本页介绍了将数据从 Cloud Storage 迁移到 BigQuery 时,在命名空间级控制对 Google Cloud资源的访问权限的使用情形。
为了控制对 Google Cloud 资源的访问权限,Cloud Data Fusion 中的命名空间默认使用 Cloud Data Fusion API Service Agent。
为了更好地隔离数据,您可以将自定义的 IAM 服务账号(称为“按命名空间的服务账号”)与每个命名空间相关联。借助自定义 IAM 服务账号(不同命名空间可以有不同的服务账号),您可以控制对 Cloud Data Fusion 中流水线设计时操作(例如流水线预览、Wrangler 和流水线验证)的命名空间之间Google Cloud 资源的访问权限。
如需了解详情,请参阅使用命名空间服务账号进行访问权限控制。
场景
在此使用情形中,营销部门使用 Cloud Data Fusion 将数据从 Cloud Storage 迁移到 BigQuery。
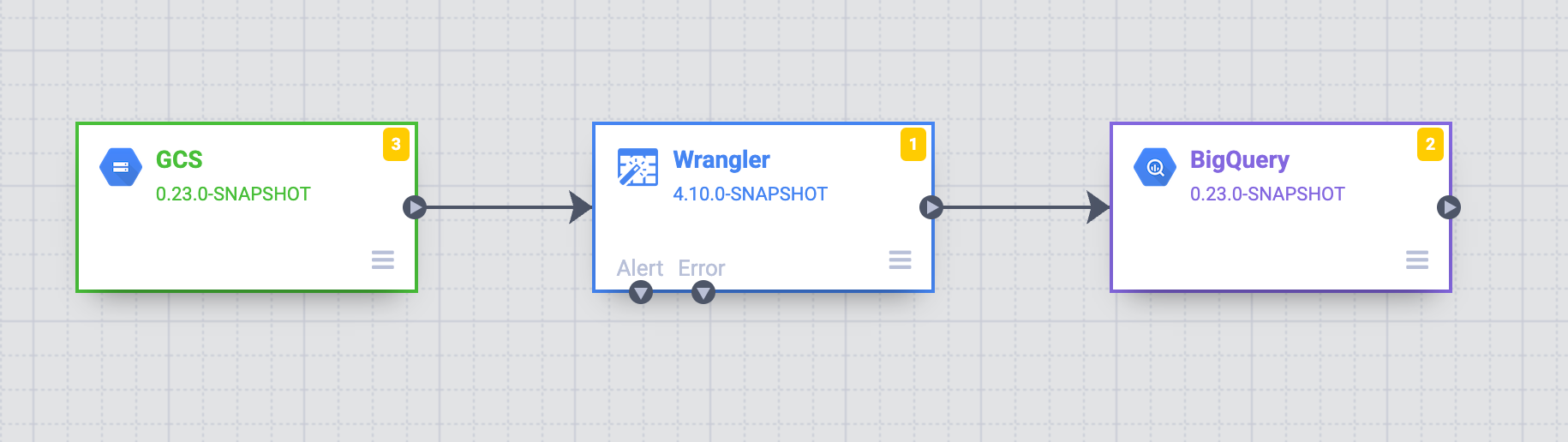
营销部门有三个团队:A、B 和 C。 您的目标是建立一种结构化方法,通过与每个团队(A、B 和 C)分别对应的 Cloud Data Fusion 命名空间来控制 Cloud Storage 中的数据访问权限。
解决方案
以下步骤展示了如何使用命名空间服务账号控制对 Google Cloud 资源的访问权限,防止不同团队的数据存储区之间发生未经授权的访问。
将 Identity and Access Management 服务账号与每个命名空间相关联
为每个团队配置命名空间中的 IAM 服务账号(请参阅配置命名空间服务账号):
通过为 A 团队添加自定义服务账号(例如
team-a@pipeline-design-time-project.iam.gserviceaccount.com)来设置访问权限控制。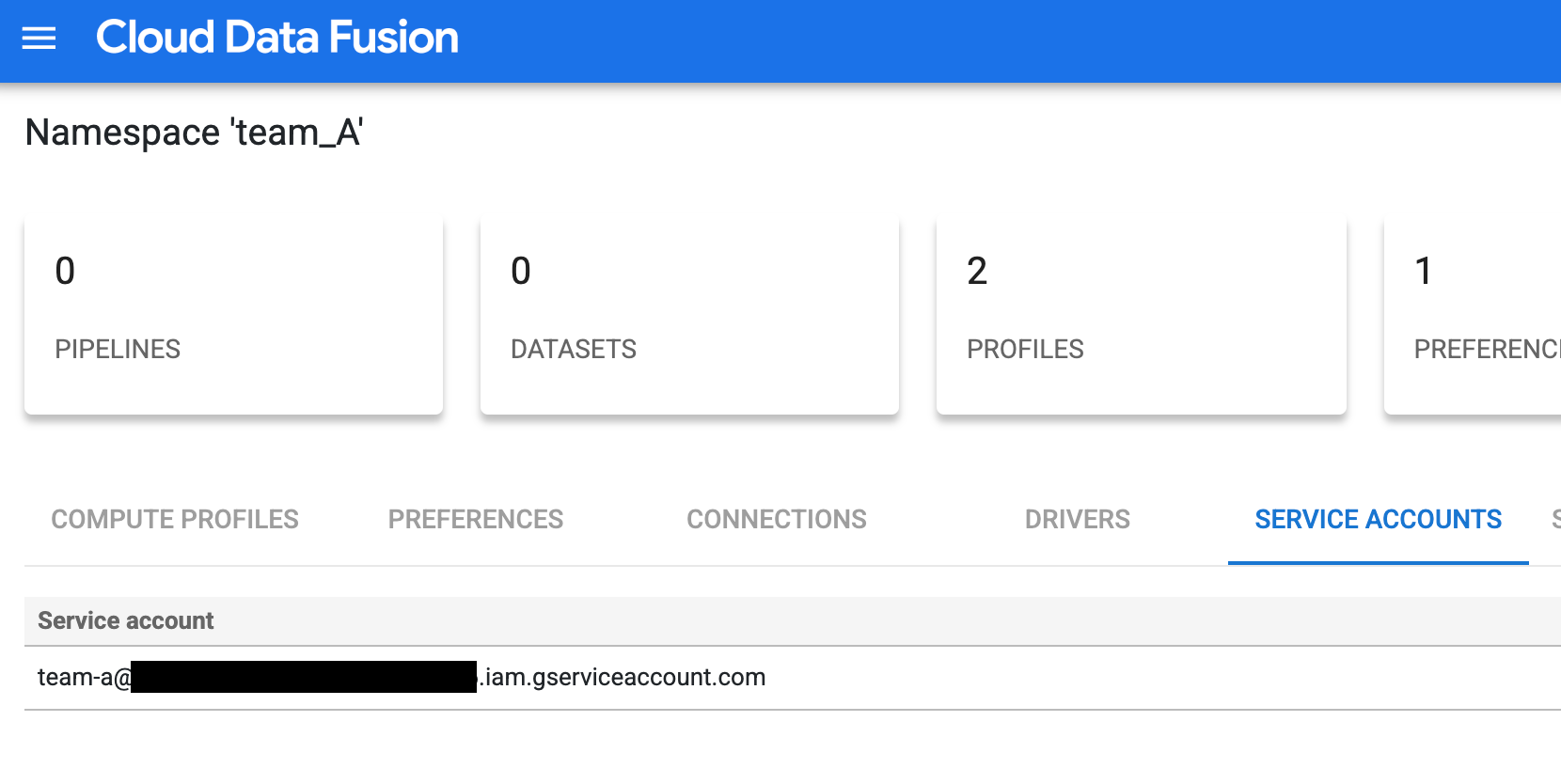
图 1:为团队 A 添加自定义服务账号。 针对团队 B 和 C 重复执行配置步骤,以设置具有类似自定义服务账号的访问权限控制。
限制对 Cloud Storage 存储分区的访问权限
通过授予适当的权限来限制对 Cloud Storage 存储分区的访问权限:
- 向 IAM 服务账号授予
storage.buckets.list权限,这是列出项目中的 Cloud Storage 存储分区所需的权限。 如需了解详情,请参阅列出存储分区。 授予 IAM 服务账号访问特定存储分区中对象的权限。
例如,向与命名空间
team_A相关联的 IAM 服务账号授予存储桶team_a1的 Storage Object Viewer 角色。此权限可让团队 A 在隔离的设计时环境中查看和列出相应存储桶中的对象和托管文件夹及其元数据。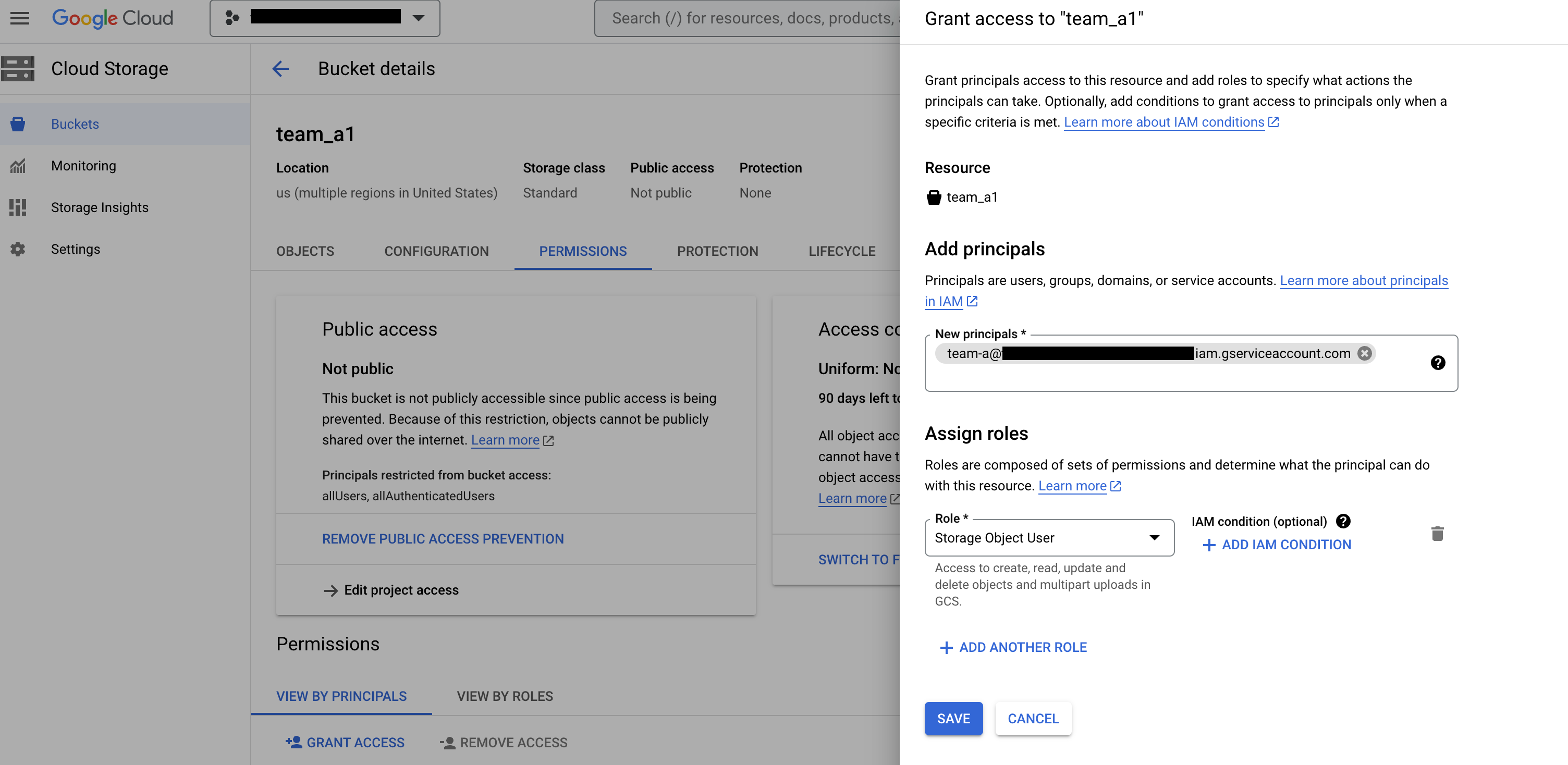
图 2:在 Cloud Storage 存储分区页面上,将团队添加为正文,并分配 Storage Object User 角色。
在相应命名空间中创建 Cloud Storage 连接
在每个团队的命名空间中创建 Cloud Storage 连接:
在 Google Cloud 控制台中,前往 Cloud Data Fusion 实例页面,然后在 Cloud Data Fusion Web 界面中打开一个实例。
依次点击系统管理员 > 配置 > 命名空间。
点击您要使用的命名空间,例如“团队 A”的命名空间。
点击连接标签页,然后点击添加连接。
选择 GCS 并配置连接。
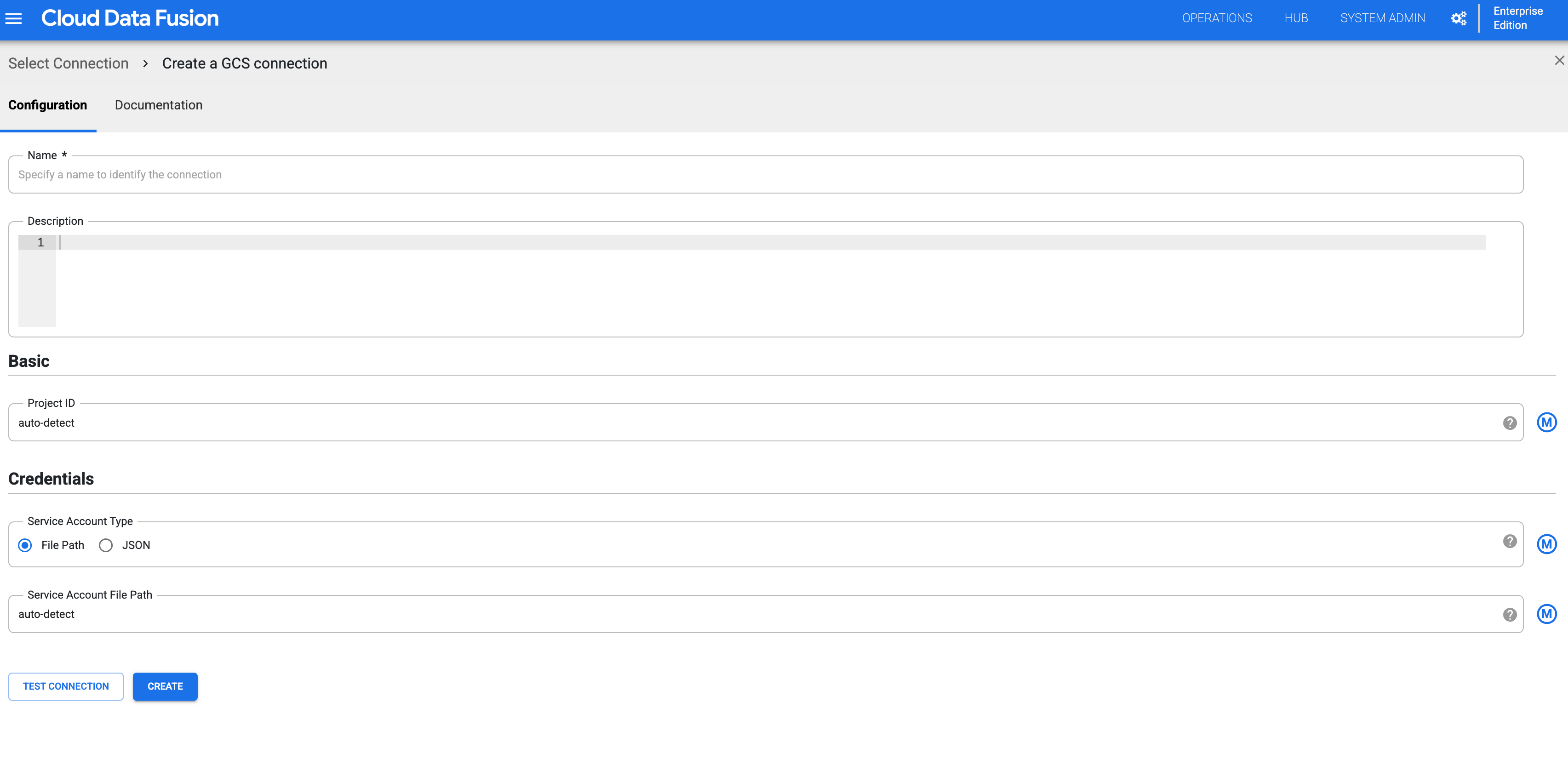
图 3:为命名空间配置 Cloud Storage 连接。 重复上述步骤,为每个命名空间创建 Cloud Storage 连接。然后,每个团队都可以与该资源的隔离副本进行交互,以执行设计时操作。
验证每个命名空间的设计时隔离
团队 A 可以通过访问各自命名空间中的 Cloud Storage 存储分区来验证设计时的隔离情况:
在 Google Cloud 控制台中,前往 Cloud Data Fusion 实例页面,然后在 Cloud Data Fusion Web 界面中打开一个实例。
依次点击系统管理员 > 配置 > 命名空间。
选择一个命名空间,例如团队 A 命名空间
team_A。依次点击 菜单 > Wrangler。
点击 GCS。
在存储桶列表中,点击
team_a1存储桶。由于“团队 A”命名空间具有
storage.buckets.list权限,因此您可以查看存储分区列表。点击该存储桶后,您可以查看其内容,因为“团队 A”命名空间具有 Storage Object Viewer 角色。
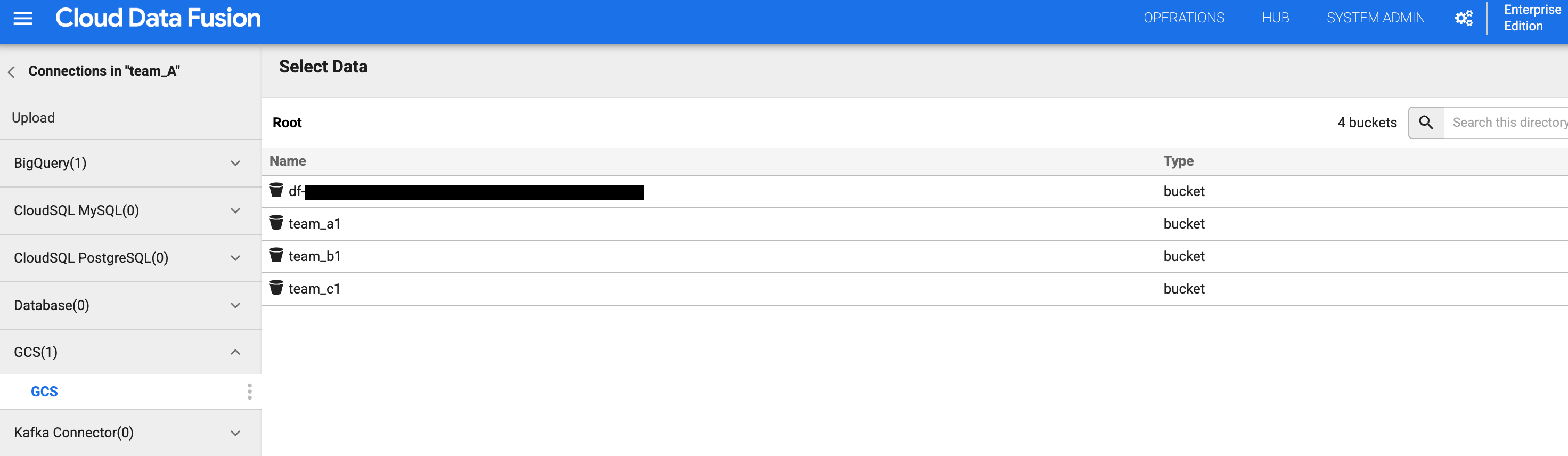
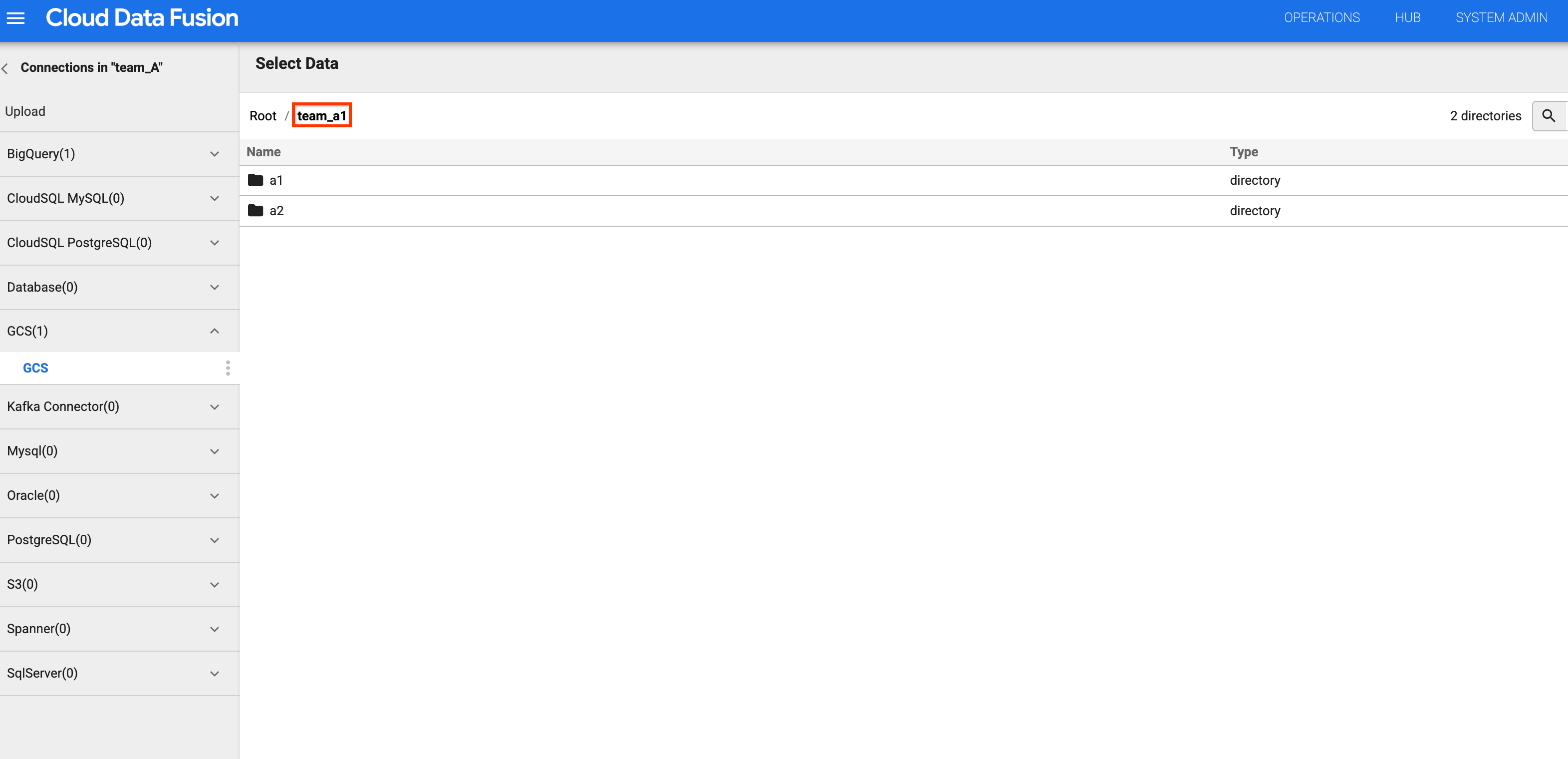
图 4 和图 5:检查团队 A 是否可以访问相应的存储桶。 返回到分桶列表,然后点击
team_b1或team_c1分桶。 由于您使用命名空间服务账号为 A 团队隔离了此设计时资源,因此访问受到限制。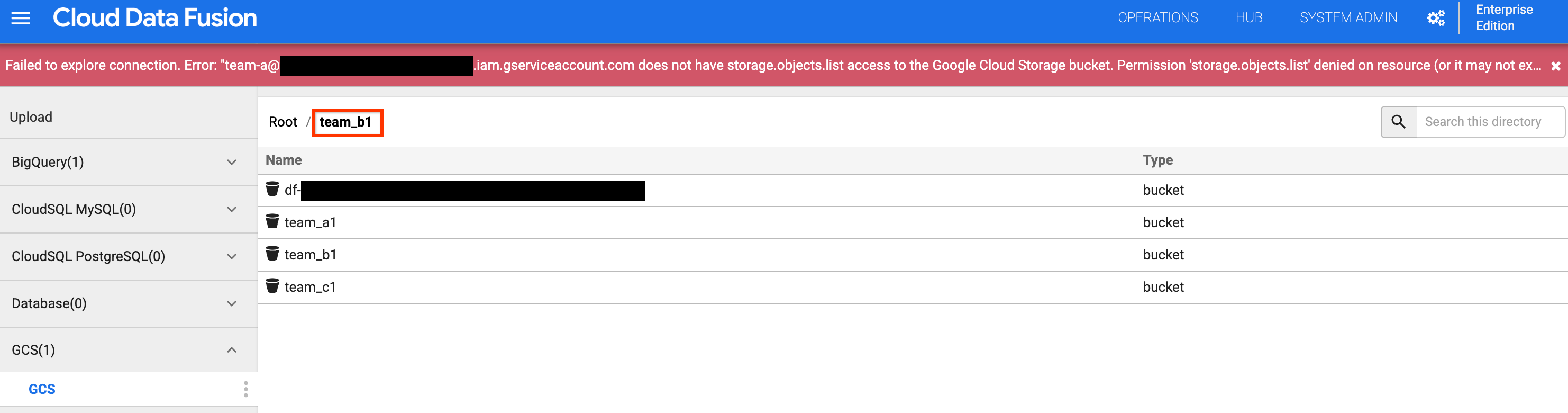
图 6:检查团队 A 是否无法访问团队 B 和 C 的存储分区。
后续步骤
- 详细了解 Cloud Data Fusion 中的安全功能。