Halaman ini menjelaskan cara mengelola kontrol akses saat Anda men-deploy dan menjalankan pipeline yang menggunakan cluster Dataproc di project Google Cloud lain.
Skenario
Secara default, saat instance Cloud Data Fusion diluncurkan di projectGoogle Cloud , instance tersebut akan men-deploy dan menjalankan pipeline menggunakan cluster Dataproc dalam project yang sama. Namun, organisasi Anda mungkin mengharuskan Anda menggunakan cluster di project lain. Untuk kasus penggunaan ini, Anda harus mengelola akses antar-project. Halaman berikut menjelaskan cara mengubah konfigurasi dasar pengukuran (default) dan menerapkan kontrol akses yang sesuai.
Sebelum memulai
Untuk memahami solusi dalam kasus penggunaan ini, Anda memerlukan konteks berikut:
- Memahami konsep Cloud Data Fusion dasar
- Memahami Identity and Access Management (IAM) untuk Cloud Data Fusion
- Memahami jaringan Cloud Data Fusion
Asumsi dan cakupan
Kasus penggunaan ini memiliki persyaratan berikut:
- Instance Cloud Data Fusion pribadi. Demi alasan keamanan, organisasi mungkin mewajibkan Anda menggunakan jenis instance ini.
- Sumber dan sink BigQuery.
- Kontrol akses dengan IAM, bukan kontrol akses berbasis peran (RBAC).
Solusi
Solusi ini membandingkan konfigurasi dan arsitektur dasar pengukuran serta kasus penggunaan tertentu.
Arsitektur
Diagram berikut membandingkan arsitektur project untuk membuat instance Cloud Data Fusion dan menjalankan pipeline saat Anda menggunakan cluster dalam project yang sama (dasar pengukuran) dan dalam project yang berbeda melalui VPC project tenant.
Arsitektur dasar pengukuran
Diagram ini menunjukkan arsitektur dasar pengukuran project:
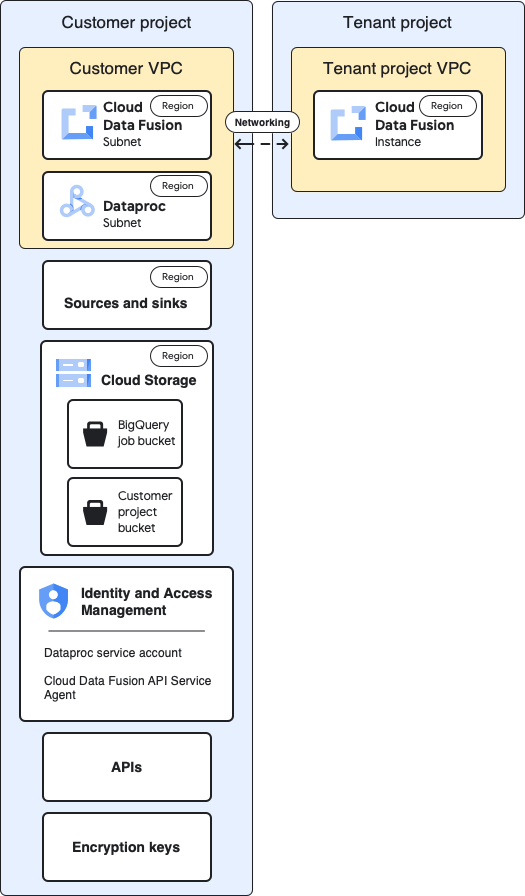
Untuk konfigurasi dasar pengukuran, Anda membuat instance Cloud Data Fusion pribadi dan menjalankan pipeline tanpa penyesuaian tambahan:
- Anda menggunakan salah satu profil komputasi bawaan
- Sumber dan sink berada dalam project yang sama dengan instance
- Tidak ada peran tambahan yang diberikan ke akun layanan mana pun
Untuk informasi selengkapnya tentang project pelanggan dan tenant, lihat Jaringan.
Arsitektur kasus penggunaan
Diagram ini menunjukkan arsitektur project saat Anda menggunakan cluster dalam project lain:
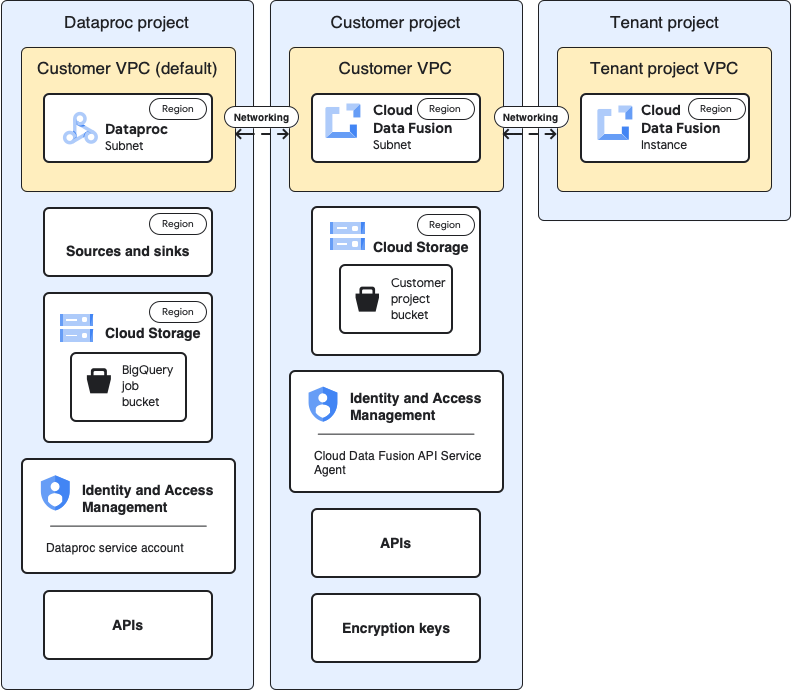
Konfigurasi
Bagian berikut membandingkan konfigurasi dasar pengukuran dengan konfigurasi khusus kasus penggunaan untuk menggunakan cluster Dataproc di project lain melalui VPC project tenant default.
Dalam deskripsi kasus penggunaan berikut, project pelanggan adalah tempat instance Cloud Data Fusion berjalan dan project Dataproc adalah tempat cluster Dataproc diluncurkan.
VPC dan instance project tenant
| Dasar pengukuran | Kasus penggunaan |
|---|---|
Dalam diagram arsitektur dasar pengukuran sebelumnya, project tenant
berisi komponen berikut:
|
Tidak diperlukan konfigurasi tambahan untuk kasus penggunaan ini. |
Project pelanggan
| Dasar pengukuran | Kasus penggunaan |
|---|---|
| Project Google Cloud adalah tempat Anda men-deploy dan menjalankan pipeline. Secara default, cluster Dataproc diluncurkan di project ini saat Anda menjalankan pipeline. | Dalam kasus penggunaan ini, Anda mengelola dua project. Di halaman ini, project pelanggan mengacu pada tempat instance Cloud Data Fusion
berjalan. Project Dataproc mengacu pada tempat peluncuran cluster Dataproc. |
VPC Pelanggan
| Dasar pengukuran | Kasus penggunaan |
|---|---|
Dari perspektif Anda (pelanggan), VPC pelanggan adalah tempat Cloud Data Fusion berada secara logis. Poin penting: Anda dapat menemukan detail VPC Pelanggan di halaman jaringan VPC project Anda. |
Tidak diperlukan konfigurasi tambahan untuk kasus penggunaan ini. |
Subnet Cloud Data Fusion
| Dasar pengukuran | Kasus penggunaan |
|---|---|
Dari perspektif Anda (pelanggan), subnet ini adalah tempat Cloud Data Fusion berada secara logis. Poin penting: Region subnet ini sama dengan lokasi instance Cloud Data Fusion di project tenant. |
Tidak diperlukan konfigurasi tambahan untuk kasus penggunaan ini. |
Subnet Dataproc
| Dasar pengukuran | Kasus penggunaan |
|---|---|
Subnet tempat cluster Dataproc diluncurkan saat Anda menjalankan pipeline. Poin-poin penting:
|
Ini adalah subnet baru tempat cluster Dataproc diluncurkan saat Anda menjalankan pipeline. Poin-poin penting:
|
Sumber dan sink
| Dasar pengukuran | Kasus penggunaan |
|---|---|
Sumber tempat data diekstrak dan sink tempat data dimuat, seperti sumber dan sink BigQuery. Poin penting:
|
Konfigurasi kontrol akses khusus kasus penggunaan di halaman ini ditujukan untuk sumber dan sink BigQuery. |
Cloud Storage
| Dasar pengukuran | Kasus penggunaan |
|---|---|
Bucket penyimpanan di project pelanggan yang membantu mentransfer file antara Cloud Data Fusion dan Dataproc. Poin-poin penting:
|
Tidak diperlukan konfigurasi tambahan untuk kasus penggunaan ini. |
Bucket sementara yang digunakan oleh sumber dan sink
| Dasar pengukuran | Kasus penggunaan |
|---|---|
Bucket sementara yang dibuat oleh plugin untuk sumber dan sink Anda, seperti tugas pemuatan yang dimulai oleh plugin BigQuery Sink. Poin-poin penting:
|
Untuk kasus penggunaan ini, bucket dapat dibuat di project mana pun. |
Bucket yang merupakan sumber atau sink data untuk plugin
| Dasar pengukuran | Kasus penggunaan |
|---|---|
| Bucket pelanggan, yang Anda tentukan dalam konfigurasi untuk plugin, seperti plugin Cloud Storage dan plugin FTP ke Cloud Storage. | Tidak diperlukan konfigurasi tambahan untuk kasus penggunaan ini. |
IAM: Cloud Data Fusion API Service Agent
| Dasar pengukuran | Kasus penggunaan |
|---|---|
Saat Cloud Data Fusion API diaktifkan, peran Agen Layanan Cloud Data Fusion API ( Poin-poin penting:
|
Untuk kasus penggunaan ini, berikan peran Agen Layanan Cloud Data Fusion API ke akun layanan di project Dataproc. Kemudian, berikan peran berikut di project tersebut:
|
IAM: Akun layanan Dataproc
| Dasar pengukuran | Kasus penggunaan |
|---|---|
Akun layanan yang digunakan untuk menjalankan pipeline sebagai tugas dalam cluster Dataproc. Secara default, akun layanan Compute Engine. Opsional: dalam konfigurasi dasar pengukuran, Anda dapat mengubah akun layanan default ke akun layanan lain dari project yang sama. Berikan peran IAM berikut ke akun layanan baru:
|
Contoh kasus penggunaan ini mengasumsikan bahwa Anda menggunakan akun layanan Compute Engine default ( Berikan peran berikut ke akun layanan Compute Engine default di project Dataproc.
Berikan peran Pengguna Akun Layanan ke Akun Layanan Cloud Data Fusion di akun layanan Compute Engine default project Dataproc. Tindakan ini harus dilakukan di project Dataproc. Tambahkan akun layanan Compute Engine default dari project Dataproc ke project Cloud Data Fusion. Berikan juga peran berikut:
|
API
| Dasar pengukuran | Kasus penggunaan |
|---|---|
Saat Anda mengaktifkan Cloud Data Fusion API, API berikut juga akan diaktifkan. Untuk informasi selengkapnya tentang API ini, buka halaman API & layanan di project Anda.
Saat Anda mengaktifkan Cloud Data Fusion API, akun layanan berikut akan otomatis ditambahkan ke project Anda:
|
Untuk kasus penggunaan ini, aktifkan API berikut di project yang berisi project Dataproc:
|
Kunci enkripsi
| Dasar pengukuran | Kasus penggunaan |
|---|---|
Dalam konfigurasi dasar pengukuran, kunci enkripsi dapat dikelola Google atau CMEK Poin-poin penting: Jika Anda menggunakan CMEK, konfigurasi dasar pengukuran Anda memerlukan hal berikut:
Bergantung pada layanan yang digunakan dalam pipeline Anda, seperti BigQuery atau Cloud Storage, akun layanan juga harus diberi peran Pengenkripsi/Pendekripsi CryptoKey Cloud KMS:
|
Jika Anda tidak menggunakan CMEK, tidak diperlukan perubahan tambahan untuk kasus penggunaan ini. Jika Anda menggunakan CMEK, peran Pengenkripsi/Pendekripsi CryptoKey Cloud KMS harus diberikan ke akun layanan berikut di tingkat kunci dalam project tempat akun tersebut dibuat:
Bergantung pada layanan yang digunakan dalam pipeline Anda, seperti BigQuery atau Cloud Storage, akun layanan lainnya juga harus diberi peran Pengenkripsi/Pendekripsi CryptoKey Cloud KMS di tingkat kunci. Contoh:
|
Setelah Anda membuat konfigurasi khusus kasus penggunaan ini, pipeline data Anda dapat mulai berjalan di cluster dalam project lain.
Langkah berikutnya
- Pelajari jaringan di Cloud Data Fusion lebih lanjut.
- Lihat Referensi peran dasar dan bawaan IAM.