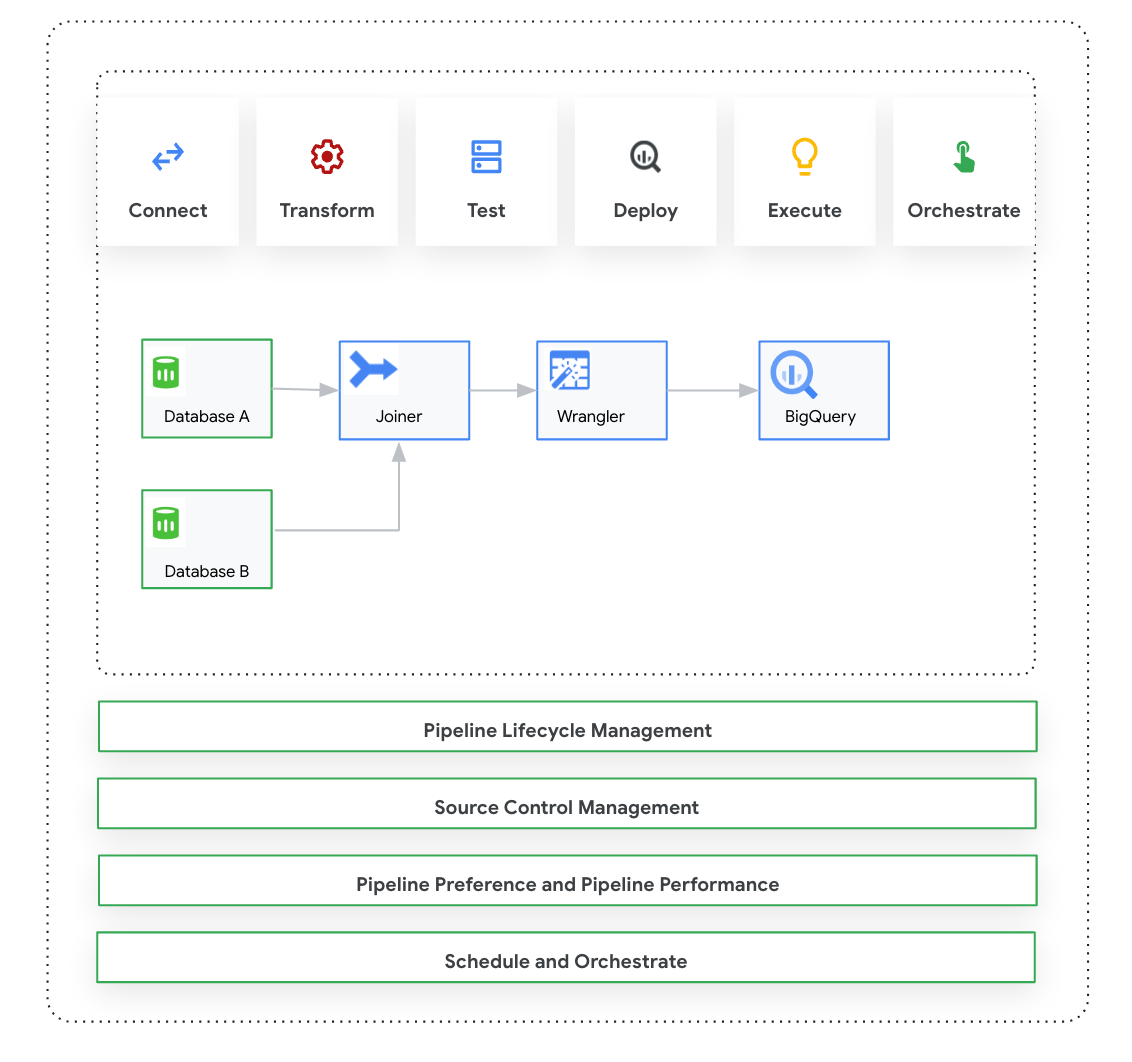
Esta página apresenta o Cloud Data Fusion: Studio, que é uma interface visual de clique e arrasto para criar pipelines de dados de uma biblioteca de plug-ins pré-criados e uma interface em que você configura, executa e gerencia seus pipelines. A criação de um pipeline no Studio geralmente segue este processo:
- Conecte-se a uma fonte de dados local ou na nuvem.
- Prepare e transforme seus dados.
- Conecte-se ao destino.
- Teste o pipeline.
- Execute o pipeline.
- Programe e acione seus pipelines.
Depois de projetar e executar o pipeline, é possível gerenciá-lo na página Pipeline Studio do Cloud Data Fusion:
- Reutilize pipelines parametrizando-os com preferências e argumentos de execução.
- Gerencie a execução do pipeline personalizando perfis de computação, gerenciando recursos e ajustando a performance do pipeline.
- Gerenciar o ciclo de vida do pipeline editando pipelines.
- Gerenciar o controle de origem do pipeline usando a integração do Git.
Antes de começar
- Ative a API do Cloud Data Fusion.
- Crie uma instância do Cloud Data Fusion.
- Entenda o controle de acesso no Cloud Data Fusion.
- Entenda os principais conceitos e termos do Cloud Data Fusion.
Cloud Data Fusion: visão geral do Studio
O Studio inclui os seguintes componentes:
Administração
O Cloud Data Fusion permite ter vários namespaces em cada instância. No Studio, os administradores podem gerenciar todos os namespaces de forma centralizada ou cada um deles individualmente.
O Studio oferece os seguintes controles de administrador:
- Administração do sistema
- O módulo Administrador do sistema no Studio permite criar novos namespaces e definir as configurações centrais do perfil de computação no nível do sistema, que são aplicáveis a cada namespace nessa instância. Para mais informações, consulte Gerenciar a administração do Studio.
- Administração de namespace
- O módulo Administrador de namespace no Studio permite gerenciar as configurações de um namespace específico. Para cada namespace, é possível definir perfis de computação, preferências de execução, drivers, contas de serviço e configurações do git. Para mais informações, consulte Gerenciar a administração do Studio.
Pipeline Design Studio
Você projeta e executa pipelines no Pipeline Design Studio na interface da Web do Cloud Data Fusion. O design e a execução de pipelines de dados incluem as seguintes etapas:
- Conectar a uma fonte: o Cloud Data Fusion permite conexões com fontes de dados locais e na nuvem. A interface do Studio tem plug-ins padrão do sistema, que vêm pré-instalados no Studio. É possível fazer o download de plug-ins adicionais em um repositório de plug-ins, conhecido como Hub. Para mais informações, consulte a Visão geral dos plug-ins.
- Preparação de dados: o Cloud Data Fusion permite preparar seus dados usando o plug-in de preparação de dados Wrangler. O Wrangler ajuda a visualizar, explorar e transformar uma pequena amostra dos seus dados em um só lugar antes de executar a lógica em todo o conjunto de dados no Studio. Assim, você pode aplicar transformações rapidamente para entender como elas afetam todo o conjunto de dados. Você pode criar várias transformações e adicioná-las a uma receita. Para mais informações, consulte a Visão geral do Wrangler.
- Transformação: os plug-ins de transformação mudam os dados depois que eles são carregados de uma fonte. Por exemplo, é possível clonar um registro, mudar o formato do arquivo para JSON ou usar o plug-in JavaScript para criar uma transformação personalizada. Para mais informações, consulte a Visão geral dos plug-ins.
- Conectar a um destino: depois de preparar os dados e aplicar as transformações, você pode se conectar ao destino onde pretende carregar os dados. O Cloud Data Fusion oferece suporte a conexões com vários destinos. Para mais informações, consulte Visão geral dos plug-ins.
- Visualização: depois de projetar o pipeline, para depurar problemas antes de implantar e executar um pipeline, execute um job de visualização. Se você encontrar algum erro, poderá corrigi-lo no modo Rascunho. O Studio usa as primeiras 100 linhas do conjunto de dados de origem para gerar a visualização. O Studio mostra o status e a duração do job de visualização. Você pode interromper o job a qualquer momento. Também é possível monitorar os eventos de registro à medida que o job de visualização é executado. Para mais informações, consulte Pré-visualizar dados.
Gerenciar configurações do pipeline: depois de visualizar os dados, é possível implantar o pipeline e gerenciar as seguintes configurações:
- Configuração de computação: é possível mudar o perfil de computação que executa o pipeline. Por exemplo, você quer executar o pipeline em um cluster do Dataproc personalizado em vez do cluster padrão do Dataproc.
- Configuração do pipeline: para cada pipeline, é possível ativar ou desativar a instrumentação, como métricas de tempo. Por padrão, a instrumentação é ativada.
- Configuração do mecanismo: o Spark é o mecanismo de execução padrão. É possível transmitir parâmetros personalizados para o Spark.
- Recursos: é possível especificar a memória e o número de CPUs para o driver e o executor do Spark. O driver orquestra o job do Spark. O executor processa os dados no Spark.
- Alerta de pipeline: é possível configurar o pipeline para enviar alertas e iniciar tarefas de pós-processamento após a execução do pipeline. Você cria alertas de pipeline ao projetar o pipeline. Depois de implantar o pipeline, você poderá conferir os alertas. Para mudar as configurações de alerta, você pode editar o pipeline.
- Pushdown de transformação: é possível ativar o pushdown de transformação se você quiser que um pipeline execute determinadas transformações no BigQuery.
Para mais informações, consulte Gerenciar configurações de pipeline.
Reutilizar pipelines usando macros, preferências e argumentos de execução: o Cloud Data Fusion permite reutilizar pipelines de dados. Com pipelines de dados reutilizáveis, é possível ter um único pipeline que pode aplicar um padrão de integração de dados a vários casos de uso e conjuntos de dados. Os pipelines reutilizáveis oferecem melhor capacidade de gerenciamento. Eles permitem que você defina a maior parte da configuração de um pipeline no momento da execução, em vez de codificá-la no momento do design. No Pipeline Design Studio, é possível usar macros para adicionar variáveis às configurações de plug-ins e especificar as substituições de variáveis no momento da execução. Para mais informações, consulte Gerenciar macros, preferências e argumentos de execução.
Executar: depois de revisar as configurações do pipeline, você pode iniciar a execução. É possível observar a mudança de status durante as fases da execução do pipeline, por exemplo, provisionamento, início, execução e sucesso.
Programar e orquestrar: os pipelines de dados em lote podem ser configurados para serem executados em uma programação e frequência especificadas. Depois de criar e implantar um pipeline, é possível criar uma programação. No Pipeline Design Studio, é possível orquestrar pipelines criando um acionador em um pipeline de dados em lote para que ele seja executado quando uma ou mais execuções de pipeline forem concluídas. Eles são chamados de pipelines downstream e upstream. Você cria um acionador no pipeline downstream para que ele seja executado com base na conclusão de um ou mais pipelines upstream.
Recomendado: também é possível usar o Composer para orquestrar pipelines no Cloud Data Fusion. Para mais informações, consulte Programar pipelines e Orquestrar pipelines.
Editar pipelines: o Cloud Data Fusion permite editar um pipeline implantado. Quando você edita um pipeline implantado, uma nova versão do pipeline é criada com o mesmo nome e marcada como a versão mais recente. Isso permite que você desenvolva pipelines de maneira iterativa em vez de duplicar pipelines, criando um novo pipeline com um nome diferente. Para mais informações, consulte Editar pipelines.
Gerenciamento de controle de origem: o Cloud Data Fusion permite gerenciar melhor os pipelines entre o desenvolvimento e a produção com o Gerenciamento de controle de origem dos pipelines usando o GitHub.
Registro e monitoramento: para monitorar métricas e registros do pipeline, é recomendado ativar o serviço de registro do Stackdriver para usar o Cloud Logging com o pipeline do Cloud Data Fusion.
A seguir
- Saiba mais sobre como gerenciar a administração do Studio.