Mit Sammlungen den Überblick behalten
Sie können Inhalte basierend auf Ihren Einstellungen speichern und kategorisieren.
Auf dieser Seite wird beschrieben, wie Dienstkonten in Cloud Data Fusion verwendet werden. Weitere Informationen finden Sie unter Dienstkonten verwenden.
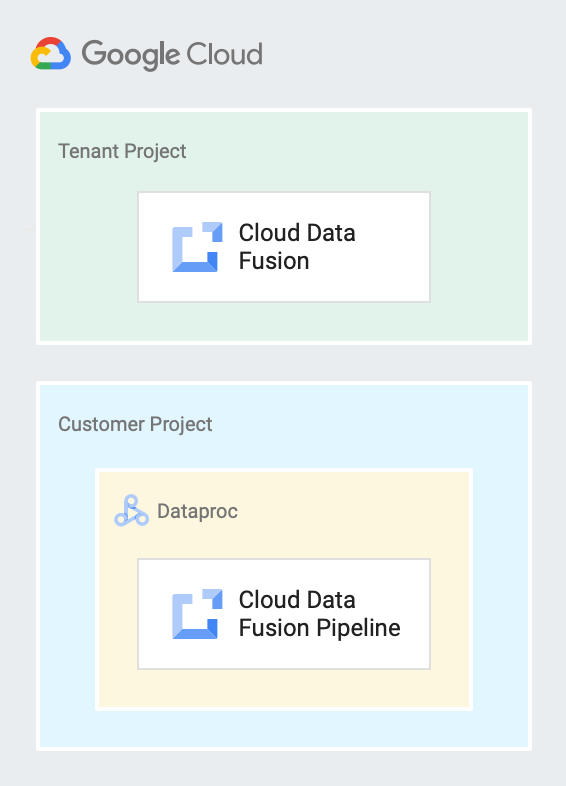
Mandanten- und Kundenprojekte
Cloud Data Fusion richtet Dienstkonten ein, um auf Ressourcen in den folgenden Projekten zuzugreifen:
Mandantenprojekt
Cloud Data Fusion erstellt ein Mandantenprojekt, das die Ressourcen und Dienste enthält, die es zur Verwaltung von Pipelines in Ihrem Namen benötigt. Beispiel: Pipelines auf Ihren Dataproc-Clustern ausführen, die sich in Ihrem Kundenprojekt befinden. Ein Mandantenprojekt ist für Sie nicht verfügbar. Wenn Sie jedoch eine private Instanz erstellen, müssen Sie möglicherweise den Mandantenprojektnamen verwenden, um VPC-Peering einzurichten.
Weitere Informationen finden Sie in der Service Infrastructure-Dokumentation zu Mandantenprojekten.
Kundenprojekt
Sie erstellen und besitzen dieses Projekt. Standardmäßig erstellt Cloud Data Fusion in diesem Projekt einen sitzungsspezifischen Dataproc-Cluster, um Ihre Pipelines auszuführen.
Das folgende Diagramm zeigt eine Cloud Data Fusion-Instanz, die in einem Mandantenprojekt ausgeführt wird, und eine Pipeline, die in einem Dataproc-Cluster in einem Kundenprojekt ausgeführt wird.
Dienstkonten in Cloud Data Fusion
Ein Dienstkonto bietet eine Identität für Cloud Data Fusion, die Cloud Data Fusion Zugriff auf Ihre Ressourcen gewährt.
Wenn Sie die Cloud Data Fusion API aktivieren und eine Cloud Data Fusion-Instanz erstellen, wird Ihrem Projekt ein Dienstkonto hinzugefügt, um auf Ressourcen wie Service Networking, Dataproc, Cloud Storage, BigQuery, Spanner und Bigtable zuzugreifen. Dieses Dienstkonto wird als Cloud Data Fusion API-Dienst-Agent bezeichnet.
Diesem Dienst-Agent werden automatisch Rollen zugewiesen.
Ein Dienstkonto wird durch seine E-Mail-Adresse definiert, die für das Konto spezifisch ist.
In Cloud Data Fusion werden die folgenden Arten von Dienstkonten verwendet. Weitere Informationen finden Sie unter Arten von Dienstkonten.
Der Dienst-Agent, der sogenannte Cloud Data Fusion API-Dienst-Agent, den Cloud Data Fusion erstellt, um Zugriff auf Kundenressourcen zu erhalten, damit der Dienst im Namen des Kunden agieren kann. Dieses Konto wird im Mandantenprojekt verwendet, um auf Ressourcen von Kundenprojekten zuzugreifen. Beispielsweise wird die Vorschau im Arbeitsspeicher statt in einem Dataproc-Cluster ausgeführt.
Identity and Access Management-Rolle Cloud Data Fusion API Service Agent (roles/datafusion.serviceAgent), die dem Cloud Data Fusion-Dienstkonto standardmäßig zugewiesen ist, enthält zusätzliche Berechtigungen, um eine optimale Nutzerfreundlichkeit zu gewährleisten. Zur Erhöhung der Sicherheit können Sie eine benutzerdefinierte Rolle mit einem Satz von erforderlichen Mindestberechtigungen für eine Aufgabe erstellen und dem Cloud Data Fusion-Dienstkonto zuweisen.
Das Compute Engine-Standarddienstkonto, das von Cloud Data Fusion erstellt wird, um Jobs bereitzustellen, die auf andere Google Cloud -Ressourcen zugreifen. Dieses Konto wird standardmäßig einer Dataproc-Cluster-VM hinzugefügt, damit Cloud Data Fusion während der Ausführung einer Pipeline auf Dataproc-Ressourcen zugreifen kann. In der Cloud Data Fusion Enterprise Edition können Sie Pipelines über ein nutzerverwaltetes Dienstkonto ausführen. Erstellen Sie dazu ein Profil über die Cloud Data Fusion-Konsole → Systemadministrator → Tab „Konfiguration“ und fügen Sie das benutzerdefinierte Dienstkonto hinzu. In Version 6.2.3 und höher können Sie ein benutzerdefiniertes Dienstkonto auswählen, das beim Erstellen einer Cloud Data Fusion-Instanz an den Dataproc-Cluster angehängt werden soll. Weitere Informationen finden Sie unter
Dienstkonten in Dataproc.
[[["Leicht verständlich","easyToUnderstand","thumb-up"],["Mein Problem wurde gelöst","solvedMyProblem","thumb-up"],["Sonstiges","otherUp","thumb-up"]],[["Schwer verständlich","hardToUnderstand","thumb-down"],["Informationen oder Beispielcode falsch","incorrectInformationOrSampleCode","thumb-down"],["Benötigte Informationen/Beispiele nicht gefunden","missingTheInformationSamplesINeed","thumb-down"],["Problem mit der Übersetzung","translationIssue","thumb-down"],["Sonstiges","otherDown","thumb-down"]],["Zuletzt aktualisiert: 2025-09-04 (UTC)."],[[["\u003cp\u003eCloud Data Fusion uses service accounts to access resources in both tenant and customer projects, enabling it to manage pipelines on the user's behalf.\u003c/p\u003e\n"],["\u003cp\u003eThe Cloud Data Fusion API Service Agent is a service account created automatically when enabling the Cloud Data Fusion API, granting it access to resources like Service Networking, Dataproc, Cloud Storage, and others.\u003c/p\u003e\n"],["\u003cp\u003eA default Compute Engine service account is also created to deploy jobs that access other Google Cloud resources, which can attach to a Dataproc cluster VM to enable Cloud Data Fusion to access Dataproc resources during pipeline runs.\u003c/p\u003e\n"],["\u003cp\u003eIn Cloud Data Fusion Enterprise edition, pipelines can run from a user-managed service account by creating a profile in the Cloud Data Fusion console, enhancing control and customization.\u003c/p\u003e\n"],["\u003cp\u003eCustomer project is owned by the customer and is the location where the ephemeral Dataproc cluster is located in order to run the user's pipelines.\u003c/p\u003e\n"]]],[],null,["# Service accounts in Cloud Data Fusion\n\nThis page describes how service accounts are used in Cloud Data Fusion. For\nmore information, see [Use service accounts](/iam/docs/service-accounts).\n\n### Tenant and customer projects\n\nCloud Data Fusion sets up service accounts to access resources in the\nfollowing projects:\n\nTenant project\n\n: Cloud Data Fusion creates a tenant project to hold the resources and\n services it needs to manage pipelines on your behalf. For example: running\n pipelines on your Dataproc clusters that reside in your customer\n project. A tenant project is not exposed to you, but when you create a\n private instance, you might need to use the tenant project name to set up VPC\n peering.\n\n For more information, see the Service Infrastructure documentation about\n [tenant projects](/service-infrastructure/docs/glossary#tenant).\n\nCustomer project\n\n: You create and own this project. By default, Cloud Data Fusion creates an\n ephemeral Dataproc cluster in this project to run the your\n pipelines.\n\nThe following diagram shows a Cloud Data Fusion instance running in a\ntenant project and a pipeline running on a Dataproc cluster in a\ncustomer project.\n\nService accounts in Cloud Data Fusion\n-------------------------------------\n\nA service account provides an identity for Cloud Data Fusion, which gives\nCloud Data Fusion access to your resources.\n\nWhen you enable the Cloud Data Fusion API and create a\nCloud Data Fusion instance, a service account is added to your project to\naccess resources like Service Networking,\nDataproc, Cloud Storage, BigQuery, Spanner,\nand Bigtable. This service account is called the\n[Cloud Data Fusion API Service Agent](/iam/docs/understanding-roles#datafusion.serviceAgent).\nRoles are automatically granted to this service agent.\n\nA service account is identified by its email address, which is unique to the\naccount.\n\nThe following types of service accounts are used in Cloud Data Fusion. For\nmore information, see [Types of service accounts](/iam/docs/service-account-types).\n\nWhat's next\n-----------\n\n- Learn about [controlling access to data](/data-fusion/docs/access-control).\n- [Give Service Account User permissions](/data-fusion/docs/how-to/granting-service-account-permission).\n- See Cloud Data Fusion [pricing](/data-fusion/pricing)."]]