Nesta página, descrevemos como executar transformações no BigQuery em vez do Spark no Cloud Data Fusion.
Para mais informações, consulte a Visão geral do pushdown de transformação.
Antes de começar
O pushdown de transformação está disponível na versão 6.5.0 e mais recente. Se o pipeline for executado em um ambiente de versão anterior, será possível fazer upgrade da instância para a versão mais recente.
Ativar o pushdown de transformação no pipeline
Console
Para ativar o pushdown de transformação em um pipeline implantado, faça o seguinte:
Acesse sua instância:
No console do Google Cloud, acesse a página do Cloud Data Fusion.
Para abrir a instância no Cloud Data Fusion Studio, clique em Instâncias e em Ver instância.
Clique em Menu > Lista.
A guia do pipeline implantado é aberta.
Clique no pipeline implantado desejado para abri-lo no Pipeline Studio.
Clique em Configurar > Pushdown de transformação.
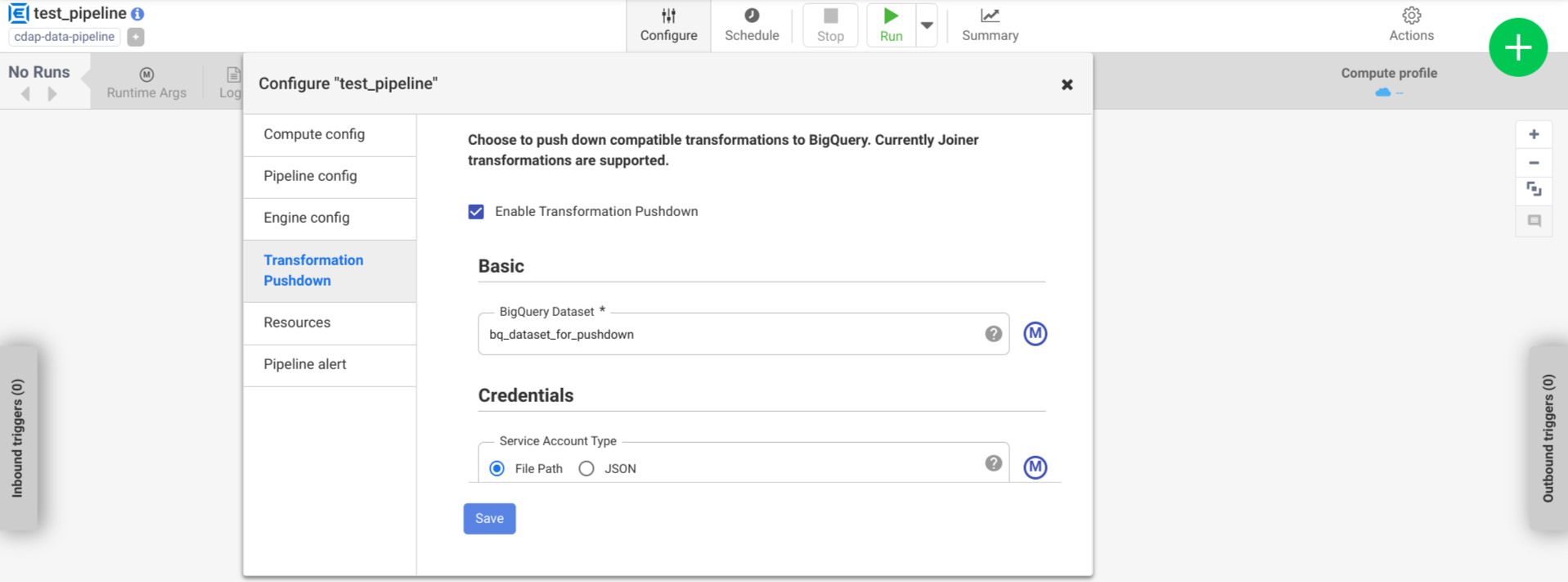
Clique em Ativar pushdown de transformação.
No campo Conjunto de dados, insira um nome de conjunto de dados do BigQuery.
Opcional: para usar uma macro, clique em M. Para mais informações, consulte Conjuntos de dados.
Opcional: configure as opções, se necessário.
Clique em Salvar.
Configurações opcionais
.| Propriedade | Suporte a macros | Versões do Cloud Data Fusion com suporte | Descrição |
|---|---|---|---|
| Usar conexão | Não | 6.7.0 e versões mais recentes | Se é possível usar uma conexão existente. |
| Conexão | Sim | 6.7.0 e versões mais recentes | O nome da conexão. Essa conexão fornece informações sobre o projeto e a conta de serviço. Opcional: use a função macro ${conn(connection_name)}. |
| ID do projeto do conjunto de dados | Sim | 6.5.0 | Se o conjunto de dados estiver em um projeto diferente daquele em que o job do BigQuery é executado, insira o ID do projeto do conjunto de dados. Se nenhum valor for fornecido, por padrão, será usado o ID do projeto em que o job é executado. |
| ID do projeto | Sim | 6.5.0 | O ID do projeto Google Cloud . |
| Tipo de conta de serviço | Sim | 6.5.0 | Selecione uma das seguintes opções:
|
| Caminho do arquivo da conta de serviço | Sim | 6.5.0 | O caminho no sistema de arquivos local para a chave da conta de serviço usada
para autorização. Ele é definido como auto-detect ao ser executado
em um cluster do Dataproc. Ao ser executado em outros clusters,
o arquivo precisa estar presente em cada nó do cluster. O padrão é auto-detect. |
| JSON da conta de serviço | Sim | 6.5.0 | O conteúdo do arquivo JSON da conta de serviço. |
| Nome do bucket temporário | Sim | 6.5.0 | O bucket do Cloud Storage que armazena os dados temporários. Ele é criado automaticamente se não existir, mas não é excluído automaticamente. Os dados do Cloud Storage são excluídos depois de carregados no BigQuery. Se esse valor não for fornecido, um bucket exclusivo será criado e excluído após a conclusão da execução do pipeline. A conta de serviço precisa ter permissão para criar buckets no projeto configurado. |
| Local | Sim | 6.5.0 | O local em que o conjunto de dados do BigQuery é criado.
Esse valor será ignorado se o conjunto de dados ou o bucket temporário já existir. O padrão é a
multirregião
US. |
| Nome da chave de criptografia | Sim | 6.5.1/0.18.1 | A chave de criptografia gerenciada pelo cliente (CMEK) que criptografa os dados gravados em qualquer bucket, conjunto de dados ou tabela criado pelo plug-in. Se o bucket, o conjunto de dados ou a tabela já existir, esse valor será ignorado. |
| Reter tabelas do BigQuery após a conclusão | Sim | 6.5.0 | Define se todas as tabelas temporárias do BigQuery criadas durante a execução do pipeline são retidas para fins de depuração e validação. O padrão é Não. |
| TTL da tabela temporária (em horas) | Sim | 6.5.0 | Defina o TTL da tabela para tabelas temporárias do BigQuery em horas. Isso é útil como uma medida de segurança caso o pipeline seja
cancelado e o processo de limpeza seja interrompido, por exemplo, se
o cluster de execução for desligado abruptamente. Definir esse valor como
0 desativa o TTL da tabela. O padrão é
72 (3 dias). |
| Prioridade de job | Sim | 6.5.0 | A prioridade usada para executar jobs do BigQuery. Selecione
uma das seguintes opções:
|
| Estágios para forçar a inclusão | Sim | 6.7.0 | Estágios com suporte para execução sempre no BigQuery. Cada nome de fase precisa estar em uma linha separada. |
| Etapas para pular a pushdown | Sim | 6.7.0 | Fases com suporte que nunca serão executadas no BigQuery. Cada nome de fase precisa estar em uma linha separada. |
| Usar a API BigQuery Storage Read | Sim | 6.7.0 | Indica se a API BigQuery Storage Read será usada ao extrair registros do BigQuery durante a execução do pipeline. Essa opção pode melhorar o desempenho da transformação pushdown, mas gera custos adicionais. Isso requer que o Scala 2.12 seja instalado no ambiente de execução. |
Monitorar as alterações no desempenho dos registros
Os registros do ambiente de execução do pipeline incluem mensagens que mostram as consultas do SQL executadas no BigQuery. É possível monitorar quais estágios do pipeline são enviados ao BigQuery.
O exemplo a seguir mostra as entradas de registro quando a execução do pipeline começa. Os
registros indicam que as operações JOIN no seu pipeline foram enviadas para o BigQuery
para execução:
INFO [Driver:i.c.p.g.b.s.BigQuerySQLEngine@190] - Validating join for stage 'Users' can be executed on BigQuery: true
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@131] - Starting push for dataset 'UserProfile'
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@131] - Starting push for dataset 'UserDetails'
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@292] - Starting join for dataset 'Users'
INFO [Driver:i.c.p.g.b.s.BigQuerySQLEngine@190] - Validating join for stage 'UserPurchases' can be executed on BigQuery: true
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@131] - Starting push for dataset 'Purchases'
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@292] - Starting join for dataset 'UserPurchases'
INFO [Driver:i.c.p.g.b.s.BigQuerySQLEngine@190] - Validating join for stage 'MostPopularNames' can be executed on BigQuery: true
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@131] - Starting push for dataset 'FirstNameCounts'
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@292] - Starting join for dataset 'MostPopularNames'
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@193] - Starting pull for dataset 'MostPopularNames'
O exemplo a seguir mostra os nomes das tabelas que serão atribuídos a cada um dos conjuntos de dados envolvidos na execução do pushdown:
INFO [batch-sql-engine-adapter:i.c.p.g.b.s.BigQuerySQLEngine@145] - Executing Push operation for dataset Purchases stored in table <TABLE_ID>
INFO [batch-sql-engine-adapter:i.c.p.g.b.s.BigQuerySQLEngine@145] - Executing Push operation for dataset UserDetails stored in table <TABLE_ID>
INFO [batch-sql-engine-adapter:i.c.p.g.b.s.BigQuerySQLEngine@145] - Executing Push operation for dataset FirstNameCounts stored in table <TABLE_ID>
INFO [batch-sql-engine-adapter:i.c.p.g.b.s.BigQuerySQLEngine@145] - Executing Push operation for dataset UserProfile stored in table <TABLE_ID>
Conforme a execução continua, os registros mostram a conclusão dos estágios de push e,
eventualmente, a execução de operações JOIN. Exemplo:
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@133] - Completed push for dataset 'UserProfile'
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@133] - Completed push for dataset 'UserDetails'
DEBUG [batch-sql-engine-adapter:i.c.p.g.b.s.BigQuerySQLEngine@235] - Executing join operation for dataset Users
INFO [batch-sql-engine-adapter:i.c.p.g.b.s.BigQueryJoinDataset@118] - Creating table `<TABLE_ID>` using job: <JOB_ID> with SQL statement: SELECT `UserDetails`.id AS `id` , `UserDetails`.first_name AS `first_name` , `UserDetails`.last_name AS `last_name` , `UserDetails`.email AS `email` , `UserProfile`.phone AS `phone` , `UserProfile`.profession AS `profession` , `UserProfile`.age AS `age` , `UserProfile`.address AS `address` , `UserProfile`.score AS `score` FROM `your_project.your_dataset.<DATASET_ID>` AS `UserProfile` LEFT JOIN `your_project.your_dataset.<DATASET_ID>` AS `UserDetails` ON `UserProfile`.id = `UserDetails`.id
INFO [batch-sql-engine-adapter:i.c.p.g.b.s.BigQueryJoinDataset@151] - Created BigQuery table `<TABLE_ID>
INFO [batch-sql-engine-adapter:i.c.p.g.b.s.BigQuerySQLEngine@245] - Executed join operation for dataset Users
Quando todos os estágios forem concluídos, uma mensagem vai mostrar que a operação Pull foi
concluída. Isso indica que o processo de exportação do BigQuery
foi acionado e os registros começarão a ser lidos no
pipeline após o início desse job de exportação. Exemplo:
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@196] - Completed pull for dataset 'MostPopularNames'
Se a execução do pipeline encontrar erros, eles serão descritos nos registros.
Para detalhes sobre a execução das operações JOIN
do BigQuery, como utilização de recursos, tempo de execução e causas de erros,
é possível conferir os dados do job do BigQuery usando o ID do job, que aparece nos
registros do job.
Analisar as métricas do pipeline
Para mais informações sobre as métricas que o Cloud Data Fusion fornece para a parte do pipeline executada no BigQuery, consulte Métricas do pipeline de pushdown do BigQuery.
A seguir
- Saiba mais sobre o pushdown de transformação no Cloud Data Fusion.