Cloud Composer 1 | Cloud Composer 2 | Cloud Composer 3
Esta página descreve como usar a DataflowTemplateOperator para iniciar
Pipelines do Dataflow de
Cloud Composer
O pipeline Cloud Storage Text para BigQuery
é um pipeline em lote que permite o upload de arquivos de texto armazenados em
Cloud Storage, transforme-os usando uma função definida pelo usuário (UDF, na sigla em inglês) do JavaScript fornecida por você e gere os resultados para
no BigQuery.
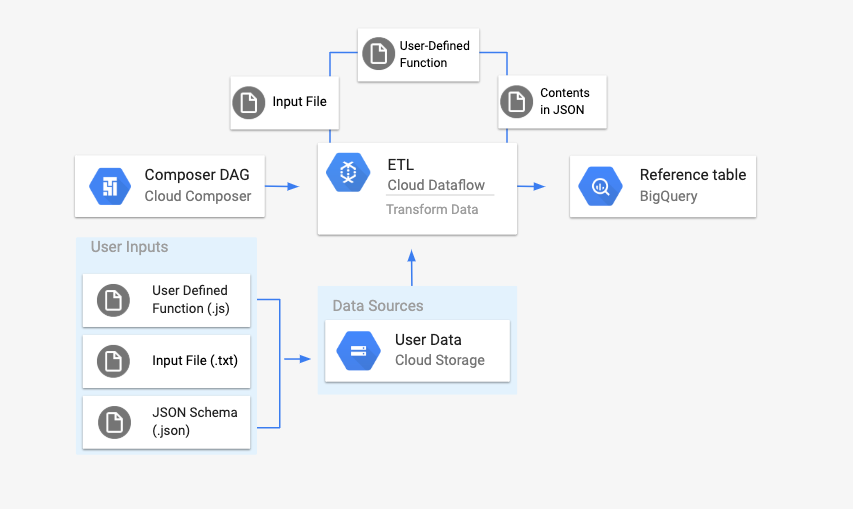
Visão geral
Antes de iniciar o fluxo de trabalho, você vai criar as seguintes entidades:
Uma tabela vazia do BigQuery de um conjunto de dados vazio que conterá as seguintes colunas de informações:
location,average_temperature,monthe, opcionalmente,inches_of_rain,is_currentelatest_measurement.Um arquivo JSON que normaliza os dados do
.txt. no formato correto para os tabela do BigQuery esquema. O objeto JSON terá uma matriz deBigQuery Schema, em que cada objeto conterá um nome de coluna, o tipo de entrada e se mas não é obrigatório.Um arquivo
.txtde entrada que vai conter os dados que serão enviados em lote à tabela do BigQuery.Uma função definida pelo usuário escrita em JavaScript que transformará cada linha do arquivo
.txtnas variáveis relevantes para a tabela.Um arquivo DAG do Airflow que apontará para o local .
Em seguida, faça upload do arquivo
.txt, do arquivo UDF.jse do esquema.json. para um bucket do Cloud Storage. Você também vai fazer upload do DAG para do ambiente do Cloud Composer.Depois do upload do DAG, o Airflow executará uma tarefa a partir dele. Esta tarefa iniciar um pipeline do Dataflow que vai aplicar função definida pelo usuário ao arquivo
.txte formate-a de acordo com a esquema JSON.Por fim, os dados serão enviados para a tabela do BigQuery que você criou anteriormente.
Antes de começar
- Para criar este guia, é necessário ter familiaridade com JavaScript a função definida pelo usuário.
- Para seguir este guia, é necessário ter um Cloud Composer de nuvem. Consulte Criar ambiente. Você pode usar qualquer versão do Cloud Composer com este guia.
-
Ative as APIs Cloud Composer, Dataflow, Cloud Storage, BigQuery.
Criar uma tabela vazia do BigQuery com uma definição de esquema
Criar uma tabela do BigQuery com uma definição de esquema. Você usará essa definição de esquema mais adiante neste guia. Isso A tabela do BigQuery vai conter os resultados do upload em lote.
Para criar uma tabela vazia com definição de esquema, faça o seguinte:
Console
No console do Google Cloud, acesse o BigQuery página:
No painel de navegação, na seção Recursos, expanda o projeto.
No painel de detalhes, clique em Criar conjunto de dados.
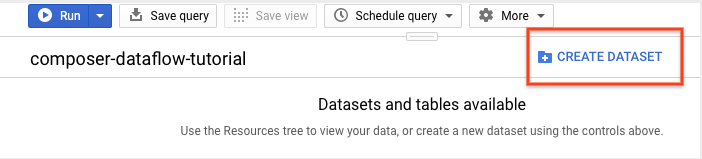
Na página "Criar conjunto de dados", na seção ID do conjunto de dados, nomeie seu Conjunto de dados
average_weather. Não altere os outros campos state.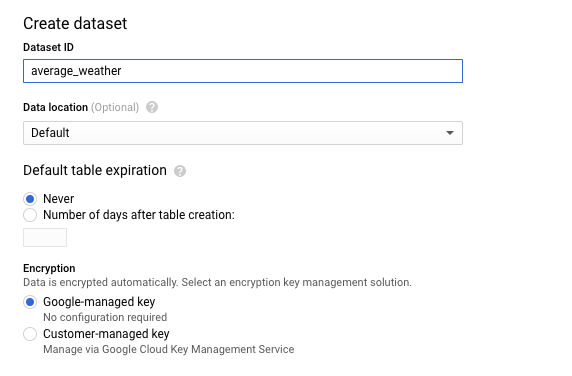
Clique em Criar conjunto de dados.
Volte para o painel de navegação, na seção Recursos, expanda seu projeto. Em seguida, clique no conjunto de dados
average_weather.No painel de detalhes, clique em Criar tabela.
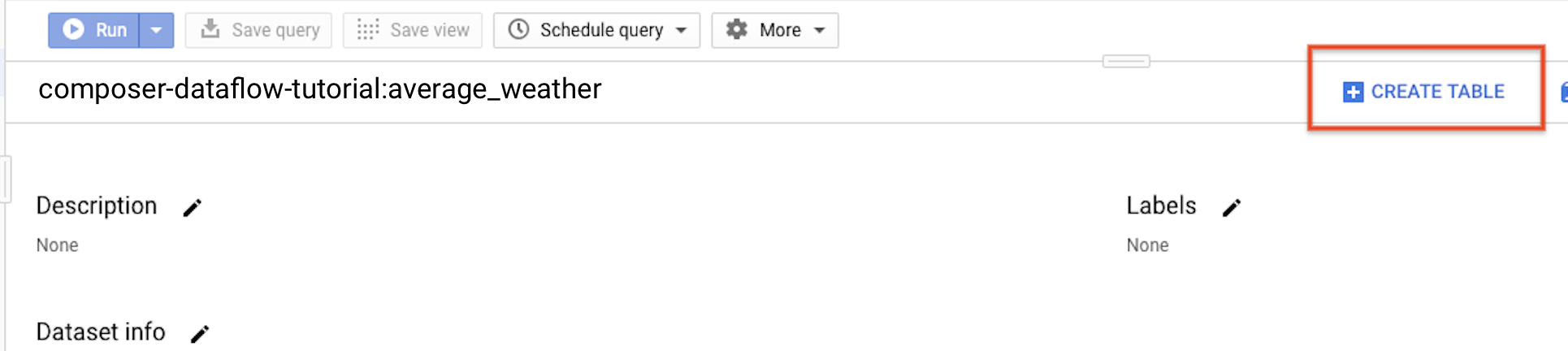
Na página Criar tabela, na seção Origem, selecione Tabela vazia.
Na página Criar tabela, na seção Destino:
Em Nome do conjunto de dados, escolha o conjunto de dados
average_weather.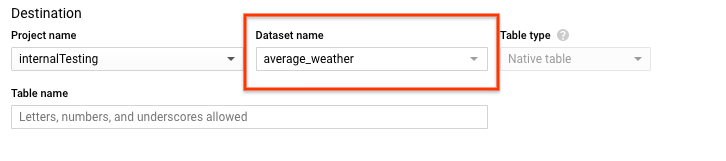
No campo Nome da tabela, digite o nome
average_weather.Verifique se Table type está definido como Native table.
Na seção Esquema, insira a definição do esquema. É possível usar uma das seguintes abordagens:
Insira as informações do esquema manualmente ativando Editar como texto e inserindo o esquema da tabela como uma matriz JSON. Digite o seguinte :
[ { "name": "location", "type": "GEOGRAPHY", "mode": "REQUIRED" }, { "name": "average_temperature", "type": "INTEGER", "mode": "REQUIRED" }, { "name": "month", "type": "STRING", "mode": "REQUIRED" }, { "name": "inches_of_rain", "type": "NUMERIC" }, { "name": "is_current", "type": "BOOLEAN" }, { "name": "latest_measurement", "type": "DATE" } ]Use Adicionar campo para inserir manualmente o esquema:
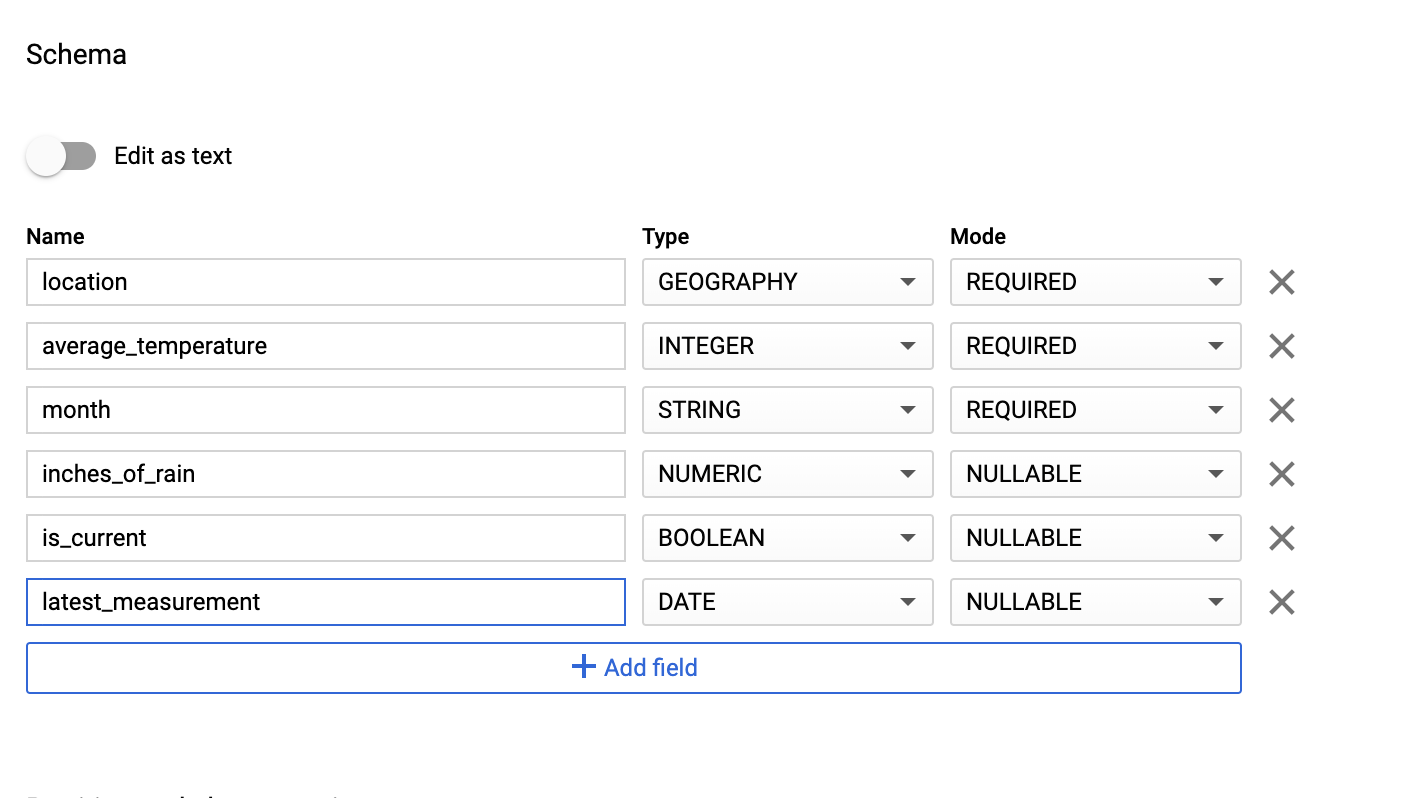
Em Configurações de partição e cluster, não altere os valores o valor de
No partitioning.Na seção Opções avançadas, para Criptografia, não altere o valor o valor padrão,
Google-managed key.Clique em Criar tabela.
bq
Use o comando bq mk para criar um conjunto de dados e uma tabela vazios neste
no conjunto de dados.
Execute o comando a seguir para criar um conjunto de dados de clima global médio:
bq --location=LOCATION mk \
--dataset PROJECT_ID:average_weather
Substitua:
LOCATION: a região em que o ambiente está localizado.PROJECT_ID: o ID do projeto.
Execute o comando a seguir para criar uma tabela vazia no conjunto de dados com a definição do esquema:
bq mk --table \
PROJECT_ID:average_weather.average_weather \
location:GEOGRAPHY,average_temperature:INTEGER,month:STRING,inches_of_rain:NUMERIC,is_current:BOOLEAN,latest_measurement:DATE
Após a criação da tabela, é possível atualizar a expiração, a descrição e os rótulos da tabela. É possível também modificar a definição do esquema.
Python
Salvar este código como
dataflowtemplateoperator_create_dataset_and_table_helper.py
e atualizar as variáveis nele para refletir seu projeto e local, então
execute-o com o seguinte comando:
python dataflowtemplateoperator_create_dataset_and_table_helper.py
Python
Para autenticar no Cloud Composer, configure o Application Default Credentials. Para mais informações, consulte Configurar a autenticação para um ambiente de desenvolvimento local.
Criar um bucket do Cloud Storage
Criar um bucket para armazenar todos os arquivos necessários para o fluxo de trabalho. O DAG que você criar mais tarde neste guia fará referência aos arquivos que você enviar ao do Google Cloud Storage. Para criar um novo bucket de armazenamento:
Console
Abra o Cloud Storage no console do Google Cloud.
Clique em Criar bucket para abrir o formulário de criação de bucket.
Insira as informações do bucket e clique em Continuar para concluir cada etapa:
Especifique um Nome globalmente exclusivo para o bucket. Este guia usa
bucketName, por exemplo.Selecione Região para o tipo de local. Em seguida, selecione um Local em que os dados do bucket serão armazenados.
Selecione Padrão como a classe de armazenamento padrão dos dados.
Selecione o controle de acesso Uniforme para acessar os objetos.
Clique em Concluído.
gsutil
Use o comando gsutil mb:
gsutil mb gs://bucketName/
Substitua:
bucketName: o nome do bucket que você criou anteriormente neste guia.
Amostras de código
C#
Para autenticar no Cloud Composer, configure o Application Default Credentials. Para mais informações, consulte Configurar a autenticação para um ambiente de desenvolvimento local.
Go
Para autenticar no Cloud Composer, configure o Application Default Credentials. Para mais informações, consulte Configurar a autenticação para um ambiente de desenvolvimento local.
Java
Para autenticar no Cloud Composer, configure o Application Default Credentials. Para mais informações, consulte Configurar a autenticação para um ambiente de desenvolvimento local.
Python
Para autenticar no Cloud Composer, configure o Application Default Credentials. Para mais informações, consulte Configurar a autenticação para um ambiente de desenvolvimento local.
Ruby
Para autenticar no Cloud Composer, configure o Application Default Credentials. Para mais informações, consulte Configurar a autenticação para um ambiente de desenvolvimento local.
Criar um esquema do BigQuery formatado em JSON para a tabela de saída
Crie um arquivo de esquema do BigQuery formatado em JSON que corresponda à
tabela de saída criada anteriormente. Os nomes, tipos e modos de campos
precisam corresponder àquelas definidas anteriormente na tabela do BigQuery
esquema. Esse arquivo normalizará os dados do seu arquivo .txt para um formato
compatíveis com seu esquema do BigQuery. Nomear este arquivo
jsonSchema.json:
{
"BigQuery Schema": [
{
"name": "location",
"type": "GEOGRAPHY",
"mode": "REQUIRED"
},
{
"name": "average_temperature",
"type": "INTEGER",
"mode": "REQUIRED"
},
{
"name": "month",
"type": "STRING",
"mode": "REQUIRED"
},
{
"name": "inches_of_rain",
"type": "NUMERIC"
},
{
"name": "is_current",
"type": "BOOLEAN"
},
{
"name": "latest_measurement",
"type": "DATE"
}]
}
Criar um arquivo JavaScript para formatar os dados
Nesse arquivo, você definirá a UDF (função definida pelo usuário) que fornece
a lógica para transformar as linhas de texto em seu arquivo de entrada. Observe que este
usa cada linha de texto do arquivo de entrada como um argumento próprio,
a função será executada uma vez para cada linha do arquivo de entrada. Nomear este arquivo
transformCSVtoJSON.js:
Criar o arquivo de entrada
Esse arquivo conterá as informações que você deseja enviar para o seu
Tabela do BigQuery. Copie este arquivo localmente e dê um nome a ele
inputFile.txt:
POINT(40.7128 74.006),45,'July',null,true,2020-02-16
POINT(41.8781 87.6298),23,'October',13,false,2015-02-13
POINT(48.8566 2.3522),80,'December',null,true,null
POINT(6.5244 3.3792),15,'March',14,true,null
Faça upload dos arquivos para o bucket
Faça upload dos arquivos a seguir no bucket do Cloud Storage que você criou antes:
- O esquema do BigQuery formatado em JSON (
.json) - A função JavaScript definida pelo usuário (
transformCSVtoJSON.js) O arquivo de entrada do texto que você quer processar (
.txt)
Console
- No Console do Google Cloud, acesse a página Buckets do Cloud Storage.
Na lista de buckets, clique no seu bucket.
Na guia Objetos do bucket, siga um destes procedimentos:
Arraste e solte os arquivos que você quer enviar da área de trabalho ou do gerenciador de arquivos para o painel principal no console do Google Cloud.
Clique no botão Fazer upload de arquivos, selecione os arquivos que deseja faça o upload na caixa de diálogo exibida e clique em Abrir.
gsutil
Execute o comando gsutil cp:
gsutil cp OBJECT_LOCATION gs://bucketName
Substitua:
bucketName: o nome do bucket que você criou anteriormente em neste guia.OBJECT_LOCATION: o caminho local do objeto. Por exemplo,Desktop/transformCSVtoJSON.js.
Amostras de código
Python
Para autenticar no Cloud Composer, configure o Application Default Credentials. Para mais informações, consulte Configurar a autenticação para um ambiente de desenvolvimento local.
Ruby
Para autenticar no Cloud Composer, configure o Application Default Credentials. Para mais informações, consulte Configurar a autenticação para um ambiente de desenvolvimento local.
Configurar o DataflowTemplateOperator
Antes de executar o DAG, defina as seguintes variáveis do Airflow.
| Variável do Airflow | Valor |
|---|---|
project_id
|
O ID do projeto |
gce_zone
|
Zona do Compute Engine em que o cluster do Dataflow precisam ser criados |
bucket_path
|
O local do bucket do Cloud Storage que você criou mais cedo |
Agora você fará referência aos arquivos criados anteriormente para criar um DAG que inicie
o fluxo de trabalho do Dataflow. Copie este DAG e salve-o localmente
como composer-dataflow-dag.py.
Airflow 2
Airflow 1
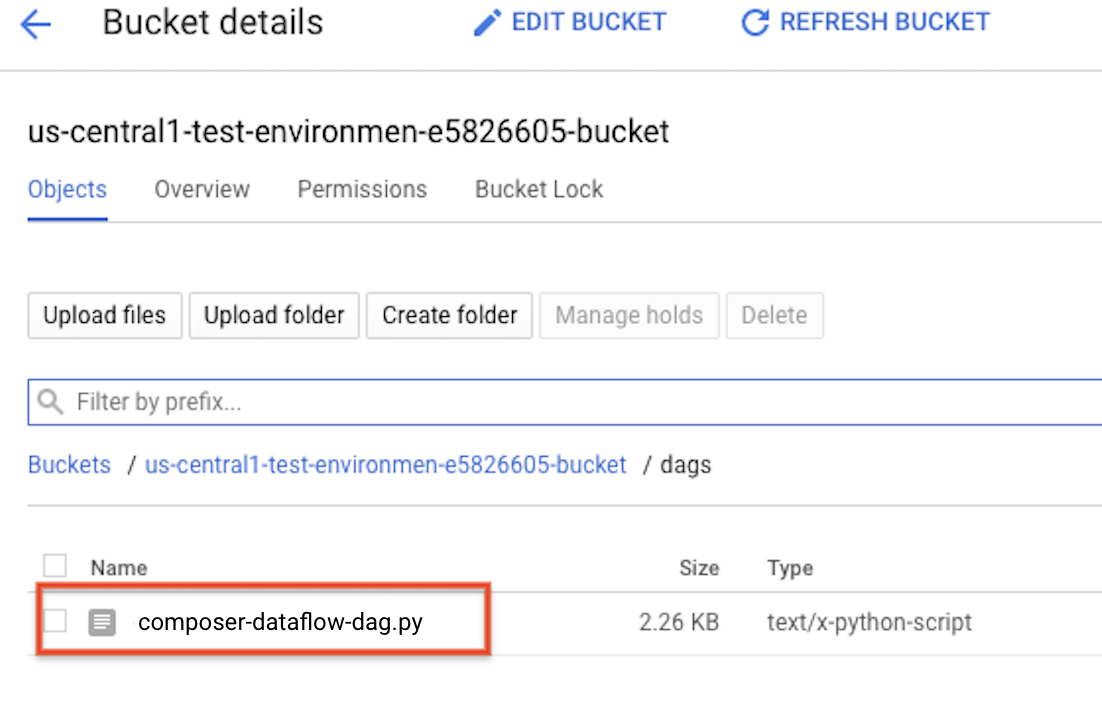
Fazer upload do DAG para o Cloud Storage
Faça upload do DAG para a pasta /dags no
do Google Cloud. Quando o upload for concluído, você poderá vê-lo ao:
Clique no link Pasta de DAGs no Cloud Composer.
Ambientes.
Ver o status da tarefa
- Acesse a interface da Web do Airflow.
- Na página "DAGs", clique no nome do DAG (como
composerDataflowDAG). - Na página "Detalhes dos DAGs", clique em Visualizar gráfico.
Verificar status:
Failed: a tarefa tem uma caixa vermelha ao redor. Também é possível manter o ponteiro sobre a tarefa e procurar por Estado: com falha.Success: a tarefa tem uma caixa verde ao redor. Você também pode manter o ponteiro sobre a tarefa e verificar Estado: sucesso.
Após alguns minutos, é possível verificar os resultados no Dataflow e no BigQuery.
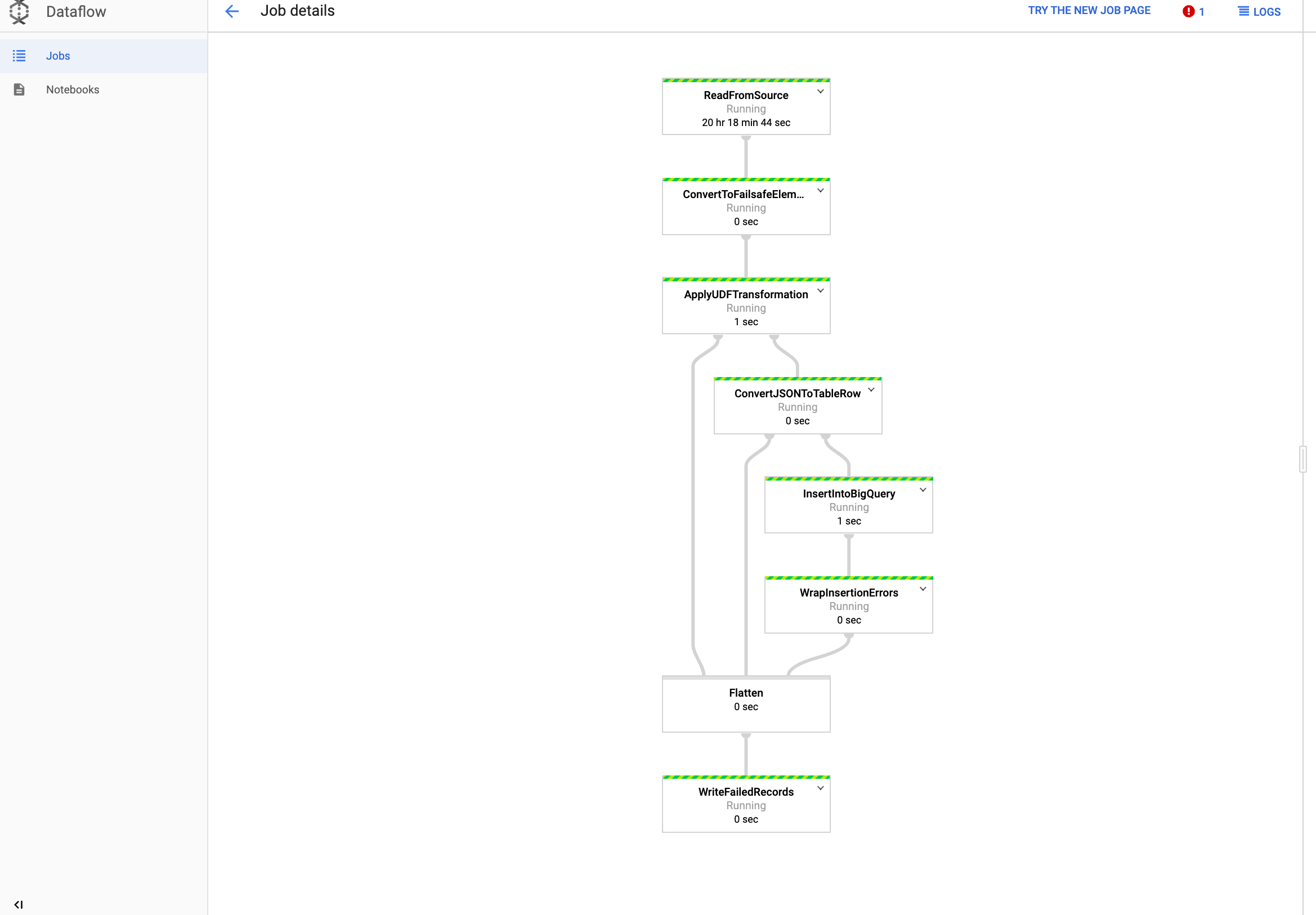
Ver o job no Dataflow
No Console do Google Cloud, abra a página Dataflow.
Seu job se chama
dataflow_operator_transform_csv_to_bq, com um ID exclusivo anexado ao final do nome com um hífen, assim:
Clique no nome para ver a detalhes de trabalho.
Ver os resultados no BigQuery
No Console do Google Cloud, acesse a página BigQuery.
Você pode enviar consultas usando o SQL padrão. Use a consulta a seguir para ver as linhas que foram adicionadas à tabela:
SELECT * FROM projectId.average_weather.average_weather