Linhagem de dados do Cloud Data Fusion
É possível usar a linhagem de dados do Cloud Data Fusion para fazer o seguinte:
Detectar a causa principal de eventos de dados inválidos.
Faça uma análise de impacto antes de fazer mudanças nos dados.
Recomendamos usar a integração de linhagem de recursos no catálogo universal do Dataplex. Para mais informações, consulte Visualizar a linhagem no catálogo universal do Dataplex.
Também é possível conferir a linhagem nos níveis de conjunto de dados e campo no Cloud Data Fusion Studio usando a opção Metadados, que mostra a linhagem de um período selecionado.
A linhagem no nível do conjunto de dados mostra a relação entre conjuntos de dados e pipelines.
A linhagem em nível de campo mostra as operações realizadas em um conjunto de campos no conjunto de dados de origem para produzir um conjunto diferente de campos no conjunto de dados de destino.
A partir do Cloud Data Fusion 6.9.2.4, se você não rastrear a linhagem no Cloud Data Fusion, recomendamos desativar a emissão de linhagem no nível do campo na sua instância usando o método patch:
curl -X PATCH -H 'Content-Type: application/json' -H "Authorization: Bearer
$(gcloud auth print-access-token)"
'https://datafusion.googleapis.com/v1beta1/projects/PROJECT_ID/locations/REGION/instances/INSTANCE_ID?updateMask=options'
-d '{ "options": { "metadata.messaging.field.lineage.emission.enabled": "false" } }'
Substitua:
PROJECT_ID: o ID do projeto Google CloudREGION: o local do Google Cloud projetoINSTANCE_ID: o ID da instância do Cloud Data Fusion
Cenário do tutorial
Neste tutorial, você trabalhará com dois pipelines:
O pipeline
Shipment Data Cleansinglê dados brutos de remessa de um pequeno conjunto de dados de amostra e aplica transformações para limpar os dados.Em seguida, o pipeline
Delayed Shipments USAlê os dados de frete limpos, analisa-os e encontra os fretes nos EUA que atrasaram além de um limite.
Esses pipelines de tutorial demonstram um cenário típico em que os dados brutos são limpos e enviados para processamento downstream. Essa trilha de dados brutos para os dados de frete limpos até os resultados da análise pode ser explorada usando o recurso de linhagem do Cloud Data Fusion.
Abrir a IU do Cloud Data Fusion
Ao usar o Cloud Data Fusion, você usa o console Google Cloud e a IU separada do Cloud Data Fusion. No console Google Cloud , é possível criar um projeto do console Google Cloud e criar e excluir instâncias do Cloud Data Fusion. Na interface do Cloud Data Fusion, é possível usar as várias páginas, como Linhagem, para acessar os recursos do Cloud Data Fusion.
No console do Google Cloud , abra a página Instâncias.
Na coluna Ações da instância, clique no link "Visualizar instância". A IU do Cloud Data Fusion será aberta em uma nova guia do navegador.
No painel Integrar, clique em Studio para abrir a página Studio do Cloud Data Fusion.
Implantar e executar pipelines
Importe os dados de frete brutos. Na página Studio, clique em Importar ou clique em + > Pipeline > Importar e selecione e importe o pipeline de limpeza de dados de frete que você baixou em Antes de começar.
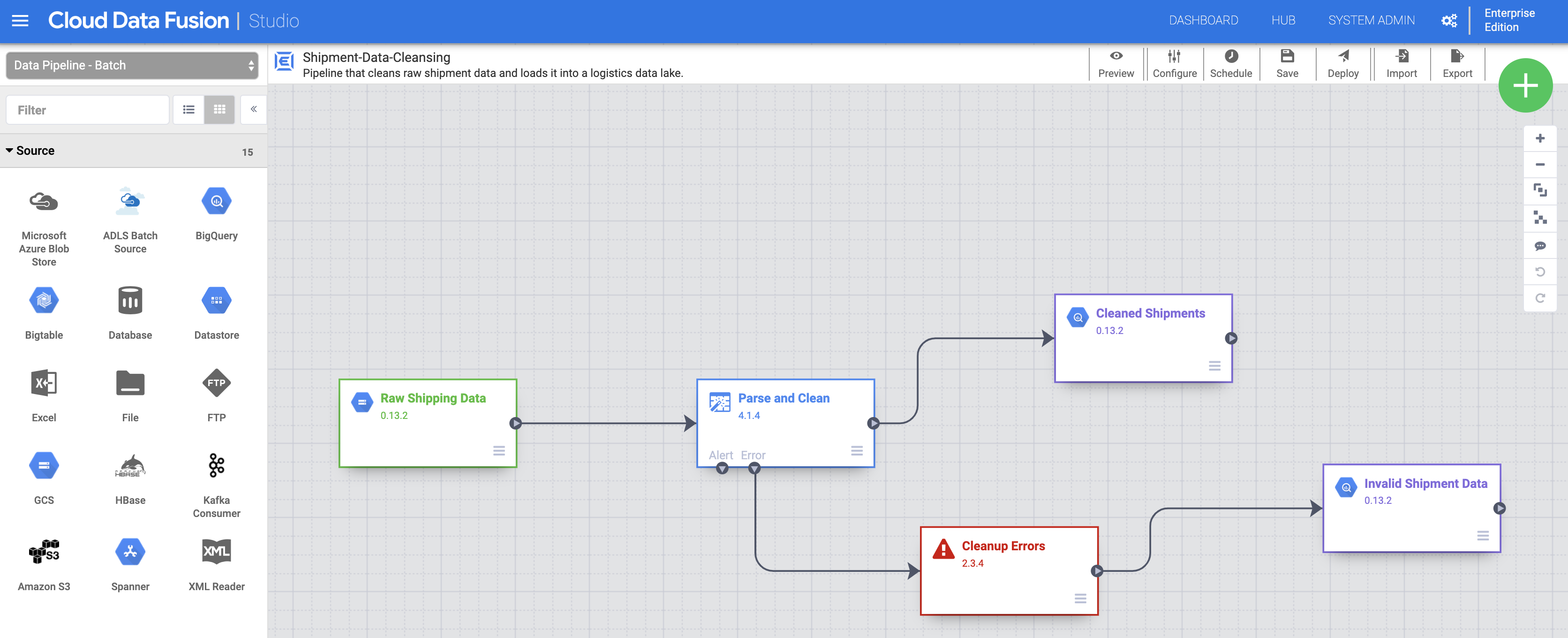
Implante o pipeline. Clique em "Implantar" no canto superior direito da página Studio. Após a implantação, a página Pipeline será aberta.
Execute o canal. Clique em "Executar" na parte superior central da página Pipeline.
Importe, implante e execute os dados e o pipeline de fretes atrasados. Depois que o status da limpeza de dados de frete mostrar Concluído, aplique as etapas anteriores aos dados de fretes atrasados nos EUA. Você fez o download deles na etapa Antes de começar. Retorne à página Studio para importar os dados e, em seguida, implante e execute esse segundo pipeline na página Pipeline. Depois que o segundo pipeline for concluído, continue com as etapas restantes.
Descobrir conjuntos de dados
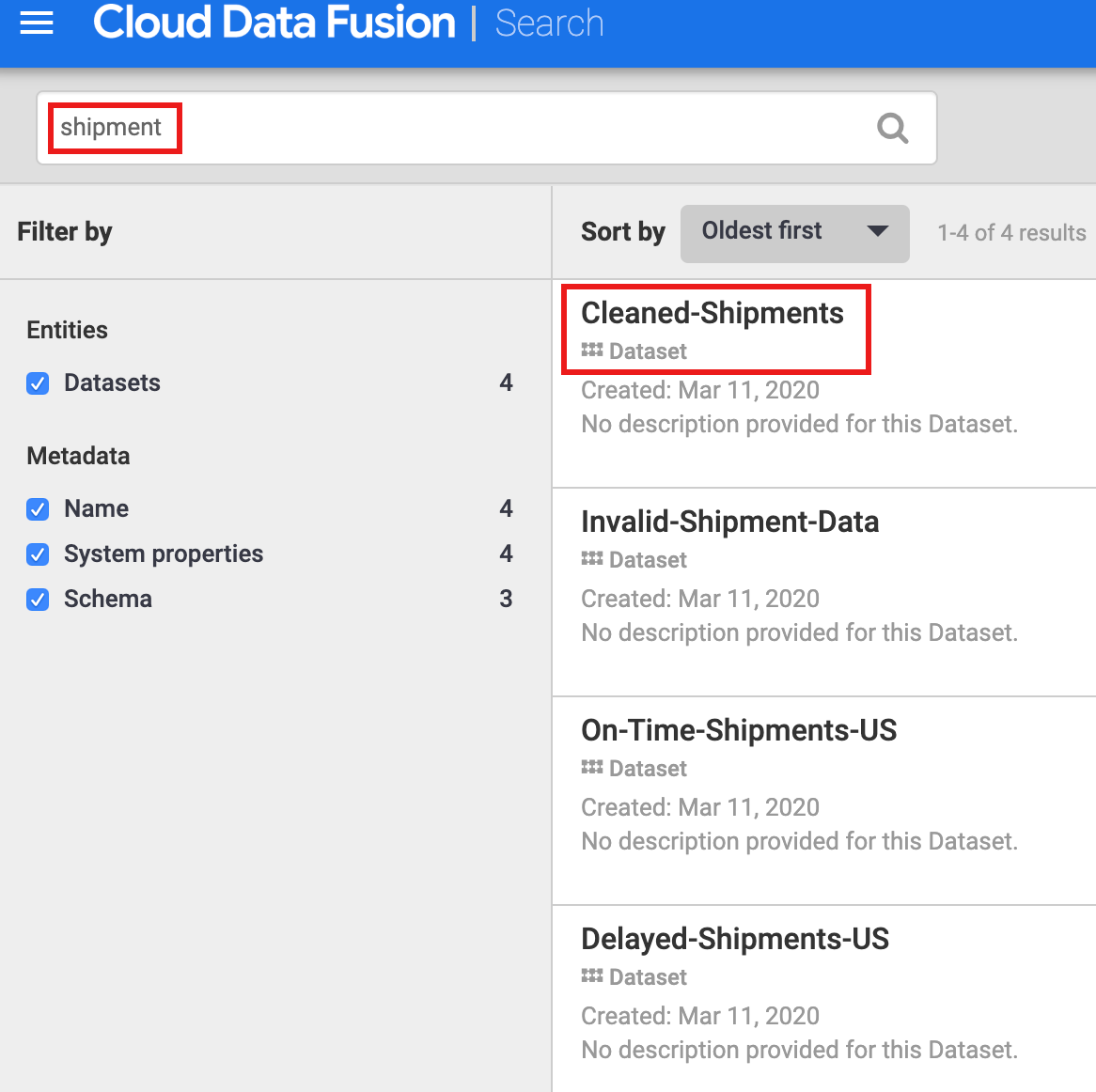
Você precisa descobrir um conjunto de dados antes de explorar a linhagem. Selecione Metadados no painel de navegação à esquerda da IU do Cloud Data Fusion para abrir a página Pesquisar para metadados. Como o conjunto de limpeza de dados de frete especificou Cleaned-Shipments (fretes limpos) como o conjunto de dados de referência, insira shipment (frete) na caixa de pesquisa. Os resultados da pesquisa incluem esse conjunto de dados.
Como usar tags para descobrir conjuntos de dados
Uma pesquisa de metadados descobre conjuntos de dados que foram consumidos, processados ou gerados por pipelines do Cloud Data Fusion. Os pipelines são executados em uma estrutura estruturada que gera e coleta metadados técnicos e operacionais. Os metadados técnicos incluem nome, tipo, esquema, campos, hora de criação e processamento do conjunto de dados. Essas informações técnicas são usadas pelos recursos de pesquisa e metadados do Cloud Data Fusion.
O Cloud Data Fusion também é compatível com a anotação de conjuntos de dados com metadados empresariais, como tags e propriedades de chave-valor, que podem ser usados como critérios de pesquisa. Por exemplo, para adicionar e pesquisar uma anotação de tag empresarial no conjunto de dados de frete brutos:
Clique no botão Propriedades do nó "Dados brutos de envio" na página Pipeline de limpeza de dados de envio para abrir a página Propriedades do Cloud Storage.
Clique em Visualizar metadados para abrir a página Pesquisar.
Em Tags empresariais, clique em + e insira um nome de tag (caracteres alfanuméricos e sublinhados são permitidos) e pressione Enter.

Explorar a linhagem
Linhagem no nível do conjunto de dados
Clique no nome do conjunto de dados "Cleaned-Shipments" (Fretes limpos) listado na página "Pesquisa" (em Descobrir conjuntos de dados) e clique na guia "Linhagem". O gráfico de linhagem mostra que esse conjunto de dados foi gerado pelo pipeline Shipments-Data-Cleansing (Limpeza de dados de frete), que consumiu o conjunto de dados brutos.
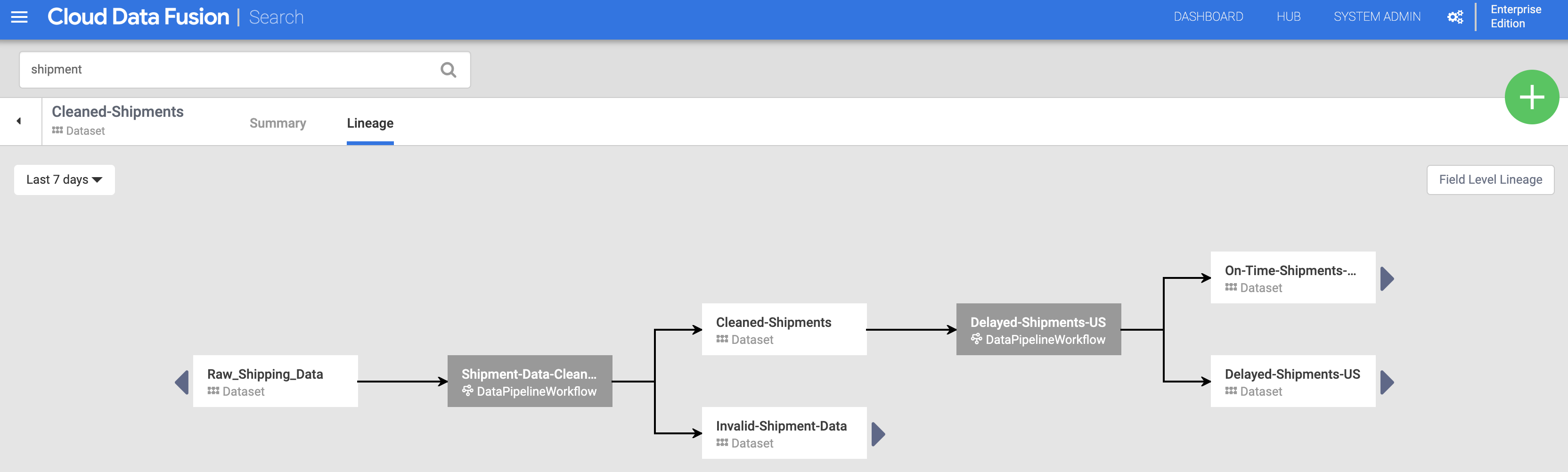
As setas para a esquerda e para a direita permitem navegar para frente e para trás por qualquer linhagem de conjunto de dados anterior ou subsequente. Neste exemplo, o gráfico exibe a linhagem completa do conjunto de dados de fretes limpos.
Linhagem no nível do campo
A linhagem no nível do campo do Cloud Data Fusion mostra a relação entre os campos de um conjunto de dados e as transformações que foram realizadas em um conjunto de campos para produzir um conjunto diferente de campos. Assim como a linhagem no nível do conjunto de dados, a linhagem no nível do campo é vinculada tempo, e os resultados mudam com o tempo.
Continuando da etapa Linhagem no nível do conjunto de dados, clique no botão "Linhagem no nível do campo" no canto superior direito do gráfico de linhagem no nível do conjunto de dados para exibir o gráfico de linhagem no nível do campo.
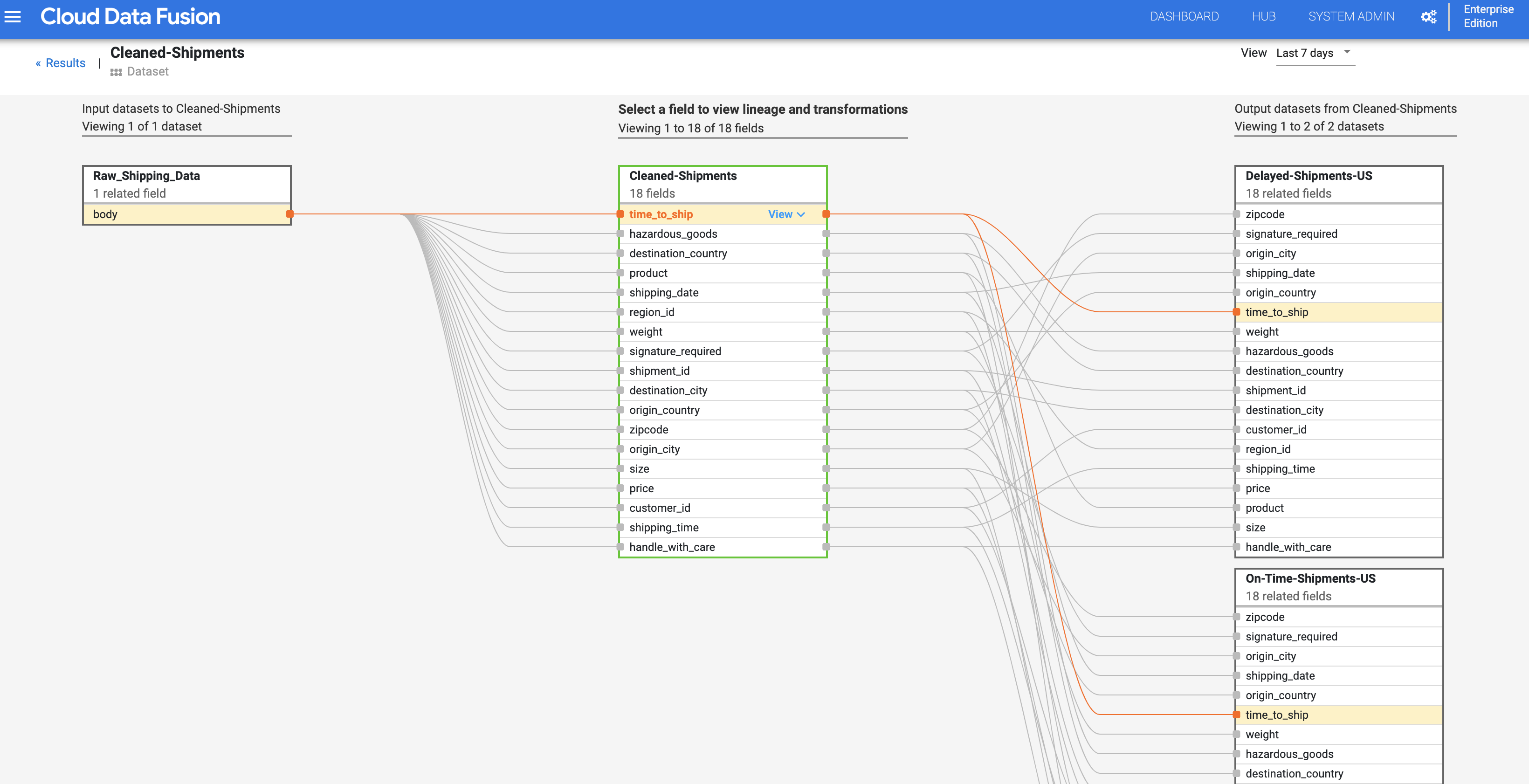
O gráfico de linhagem no nível do campo mostra as conexões entre os campos. Selecione um campo para visualizar a respectiva linhagem. Selecione Visualizar > Fixar campo para ver somente a linhagem desse campo.
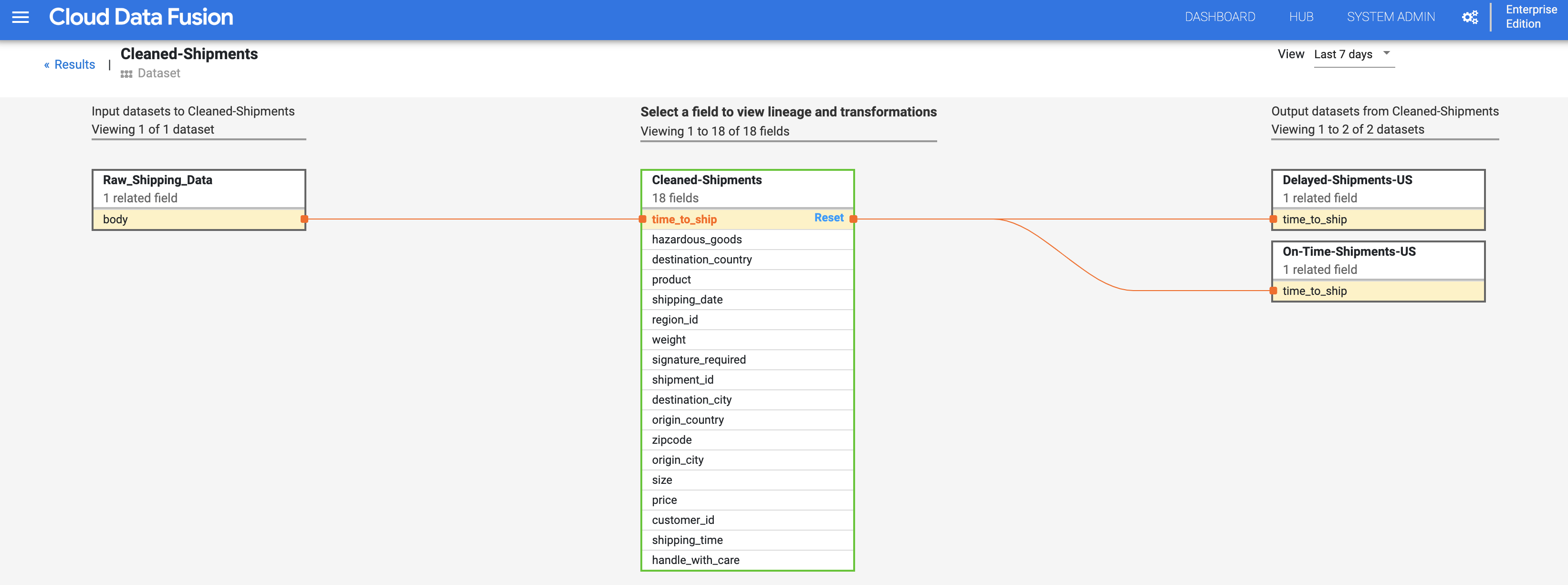
Selecione Visualizar > Visualizar impacto para realizar uma análise de impacto.
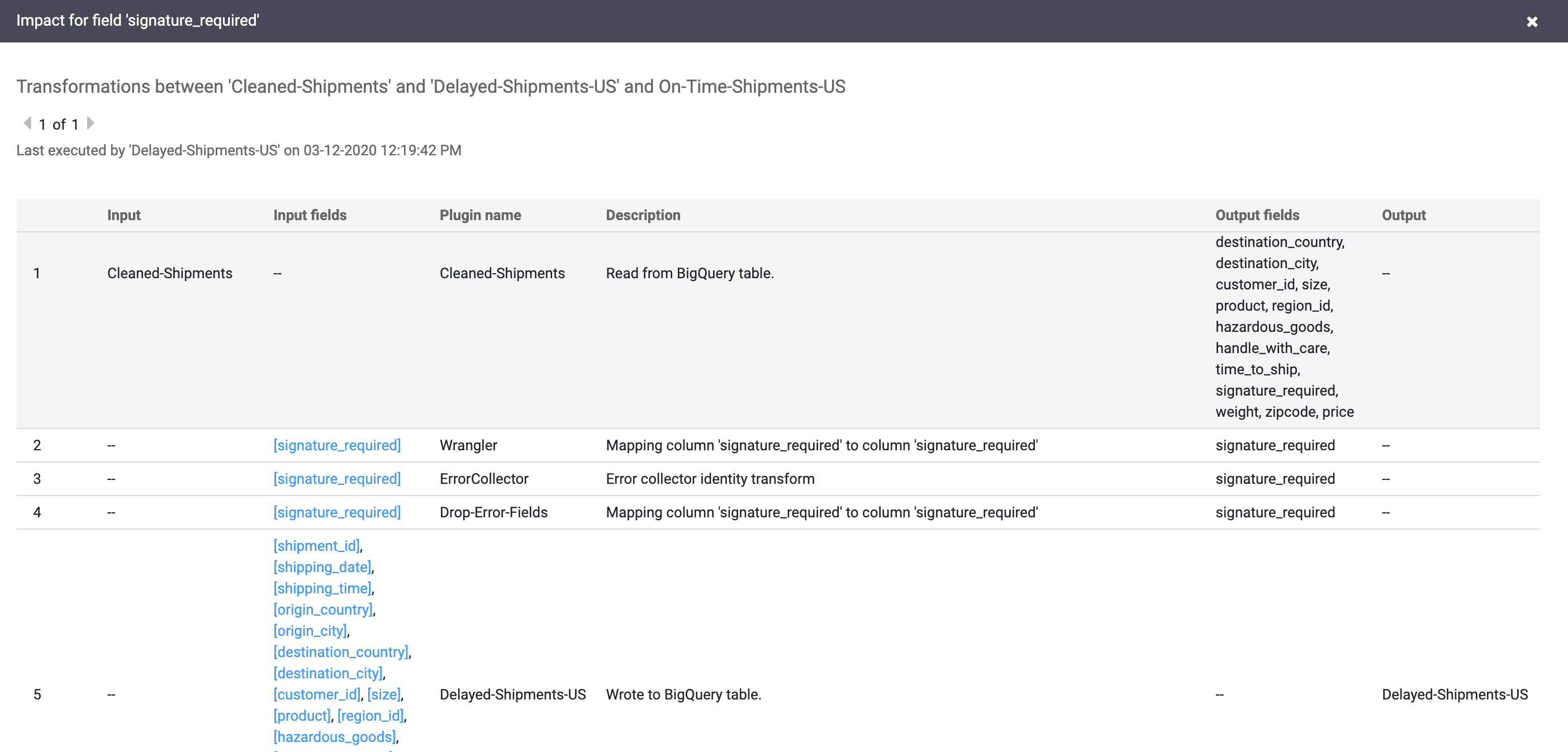
Os links de causa e impacto mostram as transformações realizadas em ambos os lados de um campo em um formato de livro contábil legível. Essas informações podem ser essenciais para a geração de relatórios e a governança.