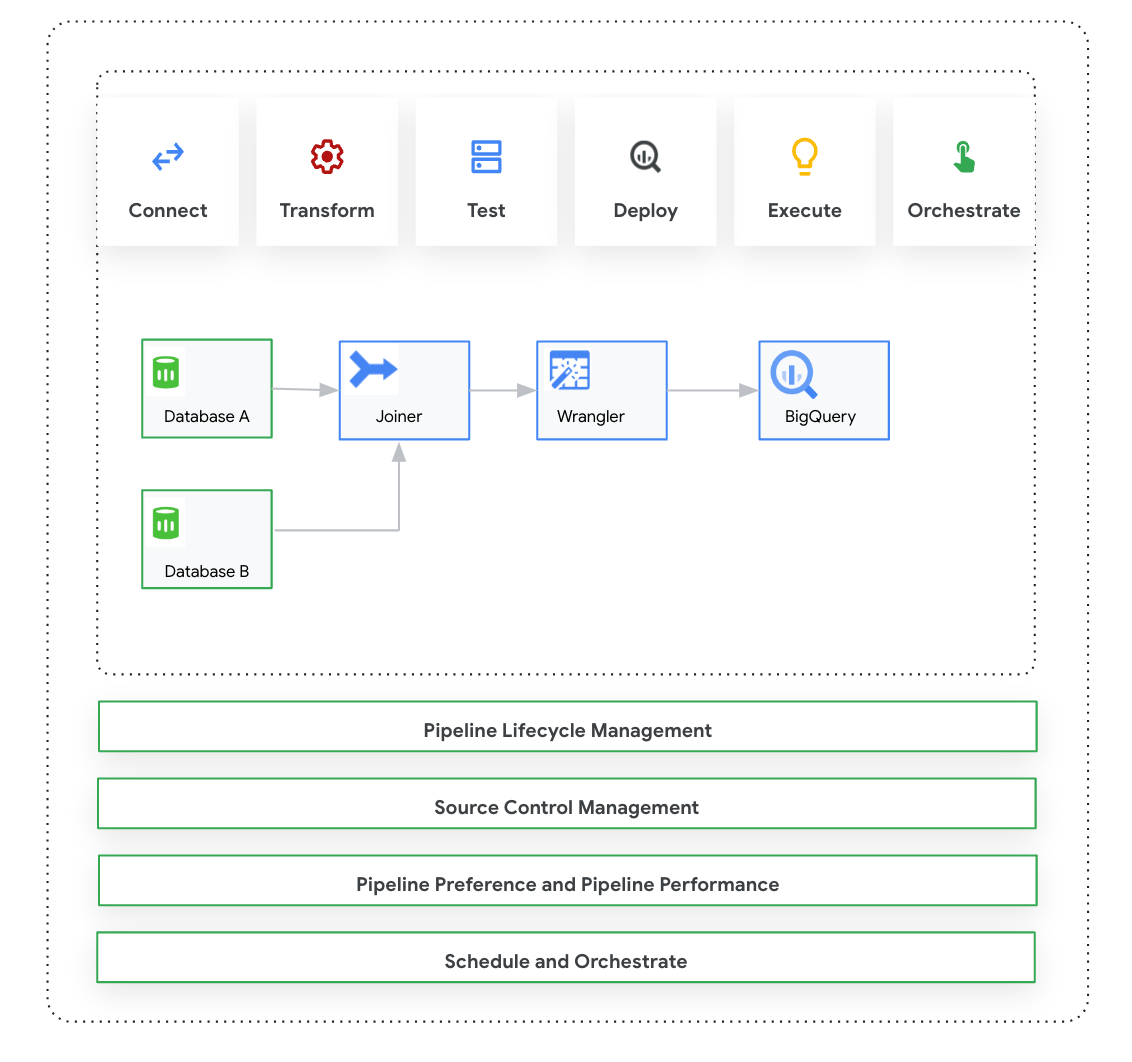
本頁介紹 Cloud Data Fusion Studio,這是一個可點選及拖曳的圖形介面,可從預先建構的程式庫中建構資料管道,並提供可用於設定、執行及管理管道的介面。在 Studio 中建構管道時,通常會遵循下列程序:
- 連結至內部部署或雲端資料來源。
- 準備及轉換資料。
- 連線至目的地。
- 測試管道。
- 執行管道。
- 排定及觸發管道。
設計及執行管道後,您可以在 Cloud Data Fusion 的 Pipeline Studio 頁面上管理管道:
- 使用偏好設定和執行階段引數,為管道設定參數,以便重複使用。
- 自訂運算設定檔、管理資源,並微調管道效能,以便管理管道執行作業。
- 編輯管道來管理管道生命週期。
- 使用 Git 整合功能管理管道原始碼控管。
事前準備
- 啟用 Cloud Data Fusion API。
- 建立 Cloud Data Fusion 執行個體。
- 瞭解 Cloud Data Fusion 中的存取權控管。
- 瞭解 Cloud Data Fusion 中的重要概念和術語。
Cloud Data Fusion:工作室總覽
工作室包含下列元件。
管理
Cloud Data Fusion 可讓您在每個執行個體中建立多個命名空間。在工作室中,管理員可以集中管理所有命名空間,或個別管理每個命名空間。
Studio 提供下列管理員控管功能:
- 系統管理
- Studio 中的 System Admin 模組可讓您建立新的命名空間,並在系統層級定義集中的運算設定檔,這些設定可套用至該執行個體中的每個命名空間。詳情請參閱「管理 Studio 管理功能」。
- 命名空間管理
- Studio 中的 Namespace Admin 模組可讓您管理特定命名空間的設定。您可以為每個命名空間定義運算設定檔、執行階段偏好設定、驅動程式、服務帳戶和 Git 設定。詳情請參閱「管理 Studio 管理功能」。
Pipeline Design Studio
您可以在 Cloud Data Fusion 網頁介面中的 Pipeline Design Studio 中設計及執行管道。設計及執行資料管道包含下列步驟:
- 連結至來源:Cloud Data Fusion 可連結至內部部署和雲端資料來源。Studio 介面提供預設的系統外掛程式,這些外掛程式已預先安裝在 Studio 中。您可以從外掛程式存放區 (稱為「Hub」) 下載其他外掛程式。詳情請參閱「外掛程式總覽」。
- 資料準備:Cloud Data Fusion 可讓您使用強大的資料準備外掛程式 Wrangler 準備資料。在 Studio 中針對整個資料集執行邏輯之前,Wrangler 可協助您在單一位置查看、探索及轉換小型資料樣本。這樣一來,您就能快速套用轉換作業,瞭解轉換作業對整個資料集的影響。您可以建立多個轉換,並將這些轉換加入至方程式。詳情請參閱 Wrangler 總覽。
- 轉換:轉換外掛程式會在資料從來源載入後進行變更,例如複製記錄、將檔案格式變更為 JSON,或使用 JavaScript 外掛程式建立自訂轉換。詳情請參閱「外掛程式總覽」。
- 連線至目的地:準備資料並套用轉換後,您可以連線至要載入資料的目的地。Cloud Data Fusion 支援連結至多個目的地。詳情請參閱「外掛程式總覽」。
- 預覽:設計管道後,您可以執行預覽工作,在部署及執行管道前先偵錯。如果遇到任何錯誤,您可以在草稿模式中修正錯誤。Studio 會使用來源資料集的前 100 列產生預覽畫面。Studio 會顯示預覽工作的狀態和時間長度。您隨時可以停止工作。您也可以在預覽工作執行時監控記錄事件。詳情請參閱「預覽資料」。
管理管道設定:預覽資料後,您可以部署管道並管理下列管道設定:
- 運算設定:您可以變更執行管道的運算資料,例如,您想要針對自訂的 Dataproc 叢集執行管道,而不是預設的 Dataproc 叢集。
- 管道設定:您可以為每個管道啟用或停用檢測功能,例如計時指標。根據預設,系統會啟用檢測功能。
- 引擎設定:Spark 是預設執行引擎。您可以為 Spark 傳遞自訂參數。
- 資源:您可以為 Spark 驅動程式和執行程式指定記憶體和 CPU 數量。驅動程式會調度管理 Spark 工作。執行緒會處理 Spark 中的資料處理作業。
- 管道快訊:您可以設定管道,在管道執行完畢後傳送快訊並開始後置處理工作。您可以在設計管道時建立管道快訊。部署管道後,您可以查看警示。如要變更快訊設定,您可以編輯管道。
- 轉換下推:如果您希望管道在 BigQuery 中執行特定轉換,可以啟用轉換下推。
詳情請參閱「管理管道設定」。
使用巨集、偏好設定和執行階段引數重複使用管道:Cloud Data Fusion 可讓您重複使用資料管道。有了可重複使用的資料管道,您就能透過單一管道,將資料整合模式套用至各種用途和資料集。可重複使用的管道可提供更佳的管理性。您可以在執行時設定管道的大部分設定,而非在設計時硬式編碼。在 Pipeline Design Studio 中,您可以使用巨集將變數新增至外掛程式設定,以便在執行階段指定變數替代字元。詳情請參閱「管理巨集、偏好設定和執行階段引數」。
執行:查看管道設定後,您可以啟動管道執行作業。您可以在管道執行階段期間查看狀態變更,例如佈建、啟動、執行和成功。
排程和協調:可以設定批次資料管道,按照指定的時間表和頻率執行。建立及部署管道後,您可以建立排程。在 Pipeline Design Studio 中,您可以建立批次資料管道觸發條件,在管道執行完畢後執行管道,藉此協調管道。這就是所謂的下游和上游管道。您可以在下游管道上建立觸發條件,讓管道根據一或多個上游管道的完成情況執行。
建議做法:您也可以使用 Composer 在 Cloud Data Fusion 中自動調度管道。詳情請參閱「排程管道」和「協調管道」。
編輯管道:Cloud Data Fusion 可讓您編輯已部署的管道。編輯已部署的管道時,系統會建立同名的新管道版本,並將其標示為最新版本。這可讓您以逐步的方式開發管道,而非複製管道,因為複製管道會建立名稱不同的新管道。詳情請參閱「編輯管道」。
原始碼控管:Cloud Data Fusion 可讓您透過使用 GitHub 管理管道的來源控管,更妥善地管理開發和實際作業環境之間的管道。
記錄和監控:如要監控管道指標和記錄,建議您啟用 Stackdriver 記錄服務,以便搭配 Cloud Data Fusion 管道使用 Cloud Logging。
後續步驟
- 進一步瞭解如何管理 YouTube 工作室的管理員。