En esta página, se describe cómo se usan las cuentas de servicio en Cloud Data Fusion. Para obtener más información, consulta Usa cuentas de servicio.
Proyectos de cliente y usuario
Cloud Data Fusion configura cuentas de servicio para acceder a los recursos en los siguientes proyectos:
- Proyecto de inquilino
Cloud Data Fusion crea un proyecto de usuario que contiene los recursos y los servicios que necesita para administrar canalizaciones en tu nombre. Por ejemplo: ejecutar canalizaciones en tus clústeres de Dataproc que residen en tu proyecto de cliente. Un proyecto de usuario no está expuesto a ti, pero cuando creas una instancia privada, es posible que debas usar el nombre del proyecto de usuario para configurar el intercambio de tráfico de VPC.
Para obtener más información, consulta la documentación de Infraestructura de servicios sobre los proyectos de usuario.
- Proyecto del cliente
Tú creas y posees este proyecto. Según la configuración predeterminada, Cloud Data Fusion crea un clúster efímero de Dataproc en este proyecto para ejecutar tus canalizaciones.
En el siguiente diagrama, se muestra una instancia de Cloud Data Fusion que se ejecuta en un proyecto de usuario y una canalización que se ejecuta en un clúster de Dataproc en un proyecto de cliente.
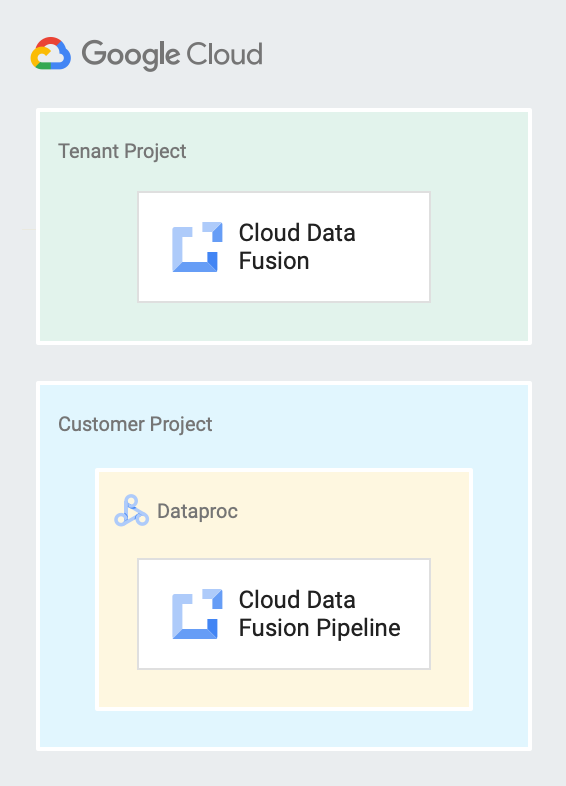
Cuentas de servicio en Cloud Data Fusion
Una cuenta de servicio proporciona una identidad para Cloud Data Fusion, que le da a Cloud Data Fusion acceso a tus recursos.
Cuando habilitas la API de Cloud Data Fusion y creas una instancia de Cloud Data Fusion, se agrega una cuenta de servicio a tu proyecto para acceder a recursos como Service Networking, Dataproc, Cloud Storage, BigQuery, Spanner y Bigtable. Esta cuenta de servicio se llama Agente de servicio de la API de Cloud Data Fusion. Las funciones se otorgan de forma automática a este agente de servicio.
Una cuenta de servicio se identifica por su dirección de correo electrónico, que es única a la cuenta.
En Cloud Data Fusion, se usan los siguientes tipos de cuentas de servicio. Para obtener más información, consulta Tipos de cuentas de servicio.
| Cuenta de servicio | Descripción |
|---|---|
service-CUSTOMER_PROJECT_NUMBER@gcp-sa-
datafusion.iam.gserviceaccount.com |
El agente de servicio, llamado Agente de servicio de la API de Cloud Data Fusion, que Cloud Data Fusion crea para obtener acceso a los recursos del cliente y poder actuar en su nombre. Se usa en el proyecto de usuario para acceder a los recursos del proyecto de cliente. Por ejemplo, la vista previa se ejecuta en la memoria en lugar de en un clúster de Dataproc. La identidad y el rol de administración de acceso de Agente de servicio de la API de Cloud Data Fusion ( |
CUSTOMER_PROJECT_NUMBER-
compute@developer.gserviceaccount.com |
La cuenta de servicio predeterminada de Compute Engine que Cloud Data Fusion crea para implementar trabajos que acceden a otros recursos de Google Cloud . De forma predeterminada, se adjunta a una VM de clúster de Dataproc para permitir que Cloud Data Fusion acceda a los recursos de Dataproc durante la ejecución de una canalización. En la edición Enterprise de Cloud Data Fusion, puedes ejecutar canalizaciones desde una cuenta de servicio administrada por el usuario si creas un perfil desde la consola de Cloud Data Fusion → Administrador del sistema → pestaña Configuración y agregas la cuenta de servicio personalizada. En las versiones 6.2.3 y posteriores, puedes elegir una cuenta de servicio personalizada para adjuntar al clúster de Dataproc cuando creas una instancia de Cloud Data Fusion. Para obtener más información, consulta Cuentas de servicio en Dataproc. |
¿Qué sigue?
- Obtén más información para controlar el acceso a los datos.
- Otorga permisos de usuario a la cuenta de servicio.
- Consulta los precios de Cloud Data Fusion.