Questo tutorial mostra come creare una pipeline riutilizzabile che legge i dati da Cloud Storage, esegue controlli della qualità dei dati e scrive su Cloud Storage.
Le pipeline riutilizzabili hanno una struttura regolare, ma puoi modificare la configurazione di ogni nodo della pipeline in base alle configurazioni fornite da un server HTTP. Ad esempio, una pipeline statica potrebbe leggere i dati da Cloud Storage, applicare trasformazioni e scrivere in una tabella di output BigQuery. Se vuoi che la trasformazione e la tabella di output BigQuery cambino in base al file Cloud Storage letto dalla pipeline, crea una pipeline riutilizzabile.
Obiettivi
- Utilizza il plug-in Cloud Storage Argument Setter per consentire alla pipeline di leggere input diversi in ogni esecuzione.
- Utilizza il plug-in Cloud Storage Argument Setter per consentire alla pipeline di eseguire diversi controlli di qualità a ogni esecuzione.
- Scrivi i dati di output di ogni esecuzione in Cloud Storage.
Costi
In questo documento vengono utilizzati i seguenti componenti fatturabili di Google Cloud:
- Cloud Data Fusion
- Cloud Storage
Per generare una stima dei costi in base all'utilizzo previsto,
utilizza il calcolatore prezzi.
Prima di iniziare
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Cloud Data Fusion, Cloud Storage, BigQuery, and Dataproc APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. - Crea un'istanza Cloud Data Fusion.
Nella console Google Cloud , apri la pagina Istanze.
Nella colonna Azioni per l'istanza, fai clic sul link Visualizza istanza. L'interfaccia web di Cloud Data Fusion si apre in una nuova scheda del browser.
Vai all'interfaccia web di Cloud Data Fusion.
Quando utilizzi Cloud Data Fusion, usi sia la console Google Cloud che l'interfaccia web separata di Cloud Data Fusion. Nella console Google Cloud , puoi creare un progetto Google Cloud e creare ed eliminare istanze di Cloud Data Fusion. Nell'interfaccia web di Cloud Data Fusion, puoi utilizzare le varie pagine, come Pipeline Studio o Wrangler, per utilizzare le funzionalità di Cloud Data Fusion.
Esegui il deployment del plug-in Cloud Storage Argument Setter
Nell'interfaccia web di Cloud Data Fusion, vai alla pagina Studio.
Nel menu Azioni, fai clic su Impostazione argomenti GCS.
Leggi da Cloud Storage
- Nell'interfaccia web di Cloud Data Fusion, vai alla pagina Studio.
- Fai clic su arrow_drop_down Origine e seleziona Cloud Storage. Nella pipeline viene visualizzato il nodo per un'origine Cloud Storage.
Nel nodo Cloud Storage, fai clic su Proprietà.
Nel campo Nome di riferimento, inserisci un nome.
Nel campo Percorso, inserisci
${input.path}. Questa macro controlla il percorso di input di Cloud Storage nelle diverse esecuzioni della pipeline.Nel riquadro Schema di output a destra, rimuovi il campo offset dallo schema di output facendo clic sull'icona del cestino nella riga del campo offset.
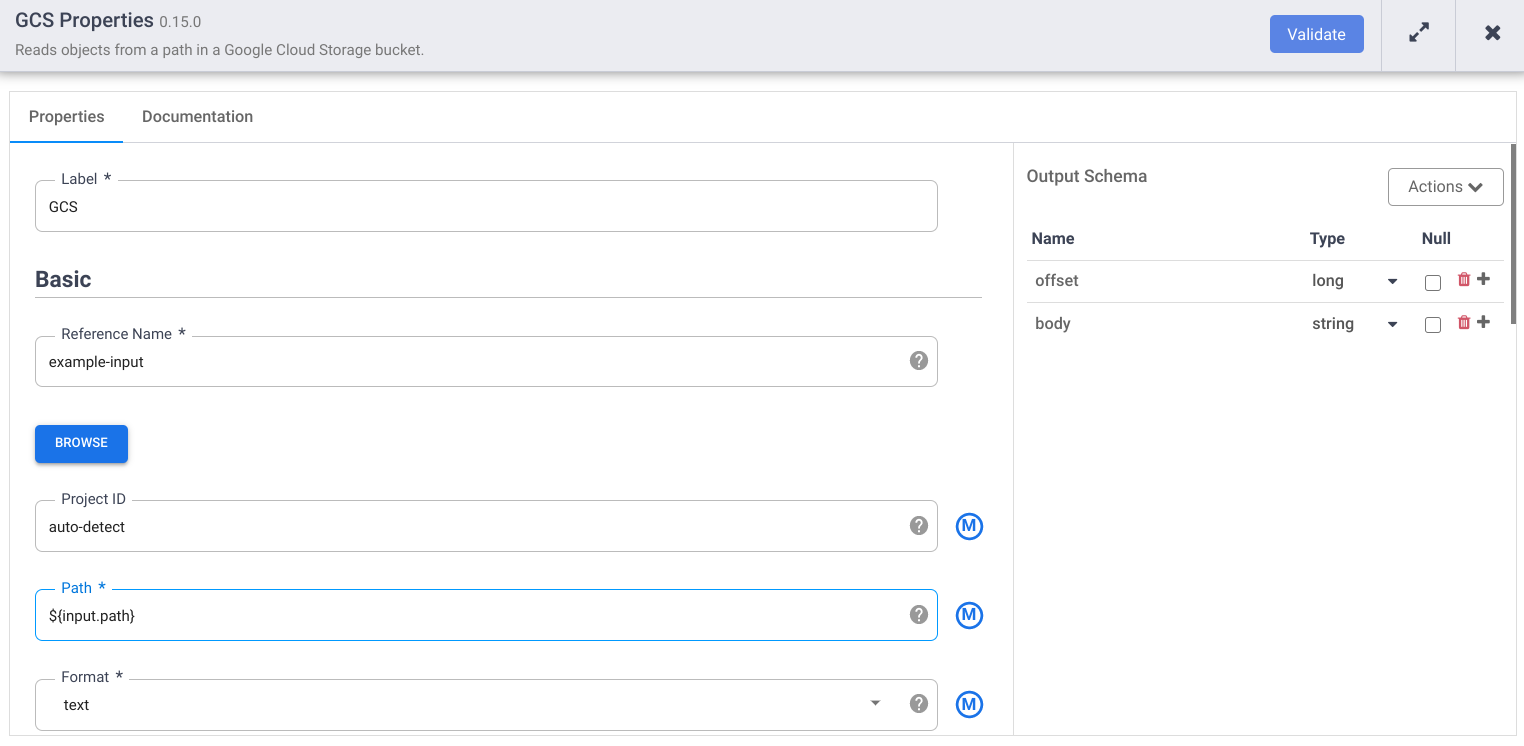
Fai clic su Convalida e correggi eventuali errori.
Fai clic su per uscire dalla finestra di dialogo Proprietà.
Trasforma i tuoi dati
- Nell'interfaccia web di Cloud Data Fusion, vai alla pipeline di dati nella pagina Studio.
- Nel menu a discesa Trasforma arrow_drop_down, seleziona Wrangler.
- Nel canvas di Pipeline Studio, trascina una freccia dal nodo Cloud Storage
al nodo Wrangler.
- Vai al nodo Wrangler nella pipeline e fai clic su Properties (Proprietà).
- Nel campo Nome campo di input, inserisci
body. - Nel campo Recipe (Ricetta), inserisci
${directives}. Questa macro controlla la logica di trasformazione nelle diverse esecuzioni della pipeline.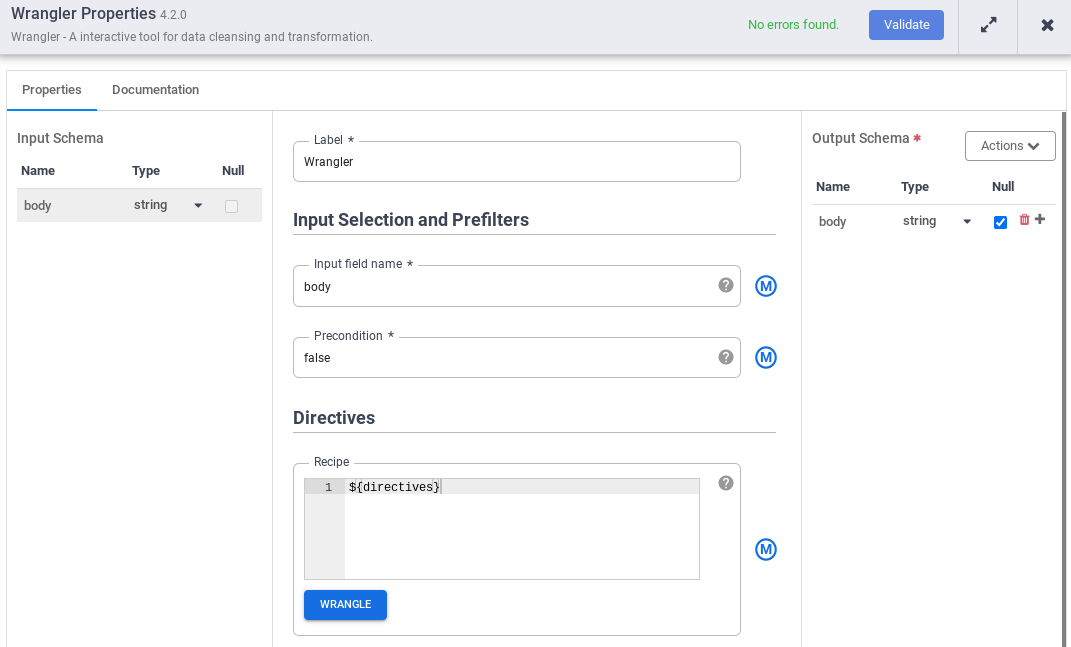
- Fai clic su Convalida e correggi eventuali errori.
- Fai clic su per uscire dalla finestra di dialogo Proprietà.
Scrivi in Cloud Storage
- Nell'interfaccia web di Cloud Data Fusion, vai alla pipeline di dati nella pagina Studio.
- Nel menu a discesa Sink arrow_drop_down, seleziona Cloud Storage.
- Nell'area di lavoro di Pipeline Studio, trascina una freccia dal nodo Wrangler al nodo Cloud Storage che hai appena aggiunto.
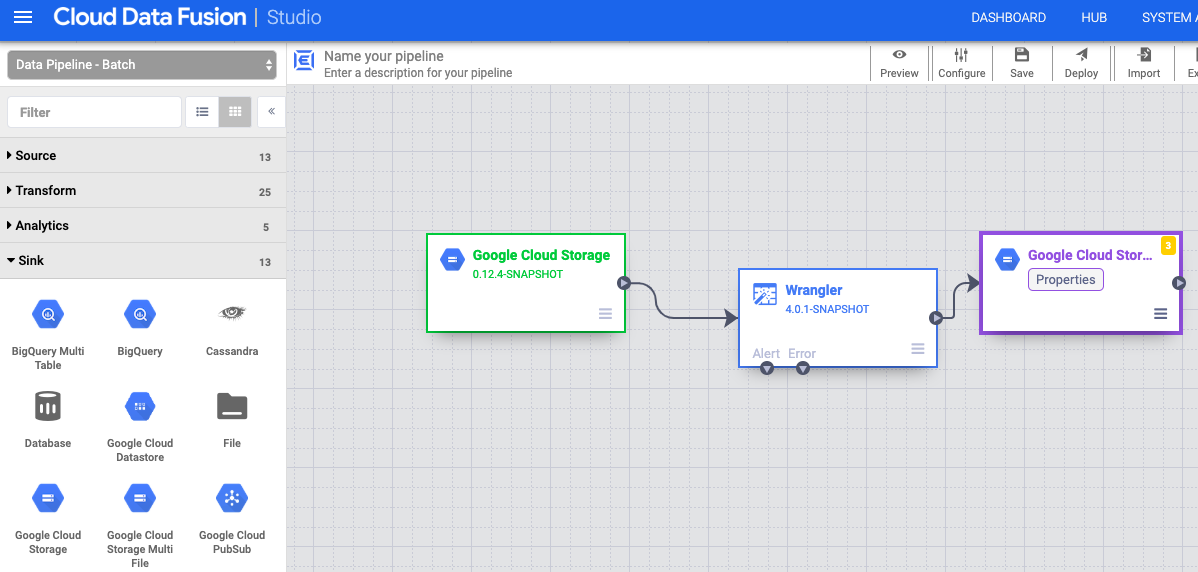
- Vai al nodo sink Cloud Storage nella pipeline e fai clic su Properties (Proprietà).
- Nel campo Nome di riferimento, inserisci un nome.
- Nel campo Percorso, inserisci il percorso di un bucket Cloud Storage nel tuo progetto, in cui la pipeline può scrivere i file di output. Se non hai
un bucket Cloud Storage, creane uno.
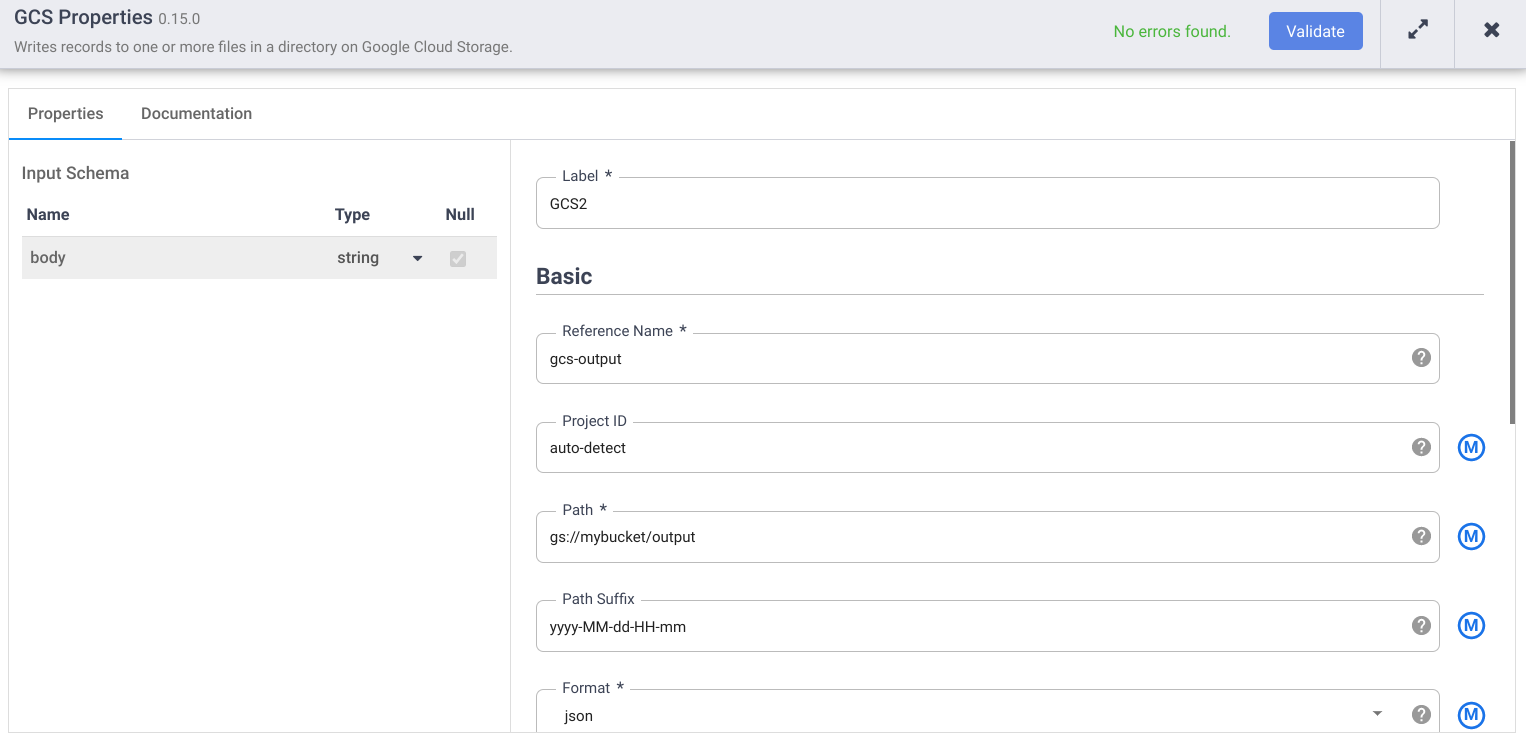
- Fai clic su Convalida e correggi eventuali errori.
- Fai clic su per uscire dalla finestra di dialogo Proprietà.
Imposta gli argomenti della macro
- Nell'interfaccia web di Cloud Data Fusion, vai alla pipeline di dati nella pagina Studio.
- Nel menu a discesa arrow_drop_down Condizioni e azioni, fai clic su Impostazione argomenti GCS.
- Nel canvas di Pipeline Studio, trascina una freccia dal nodo Cloud Storage Argument Setter al nodo origine Cloud Storage.
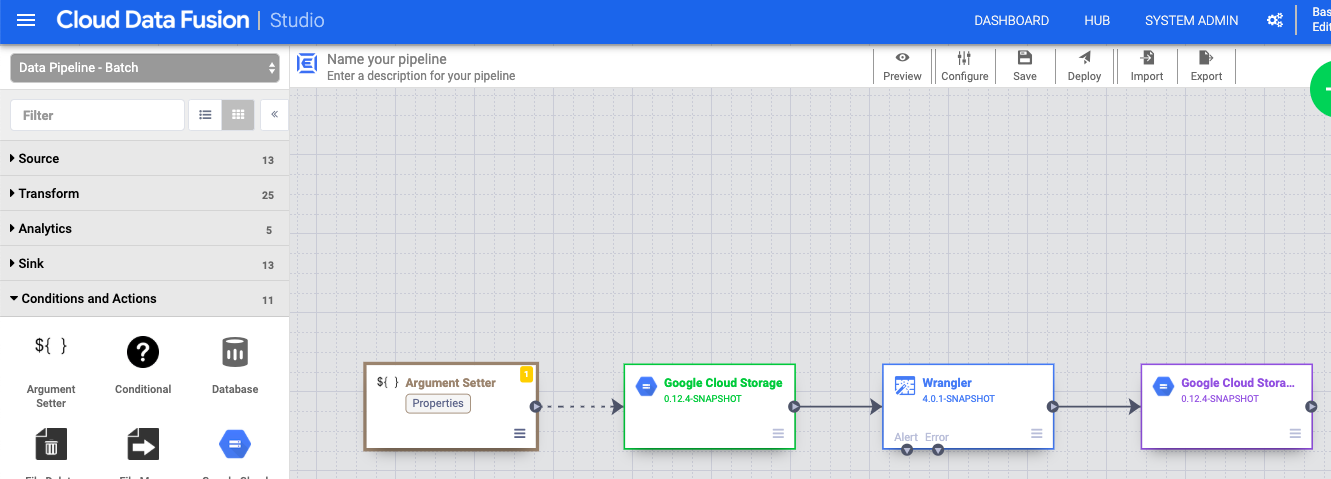
- Vai al nodo Imposta argomento Cloud Storage nella pipeline e fai clic su Proprietà.
Nel campo URL, inserisci il seguente URL:
gs://reusable-pipeline-tutorial/args.jsonL'URL corrisponde a un oggetto accessibile pubblicamente in Cloud Storage che contiene i seguenti contenuti:
{ "arguments" : [ { "name": "input.path", "value": "gs://reusable-pipeline-tutorial/user-emails.txt" }, { "name": "directives", "value": "send-to-error !dq:isEmail(body)" } ] }Il primo dei due argomenti è il valore di
input.path. Il percorsogs://reusable-pipeline-tutorial/user-emails.txtè un oggetto accessibile pubblicamente in Cloud Storage che contiene i seguenti dati di test:alice@example.com bob@example.com craig@invalid@example.comIl secondo argomento è il valore di
directives. Il valoresend-to-error !dq:isEmail(body)configura Wrangler in modo da filtrare le righe che non sono un indirizzo email valido. Ad esempio,craig@invalid@example.comviene filtrato.Fai clic su Convalida per assicurarti che non ci siano errori.
Fai clic su per uscire dalla finestra di dialogo Proprietà.
Esegui il deployment della pipeline ed eseguila
Nella barra superiore della pagina Pipeline Studio, fai clic su Assegna un nome alla pipeline. Assegna un nome alla pipeline e fai clic su Salva.
Fai clic su Esegui il deployment.
Per aprire Runtime Arguments e visualizzare gli argomenti della macro (runtime)
input.pathedirectives, fai clic sul menu a discesa arrow_drop_down accanto a Esegui.Lascia vuoti i campi dei valori per comunicare a Cloud Data Fusion che il nodo Cloud Storage Argument Setter nella pipeline imposterà i valori di questi argomenti durante l'esecuzione.

Fai clic su Esegui.
Esegui la pulizia
Per evitare che al tuo account Google Cloud vengano addebitati costi relativi alle risorse utilizzate in questo tutorial, elimina il progetto che contiene le risorse oppure mantieni il progetto ed elimina le singole risorse.
Al termine del tutorial, esegui la pulizia delle risorse create suGoogle Cloud in modo che non occupino quota e non ti vengano addebitate in futuro. Le seguenti sezioni descrivono come eliminare o disattivare queste risorse.
Elimina l'istanza Cloud Data Fusion
Segui le istruzioni per eliminare l'istanza Cloud Data Fusion.
Elimina il progetto
Il modo più semplice per eliminare la fatturazione è eliminare il progetto creato per il tutorial.
Per eliminare il progetto:
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Passaggi successivi
- Leggi le guide illustrative
- Completa un altro tutorial