Questa pagina descrive come eseguire trasformazioni in BigQuery invece che in Spark in Cloud Data Fusion.
Per ulteriori informazioni, consulta la sezione Panoramica del pushdown delle trasformazioni.
Prima di iniziare
La trasformazione Pushdown è disponibile nella versione 6.5.0 e successive. Se la pipeline viene eseguita in un ambiente precedente, puoi eseguire l'upgrade dell'istanza alla versione più recente.
Attivare il trasferimento delle trasformazioni nella pipeline
Console
Per attivare il pushdown delle trasformazioni in una pipeline di cui è stato eseguito il deployment:
Vai all'istanza:
Nella console Google Cloud, vai alla pagina Cloud Data Fusion.
Per aprire l'istanza in Cloud Data Fusion Studio, fai clic su Istanze e poi su Visualizza istanza.
Fai clic su Menu > Elenco.
Si apre la scheda della pipeline di cui è stato eseguito il deployment.
Fai clic sulla pipeline di cui vuoi eseguire il deployment per aprirla in Pipeline Studio.
Fai clic su Configura > Trasferimento delle trasformazioni.
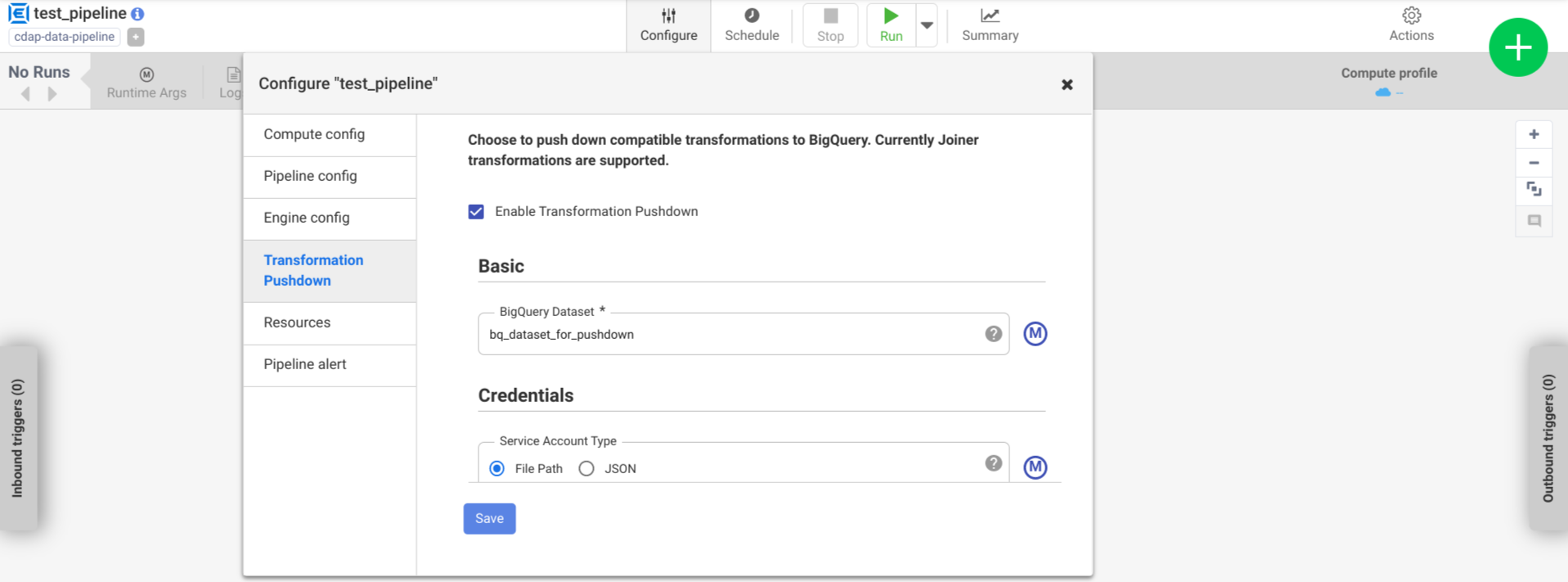
Fai clic su Attiva il trasferimento delle trasformazioni.
Nel campo Set di dati, inserisci il nome di un set di dati BigQuery.
(Facoltativo) Per utilizzare una macro, fai clic su M. Per ulteriori informazioni, consulta Set di dati.
(Facoltativo) Configura le opzioni, se necessario.
Fai clic su Salva.
Configurazioni facoltative
.| Proprietà | Supporta le macro | Versioni di Cloud Data Fusion supportate | Descrizione |
|---|---|---|---|
| Utilizza la connessione | No | 6.7.0 e versioni successive | Se utilizzare una connessione esistente. |
| Connessione | Sì | 6.7.0 e versioni successive | Il nome della connessione. Questa connessione fornisce informazioni sul progetto e sull'account di servizio. (Facoltativo) Utilizza la funzione della macro ${conn(connection_name)}. |
| ID progetto del set di dati | Sì | 6.5.0 | Se il set di dati si trova in un progetto diverso da quello in cui viene eseguito il job BigQuery, inserisci l'ID progetto del set di dati. Se non viene fornito alcun valore, per impostazione predefinita viene utilizzato l'ID progetto in cui viene eseguito il job. |
| ID progetto | Sì | 6.5.0 | L' Google Cloud ID progetto. |
| Tipo di account di servizio | Sì | 6.5.0 | Seleziona una delle seguenti opzioni:
|
| Percorso del file dell'account di servizio | Sì | 6.5.0 | Il percorso nel file system locale della chiave dell'account di servizio utilizzata per l'autorizzazione. È impostato su auto-detect quando viene eseguito su un cluster Dataproc. Quando viene eseguito su altri cluster,
il file deve essere presente su ogni nodo del cluster. Il valore predefinito è
auto-detect. |
| JSON del service account | Sì | 6.5.0 | I contenuti del file JSON dell'account di servizio. |
| Nome bucket temporaneo | Sì | 6.5.0 | Il bucket Cloud Storage che memorizza i dati temporanei. Viene creato automaticamente se non esiste, ma non viene eliminato automaticamente. I dati di Cloud Storage vengono eliminati dopo essere stati caricati in BigQuery. Se non viene fornito questo valore, viene creato un bucket univoco che viene eliminato al termine dell'esecuzione della pipeline. L'account di servizio deve avere l'autorizzazione per creare bucket nel progetto configurato. |
| Località | Sì | 6.5.0 | La posizione in cui viene creato il set di dati BigQuery.
Questo valore viene ignorato se il set di dati o il bucket temporaneo esiste già. Il valore predefinito è la regione multipla US. |
| Nome chiave di crittografia | Sì | 6.5.1/0.18.1 | La chiave di crittografia gestita dal cliente (CMEK) che cripta i datiscritti in qualsiasi bucket, set di dati o tabella creato dal plug-in. Se il bucket, il set di dati o la tabella esistente, questo valore viene ignorato. |
| Mantieni le tabelle BigQuery al termine | Sì | 6.5.0 | Indica se conservare tutte le tabelle temporanee BigQuery create durante l'esecuzione della pipeline a scopo di debugging e convalida. Il valore predefinito è No. |
| TTL della tabella temporanea (in ore) | Sì | 6.5.0 | Imposta il TTL della tabella per le tabelle temporanee BigQuery in ore. Questo è utile come misura di sicurezza nel caso in cui la pipeline venga annullata e il processo di pulizia venga interrotto (ad esempio se il cluster di esecuzione viene arrestato bruscamente). Se imposti questo valore su
0, il TTL della tabella viene disattivato. Il valore predefinito è
72 (3 giorni). |
| Priorità job | Sì | 6.5.0 | La priorità utilizzata per eseguire i job BigQuery. Seleziona una delle seguenti opzioni:
|
| Fasi per forzare il pushdown | Sì | 6.7.0 | Fasi supportate da eseguire sempre in BigQuery. Ogni nome di fase deve essere inserito in una riga distinta. |
| Fasi per saltare il pushdown | Sì | 6.7.0 | Fasi supportate da non eseguire mai in BigQuery. Ogni nome di fase deve essere inserito in una riga distinta. |
| Utilizzare l'API BigQuery Storage di lettura | Sì | 6.7.0 | Indica se utilizzare l'API BigQuery Storage di lettura per estrarre i record da BigQuery durante l'esecuzione della pipeline. Questa opzione può migliorare le prestazioni del trasferimento delle trasformazioni, ma comporta costi aggiuntivi. Per farlo, è necessario installare Scala 2.12 nell'ambiente di esecuzione. |
Monitorare le variazioni del rendimento nei log
I log di runtime della pipeline includono messaggi che mostrano le query SQL eseguite in BigQuery. Puoi monitorare le fasi della pipeline che vengono messe in BigQuery.
L'esempio seguente mostra le voci di log all'inizio dell'esecuzione della pipeline. I log indicano che le operazioni JOIN nella pipeline sono state spostate in BigQuery per l'esecuzione:
INFO [Driver:i.c.p.g.b.s.BigQuerySQLEngine@190] - Validating join for stage 'Users' can be executed on BigQuery: true
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@131] - Starting push for dataset 'UserProfile'
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@131] - Starting push for dataset 'UserDetails'
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@292] - Starting join for dataset 'Users'
INFO [Driver:i.c.p.g.b.s.BigQuerySQLEngine@190] - Validating join for stage 'UserPurchases' can be executed on BigQuery: true
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@131] - Starting push for dataset 'Purchases'
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@292] - Starting join for dataset 'UserPurchases'
INFO [Driver:i.c.p.g.b.s.BigQuerySQLEngine@190] - Validating join for stage 'MostPopularNames' can be executed on BigQuery: true
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@131] - Starting push for dataset 'FirstNameCounts'
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@292] - Starting join for dataset 'MostPopularNames'
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@193] - Starting pull for dataset 'MostPopularNames'
L'esempio seguente mostra i nomi delle tabelle che verranno assegnati a ciascuno dei set di dati coinvolti nell'esecuzione del push-down:
INFO [batch-sql-engine-adapter:i.c.p.g.b.s.BigQuerySQLEngine@145] - Executing Push operation for dataset Purchases stored in table <TABLE_ID>
INFO [batch-sql-engine-adapter:i.c.p.g.b.s.BigQuerySQLEngine@145] - Executing Push operation for dataset UserDetails stored in table <TABLE_ID>
INFO [batch-sql-engine-adapter:i.c.p.g.b.s.BigQuerySQLEngine@145] - Executing Push operation for dataset FirstNameCounts stored in table <TABLE_ID>
INFO [batch-sql-engine-adapter:i.c.p.g.b.s.BigQuerySQLEngine@145] - Executing Push operation for dataset UserProfile stored in table <TABLE_ID>
Man mano che l'esecuzione continua, i log mostrano il completamento delle fasi di push e, eventualmente, l'esecuzione delle operazioni JOIN. Ad esempio:
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@133] - Completed push for dataset 'UserProfile'
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@133] - Completed push for dataset 'UserDetails'
DEBUG [batch-sql-engine-adapter:i.c.p.g.b.s.BigQuerySQLEngine@235] - Executing join operation for dataset Users
INFO [batch-sql-engine-adapter:i.c.p.g.b.s.BigQueryJoinDataset@118] - Creating table `<TABLE_ID>` using job: <JOB_ID> with SQL statement: SELECT `UserDetails`.id AS `id` , `UserDetails`.first_name AS `first_name` , `UserDetails`.last_name AS `last_name` , `UserDetails`.email AS `email` , `UserProfile`.phone AS `phone` , `UserProfile`.profession AS `profession` , `UserProfile`.age AS `age` , `UserProfile`.address AS `address` , `UserProfile`.score AS `score` FROM `your_project.your_dataset.<DATASET_ID>` AS `UserProfile` LEFT JOIN `your_project.your_dataset.<DATASET_ID>` AS `UserDetails` ON `UserProfile`.id = `UserDetails`.id
INFO [batch-sql-engine-adapter:i.c.p.g.b.s.BigQueryJoinDataset@151] - Created BigQuery table `<TABLE_ID>
INFO [batch-sql-engine-adapter:i.c.p.g.b.s.BigQuerySQLEngine@245] - Executed join operation for dataset Users
Al termine di tutte le fasi, viene visualizzato un messaggio che indica che l'operazione Pull è stata completata. Ciò indica che la procedura di esportazione di BigQuery è stata attivata e che i record inizieranno a essere letti nella pipeline dopo l'avvio di questo job di esportazione. Ad esempio:
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@196] - Completed pull for dataset 'MostPopularNames'
Se l'esecuzione della pipeline rileva errori, questi vengono descritti nei log.
Per informazioni dettagliate sull'esecuzione delle operazioni JOIN
di BigQuery, come l'utilizzo delle risorse, il tempo di esecuzione e le cause degli errori,
puoi visualizzare i dati del job BigQuery utilizzando l'ID job, visualizzato
nei log del job.
Esamina le metriche della pipeline
Per ulteriori informazioni sulle metriche fornite da Cloud Data Fusion per la parte della pipeline eseguita in BigQuery, consulta Metriche della pipeline pushdown di BigQuery.
Passaggi successivi
- Scopri di più sul pushdown delle trasformazioni in Cloud Data Fusion.