이 페이지에서는 Cloud Data Fusion의 Spark 대신 BigQuery에 변환을 실행하는 방법을 설명합니다.
자세한 내용은 변환 푸시다운 개요를 참조하세요.
시작하기 전에
변환 푸시다운은 버전 6.5.0 이상에서 사용할 수 있습니다. 파이프라인이 이전 환경에서 실행되는 경우 최신 버전으로 인스턴스를 업그레이드할 수 있습니다.
파이프라인에서 변환 푸시다운 사용 설정
Console
배포된 파이프라인에서 변환 푸시다운을 사용 설정하려면 다음을 수행합니다.
인스턴스로 이동합니다.
Google Cloud 콘솔에서 Cloud Data Fusion 페이지로 이동합니다.
Cloud Data Fusion Studio에서 인스턴스를 열려면 인스턴스를 클릭한 다음 인스턴스 보기를 클릭합니다.
메뉴 > 목록을 클릭합니다.
배포된 파이프라인 탭이 열립니다.
원하는 배포된 파이프라인을 클릭하여 Pipeline Studio에서 엽니다.
구성 > 변환 푸시다운을 클릭합니다.
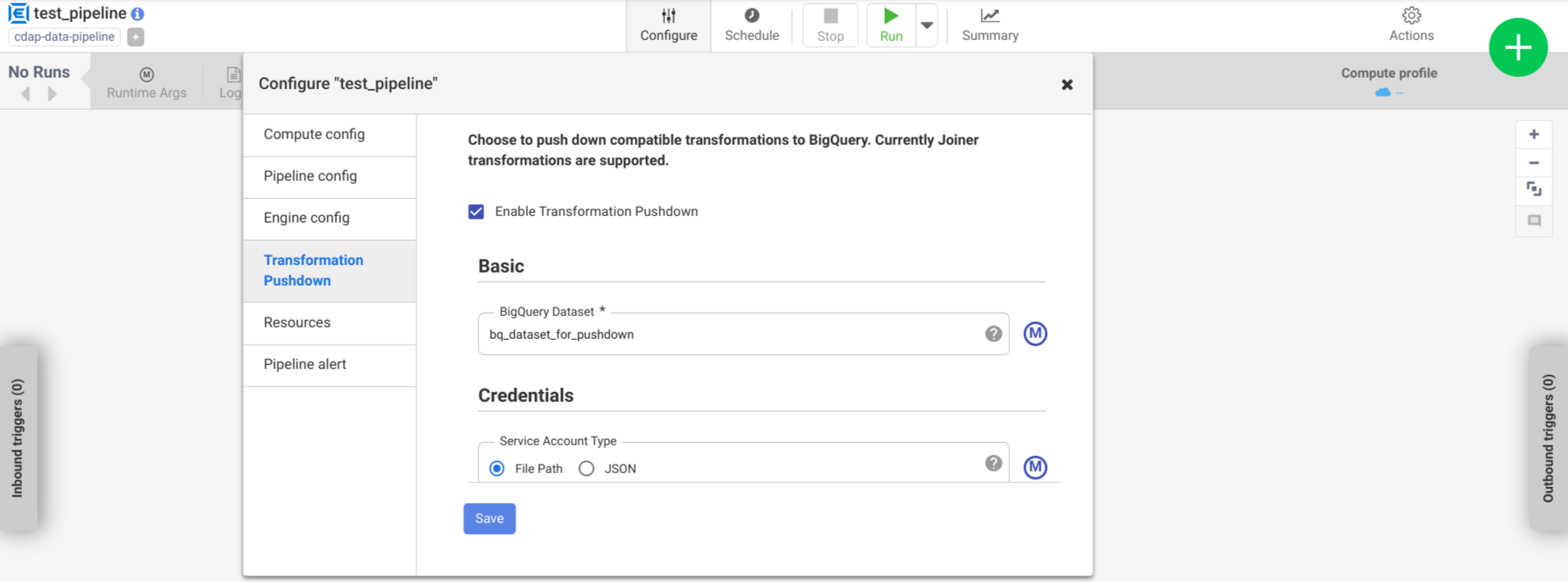
변환 푸시다운 사용 설정을 클릭합니다.
데이터 세트 필드에 BigQuery 데이터 세트 이름을 입력합니다.
선택사항: 매크로를 사용하려면 M을 클릭합니다. 자세한 내용은 데이터 세트를 참조하세요.
선택사항: 필요한 경우 옵션을 구성합니다.
저장을 클릭합니다.
선택적 구성
.| 속성 | 매크로 지원 | 지원되는 Cloud Data Fusion 버전 | 설명 |
|---|---|---|---|
| 연결 사용 | 아니요 | 6.7.0 이상 | 기존 연결을 사용할지 여부입니다. |
| 연결 | 예 | 6.7.0 이상 | 연결의 이름입니다. 이 연결은 프로젝트 및 서비스 계정 정보를 제공합니다. 선택사항: ${conn(connection_name)} 매크로 함수를 사용하세요. |
| 데이터 세트 프로젝트 ID | 예 | 6.5.0 | 데이터 세트가 BigQuery 작업이 실행되는 것과 다른 프로젝트에 있는 경우 해당 데이터 세트의 프로젝트 ID를 입력합니다. 값을 제공하지 않으면 기본적으로 작업이 실행되는 프로젝트 ID가 사용됩니다. |
| 프로젝트 ID | 예 | 6.5.0 | Google Cloud 프로젝트 ID입니다. |
| 서비스 계정 유형 | 예 | 6.5.0 | 다음 옵션 중 하나를 선택합니다.
|
| 서비스 계정 파일 경로 | 예 | 6.5.0 | 로컬 파일 시스템에서 승인에 사용되는 서비스 계정 키의 경로입니다. Dataproc 클러스터에서 실행될 때 auto-detect로 설정됩니다. 다른 클러스터에서 실행되는 경우, 파일이 클러스터의 모든 노드에 있어야 합니다. 기본값은 auto-detect입니다. |
| 서비스 계정 JSON | 예 | 6.5.0 | 서비스 계정 JSON 파일의 콘텐츠입니다. |
| 임시 버킷 이름 | 예 | 6.5.0 | 임시 데이터를 저장하는 Cloud Storage 버킷입니다. 없으면 자동으로 생성되지만 자동으로 삭제되지는 않습니다. Cloud Storage 데이터는 BigQuery에 로드된 후 자동으로 삭제됩니다. 이 값이 제공되지 않았으면 고유 버킷이 생성된 후 파이프라인 실행이 완료된 후 삭제됩니다. 서비스 계정에는 구성된 프로젝트에 버킷을 만들 수 있는 권한이 있어야 합니다. |
| 위치 | 예 | 6.5.0 | BigQuery 데이터 세트가 생성되는 위치입니다.
데이터 세트 또는 임시 버킷이 이미 있으면 이 값이 무시됩니다. 기본값은 US 멀티 리전입니다. |
| 암호화 키 이름 | 예 | 6.5.1/0.18.1 | 플러그인으로 생성된 버킷, 데이터 세트, 테이블에 기록된 데이터를 암호화하는 고객 관리 암호화 키(CMEK)입니다. 버킷, 데이터 세트 또는 테이블이 이미 있으면 이 값이 무시됩니다. |
| 완료 후 BigQuery 테이블 보관 | 예 | 6.5.0 | 디버깅 및 검증 목적으로 파이프라인을 실행하는 동안 생성된 모든 BigQuery 임시 테이블을 보관할지 여부입니다. 기본값은 아니요입니다. |
| 임시 테이블 TTL(시간) | 예 | 6.5.0 | BigQuery 임시 테이블의 테이블 TTL을 시간 단위로 설정합니다. 파이프라인이 취소되고 삭제 프로세스가 중단되는 경우(실행 클러스터가 갑자기 종료되는 경우 등)의 안전 조치로 유용합니다. 이 값을 0으로 설정하면 테이블 TTL이 사용 중지됩니다. 기본값은 72(3일)입니다. |
| 작업 우선순위 | 예 | 6.5.0 | BigQuery 작업 실행에 사용되는 우선순위입니다. 다음 옵션 중 하나를 선택합니다.
|
| 푸시다운 강제 단계 | 예 | 6.7.0 | BigQuery에서 항상 실행되도록 지원되는 단계입니다. 각 단계 이름은 별도의 줄에 있어야 합니다. |
| 푸시다운을 건너뛰는 단계 | 예 | 6.7.0 | BigQuery에서 실행되지 않는 지원되는 단계 각 단계 이름은 별도의 줄에 있어야 합니다. |
| BigQuery Storage Read API 사용 | 예 | 6.7.0 | 파이프라인 실행 중 BigQuery에서 레코드를 추출할 때 BigQuery Storage Read API를 사용할지 여부입니다. 이 옵션은 변환 푸시다운 성능을 향상시켜 주지만 추가 비용이 발생합니다. 이를 위해서는 실행 환경에 Scala 2.12를 설치해야 합니다. |
로그에서 성능 변경사항 모니터링
파이프라인 런타임 로그에는 BigQuery에서 실행되는 SQL 쿼리를 보여주는 메시지가 포함됩니다. 파이프라인에서 BigQuery에 푸시되는 스테이지를 모니터링할 수 있습니다.
다음 예시는 파이프라인 실행이 시작될 때 로그 항목을 보여줍니다. 이 로그는 파이프라인에서 JOIN 작업이 실행되도록 BigQuery에 푸시다운되었음을 나타냅니다.
INFO [Driver:i.c.p.g.b.s.BigQuerySQLEngine@190] - Validating join for stage 'Users' can be executed on BigQuery: true
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@131] - Starting push for dataset 'UserProfile'
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@131] - Starting push for dataset 'UserDetails'
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@292] - Starting join for dataset 'Users'
INFO [Driver:i.c.p.g.b.s.BigQuerySQLEngine@190] - Validating join for stage 'UserPurchases' can be executed on BigQuery: true
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@131] - Starting push for dataset 'Purchases'
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@292] - Starting join for dataset 'UserPurchases'
INFO [Driver:i.c.p.g.b.s.BigQuerySQLEngine@190] - Validating join for stage 'MostPopularNames' can be executed on BigQuery: true
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@131] - Starting push for dataset 'FirstNameCounts'
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@292] - Starting join for dataset 'MostPopularNames'
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@193] - Starting pull for dataset 'MostPopularNames'
다음 예시는 푸시다운 실행에 관련된 각 데이터 세트에 할당되는 테이블 이름을 보여줍니다.
INFO [batch-sql-engine-adapter:i.c.p.g.b.s.BigQuerySQLEngine@145] - Executing Push operation for dataset Purchases stored in table <TABLE_ID>
INFO [batch-sql-engine-adapter:i.c.p.g.b.s.BigQuerySQLEngine@145] - Executing Push operation for dataset UserDetails stored in table <TABLE_ID>
INFO [batch-sql-engine-adapter:i.c.p.g.b.s.BigQuerySQLEngine@145] - Executing Push operation for dataset FirstNameCounts stored in table <TABLE_ID>
INFO [batch-sql-engine-adapter:i.c.p.g.b.s.BigQuerySQLEngine@145] - Executing Push operation for dataset UserProfile stored in table <TABLE_ID>
실행이 계속되면 로그에 푸시 스테이지 완료가 표시되고 결국 JOIN 작업 실행이 표시됩니다. 예를 들면 다음과 같습니다.
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@133] - Completed push for dataset 'UserProfile'
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@133] - Completed push for dataset 'UserDetails'
DEBUG [batch-sql-engine-adapter:i.c.p.g.b.s.BigQuerySQLEngine@235] - Executing join operation for dataset Users
INFO [batch-sql-engine-adapter:i.c.p.g.b.s.BigQueryJoinDataset@118] - Creating table `<TABLE_ID>` using job: <JOB_ID> with SQL statement: SELECT `UserDetails`.id AS `id` , `UserDetails`.first_name AS `first_name` , `UserDetails`.last_name AS `last_name` , `UserDetails`.email AS `email` , `UserProfile`.phone AS `phone` , `UserProfile`.profession AS `profession` , `UserProfile`.age AS `age` , `UserProfile`.address AS `address` , `UserProfile`.score AS `score` FROM `your_project.your_dataset.<DATASET_ID>` AS `UserProfile` LEFT JOIN `your_project.your_dataset.<DATASET_ID>` AS `UserDetails` ON `UserProfile`.id = `UserDetails`.id
INFO [batch-sql-engine-adapter:i.c.p.g.b.s.BigQueryJoinDataset@151] - Created BigQuery table `<TABLE_ID>
INFO [batch-sql-engine-adapter:i.c.p.g.b.s.BigQuerySQLEngine@245] - Executed join operation for dataset Users
모든 단계가 완료되었으면 Pull 작업이 완료되었다는 메시지가 표시됩니다. 이것은 BigQuery 내보내기 프로세스가 트리거되었고 이 내보내기 작업이 시작된 후 파이프라인으로 레코드 읽기가 시작됨을 나타냅니다. 예를 들면 다음과 같습니다.
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@196] - Completed pull for dataset 'MostPopularNames'
파이프라인 실행에 오류가 발생하면 로그에 기술됩니다.
리소스 활용률, 실행 시간, 오류 원인 등 BigQuery JOIN 작업 실행에 대한 자세한 내용을 보려면 작업 로그에 표시되는 작업 ID를 사용하여 BigQuery 작업 데이터를 확인할 수 있습니다.
파이프라인 측정항목 검토
Cloud Data Fusion이 BigQuery에서 실행되는 파이프라인 부분에 제공하는 측정항목에 대한 자세한 내용은 BigQuery 푸시다운 파이프라인 측정항목을 참조하세요.
다음 단계
- Cloud Data Fusion의 변환 푸시다운 자세히 알아보기