの場合、データの更新頻度に影響する可能性があるパフォーマンス上の問題がパイプラインに存在することを示しています。詳細を確認するには、ストリーミング ジョブの速度が遅い場合や停止している場合のトラブルシューティングをご覧ください。
- データソースのボトルネック: データソースのバックログが増加している場合、要素のイベント タイムスタンプがウォーターマークから逸脱することがあります。これは、要素が処理されるのを待機しているためです。多くの場合、大規模なバックログはパフォーマンスのボトルネックやデータソースの問題が原因で発生しています。これらは、パイプラインで使用されているソースをモニタリングすることで検出できます。
- Pub/Sub などの順序付けされていないソースでは、頻繁に出力されている場合でも、ウォーターマークでの停止が発生することがあります。これは、要素がタイムスタンプ順に出力されず、ウォーターマークが最小の未処理タイムスタンプに基づいているためです。
- 頻繁な再試行: 要素の処理に失敗し再試行しようとしていることを示すエラーがある場合、再試行された要素からの古いタイムスタンプがデータの更新頻度指標を高めている可能性があります。この問題のトラブルシューティングを行うには、一般的な Dataflow エラーのリストをご覧ください。
最近更新されたストリーミング ジョブの場合、ジョブの状態とウォーターマークに関する情報が利用できないことがあります。Update オペレーションによりいくつかの変更が行われ、これを Dataflow モニタリング インターフェースに反映するために数分かかります。ジョブを更新してから 5 分後に、モニタリング インターフェースを更新してみてください。
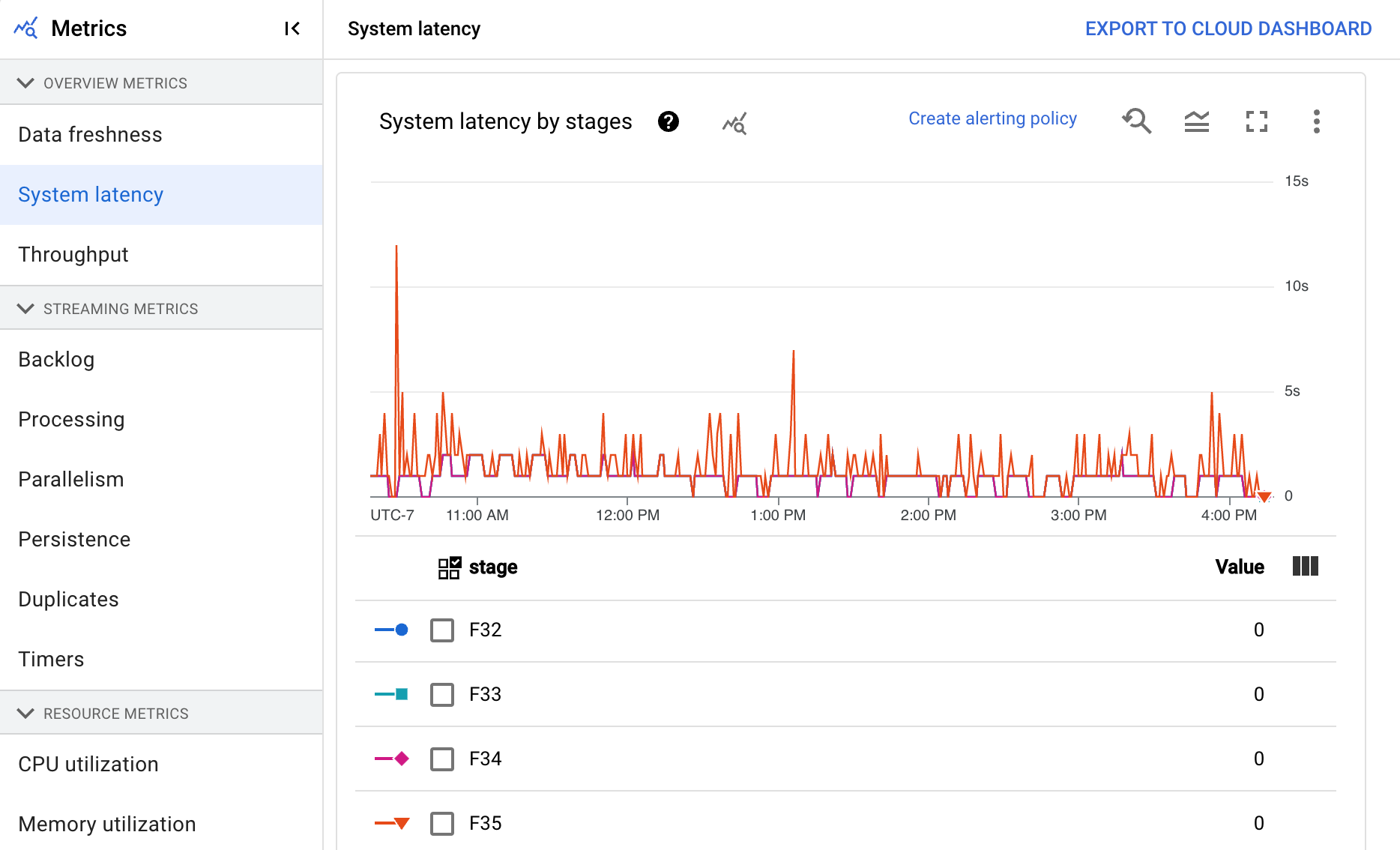
システム レイテンシ
この指標はストリーミング ジョブにのみ適用されます。
システム レイテンシとは、データ項目が処理中または処理待ち状態になっている時間の現時点での最大秒数です。この指標には、要素がソース内で待機する時間が含まれます。たとえば、出力先が一定期間書き込みリクエストの受け入れを停止すると、送信元にデータが蓄積し、システム レイテンシが増加する可能性があります。書き込みオペレーションが再開され、パイプラインが追いつくと、システム レイテンシはベースライン レベルに戻ります。
追加の考慮事項は次のとおりです。
- 複数のソースとシンクがある場合、システムのレイテンシは、すべてのシンクに書き込まれるまでにソース内で要素が待機する最長時間になります。
- 場合によっては、ソース内で要素が待機する時間の値が提供されないこともあります。また、要素にイベント時間を定義するメタデータがない場合があります。この場合、パイプラインが最初に要素を受け取った時点からシステムのレイテンシが計算されます。
ダッシュボードには、次の 2 つのグラフが表示されます。
- ステージ別のシステム レイテンシ
- システム レイテンシ
スループット
スループットは、任意の時点で処理されたデータ量を表します。ダッシュボードには、次のグラフが表示されます。
- ステップあたりのスループット(要素数 / 秒)
- ステップあたりのスループット(1 秒あたりのバイト数)
ワーカーのエラーログのカウント
[ワーカーのエラーログのカウント] には、特定の時点でのすべてのワーカーで観測されたエラーの割合が表示されます。

ストリーミング指標
[ストリーミング指標] には、次の指標が表示されます。
バックログ
この指標はストリーミング ジョブにのみ適用されます。
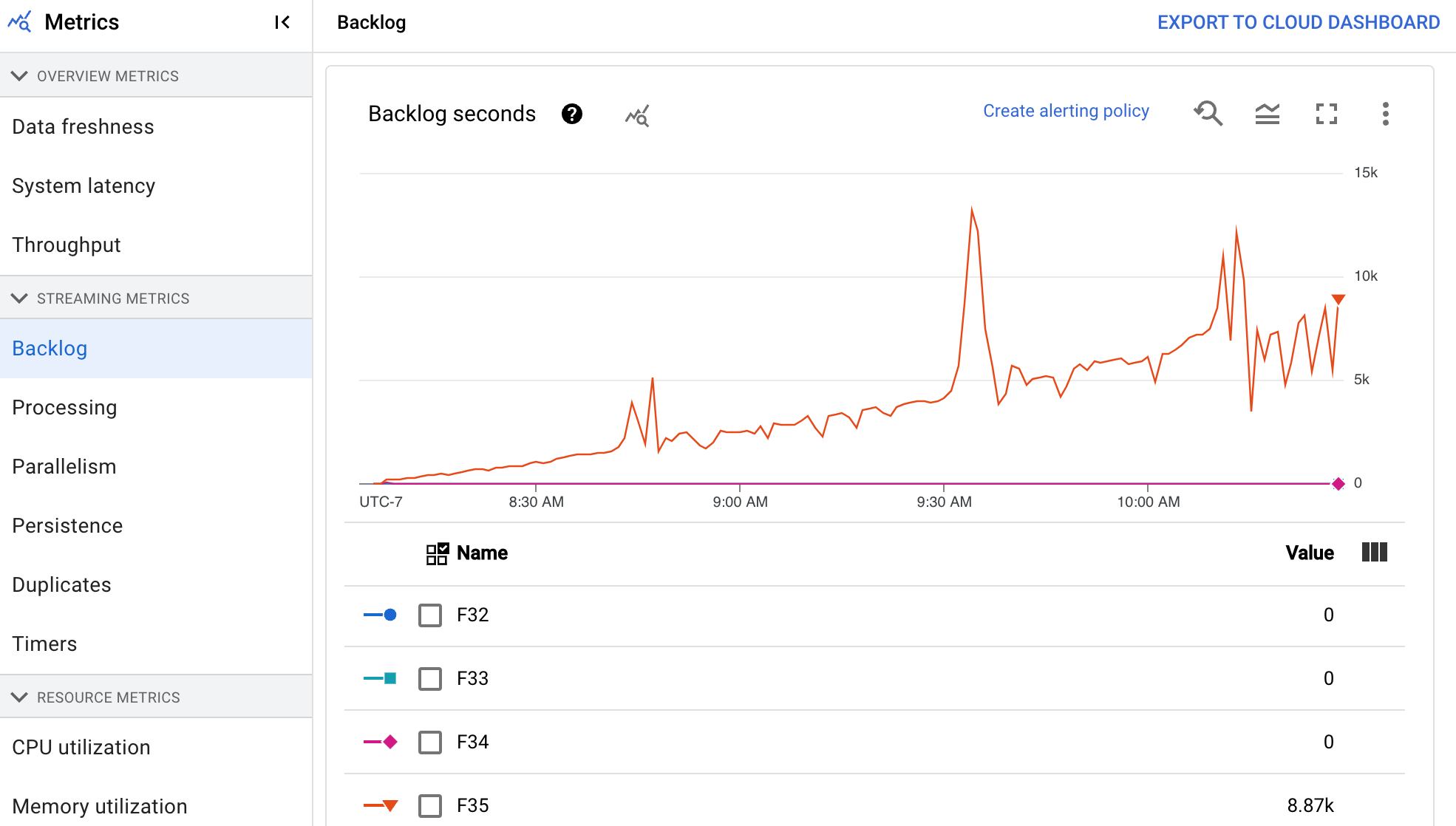
[バックログ] ダッシュボードには、処理待ちの要素に関する情報が表示されます。ダッシュボードには、次の 2 つのグラフが表示されます。
- バックログの秒数(Streaming Engine のみ)
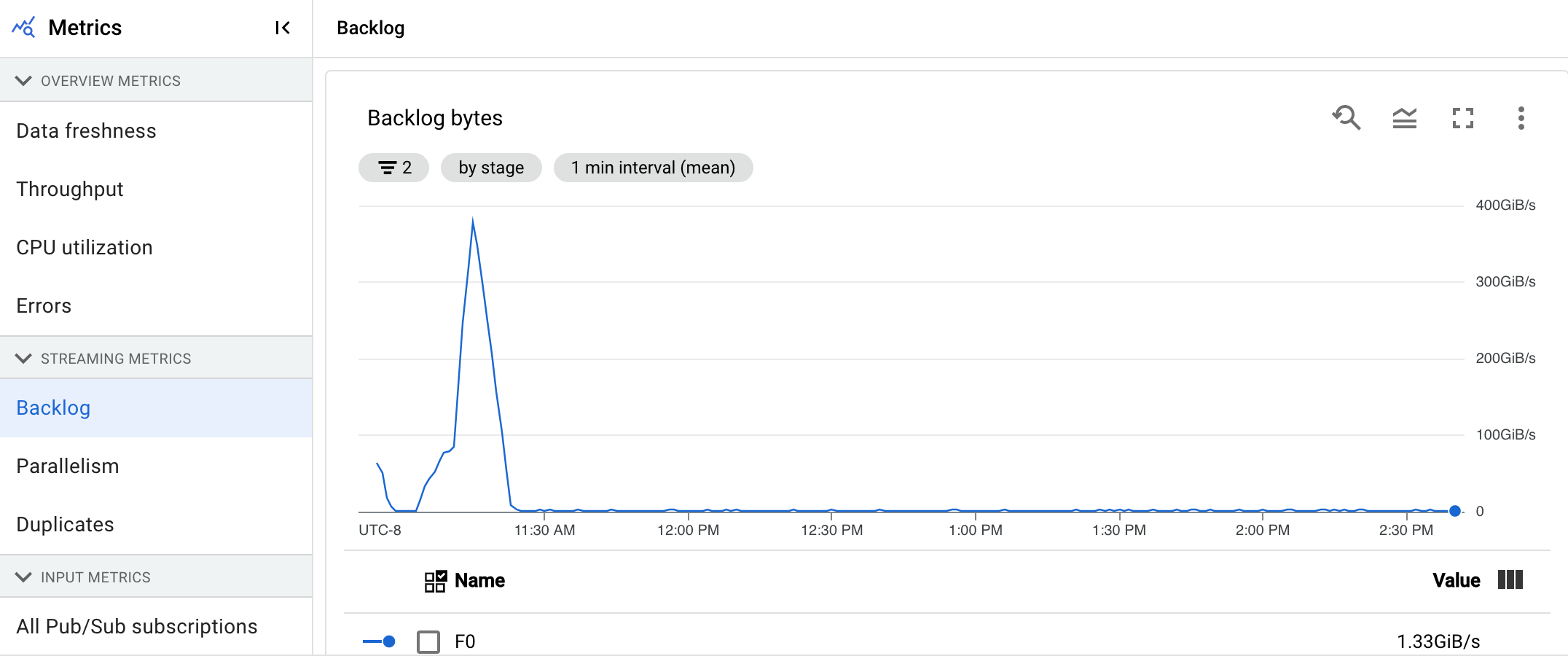
- バックログのバイト数(Streaming Engine あり、なし)
[バックログの秒数] グラフには、新しいデータがなく、スループットに変化がない場合に、現在のバックログを使用するために必要な時間(秒単位)の推定値が表示されます。バックログの推定時間は、スループットと、まだ処理が必要な入力ソースからのバックログ バイト数の両方から計算されます。この指標は、スケールアップまたはスケールダウンを行うタイミングを判断するために、ストリーミング自動スケーリング機能で使用されます。
[バックログのバイト数] グラフには、ステージの既知の未処理入力がバイト単位で表示されます。この指標は、アップストリーム ステージと対比して、各ステージで消費できる残りのバイト数を示します。この指標を正確に報告するには、パイプラインによって取り込まれる各ソースを正しく構成する必要があります。Pub/Sub や BigQuery などの組み込みソースは、すでに追加設定なしでサポートされていますが、カスタムソースには追加の実装が必要です。詳細については、制限のないカスタムソースの自動スケーリングをご覧ください。
処理中
この指標はストリーミング ジョブにのみ適用されます。
Dataflow サービスで Apache Beam パイプラインを実行すると、パイプライン タスクはワーカー VM で実行されます。[処理] ダッシュボードには、ワーカー VM でタスクが処理された時間に関する情報が表示されます。ダッシュボードには、次の 2 つのグラフが表示されます。
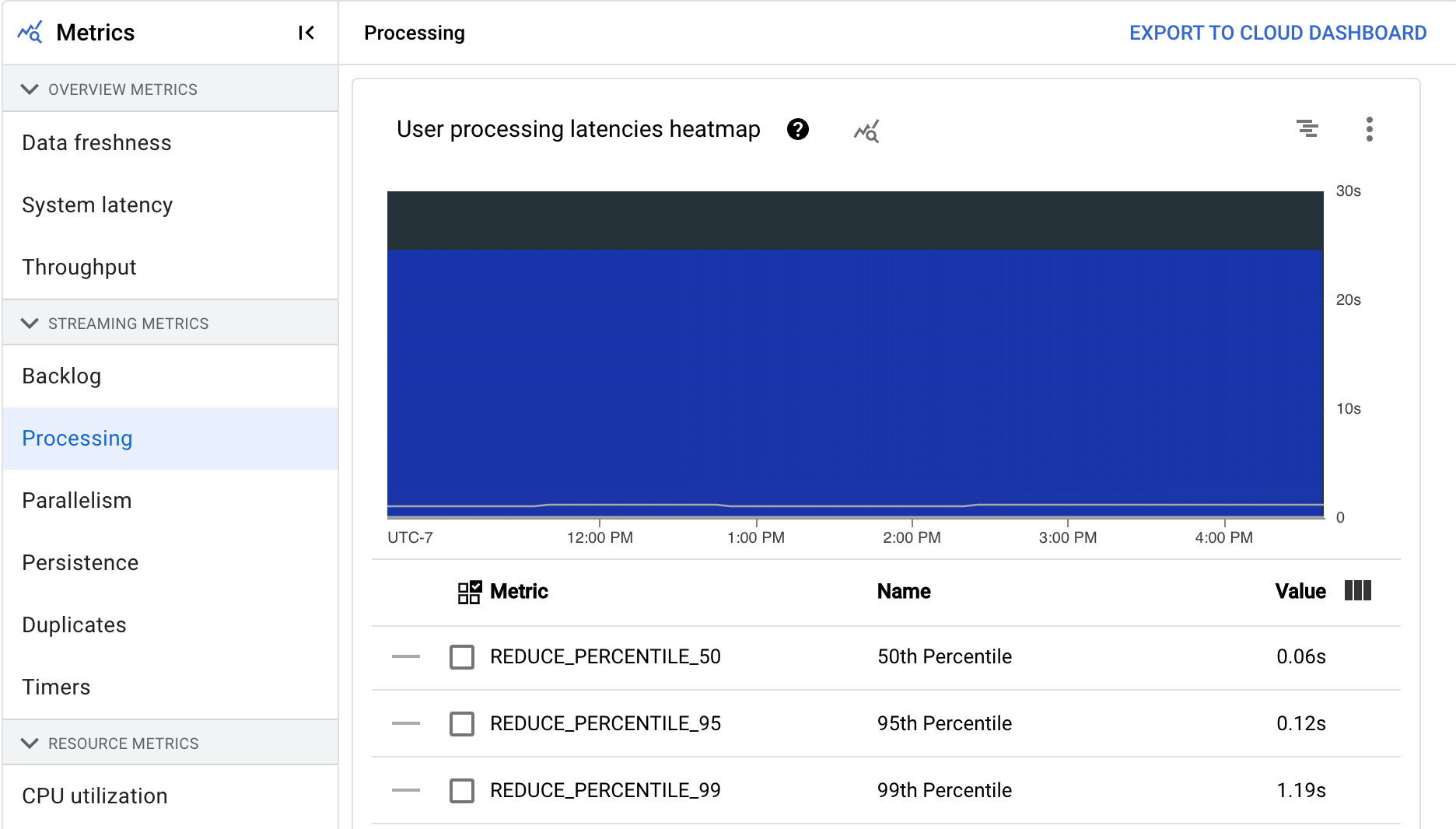
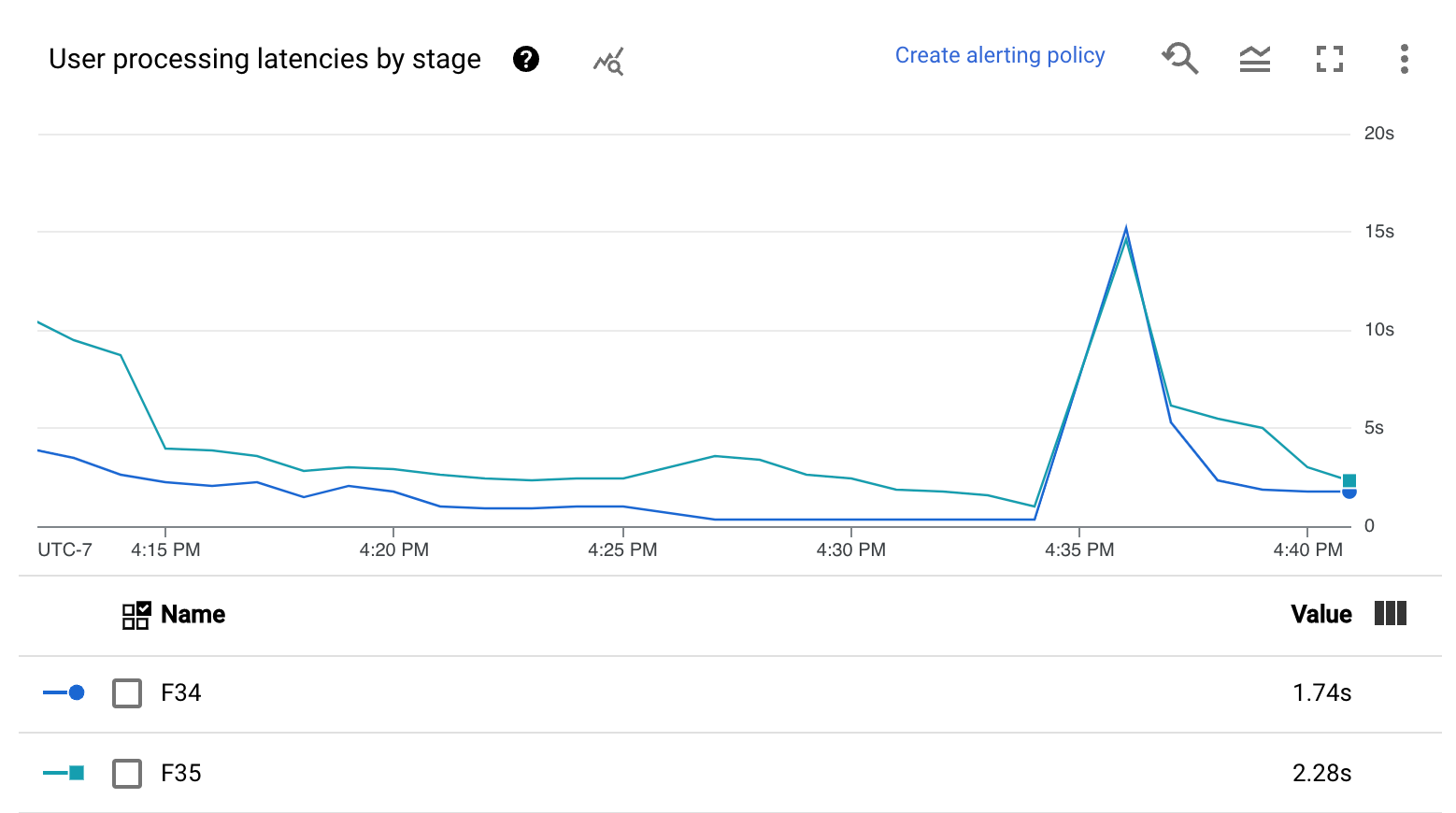
- ユーザー処理レイテンシのヒートマップ
- ステージごとのユーザー処理レイテンシ
[ユーザー処理レイテンシのヒートマップ] には、50 パーセンタイル、95 パーセンタイル、99 パーセンタイルの分布におけるオペレーションの最大レイテンシが表示されます。ヒートマップを使用すると、ロングテール オペレーションが原因でシステム全体のレイテンシが高くなっているのか、全体的なデータの更新に悪影響を与えているかを確認できます。
ダウンストリームに波及する前にアップストリームの問題を修正するには、50 パーセンタイルの高レイテンシのアラート ポリシーを設定します。
[ステージごとのユーザー処理レイテンシ] グラフには、ワーカーが処理しているすべてのタスクの 99 パーセンタイルがステージ別に表示されます。ユーザーコードがボトルネックの原因となっている場合、このグラフには、ボトルネックが発生したステージが表示されます。パイプラインをデバッグするには、次の操作を行います。
グラフを使用して、レイテンシが異常に大きいステージを探します。
ジョブの詳細ページの [実行の詳細] タブで、[グラフ表示] に [ステージのワークフロー] を選択します。[ステージのワークフロー] グラフで、レイテンシが異常に大きいステージを見つけます。
関連付けられているユーザー オペレーションを確認するには、グラフでそのステージのノードをクリックします。
詳細を確認するには、Cloud Profiler に移動し、Cloud Profiler で正しい期間のスタック トレースをデバッグします。前の手順で特定したユーザー操作を探します。
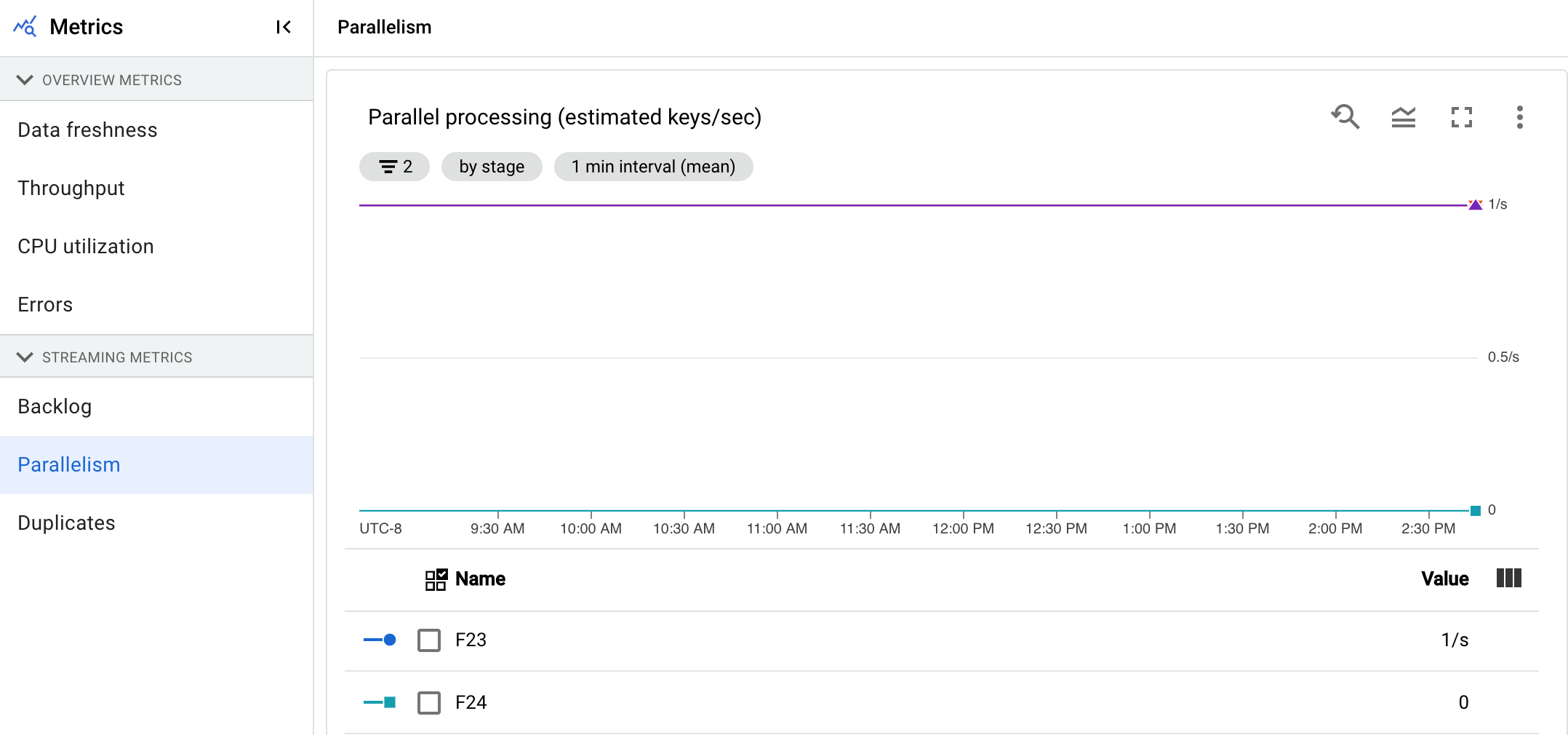
並列処理
この指標は Streaming Engine ジョブにのみ適用されます。
[並列処理] グラフには、各ステージでデータ処理に使用されるおおよそのキー数が表示されます。Dataflow は、パイプラインの並列処理に基づいてスケーリングを行います。
Dataflow がパイプラインを実行すると、処理は複数の Compute Engine 仮想マシン(VM)に分散されます。これらの仮想マシンはワーカーとしても知られています。Dataflow サービスは、パイプラインの処理ロジックを自動的に並列化し、ワーカーに分散します。特定のキーの処理はシリアル化されているため、ステージのキーの総数は、そのステージで使用可能な最大の並列処理を表します。
並列処理の指標は、低速または停滞しているパイプラインのホットキーやボトルネックを見つけるのに役立ちます。
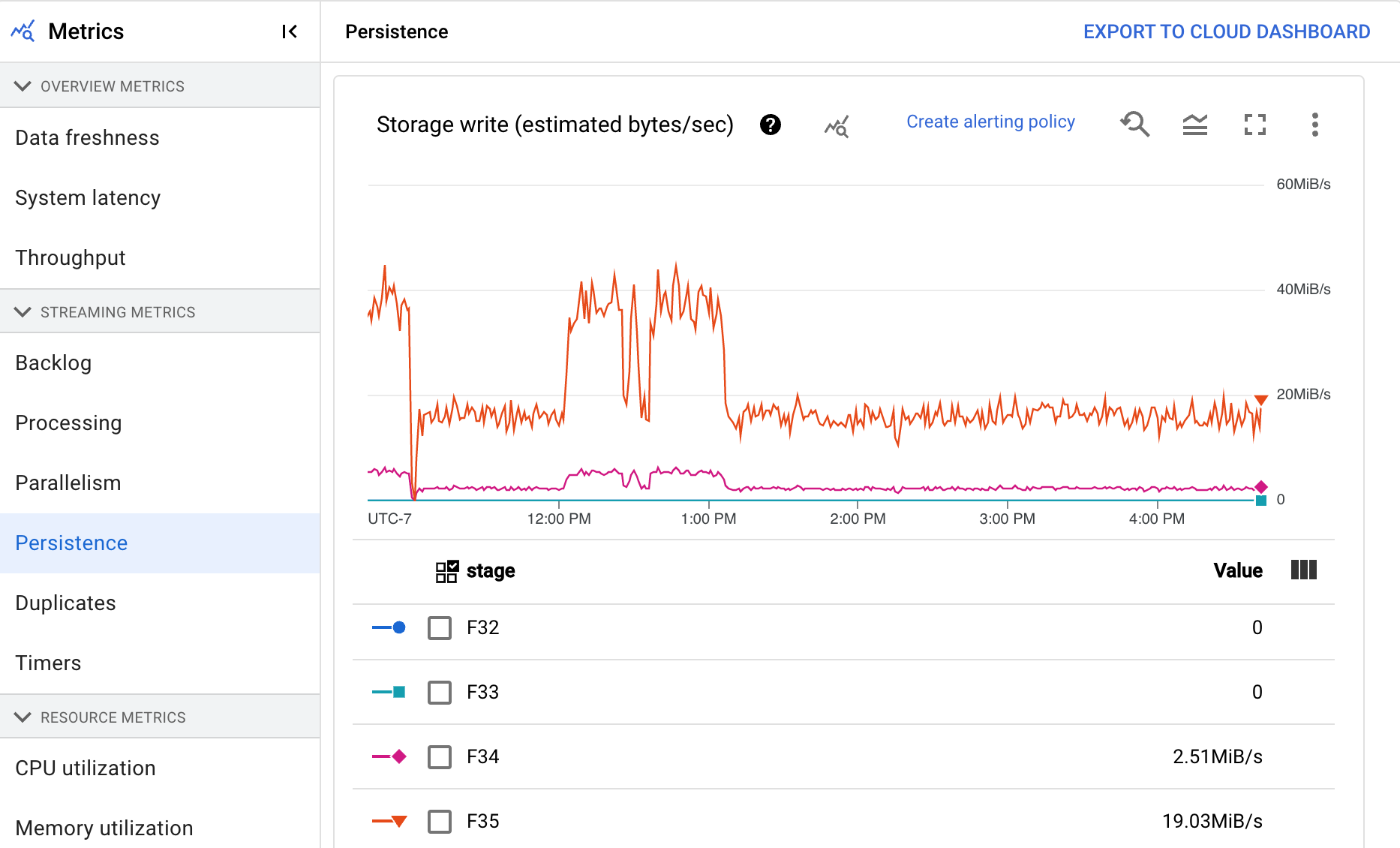
永続性
この指標はストリーミング ジョブにのみ適用されます。
[永続性] ダッシュボードには、永続ストレージが特定のパイプライン ステージによって読み書きされるレート(1 秒あたりのバイト数)に関する情報が表示されます。読み取りと書き込みのバイト数には、ユーザー状態のオペレーションと、永続シャッフル、重複除去、サイド入力、ウォーターマーク トラッキングに対応する状態が含まれます。パイプライン コーダとキャッシュ保存は、読み取りと書き込みのバイト数に影響します。内部ストレージの使用状況やキャッシュ保存に応じて、ストレージのバイト数と処理されるバイト数が異なる場合があります。
ダッシュボードには、次の 2 つのグラフが表示されます。
- ストレージ書き込み
- ストレージ読み取り
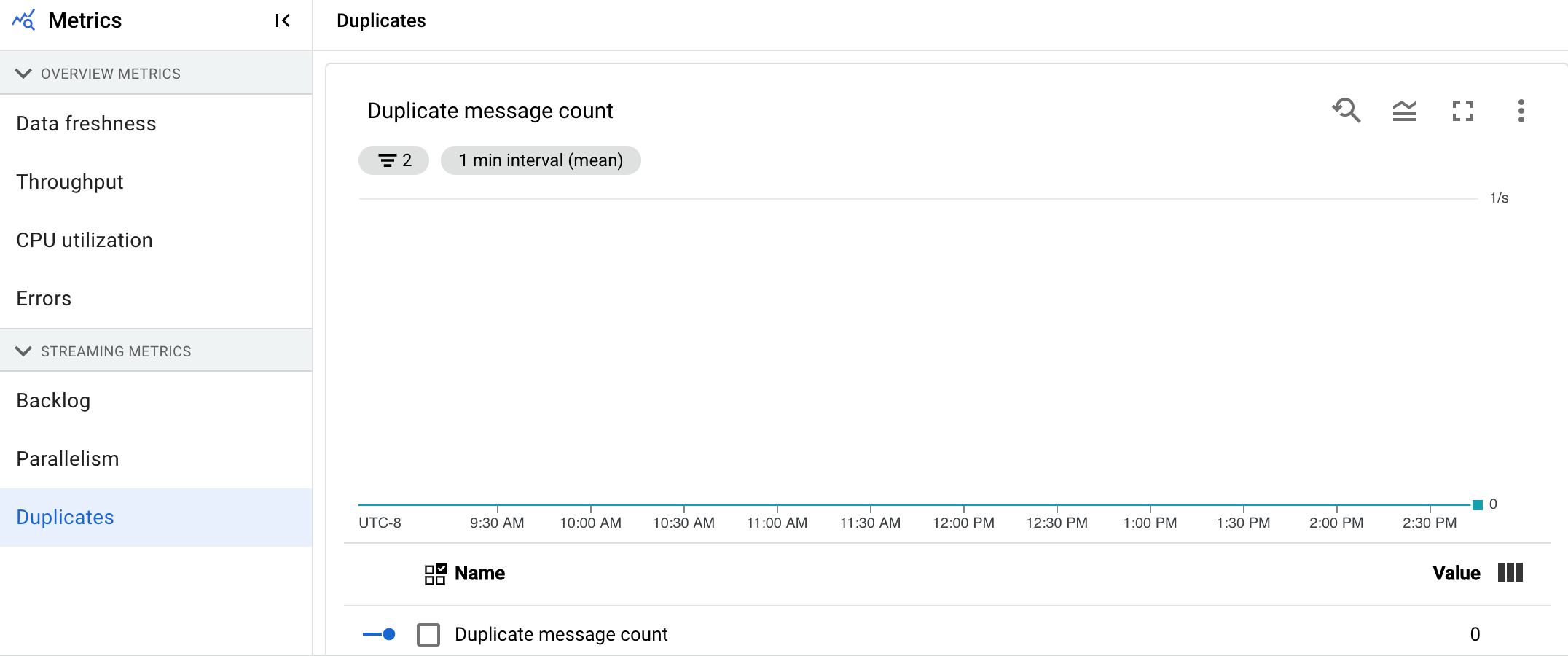
重複
この指標はストリーミング ジョブにのみ適用されます。
[重複] グラフには、特定のステージで処理され、重複として除外されたメッセージの数が表示されます。Dataflow は、at least once 配信を保証する多くのソースとシンクをサポートしています。at least once 配信の欠点は、重複が発生する可能性がある点です。Dataflow は exactly once 配信を保証するため、重複は自動的に除外されます。ダウンストリームのステージでは、同じ要素の再処理を回避できるため、状態と出力に影響はありません。各ステージで生成される重複数を減らすことで、パイプラインをリソースとパフォーマンスに対して最適化できます。
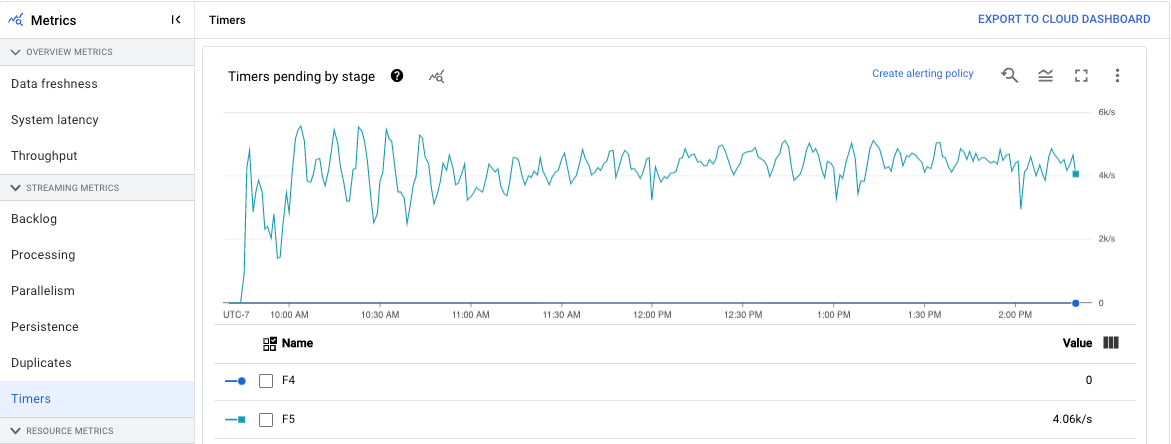
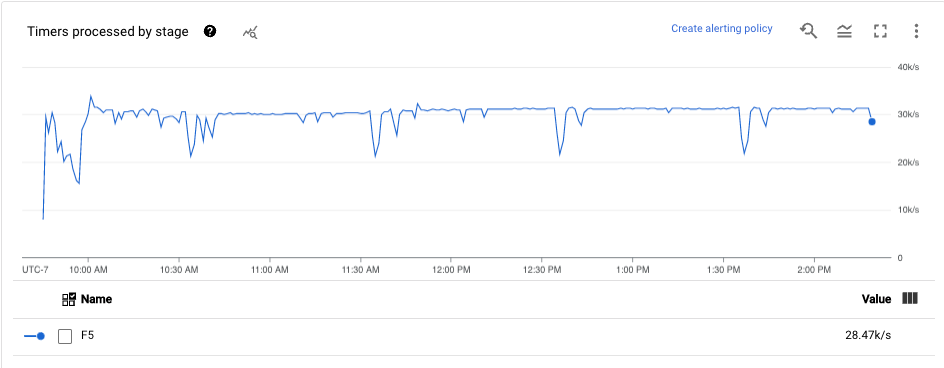
タイマー
この指標はストリーミング ジョブにのみ適用されます。
[タイマー] ダッシュボードには、保留中のタイマーの数と、特定のパイプライン ステージですでに処理されているタイマーの数が表示されます。ウィンドウはタイマーに依存するため、この指標でウィンドウの進捗を追跡できます。
ダッシュボードには、次の 2 つのグラフが表示されます。
- ステージごとの保留中タイマー
- ステージごとの処理タイマー
これらのグラフには、ある時点でのウィンドウの保留または処理の割合が表示されます。[ステージごとの保留中タイマー] グラフには、ボトルネックが原因で遅延しているウィンドウの数が表示されます。[ステージごとの処理タイマー] グラフには、要素を収集しているウィンドウの数が表示されます。
これらのグラフにはすべてのジョブタイマーが表示されます。コード内の別の場所でタイマーが使用されている場合、それらのタイマーもグラフに含まれます。
リソースの指標
[リソース指標] には、次の指標が表示されます。
CPU 使用率
CPU 使用率は、使用されている CPU の量を処理可能な CPU の量で割ったものです。このワーカーごとの指標は割合として表示されます。ダッシュボードには、次の 4 つのグラフが含まれています。
- CPU 使用率(すべてのワーカー)
- CPU 使用率(統計)
- CPU 使用率(上位 4)
- CPU 使用率(下位 4)
メモリ使用率
メモリ使用率は、ワーカーによって使用される 1 秒あたりの推定メモリ量です。ダッシュボードには、次の 2 つのグラフが表示されます。
- ワーカーの最大メモリ使用率(推定バイト数/秒)
- メモリ使用量(1 秒あたりの推定バイト数)
[ワーカーの最大メモリ使用率] グラフには、各時点で Dataflow ジョブでメモリを最も多く使用したワーカーに関する情報が表示されます。ジョブ中の複数のポイントで、最大メモリ量を使用するワーカーが変化した場合、グラフの同じ線上に複数のワーカーのデータが表示されます。線上の各データポイントは、その時点での最大メモリ量を使用してワーカーのデータを示します。グラフでは、ワーカーが使用している推定メモリとメモリの上限(バイト単位)の対比が表示されます。
このグラフを使用して、メモリ不足(OOM)の問題のトラブルシューティングを行うことができます。ワーカーのメモリ不足によるクラッシュは、このグラフに表示されません。
[メモリ使用量] グラフには、Dataflow ジョブ内のすべてのワーカーのメモリ推定値とメモリの上限(バイト単位)の比較が表示されます。
入力と出力の指標
ストリーミング Dataflow ジョブが Pub/Sub を使用してレコードを読み書きする場合、[ジョブの指標] タブに Pub/Sub の読み取りまたは書き込みの指標が表示されます。
同じタイプのすべての入力指標が結合され、すべての出力指標も結合されます。たとえば、すべての Pub/Sub 指標は 1 つのセクションにまとめられています。各指標タイプは別々のセクションにまとめられています。表示する指標を変更するには、探している指標を最もよく表すセクションを左側で選択します。次の画像は、利用可能なすべてのセクションを示しています。
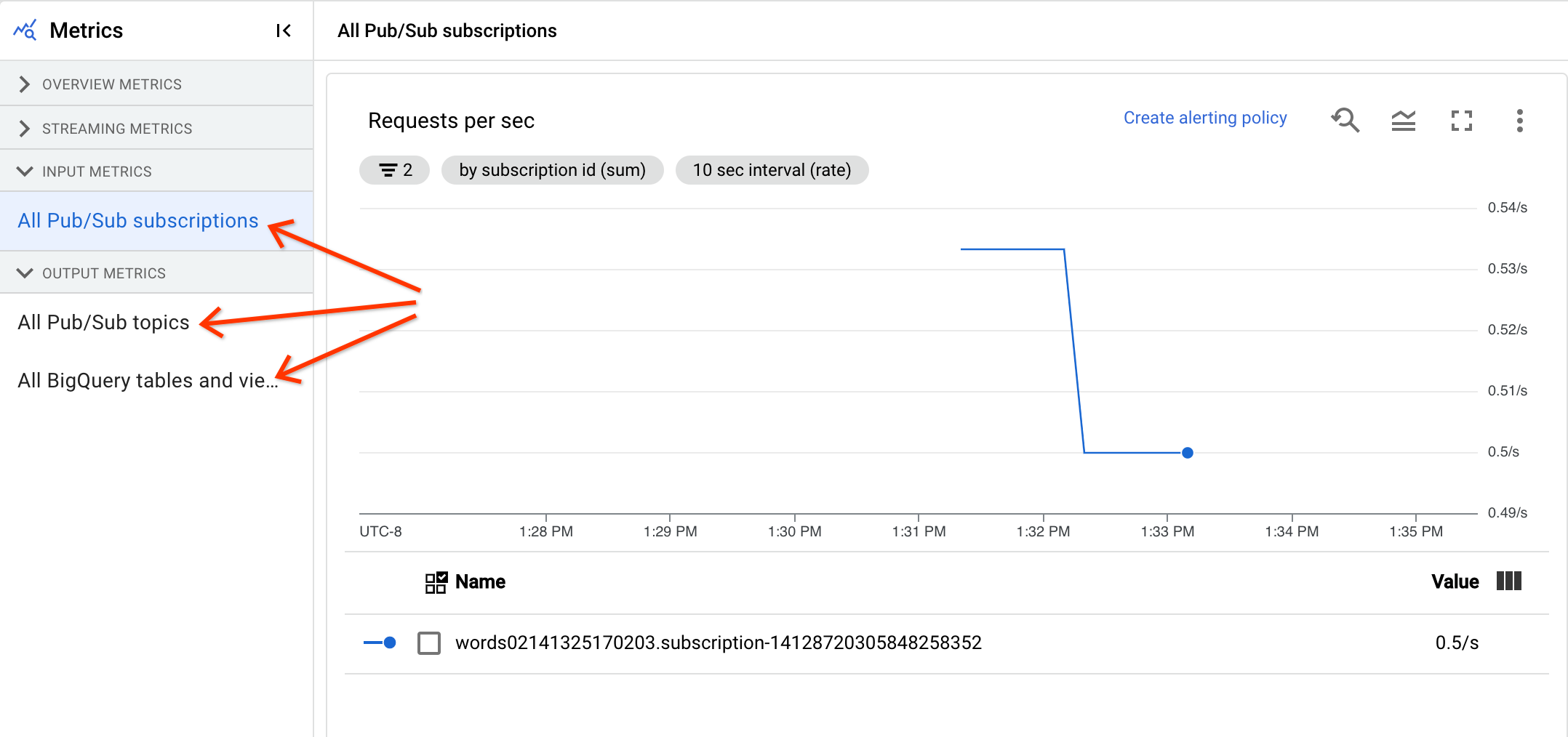
次の 2 つのグラフが、[入力の指標] セクションと [出力の指標] セクションに表示されます。
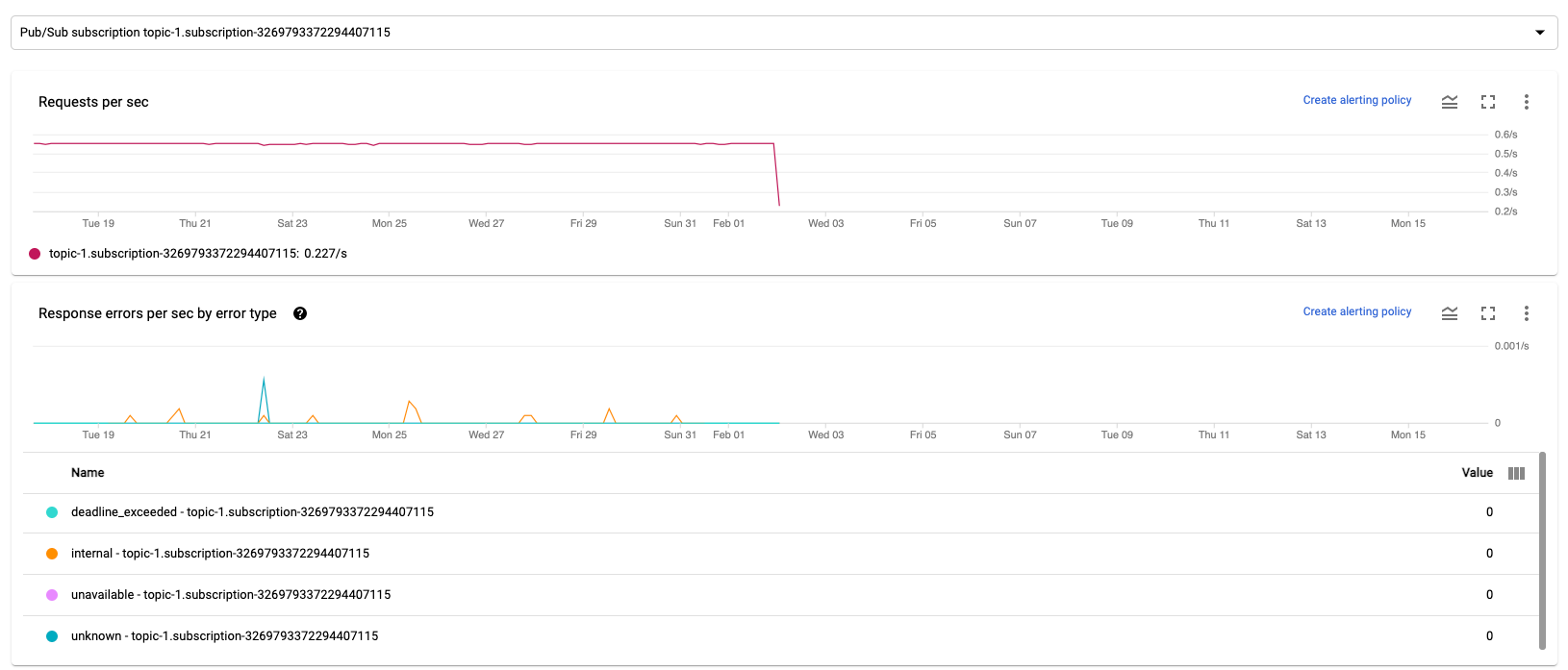
1 秒あたりのリクエスト数
1 秒あたりのリクエスト数は、一定期間に発生したデータの読み取りまたは書き込みを行う API リクエストの頻度をソース別またはシンク別に集計した値です。レートが 0 になるか、長時間にわたり、予想される動作よりも大幅に低下している場合は、パイプラインによる特定のオペレーションの実行がブロックされている可能性があります。また、読み取るデータがない可能性もあります。このような場合は、システム ウォーターマークの高いジョブステップを確認します。また、ワーカーログを調べて、エラーや処理が遅いことを示す兆候がないか調べます。

エラーの種類別のレスポンス エラー数/秒
1 秒あたりのエラーの種類別のレスポンス エラーは、一定期間に発生したデータの読み取りまたは書き込みを行う API リクエストの失敗の頻度をソース別またはシンク別に集計した値です。このようなエラーが頻繁に発生すると、API リクエストの処理が遅くなる可能性があります。このようなエラーが発生している API リクエストは調査する必要があります。これらの問題のトラブルシューティングを行うには、入力エラーコードと出力エラーコードをご覧ください。また、Pub/Sub エラーコードなど、ソースまたはシンクで使用される特定のエラーコードに関するドキュメントもご確認ください。

これらの指標をデバッグに使用するシナリオについては、「遅いジョブまたは停止したジョブのトラブルシューティング」のデバッグツールをご覧ください。
Cloud Monitoring を使用する
Dataflow は Cloud Monitoring と完全に統合されています。Cloud Monitoring は次のタスクに使用します。
- ジョブがユーザー定義のしきい値を超えた場合のアラートを作成します。
- Metrics Explorer を使用してクエリを作成し、指標の期間を調整します。
- Dataflow モニタリング インターフェースに表示されない指標を表示します。
アラートの作成と Metrics Explorer の使用方法については、Dataflow パイプラインに Cloud Monitoring を使用するをご覧ください。
Dataflow の指標の完全なリストについては、Google Cloud 指標のドキュメントをご覧ください。
Cloud Monitoring アラートを作成する
Cloud Monitoring では、Dataflow ジョブがユーザー定義のしきい値を超えたときのアラートを作成できます。指標グラフから Cloud Monitoring アラートを作成するには、[通知ポリシーを作成] をクリックします。
モニタリング グラフを表示できない場合やアラートを作成できない場合は、追加の Monitoring 権限が必要な場合があります。
Metrics Explorer で表示する
Metrics Explorer で Dataflow 指標グラフを表示できます。このグラフでは、クエリを作成し、指標の期間を調整できます。
Metrics Explorer で Dataflow グラフを表示するには、[ジョブの指標] ビューで [その他のグラフ オプション] を開き、[Metrics Explorer で表示] をクリックします。
指標の期間を調整する場合は、事前定義の期間を選択するか、カスタム期間を選択してジョブを分析できます。
デフォルトでは、ストリーミング ジョブと処理中のバッチジョブの場合、そのジョブの直近 6 時間の指標が表示されます。停止または完了したストリーミング ジョブの場合、デフォルトではジョブの所要時間全体が表示されます。
Dataflow I/O 指標
Metrics Explorer では、次の Dataflow I/O 指標を表示できます。
job/pubsub/write_count: Dataflow ジョブの PubsubIO.Write からの Pub/Sub パブリッシュ リクエスト。job/pubsub/read_count: Dataflow ジョブの PubsubIO.Read からの Pub/Sub pull リクエスト。job/bigquery/write_count: Dataflow ジョブの BigQueryIO.Write からの BigQuery 公開リクエスト。job/bigquery/write_count指標は、WriteToBigQuery 変換を使用した Python パイプラインで使用可能で、Apache Beam v2.28.0 以降ではmethod='STREAMING_INSERTS'が有効になっています。この指標は、バッチ パイプラインとストリーミング パイプラインの両方で使用できます。- パイプラインで BigQuery ソースまたはシンクを使用している場合、割り当ての問題のトラブルシューティングを行うには、BigQuery Storage API 指標を使用します。
DoFn の指標
Streaming Engine を使用し、Runner v2 を使用しないストリーミング ジョブ場合、個々のユーザー定義 DoFns について次の指標を表示できます。
job/dofn_latency_average: 過去 3 分間における 1 つのDoFnの平均メッセージ処理時間(ミリ秒単位)。job/dofn_latency_max: 過去 3 分間における 1 つのDoFnの最大メッセージ処理時間(ミリ秒単位)。job/dofn_latency_min: 過去 3 分間における 1 つのDoFnの最小メッセージ処理時間(ミリ秒単位)。job/dofn_latency_num_messages: 過去 3 分間における 1 つのDoFnによって処理されたメッセージの数。job/dofn_latency_total: 過去 3 分間における 1 つのDoFn内のすべてのメッセージの合計メッセージ処理時間(ミリ秒単位)。job/oldest_active_message_age:DoFn内で最も古いアクティブ メッセージが処理されている時間(ミリ秒単位)。
これらの指標には、Apache Beam SDK バージョン 2.53.0 以降が必要です。これらの指標を表示するには、Metrics Explorer を使用します。
これらの指標を使用すると、ジョブの処理レイテンシに最も影響を与えている DoFns を確認できます。たとえば、ジョブが停止している場合は、job/oldest_active_message_age 指標を使用して、最も古いアクティブなメッセージを含む DoFn を見つけます。次の図は、この指標で急増している DoFn を示しています。
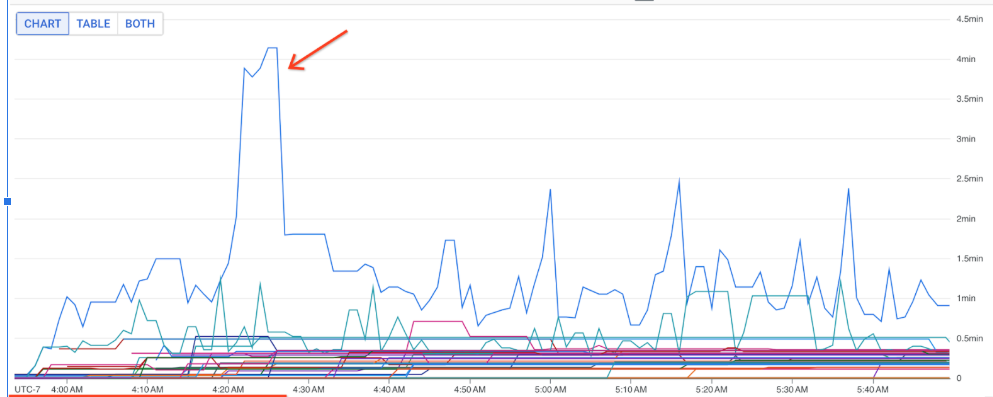
DoFn の名前を表示するには、グラフ線の上にポインタを置きます。
次のステップ
- ストリーミング ジョブの速度が遅い場合や停止している場合のトラブルシューティング。
- バッチジョブの速度が遅い場合や停止している場合のトラブルシューティング。
- ストリーミング パイプラインの水平自動スケーリングを調整する
- 費用の最適化