Auf dieser Seite wird beschrieben, wie Sie die Zugriffssteuerung verwalten, wenn Sie eine Pipeline bereitstellen und ausführen, die Dataproc-Cluster in einem anderen Projekt verwendet. Google Cloud
Szenario
Wenn eine Cloud Data Fusion-Instanz in einemGoogle Cloud -Projekt gestartet wird, werden standardmäßig Pipelines mithilfe von Dataproc-Clustern im selben Projekt bereitgestellt und ausgeführt. Möglicherweise müssen Sie in Ihrer Organisation jedoch Cluster in einem anderen Projekt verwenden. Für diesen Anwendungsfall müssen Sie den Zugriff zwischen den Projekten verwalten. Auf der folgenden Seite wird beschrieben, wie Sie die Baseline (Standardkonfigurationen) ändern und die entsprechenden Zugriffssteuerungen anwenden.
Hinweis
Für die Lösungen in diesem Anwendungsfall ist der folgende Kontext erforderlich:
- Grundlegende Kenntnisse der Cloud Data Fusion-Konzepte
- Vertrautheit mit der Identitäts- und Zugriffsverwaltung (Identity and Access Management, IAM) für Cloud Data Fusion
- Vertrautheit mit Cloud Data Fusion-Netzwerken
Annahmen und Umfang
Dieser Anwendungsfall hat folgende Anforderungen:
- Eine private Cloud Data Fusion-Instanz. Aus Sicherheitsgründen kann eine Organisation verlangen, dass Sie diese Art von Instanz verwenden.
- Eine BigQuery-Quelle und -Senke.
- Zugriffssteuerung mit IAM, keine rollenbasierte Zugriffssteuerung (Role-Based Access Control, RBAC).
Lösung
Bei dieser Lösung werden die Architektur und Konfiguration für den Referenzwert und den Anwendungsfall verglichen.
Architektur
In den folgenden Diagrammen wird die Projektarchitektur zum Erstellen einer Cloud Data Fusion-Instanz und zum Ausführen von Pipelines verglichen, wenn Sie Cluster im selben Projekt (Baseline) und in einem anderen Projekt über die VPC des Mandantenprojekts verwenden.
Referenzarchitektur
Dieses Diagramm zeigt die Baseline-Architektur der Projekte:
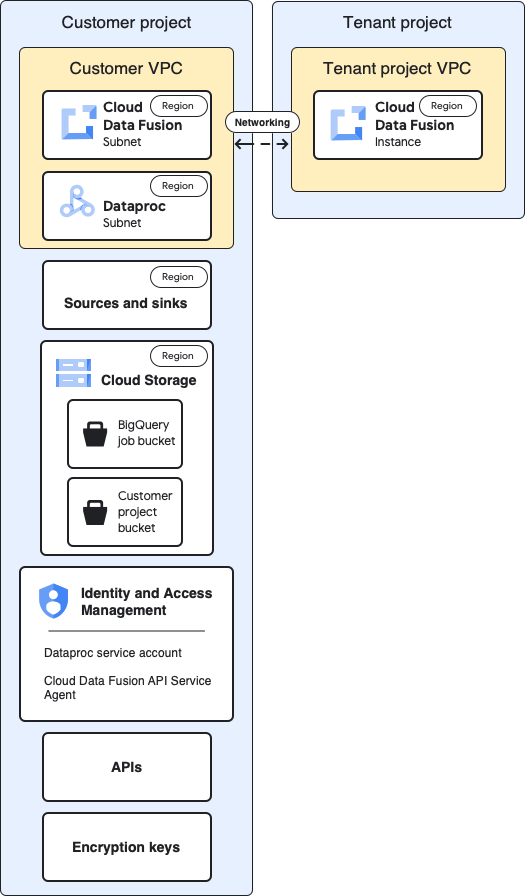
Für die Baseline-Konfiguration erstellen Sie eine private Cloud Data Fusion-Instanz und führen eine Pipeline ohne zusätzliche Anpassungen aus:
- Sie verwenden eines der integrierten Compute-Profile.
- Quell- und Senkenobjekt befinden sich im selben Projekt wie die Instanz
- Keinen der Dienstkonten wurden zusätzliche Rollen zugewiesen.
Weitere Informationen zu Mandanten- und Kundenprojekten finden Sie unter Netzwerk.
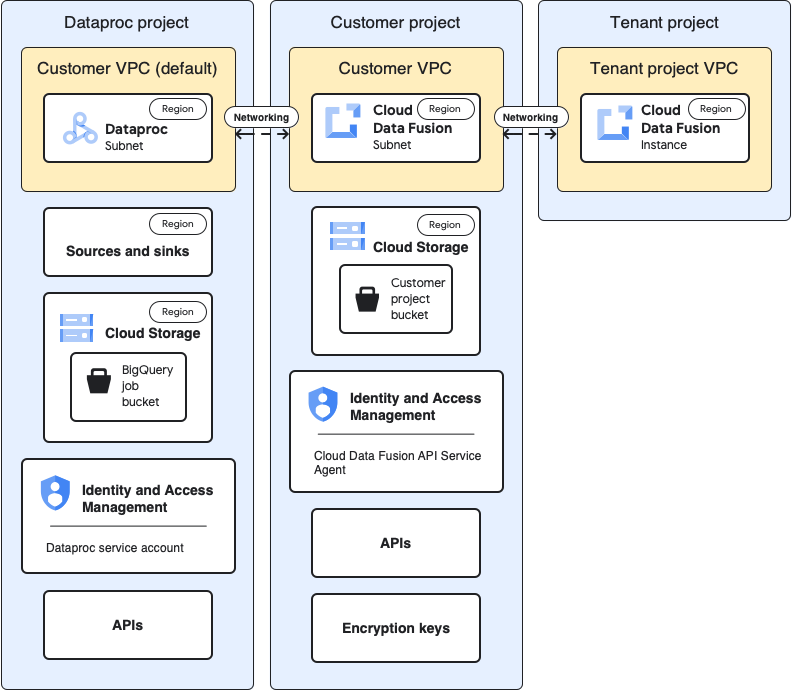
Anwendungsfallarchitektur
Dieses Diagramm zeigt die Projektarchitektur, wenn Sie Cluster in einem anderen Projekt verwenden:
Konfigurationen
In den folgenden Abschnitten werden die Baseline-Konfigurationen mit den nutzungsspezifischen Konfigurationen für die Verwendung von Dataproc-Clustern in einem anderen Projekt über die standardmäßige VPC des Mieterprojekts verglichen.
In den folgenden Anwendungsfallbeschreibungen wird die Cloud Data Fusion-Instanz im Kundenprojekt ausgeführt und der Dataproc-Cluster wird im Dataproc-Projekt gestartet.
VPC und Instanz des Mandantenprojekts
| Referenz | Anwendungsfall |
|---|---|
Im vorherigen Diagramm der Baseline-Architektur enthält das Mandantenprojekt die folgenden Komponenten:
|
Für diesen Anwendungsfall ist keine zusätzliche Konfiguration erforderlich. |
Kundenprojekt
| Referenz | Anwendungsfall |
|---|---|
| In Ihrem Google Cloud -Projekt werden Pipelines bereitgestellt und ausgeführt. Standardmäßig werden die Dataproc-Cluster in diesem Projekt gestartet, wenn Sie Ihre Pipelines ausführen. | In diesem Anwendungsfall verwalten Sie zwei Projekte. Auf dieser Seite bezieht sich das Kundenprojekt auf den Ort, an dem die Cloud Data Fusion-Instanz ausgeführt wird. Das Dataproc-Projekt gibt an, wo die Dataproc-Cluster gestartet werden. |
Kunden-VPC
| Referenz | Anwendungsfall |
|---|---|
Aus Ihrer Sicht (der des Kunden) befindet sich Cloud Data Fusion logisch im VPC des Kunden. Zusammenfassung :Die Details zum VPC des Kunden finden Sie auf der Seite „VPC-Netzwerke“ Ihres Projekts. |
Für diesen Anwendungsfall ist keine zusätzliche Konfiguration erforderlich. |
Cloud Data Fusion-Subnetz
| Referenz | Anwendungsfall |
|---|---|
Aus Ihrer Sicht (der des Kunden) befindet sich Cloud Data Fusion logisch in diesem Subnetz. Zusammenfassung :Die Region dieses Subnetzes stimmt mit dem Speicherort der Cloud Data Fusion-Instanz im Mandantenprojekt überein. |
Für diesen Anwendungsfall ist keine zusätzliche Konfiguration erforderlich. |
Dataproc-Subnetz
| Referenz | Anwendungsfall |
|---|---|
Das Subnetz, in dem Dataproc-Cluster gestartet werden, wenn Sie eine Pipeline ausführen. Zusammenfassung:
|
Dies ist ein neues Subnetz, in dem Dataproc-Cluster gestartet werden, wenn Sie eine Pipeline ausführen. Zusammenfassung:
|
Quellen und Senken
| Referenz | Anwendungsfall |
|---|---|
Die Quellen, aus denen Daten extrahiert werden, und die Senken, in die Daten geladen werden, z. B. BigQuery-Quellen und -Senken. Hauptpunkt:
|
Die nutzungsspezifischen Zugriffssteuerungskonfigurationen auf dieser Seite gelten für BigQuery-Quellen und -Ziele. |
Cloud Storage
| Referenz | Anwendungsfall |
|---|---|
Der Speicher-Bucket im Kundenprojekt, der die Übertragung von Dateien zwischen Cloud Data Fusion und Dataproc unterstützt. Zusammenfassung:
|
Für diesen Anwendungsfall ist keine zusätzliche Konfiguration erforderlich. |
Temporäre Buckets, die von Quelle und Senke verwendet werden
| Referenz | Anwendungsfall |
|---|---|
Die temporären Buckets, die von Plug-ins für Ihre Quellen und Senken erstellt werden, z. B. die Ladejobs, die vom BigQuery-Sink-Plug-in initiiert werden. Zusammenfassung:
|
Für diesen Anwendungsfall kann der Bucket in einem beliebigen Projekt erstellt werden. |
Buckets, die Datenquellen oder Datensenken für Plug-ins sind
| Referenz | Anwendungsfall |
|---|---|
| Kunden-Buckets, die Sie in den Konfigurationen für Plug-ins angeben, z. B. das Cloud Storage-Plug-in und das FTP-zu-Cloud Storage-Plug-in. | Für diesen Anwendungsfall ist keine zusätzliche Konfiguration erforderlich. |
IAM: Cloud Data Fusion API-Dienst-Agent
| Referenz | Anwendungsfall |
|---|---|
Wenn die Cloud Data Fusion API aktiviert ist, wird die Rolle Cloud Data Fusion API-Dienst-Agent ( Zusammenfassung:
|
Weisen Sie für diesen Anwendungsfall dem Dienstkonto im Dataproc-Projekt die Rolle „Cloud Data Fusion API-Dienst-Agent“ zu. Weisen Sie dann die folgenden Rollen in diesem Projekt zu:
|
IAM: Dataproc-Dienstkonto
| Referenz | Anwendungsfall |
|---|---|
Das Dienstkonto, mit dem die Pipeline als Job innerhalb des Dataproc-Clusters ausgeführt wird. Standardmäßig ist dies das Compute Engine-Dienstkonto. Optional: In der Baseline-Konfiguration können Sie das Standarddienstkonto in ein anderes Dienstkonto aus demselben Projekt ändern. Weisen Sie dem neuen Dienstkonto die folgenden IAM-Rollen zu:
|
In diesem Anwendungsfall wird davon ausgegangen, dass Sie das Standarddienstkonto der Compute Engine ( Weisen Sie dem Standard-Compute Engine-Dienstkonto im Dataproc-Projekt die folgenden Rollen zu.
Weisen Sie dem Cloud Data Fusion-Dienstkonto die Rolle „Dienstkontonutzer“ für das standardmäßige Compute Engine-Dienstkonto des Dataproc-Projekts zu. Diese Aktion muss im Dataproc-Projekt ausgeführt werden. Fügen Sie dem Cloud Data Fusion-Projekt das standardmäßige Compute Engine-Dienstkonto des Dataproc-Projekts hinzu. Weisen Sie außerdem die folgenden Rollen zu:
|
APIs
| Referenz | Anwendungsfall |
|---|---|
Wenn Sie die Cloud Data Fusion API aktivieren, werden auch die folgenden APIs aktiviert. Weitere Informationen zu diesen APIs finden Sie in Ihrem Projekt auf der Seite „APIs & Dienste“.
Wenn Sie die Cloud Data Fusion API aktivieren, werden Ihrem Projekt automatisch die folgenden Dienstkonten hinzugefügt:
|
Aktivieren Sie für diesen Anwendungsfall die folgenden APIs im Projekt, das das Dataproc-Projekt enthält:
|
Verschlüsselungsschlüssel
| Referenz | Anwendungsfall |
|---|---|
In der Baseline-Konfiguration können Verschlüsselungsschlüssel von Google verwaltet oder CMEK sein. Zusammenfassung: Wenn Sie CMEK verwenden, sind für Ihre Baseline-Konfiguration folgende Voraussetzungen erforderlich:
Je nach den in Ihrer Pipeline verwendeten Diensten, z. B. BigQuery oder Cloud Storage, müssen Dienstkonten auch die Rolle „Cloud KMS CryptoKey-Verschlüsseler/Entschlüsseler“ gewährt werden:
|
Wenn Sie CMEK nicht verwenden, sind für diesen Anwendungsfall keine weiteren Änderungen erforderlich. Wenn Sie CMEK verwenden, muss dem folgenden Dienstkonto auf Schlüsselebene im Projekt, in dem es erstellt wird, die Rolle „Cloud KMS CryptoKey-Verschlüsseler/Entschlüsseler“ zugewiesen werden:
Je nach den in Ihrer Pipeline verwendeten Diensten, z. B. BigQuery oder Cloud Storage, muss auch anderen Dienstkonten die Rolle „Cloud KMS CryptoKey-Verschlüsseler/Entschlüsseler“ auf Schlüsselebene zugewiesen werden. Beispiel:
|
Nachdem Sie diese nutzungsfallspezifischen Konfigurationen vorgenommen haben, kann Ihre Datenpipeline in Clustern in einem anderen Projekt ausgeführt werden.
Nächste Schritte
- Weitere Informationen zu Netzwerken in Cloud Data Fusion
- Weitere Informationen finden Sie in der Referenz zu einfachen und vordefinierten IAM-Rollen.