本页面介绍了如何在 Dataflow 中为自动扩缩的批处理流水线启用 Flexible Resource Scheduling (FlexRS)。
FlexRS 使用高级调度技术、Dataflow Shuffle 服务以及抢占式虚拟机 (VM) 实例和常规虚拟机组合来降低批处理费用。通过并行运行抢占式虚拟机和常规虚拟机,Dataflow 可在系统事件期间 Compute Engine 停止抢占式虚拟机实例的情况下改善用户体验。当 Compute Engine 抢占了您正在使用的抢占式虚拟机时,FlexRS 帮助确保流水线继续运行,并且您不会丢失之前的工作成果。
使用 FlexRS 的作业利用基于服务的 Dataflow Shuffle 进行联接和分组。因此,FlexRS 作业不使用永久性磁盘资源存储临时计算结果。使用 Dataflow Shuffle 让 FlexRS 可以更好地处理工作器虚拟机的抢占,因为 Dataflow 服务不需要将数据重新分发到剩余的工作器。不过,每个 Dataflow 工作器仍然需要一个 25 GB 的小型永久性磁盘卷来存储机器映像和临时日志。
支持和限制
- 支持批处理流水线。
- 需要使用 Java 版 Apache Beam SDK 2.12.0 或更高版本、Python 版 Apache Beam SDK 2.12.0 或更高版本,或者 Go 版 Apache Beam SDK。
- 使用 Dataflow Shuffle。 启用 FlexRS 会自动启用 Dataflow Shuffle。
- 不支持 GPU。
- 不支持 Compute Engine 预留。
- FlexRS 作业会出现调度延迟的现象。因此,FlexRS 最适合对时间的要求并不严格的工作负载,例如可在某个时间段内完成的每日作业或每周作业。
延迟调度
当您提交一项 FlexRS 作业时,Dataflow 服务会将该作业放入队列中,并在作业创建后的 6 小时内提交给系统,以便执行。Dataflow 会根据可用容量和其他因素在该时间段内找到启动该作业的最佳时间。
提交 FlexRS 作业时,Dataflow 服务会执行以下步骤:
- 在作业提交后立即返回作业 ID。
- 执行早期验证。
根据早期验证结果确定下一步操作。
- 如果早期验证成功,则将该作业加入队列以等待延迟启动。
- 如果早期验证未成功,则 Dataflow 服务标记该作业失败并报告错误。
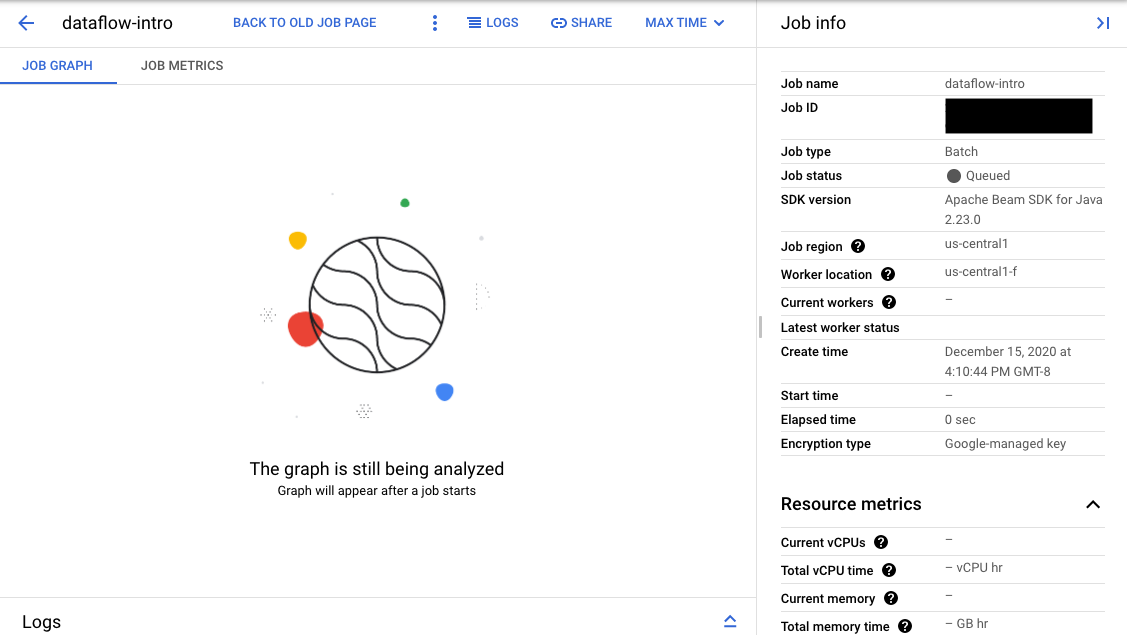
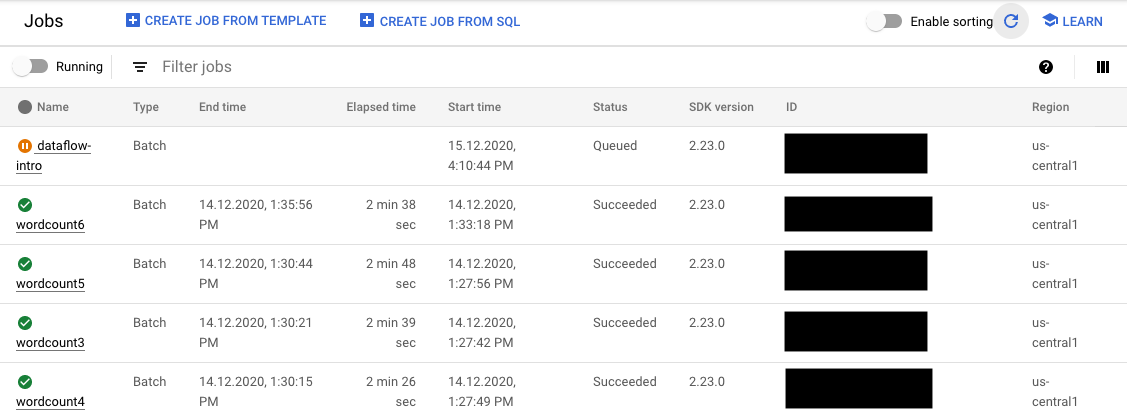
如果验证成功,您的作业会在 Dataflow 监控界面中显示 ID 和状态 Queued。如果验证失败,您的作业会显示状态 Failed。
早期验证
FlexRS 作业在提交后不会立即启动。在早期验证期间,Dataflow 服务会验证执行参数和Google Cloud 环境设置,例如 IAM 角色和网络配置。Dataflow 会在作业提交时尽可能全面地验证作业并报告潜在错误。您不需要为此早期验证过程付费。
早期验证步骤不会执行用户代码。您必须使用 Apache Beam Direct Runner 或非 FlexRS 作业验证您的代码以检查是否存在问题。如果 Google Cloud 环境在作业创建和作业延迟调度之间发生变化,则作业可能会在早期验证期间成功,但在启动时仍然失败。
启用 FlexRS
创建 FlexRS 作业后,即使作业处于已加入队列状态,也会占用并发作业配额。早期验证过程不会验证或预留任何其他配额。因此,在启用 FlexRS 之前,请验证您是否有足够的 Google Cloud 项目资源配额来启动作业。这些配额还包括抢占式 CPU、常规 CPU 和 IP 地址的额外配额(如果您启用了公共 IP 参数)。
如果您没有足够的配额,则在 FlexRS 作业部署时,您的账号可能没有足够的资源。默认情况下,Dataflow 会为工作器池中 90% 的工作器选择抢占式虚拟机。规划 CPU 配额时,请确保您有足够的抢占式虚拟机配额。您可以明确请求抢占式虚拟机配额;否则,FlexRS 作业将缺少资源,无法及时执行。
价格
系统会针对以下资源对 FlexRS 作业计费:
- 常规 CPU 和抢占式 CPU
- 内存资源
- Dataflow Shuffle 资源
- 每个工作器 25 GB 的永久性磁盘资源
虽然 Dataflow 同时使用抢占式工作器和常规工作器执行 FlexRS 作业,但无论工作器类型如何,您只需按 Dataflow 常规价格的统一折扣费率付费。Dataflow Shuffle 和 Persistent Disk 资源没有折扣。
如需了解详情,请参阅 Dataflow 价格详细信息页面。
流水线选项
Java
如需启用 FlexRS 作业,请使用以下流水线选项:
--flexRSGoal=COST_OPTIMIZED,其中费用优化目标意味着 Dataflow 服务会选择任何可用的折扣资源。--flexRSGoal=SPEED_OPTIMIZED,即针对缩短执行时间进行优化。如果未指定,则字段--flexRSGoal默认为SPEED_OPTIMIZED,与省略此标志相同。
FlexRS 作业会影响以下执行参数:
numWorkers仅设置初始工作器数量。但是,您可以基于控制费用的原因设置maxNumWorkers。- 您不能将
autoscalingAlgorithm选项与 FlexRS 作业搭配使用。 - 您不能为 FlexRS 作业指定
zone标志。Dataflow 服务会为您通过region参数指定的区域中的所有 FlexRS 作业选择地区。 - 您必须选择一个 Dataflow 位置作为您的
region。 - 您不能将 M2、M3 或 H3 机器系列用于
workerMachineType。
以下示例展示了如何添加常规流水线参数以使用 FlexRS:
--flexRSGoal=COST_OPTIMIZED \
--region=europe-west1 \
--maxNumWorkers=10 \
--workerMachineType=n1-highmem-16
如果您省略 region、maxNumWorkers 和 workerMachineType,则 Dataflow 服务会确定默认值。
Python
如需启用 FlexRS 作业,请使用以下流水线选项:
--flexrs_goal=COST_OPTIMIZED,其中费用优化目标意味着 Dataflow 服务会选择任何可用的折扣资源。--flexrs_goal=SPEED_OPTIMIZED,即针对缩短执行时间进行优化。如果未指定,则字段--flexrs_goal默认为SPEED_OPTIMIZED,与省略此标志相同。
FlexRS 作业会影响以下执行参数:
num_workers仅设置初始工作器数量。但是,您可以基于控制费用的原因设置max_num_workers。- 您不能将
autoscalingAlgorithm选项与 FlexRS 作业搭配使用。 - 您不能为 FlexRS 作业指定
zone标志。Dataflow 服务会为您通过region参数指定的区域中的所有 FlexRS 作业选择地区。 - 您必须选择一个 Dataflow 位置作为您的
region。 - 您不能将 M2、M3 或 H3 机器系列用于
machine_type。
以下示例展示了如何添加常规流水线参数以使用 FlexRS:
--flexrs_goal=COST_OPTIMIZED \
--region=europe-west1 \
--max_num_workers=10 \
--machine_type=n1-highmem-16
如果您省略 region、max_num_workers 和 machine_type,则 Dataflow 服务会确定默认值。
Go
如需启用 FlexRS 作业,请使用以下流水线选项:
--flexrs_goal=COST_OPTIMIZED,其中费用优化目标意味着 Dataflow 服务会选择任何可用的折扣资源。--flexrs_goal=SPEED_OPTIMIZED,即针对缩短执行时间进行优化。如果未指定,则字段--flexrs_goal默认为SPEED_OPTIMIZED,与省略此标志相同。
FlexRS 作业会影响以下执行参数:
num_workers仅设置初始工作器数量。但是,您可以基于控制费用的原因设置max_num_workers。- 您不能将
autoscalingAlgorithm选项与 FlexRS 作业搭配使用。 - 您不能为 FlexRS 作业指定
zone标志。Dataflow 服务会为您通过region参数指定的区域中的所有 FlexRS 作业选择地区。 - 您必须选择一个 Dataflow 位置作为您的
region。 - 您不能将 M2、M3 或 H3 机器系列用于
worker_machine_type。
以下示例展示了如何添加常规流水线参数以使用 FlexRS:
--flexrs_goal=COST_OPTIMIZED \
--region=europe-west1 \
--max_num_workers=10 \
--machine_type=n1-highmem-16
如果您省略 region、max_num_workers 和 machine_type,则 Dataflow 服务会确定默认值。
Dataflow 模板
某些 Dataflow 模板不支持 FlexRS 流水线选项。作为替代方案,您可以使用以下流水线选项。
--additional-experiments=flexible_resource_scheduling,shuffle_mode=service,delayed_launch
监控 FlexRS 作业
您可以在 Google Cloud 控制台上的两个位置监控 FlexRS 作业的状态:
在作业页面上,尚未启动的作业会显示已加入队列状态。
在监控界面页面上,在队列中等待的作业会在作业图标签页中显示“图表将在作业启动后显示”消息。