This page describes managing access control when you deploy and run a pipeline that uses Dataproc clusters in another Google Cloud project.
Scenario
By default, when a Cloud Data Fusion instance is launched in a Google Cloud project, it deploys and runs pipelines using Dataproc clusters within the same project. However, your organization might require you to use clusters in another project. For this use case, you must manage access between the projects. The following page describes how you can change the baseline (default) configurations and apply the appropriate access controls.
Before you begin
To understand the solutions in this use case, you need the following context:
- Familiarity with basic Cloud Data Fusion concepts
- Familiarity with Identity and Access Management (IAM) for Cloud Data Fusion
- Familiarity with Cloud Data Fusion networking
Assumptions and scope
This use case has the following requirements:
- A private Cloud Data Fusion instance. For security reasons, an organization may require that you use this type of instance.
- A BigQuery source and sink.
- Access control with IAM, not role-based access control (RBAC).
Solution
This solution compares baseline and use case specific architecture and configuration.
Architecture
The following diagrams compare the project architecture for creating a Cloud Data Fusion instance and running pipelines when you use clusters in the same project (baseline) and in a different project through the tenant project VPC.
Baseline architecture
This diagram shows the baseline architecture of the projects:
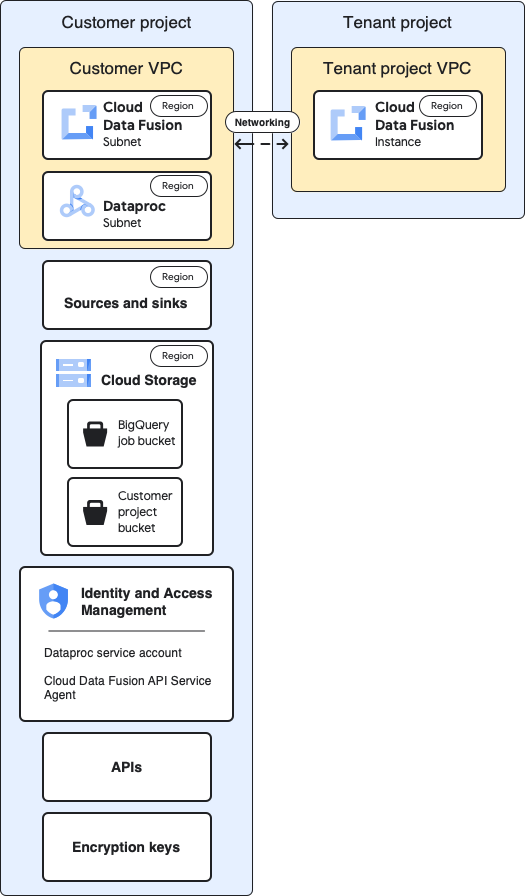
For the baseline configuration, you create a private Cloud Data Fusion instance and run a pipeline with no additional customization:
- You use one of the built-in compute profiles
- The source and sink are in the same project as the instance
- No additional roles have been granted to any of the service accounts
For more information about tenant and customer projects, see Networking.
Use case architecture
This diagram shows the project architecture when you use clusters in another project:
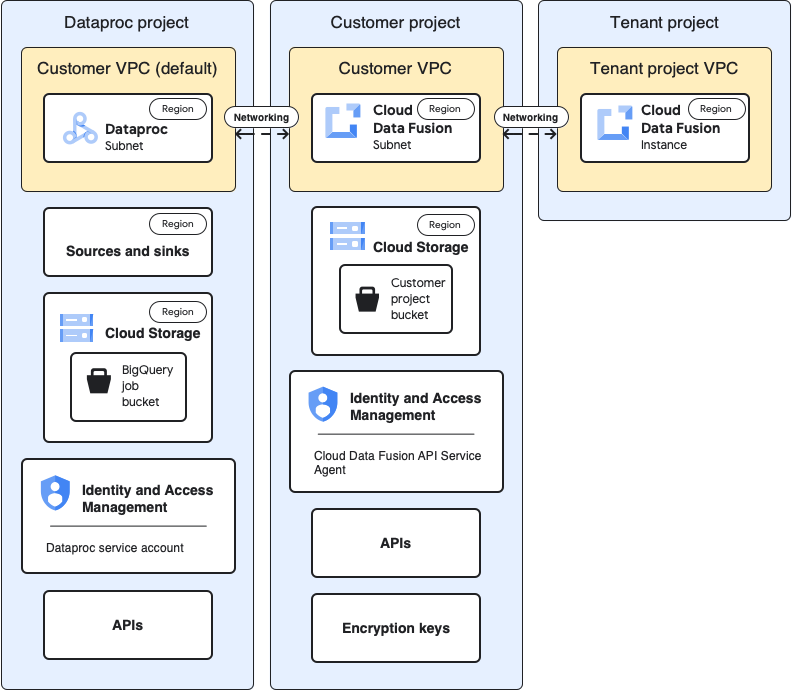
Configurations
The following sections compare the baseline configurations to the use case specific configurations for using Dataproc clusters in a different project through the default, tenant project VPC.
In the following use case descriptions, the customer project is where the Cloud Data Fusion instance runs and the Dataproc project is where the Dataproc cluster is launched.
Tenant project VPC and instance
| Baseline | Use case |
|---|---|
In the preceding baseline architecture diagram, the tenant project
contains the following components:
|
No additional configuration is needed for this use case. |
Customer project
| Baseline | Use case |
|---|---|
| Your Google Cloud project is where you deploy and run pipelines. By default, the Dataproc clusters are launched in this project when you run your pipelines. | In this use case, you manage two projects. On this page, the
customer project refers to where the Cloud Data Fusion
instance runs. The Dataproc project refers to where the Dataproc clusters launch. |
Customer VPC
| Baseline | Use case |
|---|---|
From your (the customer's) perspective, the customer VPC is where Cloud Data Fusion is logically situated. Key takeaway: You can find the Customer VPC details in the VPC networks page of your project. |
No additional configuration is needed for this use case. |
Cloud Data Fusion subnet
| Baseline | Use case |
|---|---|
From your (the customer's) perspective, this subnet is where Cloud Data Fusion is logically situated. Key takeaway: The region of this subnet is the same as the location of the Cloud Data Fusion instance in the tenant project. |
No additional configuration is needed for this use case. |
Dataproc subnet
| Baseline | Use case |
|---|---|
The subnet where Dataproc clusters are launched when you run a pipeline. Key takeaways:
|
This is a new subnet where Dataproc clusters are launched when you run a pipeline. Key takeaways:
|
Sources and sinks
| Baseline | Use case |
|---|---|
The sources where data is extracted and sinks where data is loaded, such as BigQuery sources and sinks. Key takeaway:
|
The use case specific access control configurations on this page are for BigQuery sources and sinks. |
Cloud Storage
| Baseline | Use case |
|---|---|
The storage bucket in the customer project that helps transfer files between Cloud Data Fusion and Dataproc. Key takeaways:
|
No additional configuration is needed for this use case. |
Temporary buckets used by source and sink
| Baseline | Use case |
|---|---|
The temporary buckets created by plugins for your sources and sinks, such as the load jobs initiated by the BigQuery Sink plugin. Key takeaways:
|
For this use case, the bucket can be created in any project. |
Buckets that are sources or sinks of data for plugins
| Baseline | Use case |
|---|---|
| Customer buckets, which you specify in the configurations for plugins, such as the Cloud Storage plugin and the FTP to Cloud Storage plugin. | No additional configuration is needed for this use case. |
IAM: Cloud Data Fusion API Service Agent
| Baseline | Use case |
|---|---|
When the Cloud Data Fusion API is enabled, the
Cloud
Data Fusion API Service Agent role
( Key takeaways:
|
For this use case, grant the Cloud Data Fusion API Service Agent role to the service account in the Dataproc project. Then grant the following roles in that project:
|
IAM: Dataproc service account
| Baseline | Use case |
|---|---|
The service account used to run the pipeline as a job within the Dataproc cluster. By default, it's the Compute Engine service account. Optional: in the baseline configuration, you can change the default service account to another service account from the same project. Grant the following IAM roles to the new service account:
|
This use case example assumes you use the default
Compute Engine service account ( Grant the following roles to the default Compute Engine service account in the Dataproc project.
Grant the Service Account User role to the Cloud Data Fusion Service Account on the default Compute Engine service account of the Dataproc project. This action must be performed in the Dataproc project. Add the default Compute Engine service account of the Dataproc project to the Cloud Data Fusion project. Also grant the following roles:
|
APIs
| Baseline | Use case |
|---|---|
When you enable the Cloud Data Fusion API, the following APIs are
also enabled. For more information about these APIs, go to the
APIs & services page in your project.
When you enable the Cloud Data Fusion API, the following service accounts are automatically added to your project:
|
For this use case, enable the following APIs in the project that
contains the Dataproc project:
|
Encryption keys
| Baseline | Use case |
|---|---|
In the baseline configuration, encryption keys can be Google-managed or CMEK Key takeaways: If you use CMEK, your baseline configuration requires the following:
Depending on the services used in your pipeline, such as BigQuery or Cloud Storage, service accounts must also be granted the Cloud KMS CryptoKey Encrypter/Decrypter role:
|
If you don't use CMEK, no additional changes are needed for this use case. If you use CMEK, the Cloud KMS CryptoKey Encrypter/Decrypter role must be provided to the following service account at the key level in the project where it's created:
Depending on the services used in your pipeline, such as BigQuery or Cloud Storage, other service accounts must also be granted the Cloud KMS CryptoKey Encrypter/Decrypter role at the key level. For example:
|
After you make these use case specific configurations, your data pipeline can start running on clusters in another project.
What's next
- Learn more about networking in Cloud Data Fusion.
- Refer to the IAM basic and predefined roles reference.