本页面介绍了如何在部署和运行流水线时管理访问权限控制 另一个 Google Cloud 项目中的 Dataproc 集群。
场景
默认情况下,在 Google Cloud 项目中启动 Cloud Data Fusion 实例时,它会使用同一项目中的 Dataproc 集群部署和运行流水线。不过,贵组织可能要求您在其他项目中使用集群。为此 则您必须管理项目之间的访问权限。下页介绍了如何更改基准(默认)配置并应用适当的访问权限控制。
准备工作
如需了解此用例中的解决方案,您需要以下背景信息:
- 熟悉基本的 Cloud Data Fusion 概念
- 熟悉适用于 Cloud Data Fusion 的 Identity and Access Management (IAM)
- 熟悉 Cloud Data Fusion 网络
假设和范围
此用例具有以下要求:
- 私有 Cloud Data Fusion 实例。 出于安全考虑,组织可能会要求您使用此类 实例。
- BigQuery 来源和接收器。
- 使用 IAM 进行访问权限控制,而不是基于角色的访问权限控制 (RBAC)。
解决方案
此解决方案比较基准架构和特定于用例的架构和配置。
架构
下图比较了用于创建 当您在 Cloud Data Fusion 中使用集群时, 通过租户使用同一项目(基准)和在其他项目中 项目 VPC 网络
基准架构
下图显示了项目的基准架构:
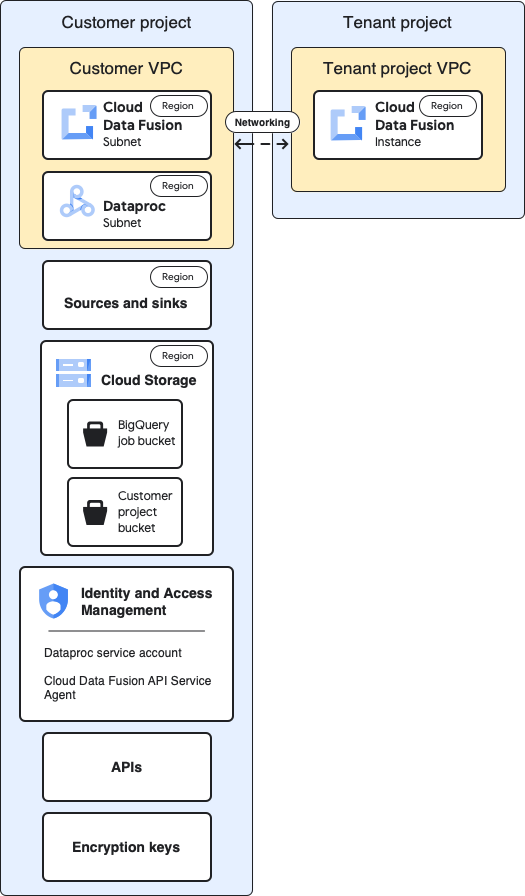
对于基准配置,您需要创建一个私有 Cloud Data Fusion 实例,并运行一个流水线,而无需进行任何其他自定义:
- 您使用的是某个内置计算配置
- 来源和接收器与实例位于同一项目中
- 未向任何服务账号授予其他角色
如需详细了解租户和客户项目,请参阅 网络。
用例架构
此图显示了在其他项目中使用集群时的项目架构 项目:
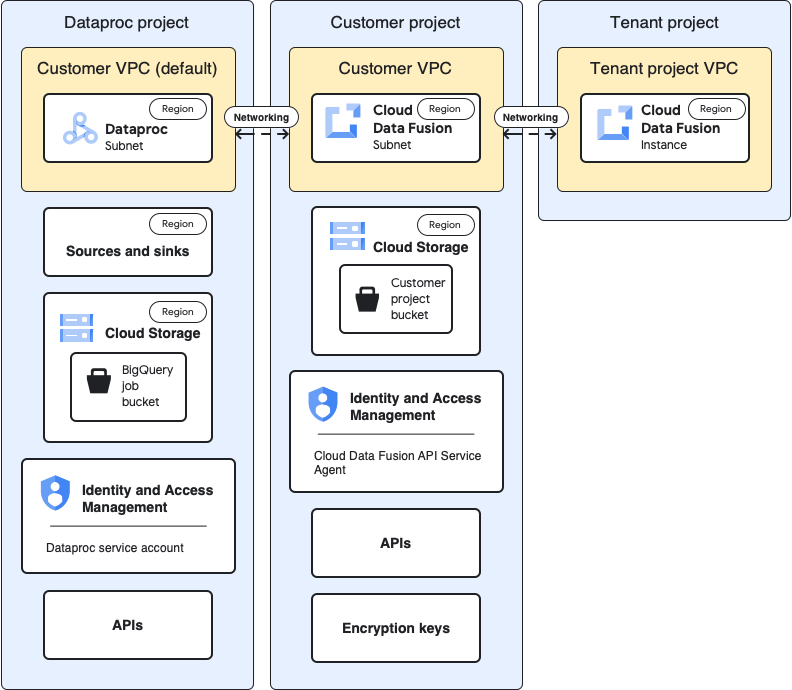
配置
以下部分将基准配置与用例进行了比较 在集群中使用 Dataproc 集群的特定配置 通过默认的租户项目 VPC 访问不同的项目。
在以下使用场景说明中,客户项目是 Cloud Data Fusion 实例运行且 Dataproc 项目 是 Dataproc 集群的启动位置。
租户项目 VPC 和实例
| 基准 | 使用场景 |
|---|---|
在前面的基准架构图中,租户项目
包含以下组件:
|
此用例无需进行额外配置。 |
客户项目
| 基准 | 使用场景 |
|---|---|
| 您可以在 Google Cloud 项目中部署和运行流水线。 默认情况下,Dataproc 集群会 使用 Cloud Storage 项目。 | 在此使用场景中,您管理两个项目。在本页中,客户项目是指 Cloud Data Fusion 实例的运行位置。 。Dataproc 项目是指 Dataproc 集群的启动位置。 |
客户 VPC
| 基准 | 使用场景 |
|---|---|
从您(客户)的角度来看,Cloud Data Fusion 在逻辑上位于客户 VPC 中。 要点总结: 您可以 (位于项目的“VPC 网络”页面中)。 |
此用例无需进行额外配置。 |
Cloud Data Fusion 子网
| 基准 | 使用场景 |
|---|---|
从您(客户)的角度来看,Cloud Data Fusion 在逻辑上位于此子网中。 要点: 此子网的区域相同 作为 Cloud Data Fusion 实例在租户中的位置 项目。 |
此用例无需进行额外配置。 |
Dataproc 子网
| 基准 | 使用场景 |
|---|---|
启动 Dataproc 集群时所在的子网 您可以运行流水线 重点小结:
|
这是在您运行流水线时启动 Dataproc 集群的新子网。 重点小结:
|
来源和接收器
| 基准 | 使用场景 |
|---|---|
提取数据的来源和加载数据的接收器; 例如 BigQuery 来源和接收器。 要点总结:
|
本页面上针对具体用例的访问权限控制配置适用于 BigQuery 源和接收器。 |
Cloud Storage
| 基准 | 使用场景 |
|---|---|
客户项目中有助于传输文件的存储桶 如何在 Cloud Data Fusion 和 Dataproc 之间提供支持。 重点小结:
|
此用例无需进行额外配置。 |
来源和接收器使用的临时存储桶
| 基准 | 使用场景 |
|---|---|
插件为来源和接收器创建的临时存储分区 例如由 BigQuery 接收器插件启动的加载作业。 要点总结:
|
对于此使用情形,存储桶可以在任何项目中创建。 |
作为插件数据来源或接收器的存储分区
| 基准 | 使用场景 |
|---|---|
| 客户存储桶,您可以在插件(例如 Cloud Storage 插件和 FTP 到 Cloud Storage 插件)的配置中指定这些存储桶。 | 此用例无需进行额外配置。 |
IAM:Cloud Data Fusion API Service Agent
| 基准 | 使用场景 |
|---|---|
启用 Cloud Data Fusion API 后,系统会自动向 Cloud Data Fusion 服务账号(主要服务代理)授予 Cloud Data Fusion API Service Agent 角色 ( 要点总结:
|
对于此用例,请向 Dataproc 项目中的服务账号授予 Cloud Data Fusion API Service Agent 角色。然后,在该项目中授予以下角色:
|
IAM:Dataproc 服务账号
| 基准 | 使用场景 |
|---|---|
用于在 Dataproc 集群中将流水线作为作业运行的服务账号。默认情况下,它是 Compute Engine 服务账号。 可选:在基准配置中,您可以更改默认值 从同一项目迁移到另一个服务账号。授权 为新服务账号授予以下 IAM 角色:
|
此使用情形示例假定您使用的是 Dataproc 项目的默认 Compute Engine 服务账号 ( 向 Dataproc 项目中的默认 Compute Engine 服务账号授予以下角色。
向 Dataproc 项目的默认 Compute Engine 服务账号中的 Cloud Data Fusion 服务账号授予 Service Account User 角色。此操作必须在 Dataproc 项目中执行。 添加 Compute Engine 服务账号的默认 Dataproc 项目关联到 Cloud Data Fusion 项目。 此外,还应授予以下角色:
|
API
| 基准 | 使用场景 |
|---|---|
启用 Cloud Data Fusion API 后,将使用以下 API
也会启用有关这些 API 的详细信息,请参阅
API 和服务页面
启用 Cloud Data Fusion API 后,系统会自动将以下服务账号添加到您的项目中:
|
对于此用例,请在
包含 Dataproc 项目:
|
加密密钥
| 基准 | 使用场景 |
|---|---|
在基准配置中,加密密钥可以是 Google 管理的加密密钥或 CMEK 重点小结: 如果您使用 CMEK,基准配置需要满足以下要求:
根据流水线中使用的服务(例如 BigQuery 或 Cloud Storage),您还必须向服务账号授予 Cloud KMS CryptoKey Encrypter/Decrypter 角色:
|
如果您不使用 CMEK,则无需针对此用例进行任何其他更改。 如果您使用 CMEK,Cloud KMS CryptoKey Encrypter/Decrypter 角色必须 在密钥级别为以下服务账号提供 创建它的位置:
根据流水线中使用的服务(例如 BigQuery 或 Cloud Storage),您还必须在密钥级别向其他服务账号授予 Cloud KMS CryptoKey Encrypter/Decrypter 角色。例如:
|
完成这些特定于用例的配置后,您的数据流水线就可以 另一个项目中的集群开始运行。
后续步骤
- 详细了解 Cloud Data Fusion 中的网络。
- 参阅 IAM 基本和预定义角色参考文档。