Restez organisé à l'aide des collections
Enregistrez et classez les contenus selon vos préférences.
Cette page explique comment les comptes de service sont utilisés dans Cloud Data Fusion. Pour en savoir plus, consultez Utiliser des comptes de service.
Projets clients et locataires
Cloud Data Fusion configure des comptes de service pour accéder aux ressources des projets suivants :
Projet locataire
Cloud Data Fusion crée un projet locataire destiné à contenir les ressources et les services dont il a besoin pour gérer des pipelines en votre nom. Par exemple, pour exécuter des pipelines sur des clusters Dataproc résidant dans votre projet client. Un projet locataire ne vous est pas directement exposé. Cependant, lorsque vous créerez une instance privée, vous devrez peut-être utiliser le nom du projet locataire pour configurer l'appairage de VPC.
Pour en savoir plus, consultez la documentation Service Infrastructure concernant les projets locataires.
Projet client
Vous créez ce projet et en êtes le propriétaire. Par défaut, Cloud Data Fusion crée un cluster Dataproc éphémère dans ce projet pour exécuter vos pipelines.
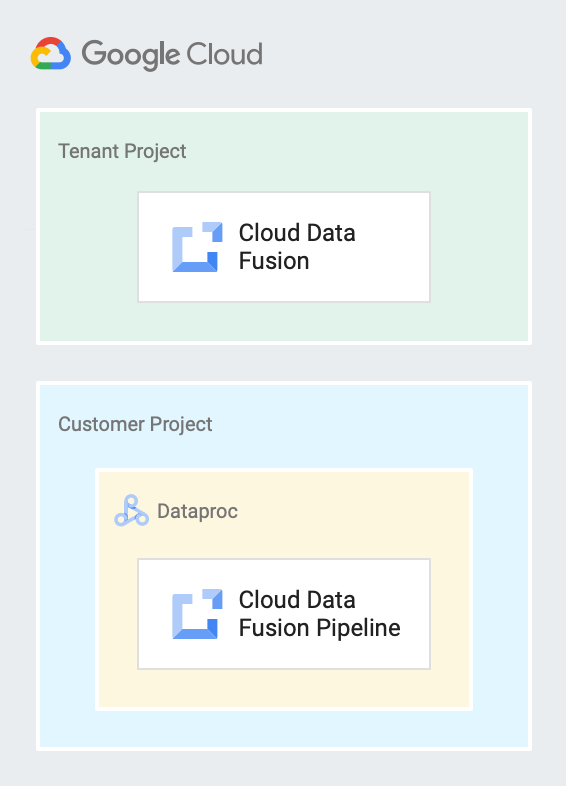
Le schéma suivant montre une instance Cloud Data Fusion s'exécutant dans un projet locataire et un pipeline s'exécutant sur un cluster Dataproc dans un projet client.
Comptes de service dans Cloud Data Fusion
Un compte de service fournit une identité à Cloud Data Fusion, lui permettant d'accéder à vos ressources.
Lorsque vous activez l'API Cloud Data Fusion et que vous créez une instance Cloud Data Fusion, un compte de service est ajouté à votre projet pour accéder à des ressources telles que Service Networking, Dataproc, Cloud Storage, BigQuery, Spanner et Bigtable. Ce compte de service est appelé Agent de service de l'API Cloud Data Fusion.
Des rôles sont automatiquement attribués à cet agent de service.
Un compte de service est identifié par son adresse e-mail, qui est unique au compte.
Les types de comptes de service suivants sont utilisés dans Cloud Data Fusion. Pour en savoir plus, consultez Types de comptes de service.
L'agent de service, appelé Agent de service de l'API Cloud Data Fusion, que Cloud Data Fusion crée pour accéder aux ressources du client afin de pouvoir agir au nom de celui-ci. Il est utilisé dans le projet locataire pour accéder aux ressources du projet client. Par exemple, la version Bêta s'exécute en mémoire plutôt que dans un cluster Dataproc.
Le rôle IAM (Identity and Access Management) Agent de service de l'API Cloud Data Fusion (roles/datafusion.serviceAgent) attribué par défaut au compte de service Cloud Data Fusion inclut des autorisations supplémentaires pour garantir une expérience utilisateur optimale. Pour renforcer la sécurité, vous pouvez créer un rôle personnalisé avec un ensemble d'autorisations minimales requises pour une tâche, puis l'attribuer au compte de service Cloud Data Fusion.
Le compte de service Compute Engine par défaut que Cloud Data Fusion crée pour déployer des jobs qui accèdent à d'autres ressources Google Cloud . Par défaut, il est associé à une VM de cluster Dataproc pour permettre à Cloud Data Fusion d'accéder aux ressources Dataproc pendant l'exécution d'un pipeline. Dans l'édition Enterprise de Cloud Data Fusion, vous pouvez exécuter des pipelines à partir d'un compte de service géré par l'utilisateur. Pour ce faire, créez un profil à partir de la console Cloud Data Fusion→Administrateur système→onglet Configuration, puis ajoutez le compte de service personnalisé. Dans les versions 6.2.3 et ultérieures, vous pouvez choisir un compte de service personnalisé à associer au cluster Dataproc lors de la création d'une instance Cloud Data Fusion. Pour en savoir plus, consultez la section
Comptes de service dans Dataproc.
Sauf indication contraire, le contenu de cette page est régi par une licence Creative Commons Attribution 4.0, et les échantillons de code sont régis par une licence Apache 2.0. Pour en savoir plus, consultez les Règles du site Google Developers. Java est une marque déposée d'Oracle et/ou de ses sociétés affiliées.
Dernière mise à jour le 2025/09/04 (UTC).
[[["Facile à comprendre","easyToUnderstand","thumb-up"],["J'ai pu résoudre mon problème","solvedMyProblem","thumb-up"],["Autre","otherUp","thumb-up"]],[["Difficile à comprendre","hardToUnderstand","thumb-down"],["Informations ou exemple de code incorrects","incorrectInformationOrSampleCode","thumb-down"],["Il n'y a pas l'information/les exemples dont j'ai besoin","missingTheInformationSamplesINeed","thumb-down"],["Problème de traduction","translationIssue","thumb-down"],["Autre","otherDown","thumb-down"]],["Dernière mise à jour le 2025/09/04 (UTC)."],[[["\u003cp\u003eCloud Data Fusion uses service accounts to access resources in both tenant and customer projects, enabling it to manage pipelines on the user's behalf.\u003c/p\u003e\n"],["\u003cp\u003eThe Cloud Data Fusion API Service Agent is a service account created automatically when enabling the Cloud Data Fusion API, granting it access to resources like Service Networking, Dataproc, Cloud Storage, and others.\u003c/p\u003e\n"],["\u003cp\u003eA default Compute Engine service account is also created to deploy jobs that access other Google Cloud resources, which can attach to a Dataproc cluster VM to enable Cloud Data Fusion to access Dataproc resources during pipeline runs.\u003c/p\u003e\n"],["\u003cp\u003eIn Cloud Data Fusion Enterprise edition, pipelines can run from a user-managed service account by creating a profile in the Cloud Data Fusion console, enhancing control and customization.\u003c/p\u003e\n"],["\u003cp\u003eCustomer project is owned by the customer and is the location where the ephemeral Dataproc cluster is located in order to run the user's pipelines.\u003c/p\u003e\n"]]],[],null,["# Service accounts in Cloud Data Fusion\n\nThis page describes how service accounts are used in Cloud Data Fusion. For\nmore information, see [Use service accounts](/iam/docs/service-accounts).\n\n### Tenant and customer projects\n\nCloud Data Fusion sets up service accounts to access resources in the\nfollowing projects:\n\nTenant project\n\n: Cloud Data Fusion creates a tenant project to hold the resources and\n services it needs to manage pipelines on your behalf. For example: running\n pipelines on your Dataproc clusters that reside in your customer\n project. A tenant project is not exposed to you, but when you create a\n private instance, you might need to use the tenant project name to set up VPC\n peering.\n\n For more information, see the Service Infrastructure documentation about\n [tenant projects](/service-infrastructure/docs/glossary#tenant).\n\nCustomer project\n\n: You create and own this project. By default, Cloud Data Fusion creates an\n ephemeral Dataproc cluster in this project to run the your\n pipelines.\n\nThe following diagram shows a Cloud Data Fusion instance running in a\ntenant project and a pipeline running on a Dataproc cluster in a\ncustomer project.\n\nService accounts in Cloud Data Fusion\n-------------------------------------\n\nA service account provides an identity for Cloud Data Fusion, which gives\nCloud Data Fusion access to your resources.\n\nWhen you enable the Cloud Data Fusion API and create a\nCloud Data Fusion instance, a service account is added to your project to\naccess resources like Service Networking,\nDataproc, Cloud Storage, BigQuery, Spanner,\nand Bigtable. This service account is called the\n[Cloud Data Fusion API Service Agent](/iam/docs/understanding-roles#datafusion.serviceAgent).\nRoles are automatically granted to this service agent.\n\nA service account is identified by its email address, which is unique to the\naccount.\n\nThe following types of service accounts are used in Cloud Data Fusion. For\nmore information, see [Types of service accounts](/iam/docs/service-account-types).\n\nWhat's next\n-----------\n\n- Learn about [controlling access to data](/data-fusion/docs/access-control).\n- [Give Service Account User permissions](/data-fusion/docs/how-to/granting-service-account-permission).\n- See Cloud Data Fusion [pricing](/data-fusion/pricing)."]]