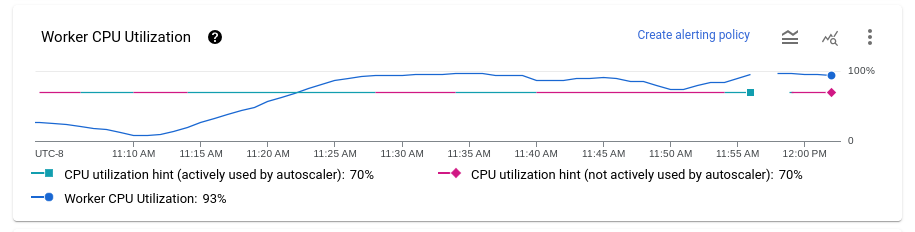
過度のダウンスケーリング。目標 CPU 使用率が高すぎると、Dataflow がスケールダウンし、バックログが増加し始め、安定したワーカー数に収束するのではなく Dataflow がスケールアップして補正するというパターンが見られる場合があります。この問題を軽減するには、ワーカー使用率のヒントを低く設定してみてください。バックログが増加し始めた時点の CPU 使用率を確認し、使用率のヒントをその値に設定します。
アップスケーリングが遅すぎる。アップスケーリングが遅すぎると、トラフィックの急増に追いつかず、レイテンシが増加する可能性があります。ワーカー使用率のヒントを減らして、Dataflow がより迅速にスケールアップするようにします。バックログが増加し始めた時点の CPU 使用率を確認し、使用率のヒントをその値に設定します。レイテンシとコストの両方をモニタリングしてください。プロビジョニングするワーカー数を増やすと、ヒント値が小さくなり、パイプラインの総コストが増加する可能性があります。
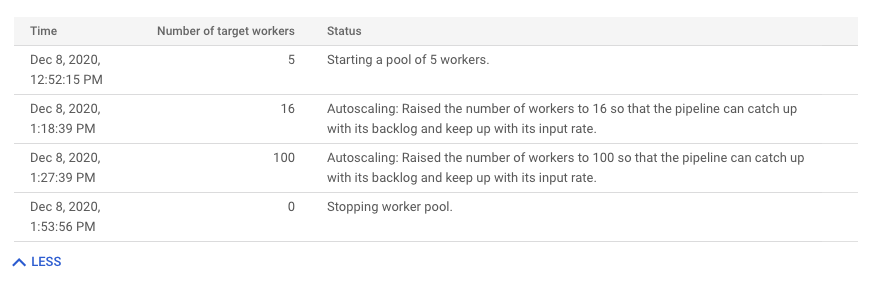
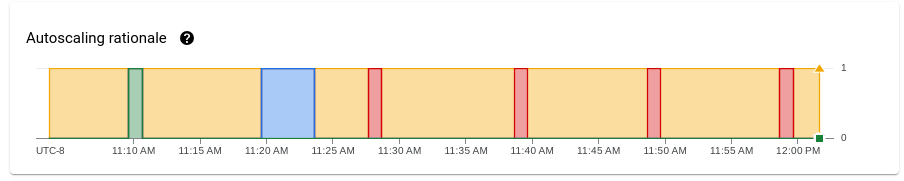
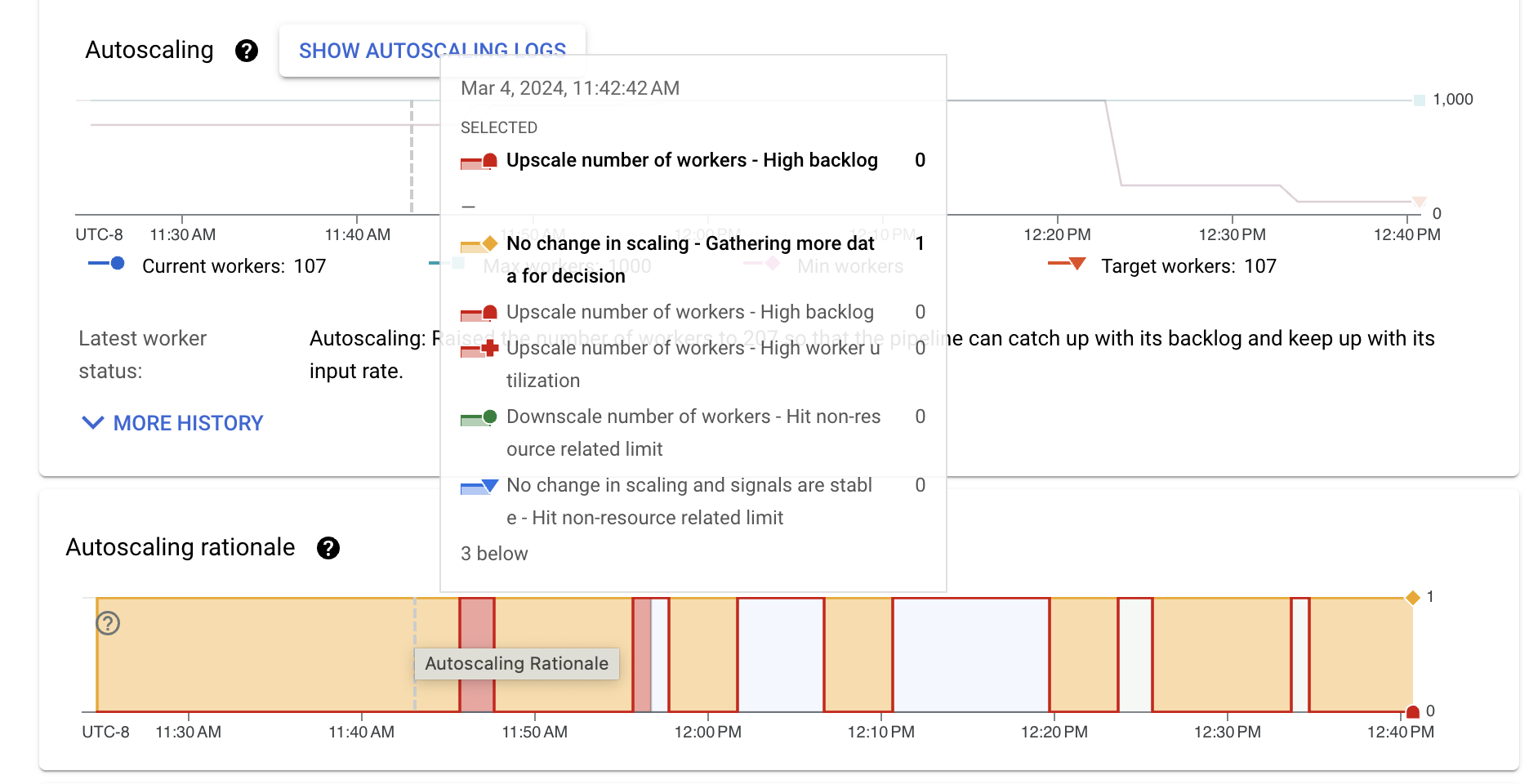
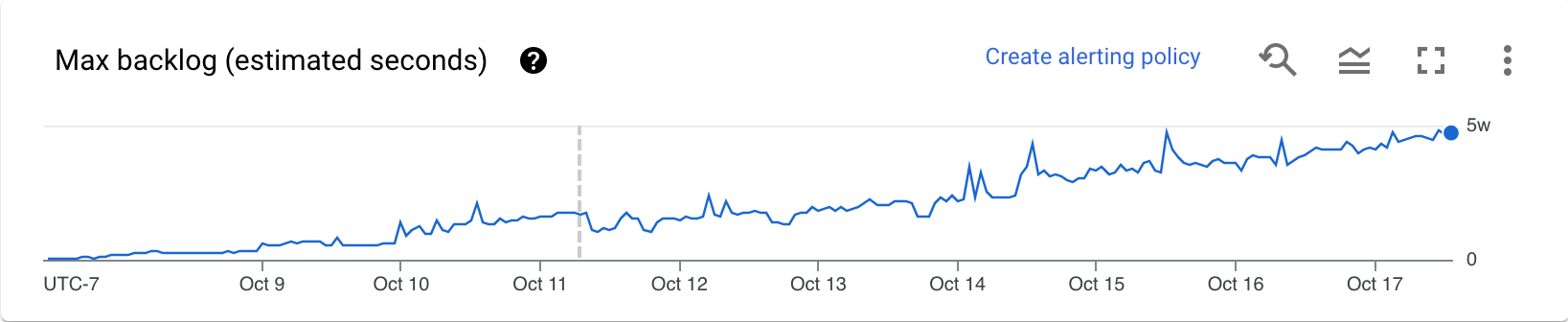
[[["わかりやすい","easyToUnderstand","thumb-up"],["問題の解決に役立った","solvedMyProblem","thumb-up"],["その他","otherUp","thumb-up"]],[["わかりにくい","hardToUnderstand","thumb-down"],["情報またはサンプルコードが不正確","incorrectInformationOrSampleCode","thumb-down"],["必要な情報 / サンプルがない","missingTheInformationSamplesINeed","thumb-down"],["翻訳に関する問題","translationIssue","thumb-down"],["その他","otherDown","thumb-down"]],["最終更新日 2025-09-04 UTC。"],[[["\u003cp\u003eDataflow's monitoring interface includes autoscaling charts that display worker instance counts, autoscaling logs, estimated backlog, and average CPU utilization for streaming jobs.\u003c/p\u003e\n"],["\u003cp\u003eThe autoscaling feature automatically adjusts the number of worker instances required for a job based on its needs, and this can be viewed under the \u003cstrong\u003eAutoscaling\u003c/strong\u003e tab.\u003c/p\u003e\n"],["\u003cp\u003eThe \u003cstrong\u003eAutoscaling\u003c/strong\u003e, \u003cstrong\u003eBacklog\u003c/strong\u003e (Streaming Engine only), and \u003cstrong\u003eCPU utilization\u003c/strong\u003e charts allow users to correlate metrics with worker scaling events, including viewing the rationale behind scaling actions.\u003c/p\u003e\n"],["\u003cp\u003eThe worker utilization hint can be adjusted to fine-tune how quickly Dataflow scales up or down, and guidance is provided for addressing excessive upscaling, downscaling, and too-slow upscaling.\u003c/p\u003e\n"],["\u003cp\u003eTo access these metrics, users need to sign into the google cloud console, select their project, navigate to Dataflow, and select the job they want to monitor.\u003c/p\u003e\n"]]],[],null,["# Monitor Dataflow autoscaling\n\nYou can view autoscaling monitoring charts for streaming jobs within the\nDataflow monitoring\ninterface. These charts display metrics over the duration of a pipeline job and\ninclude the following information:\n\n- The number of worker instances used by your job at any point in time\n- The autoscaling log files\n- The estimated backlog over time\n- The average CPU utilization over time\n\nThe charts are aligned vertically so that you can correlate the backlog and CPU\nutilization metrics with worker scaling events.\n\nFor more information about how Dataflow makes autoscaling decisions,\nsee the [Autotuning features](/dataflow/docs/guides/deploying-a-pipeline#autotuning-features) documentation.\nFor more information about Dataflow monitoring and metrics, see\n[Use the Dataflow monitoring interface](/dataflow/docs/guides/monitoring-overview).\n\nAccess autoscaling monitoring charts\n------------------------------------\n\nYou can access the Dataflow monitoring interface by using the\n[Google Cloud console](https://console.cloud.google.com/). To access the **Autoscaling** metrics tab, follow these steps:\n\n1. [Sign in](https://console.cloud.google.com/) to the Google Cloud console.\n2. Select your Google Cloud project.\n3. Open the navigation menu.\n4. In **Analytics** , click **Dataflow**. A list of Dataflow jobs appears along with their status.\n5. Click the job that you want to monitor, and then click the **Autoscaling** tab.\n\nMonitor autoscaling metrics\n---------------------------\n\nThe Dataflow service automatically chooses the number of\nworker instances required to run your autoscaling job. The\nnumber of worker instances can change over time according to the job\nrequirements.\n\nYou can view autoscaling metrics in the **Autoscaling** tab of the\nDataflow interface. Each metric is organized into the following charts:\n\n- [Autoscaling](#autoscaling)\n- [Backlog (Streaming Engine only)](#backlog)\n- [CPU utilization](#cpu-use)\n\nThe autoscaling action bar displays the current autoscaling status and workers count.\n\n### Autoscaling\n\nThe **Autoscaling** chart shows a time-series graph of the current number of\nworkers, the target number of workers, and the\n[minimum and maximum number of workers](/dataflow/docs/guides/tune-horizontal-autoscaling#set-range).\n\nTo see the autoscaling logs, click **Show autoscaling logs**.\n\nTo see the history of autoscaling changes, click **More history**.\nA table with information about the worker history of your pipeline is shown.\nThe history includes autoscaling events, including whether the number of workers\nreached the minimum or maximum worker count.\n\n### Autoscaling rationale (Streaming Engine only)\n\nThe **Autoscaling rationale** chart shows why the autoscaler scaled up,\nscaled down, or took no actions during a given time period.\n\nTo see a description of the rationale at a specific point, hold the pointer over\nthe chart.\n\nThe following table lists scaling actions and possible scaling rationales.\n\n### Worker CPU utilization\n\nCPU utilization is the amount of CPU used divided by the amount of CPU\navailable for processing. The **Mean CPU utilization** chart shows the average\nCPU utilization for all workers over time, the\n[worker utilization hint](/dataflow/docs/guides/tune-horizontal-autoscaling#utilization-hint),\nand whether Dataflow actively used the hint as a target.\n\n### Backlog (Streaming Engine only)\n\nThe **Maximum backlog** chart provides information about elements waiting to be\nprocessed. The chart shows an estimate of the\namount of time in seconds needed to consume the current backlog if no new\ndata arrives and throughput doesn't change. The estimated backlog time is\ncalculated from both the throughput and the backlog bytes from the input source\nthat still need to be processed. This metric is used by the\n[streaming autoscaling](/dataflow/docs/horizontal-autoscaling#streaming_autoscaling)\nfeature to determine when to scale up or down.\n\nData for this chart is only available for jobs that use Streaming Engine. If your\nstreaming job doesn't use Streaming Engine, the chart is empty.\n\nRecommendations\n---------------\n\nHere are some behaviors that you might observe in your pipeline, and\nrecommendations on how to\n[tune autoscaling](/dataflow/docs/guides/tune-horizontal-autoscaling):\n\n- **Excessive downscaling**. If the target CPU utilization is set too high, you\n might see a pattern where Dataflow scales down, the backlog\n starts to grow, and Dataflow scales up again to compensate,\n instead of converging on a stable number of workers. To mitigate this issue,\n try setting a lower worker utilization hint.\n Observe the CPU utilization at the point where the backlog starts to grow, and\n set the utilization hint to that value.\n\n- **Too slow upscaling**. If upscaling is too slow, it might lag behind spikes\n in traffic, resulting in periods of increased latency. Try reducing the\n worker utilization hint,\n so that Dataflow scales up more quickly. Observe the CPU\n utilization at the point where the backlog starts to grow, and set the\n utilization hint to that value. Monitor both latency and cost, because a lower\n hint value can increase the total cost for the pipeline, if more workers are\n provisioned.\n\n- **Excessive upscaling**. If you observe excessive upscaling, resulting in\n increased cost, consider increasing the worker utilization hint.\n Monitor latency to make sure it stays within acceptable bounds for your\n scenario.\n\nFor more information, see\n[Set the worker utilization hint](/dataflow/docs/guides/tune-horizontal-autoscaling#utilization-hint).\nWhen you experiment with a new worker utilization hint value, wait a few minutes\nfor the pipeline to stabilize after each adjustment.\n\nWhat's next\n-----------\n\n- [Tune Horizontal Autoscaling for streaming pipelines](/dataflow/docs/guides/tune-horizontal-autoscaling)\n- [Troubleshoot Dataflow autoscaling](/dataflow/docs/guides/troubleshoot-autoscaling)"]]