의견 보내기
사용 사례: 다른 프로젝트의 Dataproc 클러스터에 대한 액세스 제어
이 페이지에서는 다른 프로젝트에서 Dataproc 클러스터를 사용하는 파이프라인을 배포하고 실행할 때 액세스 제어를 관리하는 방법을 설명합니다. Google Cloud
시나리오
기본적으로 Cloud Data Fusion 인스턴스가Google Cloud 프로젝트에서 실행되면 동일한 프로젝트 내에서 Dataproc 클러스터를 사용하여 파이프라인을 배포하고 실행합니다. 그러나 조직에서 다른 프로젝트의 클러스터를 사용하도록 요구할 수도 있습니다. 이 사용 사례에서는 프로젝트 사이에서 액세스 권한을 관리해야 합니다. 다음 페이지에서는 기준 (기본) 구성을 변경하고 적절한 액세스 제어를 적용하는 방법을 설명합니다.
시작하기 전에
이 사용 사례의 솔루션을 이해하려면 다음 지식이 필요합니다.
가정 및 범위
이 사용 사례의 요구사항은 다음과 같습니다.
참고: 이 사용 사례에서는 소스와 싱크가 다른 VPC에 있는 네트워킹 시나리오를 보여주지 않습니다. 솔루션
이 솔루션은 기준 및 사용 사례별 아키텍처와 구성을 비교합니다.
아키텍처
다음 다이어그램은 테넌트 프로젝트 VPC를 통해 동일한 프로젝트(기준) 및 다른 프로젝트에서 클러스터를 사용할 때 Cloud Data Fusion 인스턴스를 만들고 파이프라인을 실행하기 위한 프로젝트 아키텍처를 비교합니다.
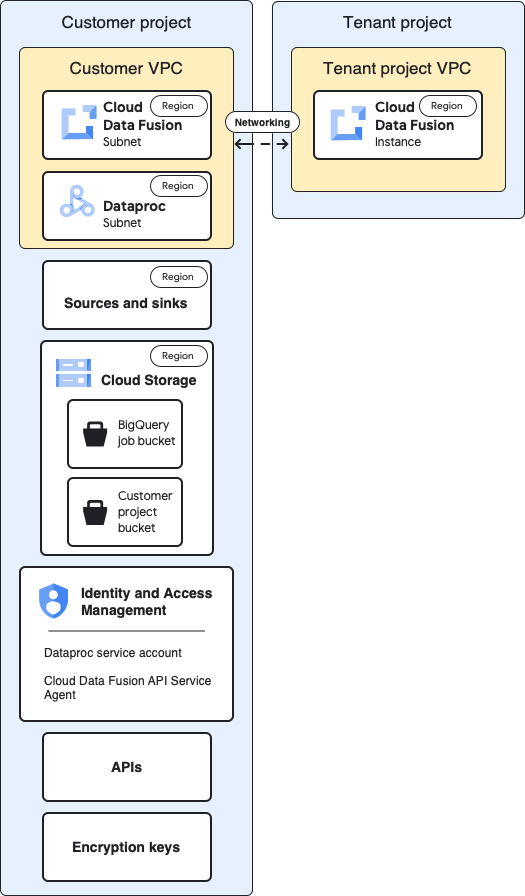
기준 아키텍처
다음 다이어그램에서는 프로젝트의 기준 아키텍처를 보여줍니다.
기준 구성의 경우 비공개 Cloud Data Fusion 인스턴스를 만들고 추가 맞춤설정 없이 파이프라인을 실행합니다.
기본 제공 컴퓨팅 프로필 중 하나를 사용합니다.
소스와 싱크가 인스턴스와 동일한 프로젝트에 있음
서비스 계정에 부여된 추가 역할 없음
테넌트 및 고객 프로젝트에 대한 자세한 내용은 네트워킹 을 참조하세요.
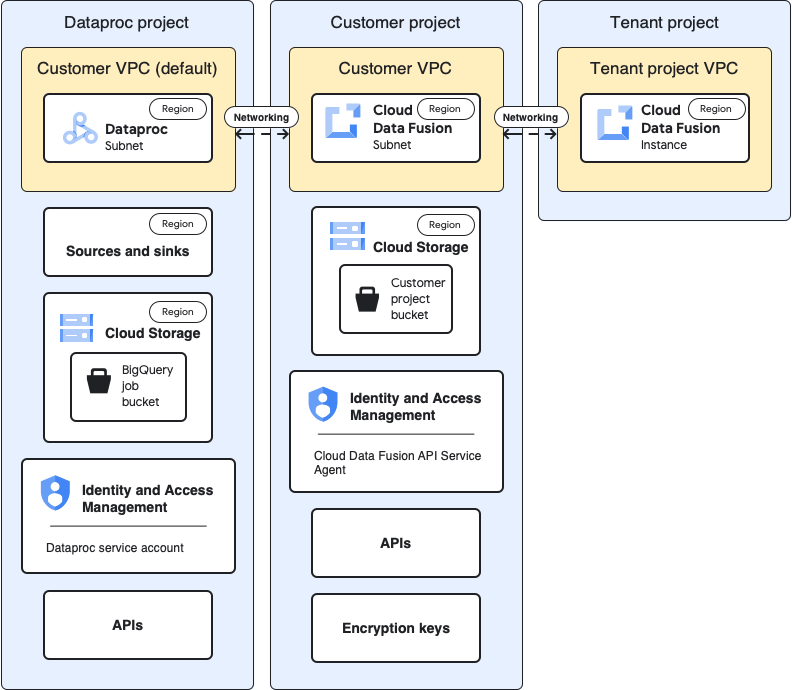
사용 사례 아키텍처
다음 다이어그램은 다른 프로젝트에서 클러스터를 사용하는 경우의 프로젝트 아키텍처를 보여줍니다.
구성
다음 섹션에서는 기준 구성을 기본 테넌트 프로젝트 VPC를 통해 다른 프로젝트의 Dataproc 클러스터를 사용하기 위한 사용 사례별 구성과 비교합니다.
다음 사용 사례 설명에서 고객 프로젝트 는 Cloud Data Fusion 인스턴스가 실행되는 곳이고 Dataproc 프로젝트 는 Dataproc 클러스터가 시작되는 위치입니다.
참고: 이 사용 사례 구성에서는 Dataproc 작업을 실행하기 위해 Dataproc 프로젝트에서 기본 Compute Engine 서비스 계정을 사용한다고 가정합니다. 테넌트 프로젝트 VPC 및 인스턴스
기준
사용 사례
앞선 기준 아키텍처 다이어그램에서는 테넌트 프로젝트에 다음 구성요소가 포함됩니다.
자동으로 생성되는 기본 VPC
Cloud Data Fusion 인스턴스의 실제 배포
이 사용 사례에는 추가 구성이 필요하지 않습니다.
고객 프로젝트
기준
사용 사례
Google Cloud 프로젝트는 파이프라인을 배포하고 실행하는 위치입니다.
기본적으로 파이프라인을 실행하면 이 프로젝트에서 Dataproc 클러스터가 실행됩니다.
이 사용 사례에서는 두 프로젝트를 관리합니다. 이 페이지에서 고객 프로젝트 는 Cloud Data Fusion 인스턴스가 실행되는 위치를 나타냅니다.Dataproc 프로젝트 는 Dataproc 클러스터가 실행되는 위치를 나타냅니다.
고객 VPC
기준
사용 사례
고객 관점에서 고객 VPC는 Cloud Data Fusion이 논리적으로 위치하는 곳입니다.
핵심 내용:
VPC 네트워크로 이동
이 사용 사례에는 추가 구성이 필요하지 않습니다.
Cloud Data Fusion 서브넷
기준
사용 사례
고객 관점에서 이 서브넷은 Cloud Data Fusion이 논리적으로 위치하는 곳입니다.
핵심 요약: 이 사용 사례에는 추가 구성이 필요하지 않습니다.
Dataproc 서브넷
기준
사용 사례
파이프라인을 실행할 때 Dataproc 클러스터가 실행되는 서브넷입니다.
핵심 내용:
이 기준 구성에서는 Dataproc이 Cloud Data Fusion 인스턴스와 동일한 서브넷에서 실행됩니다.
Cloud Data Fusion은 Cloud Data Fusion의 인스턴스와 서브넷 모두와 동일한 리전에서 서브넷을 찾습니다. 이 리전에 서브넷이 하나만 있으면 서브넷은 같습니다.
Dataproc 서브넷에 비공개 Google 액세스가 있어야 합니다.
파이프라인을 실행할 때 Dataproc 클러스터가 실행되는 새 서브넷입니다.
핵심 내용:
이 새 서브넷에서는 비공개 Google 액세스를 사용 으로 설정합니다.
Dataproc 서브넷은 Cloud Data Fusion 인스턴스와 동일한 위치에 있지 않아도 됩니다.
소스 및 싱크
기준
사용 사례
데이터가 추출되는 소스 및 데이터가 로드되는 싱크(예: BigQuery 소스 및 싱크).
핵심 내용:
데이터를 가져오고 로드하는 작업은 데이터 세트와 동일한 위치에서 처리되어야 합니다. 그렇지 않으면 오류가 발생합니다.
이 페이지의 사용 사례별 액세스 제어 구성은 BigQuery 소스 및 싱크용입니다.
Cloud Storage
기준
사용 사례
Cloud Data Fusion과 Dataproc 간에 파일을 전송하는 데 도움이 되는 고객 프로젝트의 스토리지 버킷입니다.
핵심 내용:
Cloud Data Fusion 웹 인터페이스를 통해 임시 클러스터의 Compute 프로필 설정에서 이 버킷을 지정할 수 있습니다.
일괄 및 실시간 파이프라인 또는 복제 작업의 경우: 컴퓨팅 프로필에 버킷을 지정하지 않으면 Cloud Data Fusion이 동일한 목적으로 인스턴스와 동일한 프로젝트에 버킷을 만듭니다.
정적 Dataproc 클러스터의 경우에도 이 기준 구성에서는 버킷이 Cloud Data Fusion에서 생성되며 Dataproc 스테이징 및 임시 버킷과 다릅니다.
Cloud Data Fusion API 서비스 에이전트 에는 Cloud Data Fusion 인스턴스가 포함된 프로젝트에서 이 버킷을 만들 수 있는 권한이 기본 제공됩니다.
이 사용 사례에는 추가 구성이 필요하지 않습니다.
소스 및 싱크에서 사용하는 임시 버킷
기준
사용 사례
소스 및 싱크용 플러그인에서 만든 임시 버킷입니다(예: BigQuery Sink 플러그인에서 시작된 로드 작업).
핵심 내용:
소스 및 싱크 플러그인 속성을 구성할 때 이러한 버킷을 정의할 수 있습니다.
버킷을 정의하지 않으면 버킷은 Dataproc이 실행되는 같은 프로젝트에 생성됩니다.
데이터 세트가 멀티 리전 데이터 세트인 경우 버킷이 동일한 범위에 생성됩니다.
플러그인 구성에서 버킷을 정의하는 경우 버킷 리전이 데이터 세트 리전과 일치해야 합니다.
플러그인 구성에서 버킷을 정의하지 않은 경우 파이프라인이 완료되면 자동으로 생성된 버킷이 삭제됩니다.
이 사용 사례의 경우 버킷은 모든 프로젝트에서 생성될 수 있습니다.
플러그인의 데이터 소스 또는 싱크인 버킷
기준
사용 사례
Cloud Storage 플러그인 및 FTP to Cloud Storage 플러그인과 같은 플러그인 구성에 지정하는 고객 버킷입니다.
이 사용 사례에는 추가 구성이 필요하지 않습니다.
IAM: Cloud Data Fusion API 서비스 에이전트
기준
사용 사례
Cloud Data Fusion API가 사용 설정되면 Cloud Data Fusion API 서비스 에이전트 역할 (roles/datafusion.serviceAgent)이
Cloud Data Fusion 서비스 계정 (기본 서비스 에이전트)에 자동으로 부여됩니다.
핵심 내용:
이 역할에는 BigQuery 및 Dataproc와 같이 인스턴스와 동일한 프로젝트의 서비스에 대한 권한이 포함됩니다. 지원되는 모든 서비스는 역할 세부정보 를 참조하세요.
Cloud Data Fusion 서비스 계정에서는 다음을 수행합니다.
다른 서비스(예: 설계 시 Cloud Storage, BigQuery, Datastream과 통신)와의 데이터 영역(파이프라인 설계 및 실행) 통신을 수행합니다.
Dataproc 클러스터를 프로비저닝합니다.
Oracle 소스에서 복제하는 경우 작업이 실행되는 프로젝트의 Datastream 관리자 및 스토리지 관리자 역할이 이 서비스 계정에도 부여되어야 합니다. 이 페이지에서는 복제 사용 사례를 다루지 않습니다.
이 사용 사례의 경우 Dataproc 프로젝트의 서비스 계정에 Cloud Data Fusion API 서비스 에이전트 역할을 부여합니다. 그런 다음 해당 프로젝트의 다음 역할을 부여합니다.
Compute 네트워크 사용자 역할
Dataproc 편집자 역할
IAM: Dataproc 서비스 계정
기준
사용 사례
파이프라인을 Dataproc 클러스터 내 작업으로 실행하는 데 사용되는 서비스 계정입니다. 기본적으로 Compute Engine 서비스 계정입니다.
선택사항: 기준 구성에서 기본 서비스 계정을 같은 프로젝트의 다른 서비스 계정으로 변경할 수 있습니다. 새 서비스 계정에 다음 IAM 역할을 부여합니다.
Cloud Data Fusion 실행자 역할. 이 역할을 사용하면 Dataproc에서 Cloud Data Fusion API와 통신할 수 있습니다.
Dataproc 작업자 역할 이 역할을 통해 Dataproc 클러스터에서 작업을 실행할 수 있습니다.
핵심 내용:
서비스 API 에이전트에서 Dataproc 클러스터를 실행하는 데 사용할 수 있도록 새 서비스의 API 에이전트 서비스 계정에 Dataproc 서비스 계정에 대한 서비스 계정 사용자 역할을 부여해야 합니다.
이 사용 사례 예시에서는 Dataproc 프로젝트의 기본 Compute Engine 서비스 계정(PROJECT_NUMBER -compute@developer.gserviceaccount.com
Dataproc 프로젝트의 기본 Compute Engine 서비스 계정에 다음 역할을 부여합니다.
참고: Cloud Data Fusion 파이프라인을 실행하기 위해 다른 서비스 계정을 사용하려면 Dataproc 프로젝트의 해당 서비스 계정에 역할을 부여합니다.
Dataproc 작업자 역할
Dataproc이 BigQuery를 위한 임시 버킷을 만들 수 있도록 하는 스토리지 관리자 역할(또는 최소한 `storage.buckets.create` 권한)
BigQuery 작업 사용자 역할. 이 역할을 사용하면 Dataproc에서 로드 작업을 만들 수 있습니다. 작업은 기본적으로 Dataproc 프로젝트에 생성됩니다.
BigQuery 데이터 세트 편집자 역할. 이 역할을 사용하면 Dataproc에서 데이터를 로드하는 동안 데이터 세트를 만들 수 있습니다.
Dataproc 프로젝트의 기본 Compute Engine 서비스 계정에 대한 서비스 계정 사용자 역할을 Cloud Data Fusion 서비스 계정에 부여합니다. Dataproc 프로젝트에서 이 작업을 수행해야 합니다.
Dataproc 프로젝트의 기본 Compute Engine 서비스 계정을 Cloud Data Fusion 프로젝트에 추가합니다.
다음 역할도 부여합니다.
Cloud Data Fusion 소비자 버킷에서 파이프라인 작업 관련 아티팩트를 검색할 수 있는 스토리지 객체 뷰어 역할
Dataproc 클러스터가 실행되는 동안 Cloud Data Fusion과 통신할 수 있도록 하는 Cloud Data Fusion 실행자 역할입니다.
API
기준
사용 사례
Cloud Data Fusion API를 사용 설정하면 다음 API도 사용 설정됩니다. 이러한 API에 대한 자세한 내용은 프로젝트의 API 및 서비스 페이지를 참조하세요.API 및 서비스로 이동
Cloud Autoscaling API
Dataproc API
Cloud Dataproc Control API
Cloud DNS API
Cloud OS Login API
Pub/Sub API
Compute Engine API
Container Filesystem API
Container Registry API
Service Account Credentials API
Identity and Access Management API
Google Kubernetes Engine API
참고: 프로젝트에서 Cloud Resource Manager API를 수동으로 사용 설정합니다.
Cloud Data Fusion API를 사용 설정하면 다음 서비스 계정이 프로젝트에 자동으로 추가됩니다.
Google API 서비스 에이전트
Compute Engine 서비스 에이전트
Kubernetes Engine 서비스 에이전트
Google Container Registry 서비스 에이전트
Google Cloud Dataproc 서비스 에이전트
Cloud KMS 서비스 에이전트
Cloud Pub/Sub 서비스 계정
이 사용 사례의 경우 Dataproc 프로젝트가 포함된 프로젝트에서 다음 API를 사용 설정합니다.
Compute Engine API
Dataproc API(이 프로젝트에 이미 사용 설정되어 있을 가능성이 높음) Dataproc API를 사용 설정하면 Dataproc Control API가 자동으로 사용 설정됩니다.
Resource Manager API.
암호화 키
기준
사용 사례
기준 구성에서 암호화 키는 Google 관리 암호화 키나 CMEK 일 수 있습니다.
핵심 내용: CMEK를 사용하는 경우 기준 구성에 다음이 필요합니다.
키는 리전 키이고 Cloud Data Fusion 인스턴스와 동일한 리전에서 생성되어야 합니다.
키가 생성된 프로젝트에서 키 수준 ( Google Cloud 콘솔의 IAM 페이지가 아님)에서 다음 서비스 계정에 Cloud KMS CryptoKey 암호화/복호화 역할을 부여합니다.
Cloud Data Fusion API 서비스 계정
기본적으로 Compute Engine 서비스 에이전트(service-PROJECT_NUMBER @compute-system.iam.gserviceaccount.com)인 Dataproc 서비스 계정
Google Cloud Dataproc 서비스 에이전트(service-PROJECT_NUMBER @dataproc-accounts.iam.gserviceaccount.com)
Cloud Storage 서비스 에이전트(service-PROJECT_NUMBER @gs-project-accounts.iam.gserviceaccount.com)
BigQuery 또는 Cloud Storage와 같이 파이프라인에서 사용되는 서비스에 따라 서비스 계정에 Cloud KMS CryptoKey 암호화/복호화 역할도 부여해야 합니다.
BigQuery 서비스 계정(bq-PROJECT_NUMBER @bigquery-encryption.iam.gserviceaccount.com)
Pub/Sub 서비스 계정(service-PROJECT_NUMBER @gcp-sa-pubsub.iam.gserviceaccount.com)
Spanner 서비스 계정(service-PROJECT_NUMBER @gcp-sa-spanner.iam.gserviceaccount.com)
CMEK를 사용하지 않는 경우 이 사용 사례에 추가 변경사항이 필요하지 않습니다.
CMEK를 사용하는 경우 키가 생성된 프로젝트의 키 수준에서 다음 서비스 계정에 Cloud KMS CryptoKey 암호화/복호화 역할을 부여해야 합니다.
Cloud Storage 서비스 에이전트(service-PROJECT_NUMBER @gs-project-accounts.iam.gserviceaccount.com)
BigQuery 또는 Cloud Storage와 같이 파이프라인에서 사용되는 서비스에 따라 키 수준에서 다른 서비스 계정에 Cloud KMS CryptoKey 암호화/복호화 역할도 부여해야 합니다. 예를 들면 다음과 같습니다.
BigQuery 서비스 계정(bq-PROJECT_NUMBER @bigquery-encryption.iam.gserviceaccount.com)
Pub/Sub 서비스 계정(service-PROJECT_NUMBER @gcp-sa-pubsub.iam.gserviceaccount.com)
Spanner 서비스 계정(service-PROJECT_NUMBER @gcp-sa-spanner.iam.gserviceaccount.com)
이러한 사용 사례별 구성을 완료하면 데이터 파이프라인이 다른 프로젝트의 클러스터에서 실행될 수 있습니다.
다음 단계
의견 보내기
달리 명시되지 않는 한 이 페이지의 콘텐츠에는 Creative Commons Attribution 4.0 라이선스 에 따라 라이선스가 부여되며, 코드 샘플에는 Apache 2.0 라이선스 에 따라 라이선스가 부여됩니다. 자세한 내용은 Google Developers 사이트 정책 을 참조하세요. 자바는 Oracle 및/또는 Oracle 계열사의 등록 상표입니다.
최종 업데이트: 2025-10-19(UTC)
의견을 전달하고 싶나요?
[[["이해하기 쉬움","easyToUnderstand","thumb-up"],["문제가 해결됨","solvedMyProblem","thumb-up"],["기타","otherUp","thumb-up"]],[["이해하기 어려움","hardToUnderstand","thumb-down"],["잘못된 정보 또는 샘플 코드","incorrectInformationOrSampleCode","thumb-down"],["필요한 정보/샘플이 없음","missingTheInformationSamplesINeed","thumb-down"],["번역 문제","translationIssue","thumb-down"],["기타","otherDown","thumb-down"]],["최종 업데이트: 2025-10-19(UTC)"],[],[]]