Auf dieser Seite wird beschrieben, wie Sie Daten aus einer PostgreSQL-Datenbank in einem Cloud Data Fusion-Instanz.
Hinweis
- Erstellen Sie eine Cloud Data Fusion-Instanz.
- Erlauben Sie Ihrer PostgreSQL-Datenbank, Verbindungen von Cloud Data Fusion zu akzeptieren. Daher empfehlen wir Ihnen, eine private Cloud Data Fusion-Instanz zu verwenden.
Erforderliche Rollen
Bitten Sie Ihren Administrator, Ihnen die folgenden IAM-Rollen zuzuweisen, um die Berechtigungen zu erhalten, die Sie zum Herstellen einer Verbindung zu einer PostgreSQL-Datenbank benötigen:
-
Dataproc-Worker (
roles/dataproc.worker) für das Dataproc-Dienstkonto im Projekt, das den Cluster enthält -
Cloud Data Fusion-Ausführer (
roles/datafusion.runner) für das Dataproc-Dienstkonto in dem Projekt, das den Cluster enthält -
So verwenden Sie Cloud SQL ohne den Cloud SQL Auth Proxy:
Cloud SQL-Client (
roles/cloudsql.client) für das Projekt, das die Cloud SQL-Instanz enthält
Weitere Informationen zum Zuweisen von Rollen finden Sie unter Zugriff auf Projekte, Ordner und Organisationen verwalten.
Sie können die erforderlichen Berechtigungen auch über benutzerdefinierte Rollen oder andere vordefinierte Rollen erhalten.
Instanz in Cloud Data Fusion öffnen
Rufen Sie in der Google Cloud Console die Seite „Cloud Data Fusion“ auf.
Um die Instanz in Cloud Data Fusion Studio zu öffnen, Klicken Sie auf Instanzen und dann auf Instanz ansehen.
Speichern Sie Ihr PostgreSQL-Passwort als Sicherheitsschlüssel
Geben Sie Ihr PostgreSQL-Passwort als sicheren Schlüssel ein, um Ihre Cloud Data Fusion-Instanz zu verschlüsseln. Weitere Informationen zu Schlüsseln finden Sie unter Cloud KMS
Klicken Sie in der Cloud Data Fusion-UI auf Systemadmin >. Konfiguration.
Klicken Sie auf HTTP-Aufrufe ausführen.

Wählen Sie im Drop-down-Menü PUT aus.
Geben Sie im Feld Pfad
namespaces/default/securekeys/pg_passwordein.Geben Sie im Feld Body den Wert
{"data":"POSTGRESQL_PASSWORD"}ein.POSTGRESQL_PASSWORDdurch PostgreSQL ersetzen Passwort.Klicken Sie auf Senden.
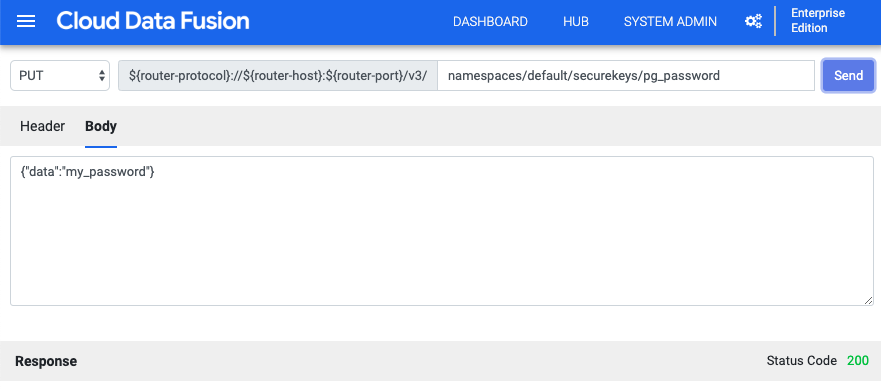
Im Feld Response werden Sie über alle Fehler informiert.
Mit Cloud SQL for PostgreSQL verbinden
Klicken Sie in der Cloud Data Fusion-UI auf das Menü menu und rufen Sie die Seite Wrangler auf.
Klicken Sie auf Verbindung hinzufügen.
Wählen Sie als zu verbindenden Quelltyp Datenbank aus.
Klicken Sie unter Google Cloud SQL for PostgreSQL auf Hochladen.

Laden Sie eine JAR-Datei hoch, die Ihren PostgreSQL-Treiber enthält. Ihre JAR-Datei muss das Format
NAME-VERSION.jarhaben. Wenn Ihre JAR-Datei dieses Format nicht befolgt, benennen Sie sie vor dem Hochladen um.Klicken Sie auf Weiter.
Geben Sie den Namen des Treibers, den Klassennamen und die Version in die Felder ein.
Klicken Sie auf Beenden.
Klicken Sie im Fenster Verbindung hinzufügen auf Google Cloud SQL für PostgreSQL Der JAR-Name sollte unter Google Cloud SQL for PostgreSQL angezeigt werden.

Füllen Sie die Pflichtfelder aus. Wählen Sie im Feld Passwort den zuvor gespeicherten Schlüssel aus. Dadurch wird Ihr Passwort mit Cloud KMS abgerufen.
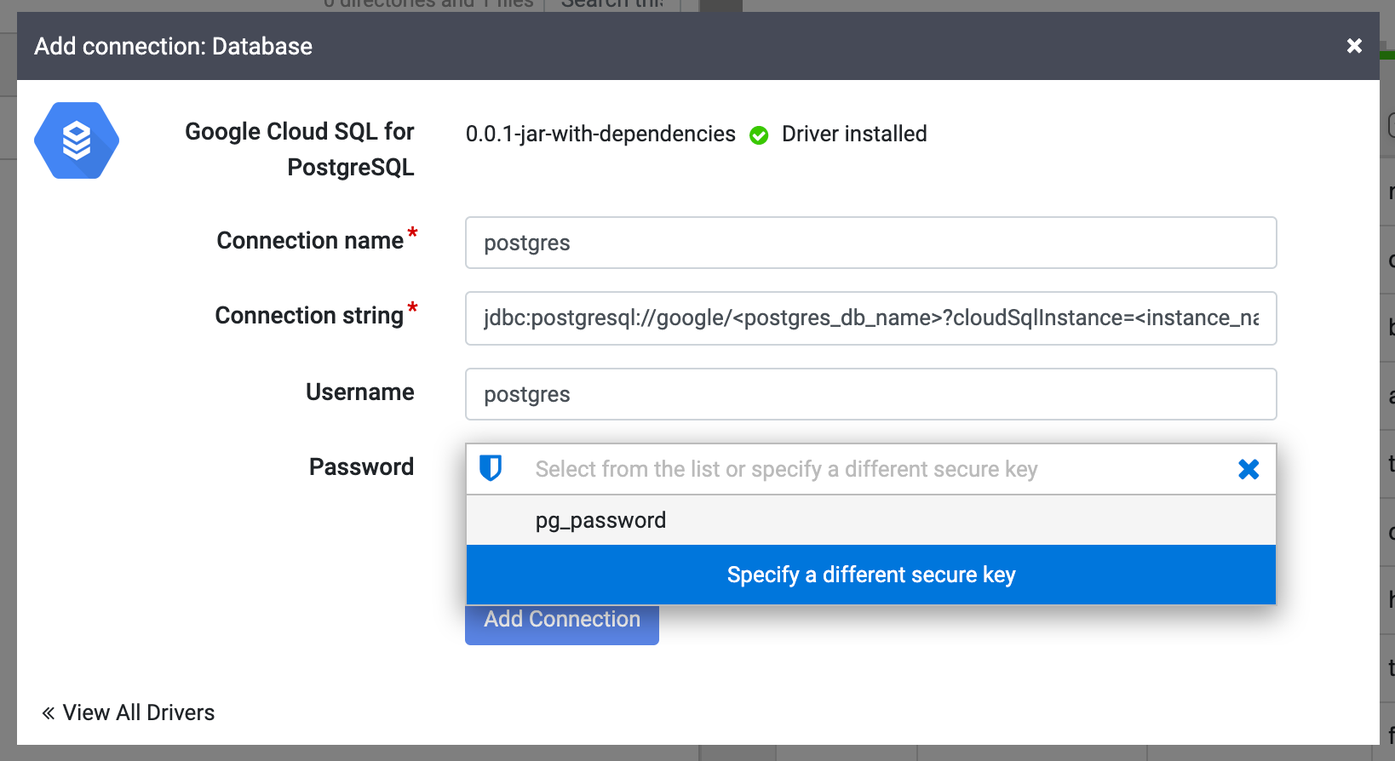
Geben Sie im Feld Verbindungsstring den Verbindungsstring so ein:
jdbc:postgresql://google/DATABASE_NAME?cloudSqlInstance=INSTANCE_CONNECTION_NAME&socketFactory=com.google.cloud.sql.postgres.SocketFactory&useSSL=false
Dabei gilt:
DATABASE_NAME: Der Cloud SQL-Datenbankname, der auf der Seite „Instanzdetails“ auf dem Tab Datenbanken aufgeführt ist.INSTANCE_CONNECTION_NAME: Der Name der Cloud SQL-Instanzverbindung, der auf der Seite „Instanzdetails“ auf dem Tab Übersicht angezeigt wird.

Beispiel:
jdbc:postgresql://google/postgres?cloudSqlInstance=dis-demo:us-central1:pgsql-1&socketFactory=com.google.cloud.sql.postgres.SocketFactory&useSSL=false
Cloud SQL Admin API aktivieren.
Klicken Sie auf Verbindung testen, um sicherzustellen, dass die Verbindung mit der Datenbank hergestellt werden kann.
Klicken Sie auf Verbindung hinzufügen.
Nachdem die PostgreSQL-Datenbank verbunden wurde, können Sie in Wrangler Transformationen auf Ihre Daten anwenden und in Studio eine Pipeline erstellen sowie die Ausgabe in eine Senke schreiben.