데이터 파이프라인 성능을 향상시키려면 Apache Spark 대신 BigQuery로 일부 변환 작업을 푸시하면 됩니다. 변환 푸시다운은 Cloud Data Fusion 데이터 파이프라인의 작업을 실행 엔진으로 BigQuery에 푸시할 수 있도록 하는 설정을 나타냅니다. 따라서 작업과 데이터가 BigQuery로 전송되고 작업이 수행됩니다.
변환 푸시다운은 여러 복잡한 JOIN 작업 또는 기타 지원되는 변환이 포함된 파이프라인의 성능을 향상시켜 줍니다. BigQuery에서 일부 변환을 실행하는 것이 Spark에서 실행하는 것보다 빠를 수 있습니다.
지원되지 않는 변환과 모든 미리보기 변환은 Spark에서 실행됩니다.
지원되는 변환
변환 푸시다운은 Cloud Data Fusion 버전 6.5.0 이상에서 사용할 수 있지만 다음 변환 중 일부는 이후 버전에서만 지원됩니다.
JOIN 작업
변환 푸시다운은 Cloud Data Fusion 버전 6.5.0 이상의
JOIN작업에 사용할 수 있습니다.기본(on-keys) 및 고급
JOIN작업이 지원됩니다.BigQuery에서 실행되기 위해서는 조인에 정확히 2개의 입력 단계가 있어야 합니다.
하나 이상의 입력을 메모리에 로드하도록 구성된 조인은 다음 경우를 제외하고 BigQuery 대신 Spark에서 실행됩니다.
- 조인에 대한 입력이 이미 푸시다운된 경우
- SQL Engine에서 실행되도록 조인을 구성한 경우(강제 실행 단계 참조)
BigQuery 싱크
변환 푸시다운은 Cloud Data Fusion 버전 6.7.0 이상의 BigQuery 싱크에 사용할 수 있습니다.
BigQuery 싱크가 BigQuery에서 실행된 단계를 따르는 경우 레코드를 BigQuery에 기록하는 작업이 BigQuery에서 직접 수행됩니다.
이 싱크의 성능을 향상시키려면 다음이 필요합니다.
- BigQuery 싱크에 사용되는 데이터 세트에서 테이블을 만들고 업데이트할 수 있는 권한이 서비스 계정에 있어야 합니다.
- 변환 푸시다운 및 BigQuery 싱크에 사용되는 데이터 세트가 동일한 위치에 저장되어야 합니다.
- 작업은 다음 중 하나여야 합니다.
Insert(Truncate Table옵션은 지원되지 않음)UpdateUpsert
GROUP BY 집계
변환 푸시다운은 Cloud Data Fusion 버전 6.7.0 이상의 GROUP BY 집계에 사용할 수 있습니다.
BigQuery의 GROUP BY 집계는 다음 작업에서 사용할 수 있습니다.
AvgCollect List(출력 배열에서 null 값이 삭제됨)Collect Set(출력 배열에서 null 값이 삭제됨)ConcatConcat DistinctCountCount DistinctCount NullsLogical AndLogical OrMaxMinStandard DeviationSumSum of SquaresCorrected Sum of SquaresVarianceShortest StringLongest String
GROUP BY 집계는 다음 경우에 BigQuery에서 실행됩니다.
- 이미 푸시다운된 단계를 따릅니다.
- SQL Engine에서 실행되도록 구성했습니다(강제 실행 단계 옵션 참조).
집계 중복 삭제
변환 푸시다운은 다음 작업에 대해 Cloud Data Fusion 버전 6.7.0 이상의 집계 중복 삭제에 사용할 수 있습니다.
- 필터 작업이 지정되지 않았습니다.
ANY(원하는 필드의 null이 아닌 값)MIN(지정된 필드의 최솟값)MAX(지정된 필드의 최댓값)
다음 작업은 지원되지 않습니다.
FIRSTLAST
집계 중복 삭제는 다음 경우에 SQL Engine에서 실행됩니다.
- 이미 푸시다운된 단계를 따릅니다.
- SQL Engine에서 실행되도록 구성했습니다(강제 실행 단계 옵션 참조).
BigQuery 소스 푸시다운
BigQuery 소스 푸시다운은 Cloud Data Fusion 버전 6.8.0 이상에서 사용할 수 있습니다.
BigQuery 소스가 BigQuery 푸시다운과 호환되는 단계를 따르는 경우 파이프라인은 BigQuery 내에서 호환되는 모든 단계를 실행할 수 있습니다.
Cloud Data Fusion은 BigQuery 내에서 파이프라인을 실행하는 데 필요한 레코드를 복사합니다.
BigQuery 소스 푸시다운을 사용하면 테이블 파티셔닝 및 클러스터링 속성이 보존되므로 이러한 속성을 사용하여 조인과 같은 추가 작업을 최적화할 수 있습니다.
기타 요구사항
BigQuery 소스 푸시다운을 사용하려면 다음 요구사항이 충족되어야 합니다.
BigQuery 변환 푸시다운용으로 구성된 서비스 계정에 BigQuery 소스 데이터 세트의 테이블을 읽을 수 있는 권한이 있어야 합니다.
BigQuery 소스에 사용된 데이터 세트와 변환 푸시다운용으로 구성된 데이터 세트는 동일한 위치에 저장되어야 합니다.
윈도우 집계
변환 푸시다운은 Cloud Data Fusion 버전 6.9 이상의 윈도우 집계에 사용할 수 있습니다. BigQuery의 윈도우 집계는 다음 작업에 지원됩니다.
RankDense RankPercent RankN tileRow NumberMedianContinuous PercentileLeadLagFirstLastCumulative distributionAccumulate
윈도우 집계는 다음 경우에 BigQuery에서 실행됩니다.
- 이미 푸시다운된 단계를 따릅니다.
- SQL Engine에서 실행되도록 구성했습니다 (강제 푸시다운 단계 옵션 참조).
Wrangler 필터 푸시다운
Cloud Data Fusion 버전 6.9 이상에서 Wrangler 필터 푸시다운을 사용할 수 있습니다.
Wrangler 플러그인을 사용하면 Spark 대신 BigQuery에서 실행되도록 Precondition 작업이라고 하는 필터를 푸시할 수 있습니다.
필터 푸시다운은 버전 6.9에서도 출시된 전제조건용 SQL 모드에서만 지원됩니다. 이 모드에서는 플러그인이 ANSI 표준 SQL의 전제조건 표현식을 허용합니다.
SQL 모드가 전제조건에 사용되는 경우 지시어와 사용자 정의 지시어가 SQL 모드의 전제조건에서 지원되지 않으므로 Wrangler 플러그인에서 중지됩니다.
변환 푸시다운이 사용 설정된 경우 여러 입력이 포함된 Wrangler 플러그인에서는 전제조건용 SQL 모드가 지원되지 않습니다. 여러 입력과 함께 사용할 경우 SQL 필터 조건이 있는 이 Wrangler 스테이지가 Spark에서 실행됩니다.
다음 경우에 BigQuery에서 필터가 실행됩니다.
- 이미 푸시다운된 단계를 따릅니다.
- SQL Engine에서 실행되도록 구성했습니다 (강제 푸시다운 단계 옵션 참조).
측정항목
Cloud Data Fusion이 BigQuery에서 실행되는 파이프라인 부분에 제공하는 측정항목에 대한 자세한 내용은 BigQuery 푸시다운 파이프라인 측정항목을 참조하세요.
변환 푸시다운을 사용해야 하는 경우
BigQuery에서 변환을 실행하려면 다음이 필요합니다.
- 파이프라인에서 지원되는 단계에 대해 BigQuery에 레코드를 기록합니다.
- BigQuery에서 지원되는 단계를 실행합니다.
- BigQuery 싱크에서 수행되지 않는 한 지원되는 변환이 실행된 후 BigQuery에서 레코드를 읽습니다.
데이터 세트 크기에 따라 상당한 네트워크 오버헤드가 발생하여 변환 푸시다운이 사용 설정되었을 때 전반적인 파이프라인 실행 시간에 부정적인 영향을 줄 수 있습니다.
네트워크 오버헤드로 인해 다음 경우에 변환 푸시다운이 권장됩니다.
- 지원되는 여러 작업이 순차적으로 실행됩니다(스테이지 간 단계 없음).
- Spark와 비교해서 변환을 실행하는 동안 BigQuery로 얻는 성능 이점이 BigQuery로 들어오고 나가는 데이터 이동으로 인한 지연 시간보다 큽니다.
작동 방식
변환 푸시다운을 사용하는 파이프라인을 실행하는 경우 Cloud Data Fusion이 BigQuery에서 지원되는 변환 단계를 실행합니다. 파이프라인의 다른 모든 단계는 Spark에서 실행됩니다.
변환 실행 시:
Cloud Data Fusion이 입력 데이터 세트를 BigQuery에 로드합니다(Cloud Storage에 레코드를 작성한 후 BigQuery 로드 작업 실행).
그런 후
JOIN작업 및 지원되는 변환이 SQL 문을 사용하여 BigQuery 작업으로 실행됩니다.작업 실행 후 추가 처리가 필요하면 BigQuery에서 Spark로 레코드를 내보낼 수 있습니다. 하지만 BigQuery 싱크에 직접 복사 시도 옵션이 사용 설정되었고 BigQuery 싱크가 BigQuery에서 실행된 단계를 따르는 경우 레코드가 대상 BigQuery 싱크 테이블에 직접 기록됩니다.
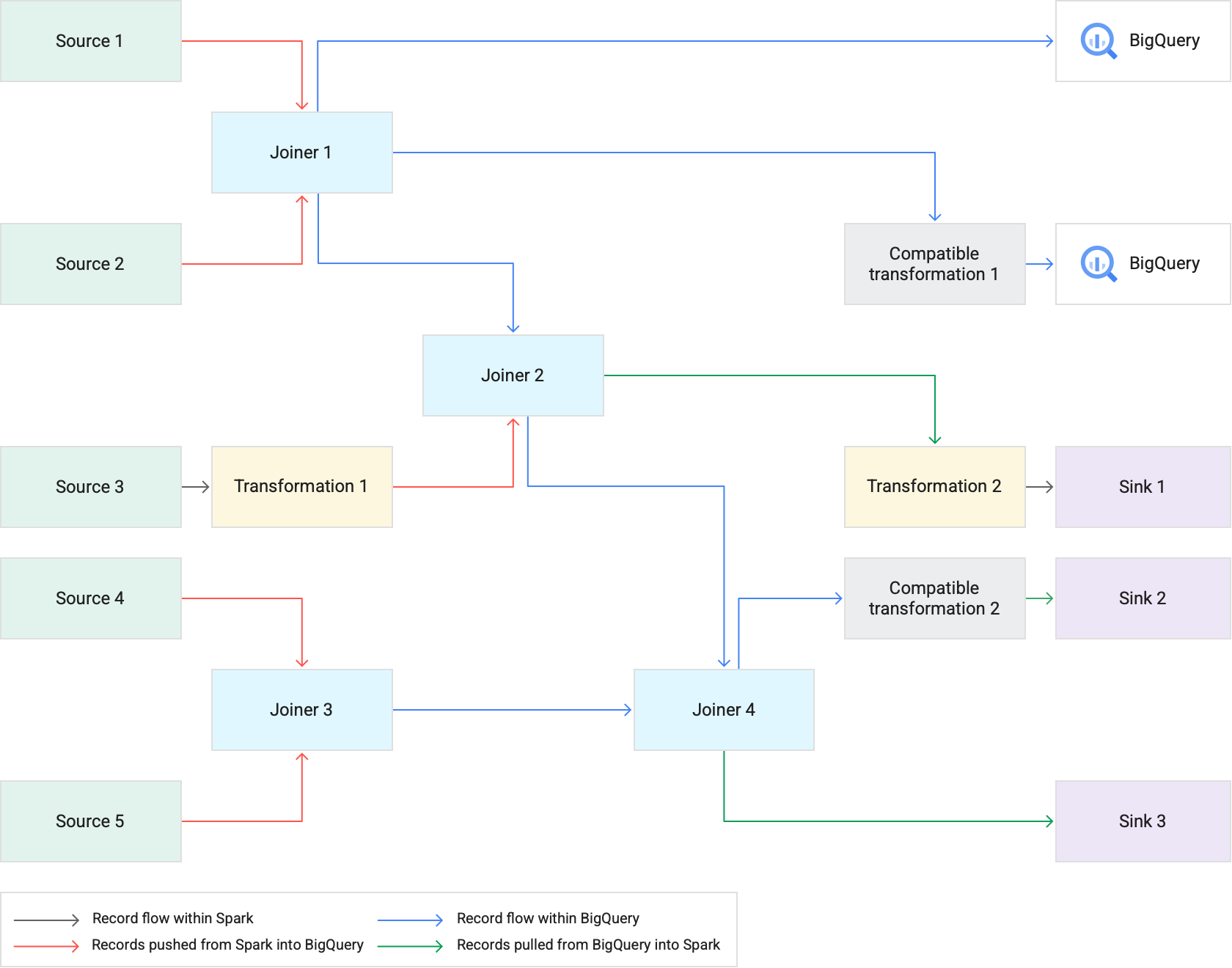
다음 다이어그램은 Spark 대신 BigQuery에서 변환 푸시다운이 지원되는 변환을 수행하는 방법을 보여줍니다.
권장사항
클러스터 및 실행자 크기 조정
파이프라인에서 리소스 관리를 최적화하려면 다음을 수행합니다.
워크로드에 대해 적절한 개수의 클러스터 작업자(노드)를 사용합니다. 즉, 인스턴스에 사용 가능한 CPU 및 메모리를 완전히 활용해서 프로비저닝된 Dataproc 클러스터를 최대한 활용하고, 대규모 작업에 대한 BigQuery의 실행 속도 이점도 활용합니다.
자동 확장 클러스터를 사용하여 파이프라인에서 동시 로드를 향상시킵니다.
파이프라인 실행 중 BigQuery에서 레코드를 가져오고 내보내는 파이프라인의 스테이지에서 리소스 구성을 조정합니다.
권장: 실행자 리소스에 대해 CPU 코어 수를 늘려서 실험을 진행합니다(워커 노드에 사용되는 최대 CPU 코어 수까지). 실행자는 BigQuery에서 데이터가 들어오고 나가는 직렬화 및 역직렬화 단계 중 CPU 사용을 최적화합니다. 자세한 내용은 클러스터 크기 조정을 참조하세요.
BigQuery에서 변환을 실행할 때의 이점은 파이프라인이 더 작은 Dataproc 클러스터에서 실행될 수 있다는 것입니다. 조인이 파이프라인에서 리소스 소비가 가장 큰 작업인 경우 이제 BigQuery에서 큰 JOIN 작업이 수행되므로 더 작은 클러스터 크기로 실험을 하면서 전반적으로 컴퓨팅 비용을 줄일 수 있습니다.
BigQuery Storage Read API를 사용하여 데이터를 빠르게 검색
BigQuery가 변환을 실행한 후에는 파이프라인에 Spark에서 실행할 추가 단계가 있을 수 있습니다. Cloud Data Fusion 버전 6.7.0 이상에서 변환 푸시다운은 지연 시간을 개선하고 Spark로 읽기 작업을 더 빠르게 수행할 수 있게 해주는 BigQuery Storage Read API를 지원합니다. 전반적으로 파이프라인 실행 시간을 줄일 수 있습니다.
API가 레코드 읽기를 병렬로 수행하므로 실행자 크기를 그에 맞게 조정하는 것이 좋습니다. 리소스 소비가 높은 작업을 BigQuery에서 실행할 경우 파이프라인이 실행될 때 동시 로드 성능을 개선하기 위해 실행자의 메모리 할당을 줄입니다 (클러스터 및 실행자 크기 조정 참고).
BigQuery Storage Read API는 기본적으로 사용 중지됩니다. Scala 2.12가 설치된 실행 환경에서 이를 사용 설정할 수 있습니다(Dataproc 2.0 및 Dataproc 1.5 포함).
데이터 세트 크기 고려
JOIN 작업에서 데이터 세트 크기를 고려합니다. JOIN 교차 작업과 같이 상당한 개수의 출력 레코드를 생성하는 JOIN 작업의 경우 결과 데이터 세트 크기는 입력 데이터 세트보다 몇 배 더 클 수 있습니다. 또한 변환 또는 싱크와 같이 이러한 레코드에 대한 추가적인 Spark 처리가 전반적인 파이프라인 성능 측면에서 발생하는 경우 이러한 레코드를 Spark로 가져올 때의 오버헤드를 고려해야 합니다.
왜곡된 데이터 완화
과도하게 왜곡된 데이터에 대해 JOIN 작업을 수행하면 BigQuery 작업이 리소스 활용률 한도를 초과해서 수행되고, 그 결과 JOIN 작업이 실패할 수 있습니다. 이를 방지하려면 연결자 플러그인 설정으로 이동하고 왜곡된 입력 단계 필드에서 왜곡된 입력을 식별합니다. 이렇게 하면 BigQuery 문이 한도를 초과할 위험을 줄이는 방식으로 Cloud Data Fusion에서 입력이 조정됩니다.