Per migliorare le prestazioni delle pipeline di dati, puoi inviare alcune operazioni di trasformazione a BigQuery anziché ad Apache Spark. Il pushdown delle trasformazioni si riferisce a un'impostazione che consente di inviare un'operazione in una pipeline di dati di Cloud Data Fusion a BigQuery come motore di esecuzione. Di conseguenza, l'operazione e i relativi dati vengono trasferiti a BigQuery, dove viene eseguita l'operazione.
La trasformazione Pushdown migliora le prestazioni delle pipeline che hanno più operazioni JOIN complesse o altre trasformazioni supportate. L'esecuzione di alcune trasformazioni in
BigQuery potrebbe essere più rapida rispetto all'esecuzione in Spark.
Le trasformazioni non supportate e tutte le trasformazioni di anteprima vengono eseguite in Spark.
Trasformazioni supportate
Il trasferimento delle trasformazioni è disponibile in Cloud Data Fusion 6.5.0 e versioni successive, ma alcune delle seguenti trasformazioni sono supportate solo nelle versioni successive.
JOIN operazioni
Il trasferimento delle trasformazioni è disponibile per le operazioni
JOINin Cloud Data Fusion 6.5.0 e versioni successive.Sono supportate le operazioni
JOINdi base (on-key) e avanzate.Le unioni devono avere esattamente due fasi di input per l'esecuzione in BigQuery.
Le unioni configurate per caricare uno o più input in memoria vengono eseguite in Spark anziché in BigQuery, tranne nei seguenti casi:
- Se uno degli input dell'unione è già stato spostato verso il basso.
- Se hai configurato l'unione per l'esecuzione in SQL Engine (vedi l'opzione Fasi per forzare l'esecuzione).
Sink BigQuery
Il pushdown delle trasformazioni è disponibile per l'emissario BigQuery in Cloud Data Fusion versione 6.7.0 e successive.
Quando l'eseguione di BigQuery segue una fase eseguita in BigQuery, l'operazione che scrive i record in BigQuery viene eseguita direttamente in BigQuery.
Per migliorare le prestazioni con questo sink, devi disporre di quanto segue:
- L'account di servizio deve avere l'autorizzazione per creare e aggiornare le tabelle nel set di dati utilizzato dall'esegui operazione in BigQuery.
- I set di dati utilizzati per la trasformazione pushdown e il sink BigQuery devono essere archiviati nella stessa posizione.
- L'operazione deve essere una delle seguenti:
Insert(l'opzioneTruncate Tablenon è supportata)UpdateUpsert
GROUP BY aggregazioni
La trasformazione Pushdown è disponibile per le aggregazioni GROUP BY in Cloud Data Fusion 6.7.0 e versioni successive.
Le aggregazioni GROUP BY in BigQuery sono disponibili per le seguenti operazioni:
AvgCollect List(i valori null vengono rimossi dall'array di output)Collect Set(i valori null vengono rimossi dall'array di output)ConcatConcat DistinctCountCount DistinctCount NullsLogical AndLogical OrMaxMinStandard DeviationSumSum of SquaresCorrected Sum of SquaresVarianceShortest StringLongest String
Le aggregazioni GROUP BY vengono eseguite in BigQuery nei seguenti
casi:
- Segue una fase che è già stata spostata verso il basso.
- L'hai configurato per l'esecuzione in SQL Engine (vedi l'opzione Fasi per forzare l'esecuzione).
Aggregazioni deduplicate
Il pushdown delle trasformazioni è disponibile per le aggregazioni deduplicati in Cloud Data Fusion versione 6.7.0 e successive per le seguenti operazioni:
- Nessuna operazione di filtro specificata
ANY(un valore non nullo per il campo desiderato)MIN(il valore minimo per il campo specificato)MAX(il valore massimo per il campo specificato)
Le seguenti operazioni non sono supportate:
FIRSTLAST
Le aggregazioni deduplicative vengono eseguite nel motore SQL nei seguenti casi:
- Segue una fase che è già stata spostata verso il basso.
- L'hai configurato per l'esecuzione in SQL Engine (vedi l'opzione Fasi per forzare l'esecuzione).
Pushdown delle origini BigQuery
Il pushdown delle origini BigQuery è disponibile nelle versioni 6.8.0 e successive di Cloud Data Fusion.
Quando un'origine BigQuery segue una fase compatibile per il pushdown di BigQuery, la pipeline può eseguire tutte le fasi compatibili all'interno di BigQuery.
Cloud Data Fusion copia i record necessari per eseguire la pipeline in BigQuery.
Quando utilizzi BigQuery Source Pushdown, le proprietà di partizione e clustering delle tabelle vengono conservate, il che ti consente di utilizzarle per ottimizzare ulteriori operazioni, come le unioni.
Requisiti aggiuntivi
Per utilizzare il pushdown dell'origine BigQuery, devono essere soddisfatti i seguenti requisiti:
L'account di servizio configurato per BigQuery Pushdown delle trasformazioni deve disporre delle autorizzazioni per leggere le tabelle nel set di dati dell'origine BigQuery.
I set di dati utilizzati nell'origine BigQuery e il set di dati configurato per il pushdown delle trasformazioni devono essere archiviati nella stessa posizione.
Aggregazioni delle finestre
La trasformazione Pushdown è disponibile per le aggregazioni delle finestre in Cloud Data Fusion 6.9 e versioni successive. Le aggregazioni delle finestre in BigQuery sono supportate per le seguenti operazioni:
RankDense RankPercent RankN tileRow NumberMedianContinuous PercentileLeadLagFirstLastCumulative distributionAccumulate
Le aggregazioni delle finestre vengono eseguite in BigQuery nei seguenti casi:
- Segue una fase che è già stata spostata verso il basso.
- L'hai configurato per l'esecuzione in SQL Engine (vedi l'opzione Fasi per forzare il pushdown).
Filtro pushdown di Wrangler
La funzionalità di trasferimento dei filtri di Wrangler è disponibile nelle versioni Cloud Data Fusion 6.9 e successive.
Quando utilizzi il plug-in Wrangler, puoi inviare i filtri, noti come Precondition
operazioni, da eseguire in BigQuery anziché in Spark.
Il pushdown dei filtri è supportato solo con la modalità SQL per Precondizioni, che è stata rilasciata anche nella versione 6.9. In questa modalità, il plug-in accetta un'espressione di precondizione in SQL standard ANSI.
Se la modalità SQL viene utilizzata per i prerequisiti, le Directives e le User Defined Directives sono disattivate per il plug-in Wrangler, in quanto non sono supportate con i prerequisiti in modalità SQL.
La modalità SQL per i prerequisiti non è supportata per i plug-in Wrangler con più input quando è attivata la trasformazione pushdown. Se utilizzata con più input, questa fase di Wrangler con condizioni di filtro SQL viene eseguita in Spark.
I filtri vengono eseguiti in BigQuery nei seguenti casi:
- Segue una fase che è già stata spostata verso il basso.
- L'hai configurato per l'esecuzione in SQL Engine (vedi l'opzione Fasi per forzare il pushdown).
Metriche
Per ulteriori informazioni sulle metriche fornite da Cloud Data Fusion per la parte della pipeline eseguita in BigQuery, consulta Metriche della pipeline pushdown di BigQuery.
Quando utilizzare il pushdown delle trasformazioni
L'esecuzione delle trasformazioni in BigQuery prevede quanto segue:
- Scrittura di record in BigQuery per le fasi supportate nella pipeline.
- Esecuzione delle fasi supportate in BigQuery.
- Lettura dei record da BigQuery dopo l'esecuzione delle trasformazioni supportate, a meno che non siano seguite da un destinazione BigQuery.
A seconda delle dimensioni dei set di dati, potrebbe esserci un overhead della rete considerevole, che può avere un impatto negativo sul tempo di esecuzione complessivo della pipeline quando è attivata la funzionalità di trasferimento delle trasformazioni.
A causa del sovraccarico della rete, consigliamo di utilizzare la trasformazione pushdown nei seguenti casi:
- Più operazioni supportate vengono eseguite in sequenza (senza passaggi tra le fasi).
- I miglioramenti delle prestazioni di BigQuery che esegue le trasformazioni, rispetto a Spark, superano la latenza del trasferimento dei dati in e possibilmente fuori da BigQuery.
Come funziona
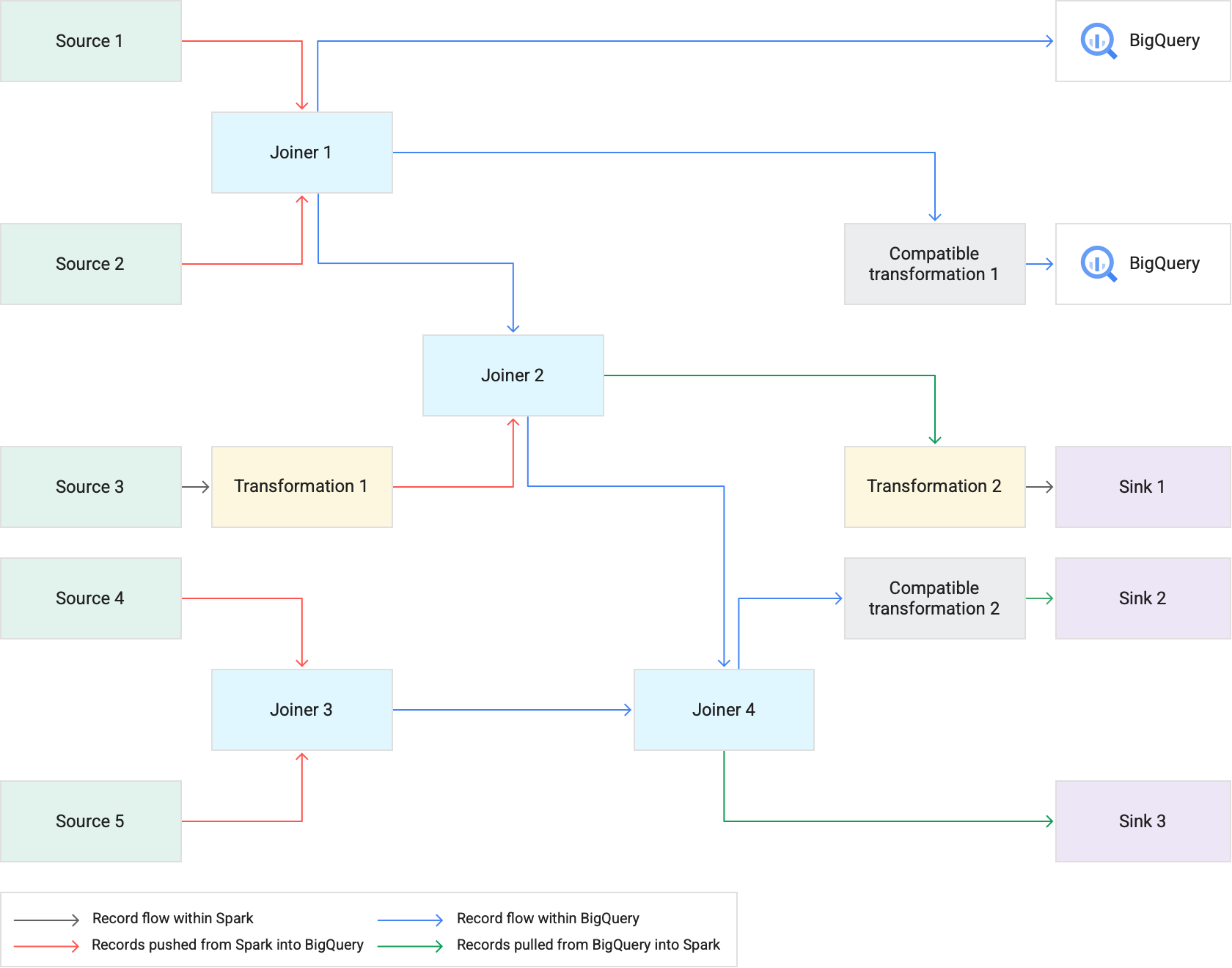
Quando esegui una pipeline che utilizza il pushdown delle trasformazioni, Cloud Data Fusion esegue le fasi di trasformazione supportate in BigQuery. Tutte le altre fasi della pipeline vengono eseguite in Spark.
Durante l'esecuzione delle trasformazioni:
Cloud Data Fusion carica i set di dati di input in BigQuery scrivendo i record in Cloud Storage e poi eseguendo un job di caricamento BigQuery.
Le operazioni
JOINe le trasformazioni supportate vengono poi eseguite come job BigQuery utilizzando istruzioni SQL.Se è necessaria un'ulteriore elaborazione dopo l'esecuzione dei job, i record possono essere esportati da BigQuery in Spark. Tuttavia, se l'opzione Cerca di eseguire una copia diretta negli sink BigQuery è attivata e lo sink BigQuery segue una fase eseguita in BigQuery, i record vengono scritti direttamente nella tabella dello sink BigQuery di destinazione.
Il seguente diagramma mostra come il pushdown delle trasformazioni esegue le trasformazioni supportate in BigQuery anziché in Spark.
Best practice
Regolare le dimensioni di cluster ed esecutori
Per ottimizzare la gestione delle risorse nella pipeline:
Utilizza il numero corretto di worker (nodi) del cluster per un workload. In altre parole, sfrutta al meglio il cluster Dataproc di cui è stato eseguito il provisioning utilizzando al meglio la CPU e la memoria disponibili per l'istanza, beneficiando al contempo della velocità di esecuzione di BigQuery per i job di grandi dimensioni.
Migliora il parallelismo nelle pipeline utilizzando cluster con scalabilità automatica.
Modifica le configurazioni delle risorse nelle fasi della pipeline in cui i record vengono inviati o estratti da BigQuery durante l'esecuzione della pipeline.
Consigliato: prova ad aumentare il numero di core della CPU per le risorse dell'executor (fino al numero di core della CPU utilizzati dal tuo nodo worker). Gli esecutori ottimizzano l'utilizzo della CPU durante le fasi di serializzazione e deserializzazione quando i dati entrano e escono da BigQuery. Per ulteriori informazioni, consulta la sezione Dimensionamento del cluster.
Un vantaggio dell'esecuzione delle trasformazioni in BigQuery è che le tue pipeline possono essere eseguite su cluster Dataproc più piccoli. Se le unioni sono le operazioni più dispendiose in termini di risorse nella pipeline, puoi fare esperimenti con dimensioni dei cluster più piccole, poiché le operazioni JOIN pesanti ora vengono eseguite in BigQuery, il che ti consente di ridurre potenzialmente i costi complessivi di calcolo.
Recuperare i dati più velocemente con l'API BigQuery Storage Read
Dopo che BigQuery ha eseguito le trasformazioni, la pipeline potrebbe avere fasi aggiuntive da eseguire in Spark. In Cloud Data Fusion versione 6.7.0 e successive, il pushdown delle trasformazioni supporta l'API BigQuery Storage Read, che migliora la latenza e consente di eseguire operazioni di lettura più rapide in Spark. Può ridurre il tempo di esecuzione complessivo della pipeline.
L'API legge i record in parallelo, pertanto ti consigliamo di regolare le dimensioni degli executor di conseguenza. Se in BigQuery vengono eseguite operazioni che richiedono molte risorse, riduci l'allocazione della memoria per gli esecutori per migliorare il parallelismo durante l'esecuzione della pipeline (vedi Modificare le dimensioni del cluster e degli esecutori).
L'API BigQuery Storage Read è disabilitata per impostazione predefinita. Puoi attivarlo negli ambienti di esecuzione in cui è installato Scala 2.12 (inclusi Dataproc 2.0 e Dataproc 1.5).
Considera le dimensioni del set di dati
Tieni conto delle dimensioni dei set di dati nelle operazioni JOIN. Per le operazioni JOIN
che generano un numero significativo di record di output, ad esempio
qualcosa che assomiglia a un'operazione JOIN incrociata, le dimensioni del set di dati risultante
potrebbero essere ordini di grandezza superiori a quelle del set di dati di input. Inoltre, tieni conto dell'overhead di inserimento di questi record in Spark quando si verifica un'ulteriore elaborazione di Spark per questi record, ad esempio una trasformazione o un sink, nel contesto del rendimento complessivo della pipeline.
Mitigare i dati distorti
Le operazioni JOIN per dati fortemente distorti potrebbero causare il superamento dei limiti di utilizzo delle risorse da parte del job BigQuery, provocando il fallimento dell'operazione JOIN. Per evitare questo problema, vai alle impostazioni del plug-in Joiner e identifica l'input non uniforme nel campo Fase di input non uniforme. In questo modo, Cloud Data Fusion organizza gli input in modo da ridurre il rischio che l'istruzione BigQuery superi i limiti.