データ サンプリングを使用すると、Dataflow パイプラインの各ステップでデータをモニタリングできます。実行中のジョブや完了したジョブの実際の入出力を確認できるので、この情報はパイプラインに関する問題のデバッグに役立ちます。
データ サンプリングの用途は次のとおりです。
開発中に、パイプライン全体でどのような要素が生成されているかを確認する。
パイプラインが例外をスローした場合に、その例外に関連付けられている要素を確認する。
デバッグ時に、変換の出力を表示して、出力が正しいことを確認する。
パイプライン コードを調べることなく、パイプラインの動作を理解する。
ジョブの終了後に、サンプリングされた要素を確認する。または、サンプリング データを前回の実行と比較する。
概要
Dataflow では、次の方法でパイプライン データをサンプリングできます。
定期的なサンプリング。このタイプのサンプリングでは、Dataflow はジョブの実行時にサンプルを収集します。サンプリングされたデータを使用して、パイプラインが想定どおりに要素を処理しているかどうかを確認できます。また、ホットキーや不適切な出力などのランタイムの問題を診断できます。詳細については、このドキュメントの定期的なデータ サンプリングを使用するをご覧ください。
例外サンプリング。このタイプのサンプリングでは、パイプラインが例外をスローすると、Dataflow がサンプルを収集します。サンプルを使用して、例外発生時に処理されていたデータを確認できます。例外サンプリングはデフォルトで有効になっていますが、無効にすることもできます。詳細については、このドキュメントの例外サンプリングを使用するをご覧ください。
Dataflow は、Java の場合は gcpTempLocation パイプライン オプション、Python か Go の場合は temp_location で指定された Cloud Storage パスに、サンプリングされた要素を書き込みます。サンプリング データは Google Cloud コンソールで表示でき、Cloud Storage の元データファイルを調べても確認できます。ファイルは、削除するまで Cloud Storage に保持されます。
データのサンプリングは Dataflow ワーカーで実行されます。サンプリングはベスト エフォート型です。一時的なエラーが発生した場合、サンプルが破棄される可能性があります。
要件
データ サンプリングを使用するには、Runner v2 を有効にする必要があります。詳細については、Dataflow Runner v2 を有効にするをご覧ください。
Google Cloud コンソールでサンプリング データを表示するには、次の Identity and Access Management 権限が必要です。
storage.buckets.getstorage.objects.getstorage.objects.list
定期的なサンプリングには、次の Apache Beam SDK が必要です。
- Apache Beam Java SDK 2.47.0 以降
- Apache Beam Python SDK 2.46.0 以降
- Apache Beam Go SDK 2.53.0 以降
例外サンプリングには、次の Apache Beam SDK が必要です。
- Apache Beam Java SDK 2.51.0 以降
- Apache Beam Python SDK 2.51.0 以降
- Apache Beam Go SDK は例外サンプリングをサポートしていません。
これらの SDK からは、デフォルトですべてのジョブに対して例外サンプリングが有効になっています。
定期的なデータ サンプリングを使用する
このセクションでは、ジョブの実行中にパイプライン データを継続的にサンプリングする方法について説明します。
定期的なデータ サンプリングを有効にする
定期的なサンプリングはデフォルトで無効になっています。有効にするには、次のパイプライン オプションを設定します。
Java
--experiments=enable_data_sampling
Python
--experiments=enable_data_sampling
Go
--experiments=enable_data_sampling
このオプションは、プログラムまたはコマンドラインで設定できます。詳細については、試験運用版のパイプライン オプションを設定するをご覧ください。
Dataflow テンプレートを実行する場合は、additional-experiments フラグを使用してデータ サンプリングを有効にします。
--additional-experiments=enable_data_sampling
定期的なサンプリングを有効にすると、Dataflow はジョブグラフの各 PCollection からサンプルを収集します。サンプリング レートは 30 秒ごとに約 1 サンプルです。
データ量によっては、定期的なデータ サンプリングを行うと、パフォーマンス オーバーヘッドが大幅に増加する可能性があります。定期的なサンプリングはテスト中にのみ有効にし、本番環境のワークロードでは無効にすることをおすすめします。
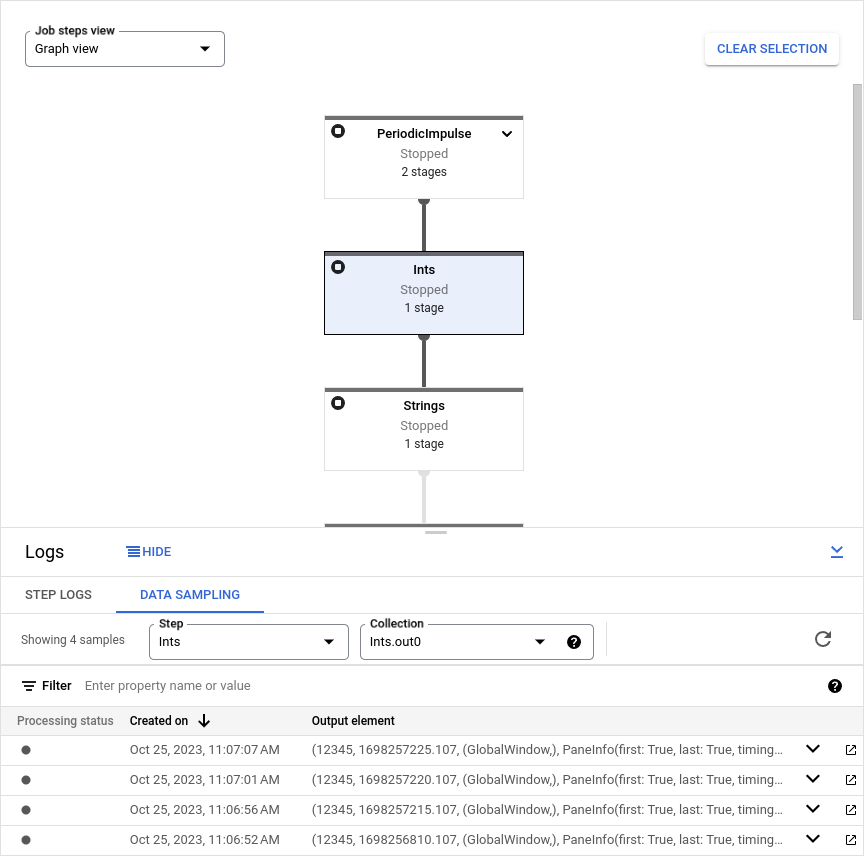
サンプリング データを表示する
Google Cloud コンソールでサンプリング データを表示するには、次の操作を行います。
Google Cloud コンソールで、Dataflow の [ジョブ] ページに移動します。
ジョブを選択します。
下のパネルの keyboard_capslock をクリックしてログパネルを開きます。
[データ サンプリング] タブをクリックします。
[ステップ] フィールドで、パイプライン ステップを選択します。ジョブグラフでステップを選択することもできます。
[コレクション] フィールドで、
PCollectionを選択します。
Dataflow がその PCollection のサンプルを収集した場合、サンプリング データがタブに表示されます。各サンプルについて、作成日と出力要素がタブに表示されます。出力要素は、要素データ、タイムスタンプ、ウィンドウとペインの情報など、コレクション要素をシリアル化した表現です。
次の例は、サンプリングされた要素を示しています。
Java
TimestampedValueInGlobalWindow{value=KV{way, [21]},
timestamp=294247-01-09T04:00:54.775Z, pane=PaneInfo{isFirst=true, isLast=true,
timing=ON_TIME, index=0, onTimeIndex=0}}
Python
(('THE', 1), MIN_TIMESTAMP, (GloblWindow,), PaneInfo(first: True, last: True,
timing: UNKNOWN, index: 0, nonspeculative_index: 0))
Go
KV<THE,1> [@1708122738999:[[*]]:{3 true true 0 0}]
次の図は、サンプリング データがGoogle Cloud コンソールでどのように表示されるかを示しています。
例外サンプリングを使用する
パイプラインが未処理の例外をスローした場合は、その例外とそれに関連付けられている入力要素を表示できます。サポートされている Apache Beam SDK を使用している場合、例外サンプリングがデフォルトで有効になっています。
例外を表示する
例外を表示する手順は次のとおりです。
Google Cloud コンソールで、Dataflow の [ジョブ] ページに移動します。
ジョブを選択します。
[ログ] パネルを開くには、[ログ] パネルの keyboard_capslock(パネルの切り替え)をクリックします。
[データ サンプリング] タブをクリックします。
[ステップ] フィールドで、パイプライン ステップを選択します。ジョブグラフでステップを選択することもできます。
[コレクション] フィールドで、
PCollectionを選択します。[例外] 列には、例外の詳細が表示されます。例外に出力要素はありません。代わりに、[出力要素] 列にはメッセージ
Failed to process input element: INPUT_ELEMENTが含まれます。ここで、INPUT_ELEMENT は関連する入力要素です。入力サンプルと例外の詳細を新しいウィンドウで表示するには、(新しいウィンドウで開く)をクリックします。
次の図は、Google Cloud コンソールで例外がどのように表示されるかを示しています。

例外サンプリングを無効にする
例外サンプリングを無効にするには、次のパイプライン オプションを設定します。
Java
--experiments=disable_always_on_exception_sampling
Python
--experiments=disable_always_on_exception_sampling
このオプションは、プログラムまたはコマンドラインで設定できます。詳細については、試験運用版のパイプライン オプションを設定するをご覧ください。
Dataflow テンプレートを実行する場合は、additional-experiments フラグを使用して例外サンプリングを無効にします。
--additional-experiments=disable_always_on_exception_sampling
セキュリティ上の考慮事項
Dataflow は、作成および管理する Cloud Storage バケットにサンプリング データを書き込みます。データを保護するため、Cloud Storage のセキュリティ機能を使用します。特に、次のセキュリティ対策を検討してください。
- 顧客管理の暗号鍵(CMEK)を使用して、Cloud Storage バケットを暗号化します。暗号化オプションの選択の詳細については、ニーズに合った暗号化を選択するをご覧ください。
- Cloud Storage バケットに有効期間(TTL)を設定し、データファイルが一定期間後に自動的に削除されるようにします。詳細については、バケットのライフサイクル構成を設定するをご覧ください。
- IAM 権限を Cloud Storage バケットに割り当てる場合は、最小権限の原則に従います。
また、PCollection データ型の個々のフィールドを難読化して、サンプリング データに未加工の値が表示されないようにすることもできます。
- Python:
__repr__メソッドまたは__str__メソッドをオーバーライドします。 - Java:
toStringメソッドをオーバーライドします。
ただし、I/O コネクタからの入力と出力を難読化するには、コネクタのソースコードを変更する必要があります。
課金
Dataflow でデータ サンプリングを実行すると、Cloud Storage データ ストレージと Cloud Storage の読み取り / 書き込みオペレーションに対して課金されます。詳しくは、Cloud Storage の料金をご覧ください。
各 Dataflow ワーカーはサンプルを一括で書き込みます。このため、バッチごとに 1 つの読み取り / 書き込みオペレーションが発生します。
トラブルシューティング
このセクションでは、データ サンプリングの使用時に発生する一般的な問題について説明します。
権限エラー
サンプルを表示する権限がない場合、 Google Cloud コンソールに次のエラーが表示されます。
You don't have permission to view a data sample.
このエラーを解決するには、必要な IAM 権限があるか確認してください。それでもエラーが発生する場合は、IAM 拒否ポリシーが適用されている可能性があります。
サンプルが表示されない
サンプルが表示されない場合は、次の点を確認してください。
enable_data_samplingオプションを設定して、データ サンプリングが有効になっていることを確認します。データ サンプリングを有効にするをご覧ください。- Runner v2 を使用していることを確認します。
- ワーカーが起動していることを確認します。ワーカーが開始されるまでサンプリングは開始されません。
- ジョブとワーカーが正常な状態であることを確認します。
- プロジェクトの Cloud Storage の割り当てを再度確認します。Cloud Storage の割り当て上限を超えると、Dataflow はサンプルデータを書き込むことができません。
- データ サンプリングでは、イテラブルからサンプリングできません。このようなタイプのストリームのサンプルは利用できません。