Vous trouverez sur cette page la procédure à suivre pour exécuter un pipeline dans Cloud Data Fusion sur un cluster Dataproc existant.
Par défaut, Cloud Data Fusion crée des clusters éphémères pour chaque pipeline : il crée un cluster au début de l'exécution du pipeline, puis le supprime une fois l'exécution du pipeline terminée. Même si ce comportement permet de réduire les coûts en veillant à ce que les ressources ne soient créées que lorsque cela est requis, ce comportement par défaut peut ne pas être souhaitable dans les scénarios suivants :
Si le temps nécessaire à la création d'un cluster pour chaque pipeline est prohibitif pour votre cas d'utilisation.
Si votre organisation exige que les clusters soient créés de manière centralisée. Par exemple, lorsque vous souhaitez appliquer certaines stratégies à tous les clusters Dataproc.
Pour ces scénarios, vous exécutez plutôt des pipelines sur un cluster existant en procédant comme suit :
Avant de commencer
Vous devez disposer des éléments suivants :
Une instance Cloud Data Fusion.
Un cluster Dataproc existant.
Si vous exécutez vos pipelines dans Cloud Data Fusion version 6.2, utilisez une image Dataproc plus ancienne qui s'exécute avec Hadoop 2.x (par exemple, 1.5-debian10) ou mettez à jour Cloud Data Fusion vers la dernière version.
Se connecter au cluster existant
Dans Cloud Data Fusion versions 6.2.1 et ultérieures, vous pouvez vous connecter à un cluster Dataproc existant lorsque vous créez un profil Compute Engine.
Accédez à votre instance :
Dans la console Google Cloud, accédez à la page Cloud Data Fusion.
Pour ouvrir l'instance dans Cloud Data Fusion Studio, cliquez sur Instances, puis sur Afficher l'instance.
Cliquez sur Administrateur système.
Cliquez sur l'onglet Configuration.
Cliquez sur Profils de calcul système.
Cliquez sur Créer un profil. Une page d'approvisionneurs s'ouvre.
Cliquez sur Existing Dataproc (Cluster Dataproc existant).
Saisissez les informations de profil, de cluster et de surveillance.
Cliquez sur Créer.
Configurer votre pipeline pour qu'il utilise un profil personnalisé
Accédez à votre instance :
Dans la console Google Cloud, accédez à la page Cloud Data Fusion.
Pour ouvrir l'instance dans Cloud Data Fusion Studio, cliquez sur Instances, puis sur Afficher l'instance.
Accédez à votre pipeline sur la page Studio.
Cliquez sur Configurer.
Cliquez sur Compute config (Configuration de calcul).
Cliquez sur le profil que vous avez créé.
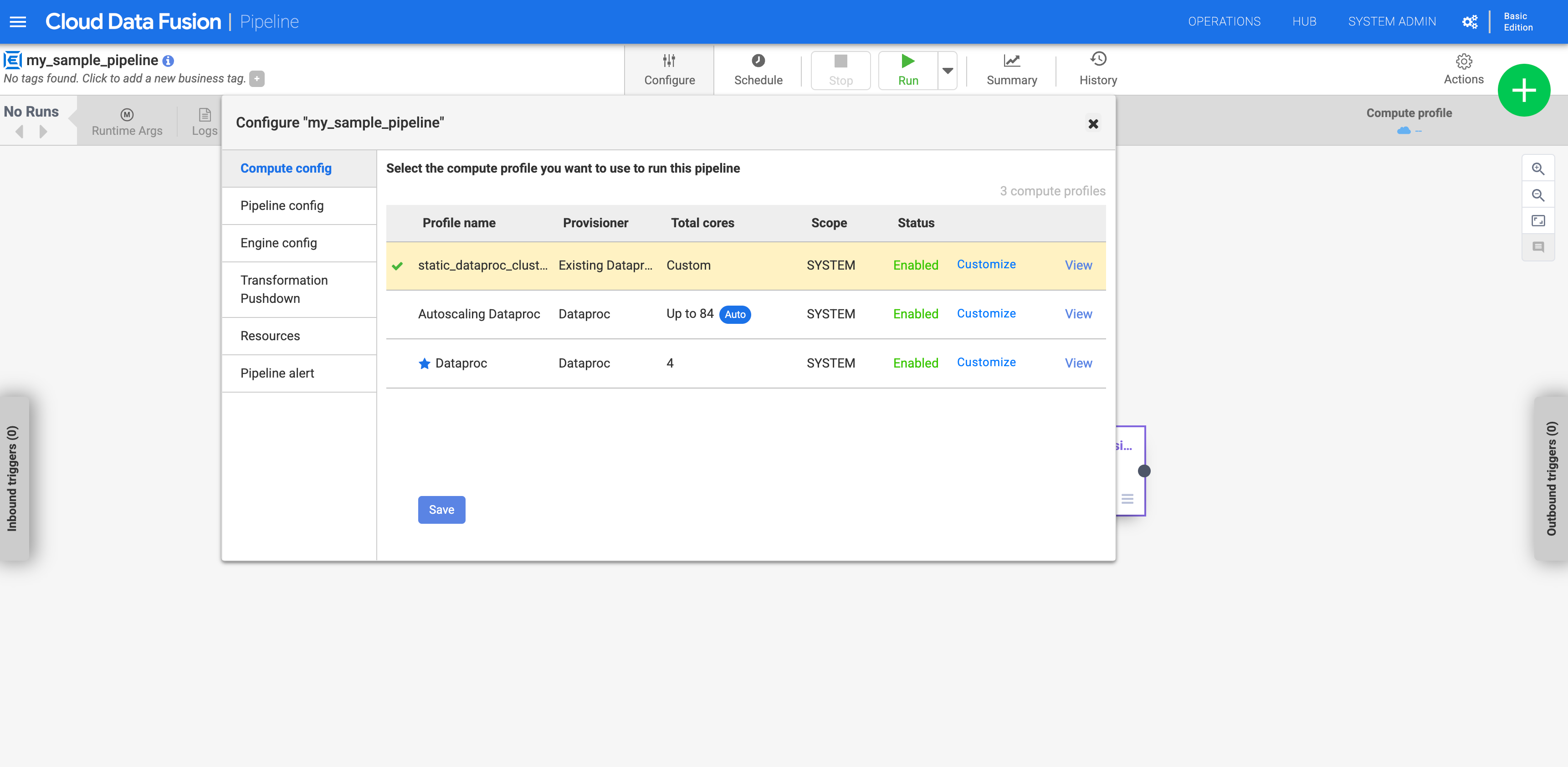
Figure 1: Cliquer sur le profil personnalisé Exécutez le pipeline. Il s'exécute sur le cluster Dataproc existant.
Étape suivante
- Découvrez comment configurer des clusters.
- Résolvez les problèmes liés à la suppression de clusters.